许多开发人员都很熟悉墨菲法则的一个例子:他们发现在花费了大量时间确保应用程序在开发环境中快速和灵活之后,在发布到生产环境的时候性能会不可思议的大幅下降。更糟糕的是,应用程序平时运行正常,老板或者重要客户操作应用的时候却反应缓慢。详细的日志记录和分析对于追踪这些间歇性的性能瓶颈尤为重要。
然而,当今世界充满了面向服务的架构和分布式的应用,查找性能瓶颈对应的组件极其困难。考虑一个典型 Web 2.0 风格应用的服务器端的常见场景:
- 服务器接收一个 Web 请求,分发给负责产生响应的组件。
- 该请求也许需要通过 LDAP 服务器进行安全验证。
- 控制器组件对数据库执行查询。
- 控制器组件也会调用第三方 Web 服务。
- 控制器组件将所有获得的数据进行汇总,组成一系列业务对象用于显示。
- 业务对象被展现,响应内容传回用户浏览器。
- 运行于浏览器的 AJAX 代码产生其他的请求,与服务器端交互。
对于“为何我的网页反应迟钝?”这样问题的回答需要研究多个组件和执行路径,同时需要生产环境中所有应用组件的详细性能数据。
Perf4J 是一款开源工具包,用于添加 Java 服务器端计时代码、记录日志和监控结果。对于熟悉诸如 log4j 日志框架的开发人员来说,可以这样类比:
Perf4J is to System.currentTimeMillis() as log4j is to System.out.println()
如何利用这个类比理解 Perf4J 呢?回想一下过去还没有广泛应用 Java 日志记录框架的糟糕岁月,我们大多数人如何添加日志记录语句。我们使用System.out.println()作为一种“简陋的调试器”,利用这种快捷但糟糕的方式记录信息。我们很快意识到,这是不够的。我们希望把记录语句输出到专门的日志文件中(如果可能的话,多个不同文件),也许可以每天覆盖日志。我们需要能够设定重要性的不同级别以输出不用的日志语句,可以选择在不改变代码的情况下在特定环境下只输出特定日志,或者在不同环境中改变日志格式。因此,log4j 提供的丰富功能来源于原始想法,是一种“更好的 ”System.out.println()日志语句。
类似的,当 Java 新手发现他们需要添加性能监控代码时,他们经常这样做:
long start = System.currentTimeMillis();
// execute the block of code to be timed
log.info("ms for block n was: " + (System.currentTimeMillis() - start));
但是很快,这些开发人员发现他们需要更多的信息,综合的性能统计数据如平均、最小、最大、标准差和特定时间段内每秒的事务处理量。他们希望将这些数据绘成实时图表监控运行服务器上的问题,或者通过 JMX 输出性能指标以便于启动监控器在性能下降的情况下发出警报。此外,他们还希望计时语句可以和类似 log4j 的框架配合使用。
Perf4J 的目标是通过易于集成(和扩展)的开源软件包提供这些功能。Per4J 是由 Homeaway.com 开发的,其基础设施的分布式特性和网站的高可用性及性能需求需要深入的性能分析。Perf4J 的特点包括:
- 简洁的 stop watch 计时机制。
- 提供命令行工具,从原始的日志文件中生成汇总的统计数据和性能图表。
- 定制的 log4j appender,可以在运行时应用中生成数据和图表,计划在以后的版本中支持
java.util.logging和 logback。 - 能够以 JMX 属性的形式发布性能数据,在数据超过指定阈值时发送通知。
- 提供
@Profiled注解和一套自定义机制,允许在与 AOP 框架(如 AspectJ 或者 Spring AOP)集成时巧妙的计时。
下面的例子展现了如何轻松利用这些功能。可以通过 Perf4J 开发人员指南来了解集成 Perf4J 的详细信息。
利用 StopWatch 类开发计时代码
org.perf4j.LoggingStopWatch类用于在代码中添加计时语句并打印到标准输出或者日志文件中:
StopWatch stopWatch = new LoggingStopWatch();
//... execute code here to be timed
stopWatch.stop("example1", "custom message text");
对stop()方法的调用记录了执行时间并打印日志信息。默认情况下,基类LoggingStopWatch将输出打印到System.err流中。但是大多数情况下,你需要使用一个集成到现有 Java 日志框架(如Log4JStopWatch、CommonsLogStopWatch或者Slf4JStopWatch)的子类。下面是一些stop watch的输出示例:
start[1233364397765] time[499] tag[example1] message[custom message text]
start[1233364398264] time[556] tag[example1] message[custom message text]
start[1233364398820] time[698] tag[example1] message[custom message text]
使用 LogParser 创建统计数据和图表
虽然默认的stop watch输出相比直接调用System.currentTimeMillis()来说没有很大的改进,但真正的好处在于能够解析这些输出以生成统计数据和图表。LogParser 通过 tag 和时间片把stop watch输出分组,生成详细的统计信息和可选的时间序列图(使用 Google Chart API)。下面是一些使用默认文本格式(也支持 csv 格式)的示例输出:
Performance Statistics 20:32:00 - 20:32:30
Tag Avg(ms) Min Max Std Dev Count
codeBlock1 249.4 2 487 151.3 37
codeBlock2.failure 782.9 612 975 130.8 17
codeBlock2.success 260.7 6 500 159.5 20
Performance Statistics 20:32:30 - 20:33:00
Tag Avg(ms) Min Max Std Dev Count
codeBlock1 244.0 7 494 150.6 41
codeBlock2.failure 747.9 531 943 125.3 21
codeBlock2.success 224.1 26 398 106.8 21
Performance Statistics 20:33:00 - 20:33:30
Tag Avg(ms) Min Max Std Dev Count
codeBlock1 289.3 10 464 141.1 22
codeBlock2.failure 781.1 599 947 135.1 8
codeBlock2.success 316.2 115 490 112.6 13
平均执行时间和每秒事务处理量的图表以指向 Google Chart Server 的 URL 的形式生成。
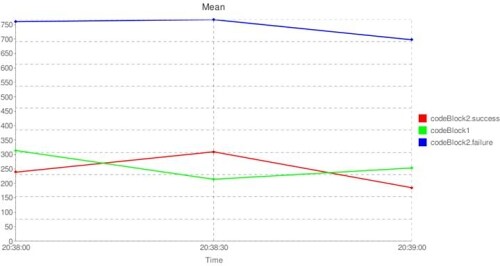
同时,虽然LogParser默认从标准输入中读取数据,但是你也可以指定一个来自运行时服务器的日志文件,用LogParser实时输出:
tail -f performance.log | java -jar perf4j-0.9.8.1.jar
集成 Log4J
Perf4J 的扩展功能大部分通过一套定制的 log4j appender 提供。这样开发人员就能在部署阶段通过非常熟悉的日志框架来零零散散的添加分析和监控功能(未来的 Perf4J 将提供定制 logback appender 和java.util.logging处理器)。其中一个重要的功能是允许 Perf4J 作为 JMX MBeans 的属性展示性能数据,同时在性能低于可接受的阈值时发送 JMX 通知。因为 JMX 已经成为处理和监控 Java 应用的标准接口,提供 Perf4J MBean 开启了广泛的由第三方监控应用提供的功能。举例来说,我们 Homeaway 的 IT 部门标准化了 Nagios 和 Cacti 用于系统监控,这两个工具都支持把 MBeans 作为数据源查询。
下面的 log4j.xml 文件示例显示了如何启用用于 JMX 的 Perf4J appender:
<?xml version="1.0" encoding="UTF-8" ?>
<log4j:configuration debug="false" xmlns:log4j="http://jakarta.apache.org/log4j/">
<!-- Perf4J appenders -->
<!--
This AsyncCoalescingStatisticsAppender groups StopWatch log messages
into GroupedTimingStatistics messages which it sends on the
file appender and perf4jJmxAppender defined below
-->
<appender name="CoalescingStatistics"
class="org.perf4j.log4j.AsyncCoalescingStatisticsAppender">
<!--
The TimeSlice option means timing logs are aggregated every 10 secs.
-->
<param name="TimeSlice" value="10000"/>
<appender-ref ref="fileAppender"/>
<appender-ref ref="perf4jJmxAppender"/>
</appender>
<!--
This file appender is used to output aggregated performance statistics
in a format identical to that produced by the LogParser.
-->
<appender name="fileAppender" class="org.apache.log4j.FileAppender">
<param name="File" value="perfStats.log"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%m%n"/>
</layout>
</appender>
<!--
This JMX appender creates an MBean and publishes it to the platform MBean
server by
default.
-->
<appender name="perf4jJmxAppender"
class="org.perf4j.log4j.JmxAttributeStatisticsAppender">
<!-- The tag names whose statistics should be exposed as MBean attributes. -->
<param name="TagNamesToExpose" value="firstBlock,secondBlock"/>
<!--
The NotificationThresholds param configures the sending of JMX notifications
when statistic values exceed specified thresholds. This config states that
the firstBlock max value should be between 0 and 800ms, and the secondBlock max
value should be less than 1500 ms. You can also set thresholds on the Min,
Mean, StdDev, Count and TPS statistics - e.g. firstBlockMean(<600).
-->
<param name="NotificationThresholds" value="firstBlockMax(0-800),secondBlockMax(<1500)"/>
</appender>
<!-- Loggers -->
<!-- The Perf4J logger. -->
<logger name="org.perf4j.TimingLogger" additivity="false">
<level value="INFO"/>
<appender-ref ref="CoalescingStatistics"/>
</logger>
<!--
The root logger sends all log statements EXCEPT those sent to the perf4j
logger to System.out.
-->
<root>
<level value="INFO"/>
<appender name="console" class="org.apache.log4j.ConsoleAppender">
<layout class="org.apache.log4j.SimpleLayout"/>
</appender>
</root>
</log4j:configuration>
除了 JMX 插件,Perf4J 也支持生成性能图表的画图 appender,使用前端的 Perf4J 画图 Servlet。定制的 csv 布局可以轻松的导入 Excel 或者其他电子表格应用。
使用 @Profiled 注解简化性能日志
在代码中增加性能记录语句(通常的日志语句)的一个缺点是降低了代码的“信噪比”,难以在特定代码块中遵循严格的业务逻辑。为了改善这一不足,Perf4J 提供了@Profiled注解,可以添加在需要记录执行时间的方法上,允许方法本身不添加StopWatch代码:``
@Profiled(tag = "dynamicTag_{$0}")
public void profiledExample(String tagSuffix) {
... business logic only here
}
一旦添加了@Profiled注解,Perf4J 的计时切面会通过一个面向切面的编程框架如 AspectJ 或者 Spring AOP 启用。这个切面在方法调用周围加入建立和停止StopWatch实例的字节码。计时切面甚至可以有选择的使用 AspectJ 的加载时编织(load-time weaving)功能。因此,通过使用加载时编织你可以保证那些没有启用性能监控的方法绝没有额外的负担。
一个简单的示例:基于 Web 的质数生成器
本示例将带你感受如何创建一个使用 Perf4J 库大多数功能的真实应用。你可以下载 perf4jPrimes.war文件,然后 Servlet 容器中运行它。在 war 包中也包含该应用的源代码。
一切从简,本例子只包含两个主要的代码文件:primes.jsp用于显示生成的质数和接受用户指定的参数,PrimeNumberGenerator类包含真正的生成代码(大部分委托给java.math.BigInteger类)。其中有三处使用了 Perf4J 计时代码块:
- 在
primes.jsp创建Log4JStopWatch统计整个页面的生成时间。 PrimeNumberGenerator.generatePrime()方法具有一个Profiled注解。PrimeNumberGenerator.randomFromRandomDotOrg()也含有Profiled注解。
如果查看WEB-INF/classes/log4j.xml文件,你会看到启用了下面的 Perf4 功能:
- 所有单独的
stop watch日志都被写入标准输出(请注意你的 servlet 容器可能把标准输出定向到磁盘的某个文件中)。如果需要的话,你可以直接使用LogParser。 AsyncCoalescingStatisticsAppender被创建以汇总stop watch日志并传递给下游的GraphingStatisticsAppenders和JmxAttributeStatisticsAppender。- 两个
GraphingStatisticsAppender被创建,其中一个表示平均执行时间,另一个输出每秒事务数。
一旦在 Web 服务器上启动了该 Web 应用,你就可以通过http://servername/<rootContextLocation>/primes.jsp访问质数生成页面,其中rootContextLocation由你的 Web 服务器配置决定(当然,为了方便,你也可以通过http://servername/<rootContextLocation>/PrimeNumberGenerator.java查看PrimeNumberGenerator源代码)。在primes.jsp页面中,你会看到很多用于质数生成的不同参数。你可以改变参数,然后点击“ 生成质数”按钮,看看这些参数是如何影响质数产生时间的。在生成大量质数之后,你可以通过三种途径来查看 Perf4J 输出:
- 原始的标准输出日志。
- 通过
http://servername/<rootContextLocation>/perf4jGraphs访问图形化 Servlet。你应该能够看到平均执行时间和每秒事务数。 - JMX 监控也启用了。你可以通过 Java SDK 附带的 jconsole 应用查看 Perf4J MBean 值。这需要在启动 Web 服务器时,使用 -Dcom.sun.management.jmxremote 命令行参数。然后,如果在运行 Web 服务 器的同一台机器上启动 jconsole 就可以在“
MBeans”标签中看到 “org.perf4j.StatisticsExposingMBean.Perf4J”的数据值。
因为到现在为止你还没有启用任何TimingAspects支持@Profiled注解,你能够看到的唯一stop watch输出就是“fullPageGeneration”标记。如果要启用TimingAspects,你可以使用AspectJ加载时编织。你需要做的是,在启动 Web 服务器时使用AspectJ weaving代理命令行参数:
-javaagent:/path/to/aspectjweaver-1.6.1.jar
你可以在这里下载 jar 包: http://mirrors.ibiblio.org/pub/mirrors/maven2/org/aspectj/aspectjweaver/1.6.1/aspectjweaver-1.6.1.jar
当代理启用时,你可以在“generatePrime”和“randomFromRandomDotOrg”标记中看到stop watch的输出。
陷阱与最佳实践
很多监控应用的方法,不论是针对性能、稳定性还是语义正确性,都无法最有效的体现它们的意图。要么生成了太多的信息以至于难以分析这些数据,要么在需要信息的地方却得不到关键的数据。虽然所有的监控都需要一些额外的开销,但是性能监控应该对这些引入的开销格外小心。以下建议可以帮助你最大限度地利用 Perf4J,同时又将副作用降到最低:
- 在判断需要分析哪些方法和代码块时,首先把重点放在关键点上。在企业应用中,每当遇到性能瓶颈时,都会存在很多“通常的疑点”:数 据库调用、运程方法调用、磁盘 I/O、针对大型数据集的计算操作。因此,你应该首先集中分析这些类型的操作。同时,因为这些操作花费几十甚至几百毫秒的时 间,Perf4J 所带来的额外开销相对于本地执行时间来说微不足道,在实践中可以忽略不计。事实上,这也是 Perf4J 故意使用
System.currentTimeMillis(而不是System.nanoTime)计时代码块的原因之一:纳秒的粒度在这种企业应用代码块中意 义并不大。 - Perf4J 把性能分析的工作委托给独立的线程或者进程。当使用
AsyncCoalescingStatisticsAppender时,执行线程把日志事件推入到一个内存中的队列,由另外一个独立的线程发送这些日志 消息到下游 appender。因此,即使那些下游 appender 做了大量敏感的工作,如建立图表、更新 MBean 属性或者存储到数据库中,对计时的代码 块的影响微乎其微,而且与这些下游 appender 做的工作多少无关。类似的,当把计时日志写入文件用于解析和分析时(例如,使用 Unix tail 命令),对于计时进程的影响也只与它写日志所花费的时间有关,与 log 分析器的时间无关。 - 不要忘记性能回归测试的好处。除了监测运行时的性能瓶颈,Perf4J 非常适合创建性能回归测试以判断代码更改是否对性能有显著影响(不论是积极或消极的)。通过创建一个原始代码的基准,你很快就能发现新代码对性能产生了何种影响。
- ** 利用
@Profiled注解和 AspectJ 的加载时编织来决定哪些方法应该在部署时计时。** 如果使用了 @Profiled 注解,你可以自由的在方法调用周围添加计时,然后决定在使用 AspectJ 的aop.xml配置文件进行部署时需要对哪些方法进行计时。没有计时的方法不 会被关注。虽然那些被计时的方法比直接在代码中使用StopWatches存在一些细微的额外开销(事实上 AspectJ 在计时方法的周围建立了一个闭 包),这些开销相对于那些需要花费几毫秒的方法来说是微不足道的。 - 不要忘记应用程序中 JVM 之外执行的部分。举例来说,很多 Web 2.0 应用的大部分都是通过运行在客户端浏览器中的 JavaScript 实现,虽然 Perf4J 可以用于衡量运行在服务器端的方法(响应 AJAX 远程调用),但如果 JavaScript 执行性能下降,你仍然需要其他的客户端调试工具。
展望 Perf4J
Perf4J 目前正在积极的发展,新的功能层出不穷。举例来说,凭借新版本的 Perf4J,我们可以通过单独的配置文件指定要分析的方法,这样即使 无法获得某些方法的源代码也可以对其进行计时。我们始终将用户的反馈和需求放在第一位,如果你想打造它未来的功能,那现在就来尝试 Perf4J 吧。更重要 的是,Perf4J 在 Apache 2 协议下完全开源,代码都充分文档化,你可以随意扩展。
现在就下载Perf4J 吧,告诉我们你的想法!
查看英文原文: Performance Analysis and Monitoring with Perf4J 。
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




