
近期,阿里开源了自研的大规模分布式搜索引擎 Havenask(内部代号 HA3)。
Havenask 是阿里巴巴内部广泛使用的大规模分布式检索系统,支持了淘宝、天猫、菜鸟、优酷、高德、饿了么等在内整个阿里的搜索业务,是过去十多年阿里在电商领域积累下来的核心竞争力产品。
大数据时代,数据检索是必备的基础能力。Havenask 支持千亿级别数据实时检索、百万 QPS 查询,百万 TPS 高时效性写入保障,毫秒级查询延迟和数据更新。并具有良好的分布式架构、极致的性能优化,能够实现比现有技术方案更低的成本,帮助企业降本提效。
开源地址:http://github.com/alibaba/havenask
应用在阿里核心场景的搜索引擎
Havenask 主要是作为高性能 AI 智能引擎,应用在搜索、推荐和广告等最典型的 AI 场景,比如淘宝、天猫 App 的首页搜索框、首页拍照搜索、首页信息流、逛逛等。
在这个场景中,工程引擎需要支持好算法团队快速 AB 实验、快速优化迭代,做到算法优化分钟级上线;并在机器资源可控,成本可接受前提下,支持算法团队实验千亿级参数、超大模型,极致优化算法效果。算法效果的好坏直接影响客户体验,影响用户的留存、购买转化、以及广告效率。因此,Havenask 对电商业务的增长起关键作用。
以手机淘宝 App 首页的拍立淘(拍照搜商品)为例,我们对感兴趣的物品随手拍一张照片,利用这张图片,在拍立淘中搜索,淘宝就会从数十亿商品中找到一样或者类似的商品。这也是典型的向量计算场景。数十亿数据,高纬度向量计算,需要 Havenask 具备实时、高性能、低成本特性,才能实现实时无延迟的搜索体验。
Havenask 另外一个应用场景是大数据检索,比如淘宝 App 中订单检索、物流信息、优惠券发放使用等,本质上都是关键词附加多条件的检索。
传统的做法是基于数据库来实现。但在这种场景中,数据量至少是 TB、PB 规模。当数据规模特别大,高并发更新和查询操作,会给数据库性能带来较大的瓶颈,成本上也会有比较大的挑战。而基于 Havenask 搜索引擎技术,可实现千亿级数据,秒级时效性,毫秒级查询延迟,为用户提供顺滑的用户体验,成本也远低于数据库方案。
以淘宝优惠券为例,淘宝有数千万商家、数亿消费者,会有大量优惠券的发放和使用,优惠券的状态变更也具有实效性,因此优惠券的发放、使用和结算,要做到好的体验,必须准确、实时。这不是一件容易的事情,对系统性能的要求非常高,成本也不会低。但依赖 Havenask,就能以低成本实现千亿级数据查询、秒级时效性、毫秒级查询延迟。
阿里巴巴内部十余年的沉淀
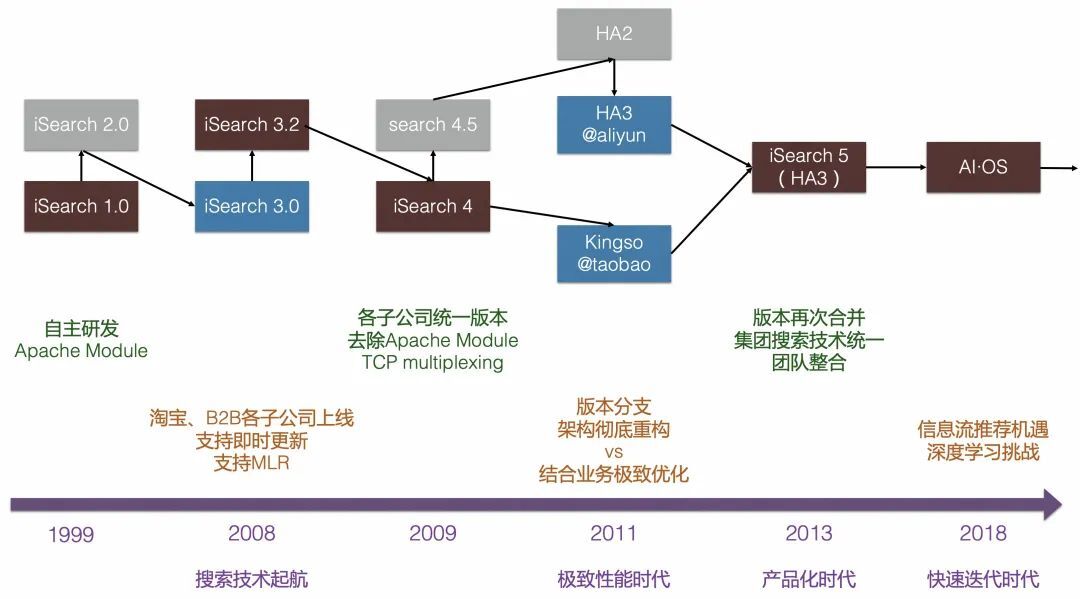
阿里电商搜索早期是以 Apache http server module 的形式实现,支持淘宝、B2B 等子公司搜索业务,一个业务一个版本分支,与业务逻辑深度耦合。因此大概从 2009 年开始,阿里支持业务的同时,组建了一支小队伍,从零开始重写整个搜索系统。
2011 年,新系统完成研发,替代雅虎老的网页搜索系统完成上线,开启自研大规模分布式高性能搜索引擎时代。当时内部代号“问天引擎”(HA3),后来随着组织架构调整成为今天的 UC 神马搜索。
上线自研引擎之后,经过一两年的时间,阿里将多个老引擎分支做了统一。问天引擎开始支持集团几乎所有搜索业务,包括淘宝、天猫等,以统一代码分支和产品化、规模化的方式支持集团大量搜索业务。搜索技术团队也统一到了一起,以极致性能优化、分布式、高可用、运维友好为目标不断打磨这个搜索产品。
2016 年,随着深度学习技术广泛应用,电商领域迎来信息流推荐的新机遇,也给工程引擎带来新的挑战。从这时开始,阿里在信息流推进的基础上,将原来的 HA3 体系发展成了阿里集团里一个比较核心的 AI 引擎。
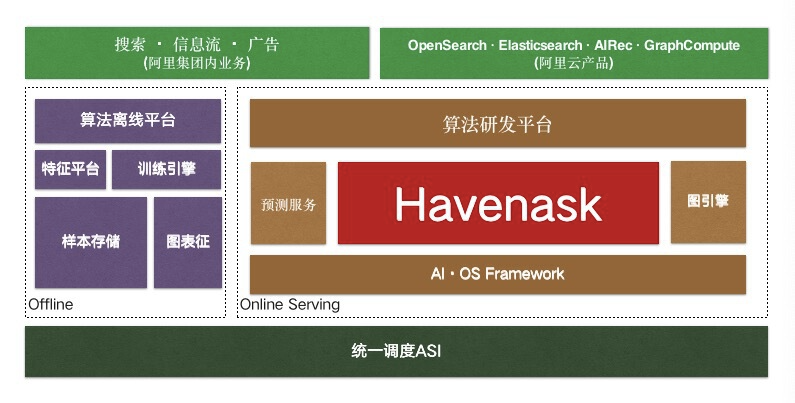
此后经过不断演进,Havenask 逐渐成为了阿里搜推广场景的核心 AI 智能引擎。作为阿里搜推广中台的工程引擎体系 AI·OS (AI Online Serving) 的核心引擎,Havenask 支撑了阿里集团包括淘宝、天猫、菜鸟、高德、饿了么等业务在内的数千搜索业务。
现在 Havenask 支持的业务,可以分为三类:
淘宝、天猫主搜最头部业务,直接部署使用 Havenask 搜索引擎,引擎团队贴身支持算法和业务,业务规模在个位数;
淘宝、天猫主搜之外的其他核心搜索业务,比如高德、优酷、饿了么、AE 等,由 Havenask 之上构建的 OpenSearch PaaS 版平台产品支持,业务方自助定制开发和运维,引擎团队提供支持,业务规模在百级别;
其他中长尾业务,或者无深度定制需求的核心搜索业务,由云上云下统一的云产品 OpenSearch SaaS 版(底层基于 Havenask)支持,业务方自助使用,引擎团队提供支持,业务规模在千级别。
搜索引擎的整体架构
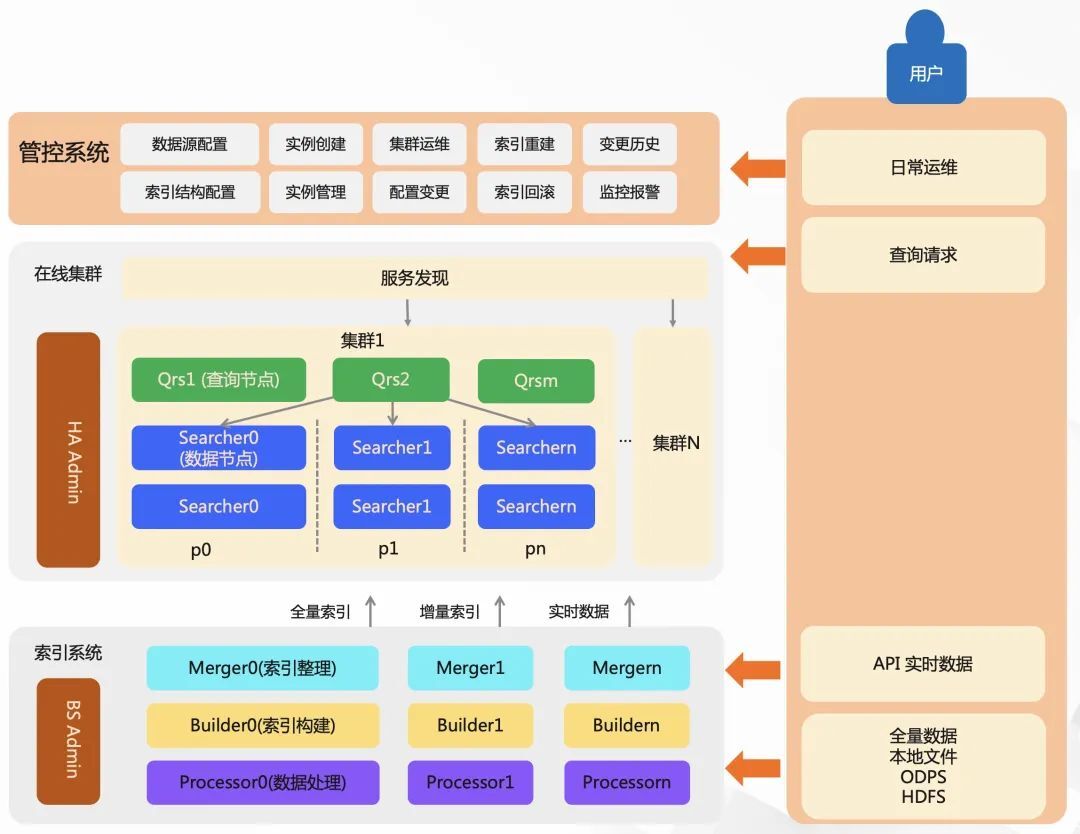
在 Havenask 中,一个较为完整的搜索服务由:在线系统、索引系统、管控系统、扩展插件等部分构成,其中包括了查询流、数据流、控制流。
在线系统,包含了 QRS 和 Searcher。Qrs 负责接收用户查询、查询分发、收集整合结果。Searcher 是搜索查询的执行者,负责倒排索引召回、统计、条件过滤、文档打分、排序、摘要生成等。
索引系统,负责索引数据生成的过程,还包含有文档处理与索引构建服务 Build Service。索引构建分为三个步骤,对数据进行前置处理(例如分词、向量计算等)、产出索引、合并索引文件的处理。
管控系统,负责提供强大的运维能力。
扩展插件,提供插件机制,索引和在线流程各环节中,均可以通过开发插件,对原始文档、查询 Query、召回、算分、排序、摘要进行灵活修改。
Havenask 作为 AI 引擎,本质上是为了帮助用户更精准的找到满足自己需求的商品,随着机器学习技术的发展,大量深度学习算法应用在电商搜索引擎上,实现个性化和智能化。以电商搜索为例,用户在搜索框中敲一个关键词或者一句话,系统首先会试图理解这个关键词或者这句话(NLP 技术),并拆分成以关键词、语义相关性、向量检索等多路方式召回,召回一批商品,并对这批商品做粗排,粗排后更小的商品集合上再做精排,这其中各个环节会大量应用机器学习算法,来实现搜索的个性化和智能化,整个过程需要在毫秒级完成。
在这个流程中,搜索团队在性能和迭代效率上做了大量优化,关键有两点:
海量物品的准确召回,是提升搜索质量的第一个环节,一般会通过多个系统的调用实现多路召回,调用链路复杂,召回延迟也可能较大。Havenask 支持在一个系统内部利用全图化思想,并发的完成关键词、语义相关性、向量、个性化等多路召回,合并后直接返回最终召回结果,做到极小的召回延迟。
针对不同的召回特性,支持 O2O(offline 计算转 online,或 online 计算转 offline)优化,支持数据、模型实时更新,并保证在离线的一致性。算法工程师可以运用更复杂的召回策略,在线上快速做各种 AB 实验,实验验证效果后可以分钟级全量上线。
另外,AI 引擎还支持丰富的插件拓展机制,和自研 CAVA 语言(类似于 JAVA 的语言)开发,并能集成达摩院 Proxima 向量库,支持多模态搜索。
阿里内部大数据检索场景的业务大部分基于 Havenask。大数据检索场景最主要的特点是数据量大,数据更新或查询并发度高,一般不需要强一致性,数据库的强一致性和事务,在这个场景下反而会导致性能瓶颈和较高的成本。
在大数据检索场景下,比较接近的对标软件是 Elasticsearch。Elasticsearch 主要以日志分析和检索、监控、安全分析、企业文档搜索、关键词召回等为主要场景。Havenask 跟 Elasticsearch 也有一些差别:
Havenask 数据更新时效性更好,大数据量数据写入高并发情况下,数据更新后到可查询到仍然可以做到 1 秒内。ES 受架构限制,虽然时效性可配置,但大数据量情况下,时效性配置到 1 秒在生产上基本不太可用。
更好的查询性能。在同一数据集上的测试表明,Havenask 用更少的资源(内存使用量少 20~50%),查询 QPS 高 2~3 倍,查询平均延迟低约 2/3。
因此,在大数据检索场景下,可以说 Havenask 给业界提供了一个极致性价比的新技术方案。
Havenask 底层全部由 C++ 实现,具备较完备的索引构建、存储和管理能力,具有较好的扩展性,既能使用单机的存储媒介、开源的分布式存储系统,也能基于云存储产品。
后续开源规划
搜索引擎是非常复杂的一个系统。在数据规模极大的时候,要想达到很好的稳定性、实时性,这是非常有挑战的。对于一般规模企业来说,自研大规模分布式搜索引擎,一般需要投入几十甚至上百人的团队,耗时数年。Havenask 的开源,无疑也为有类似需要的企业,节省了高昂的研发成本。开发者和企业也能借助 Havenask 在 AI 领域实现更容易、更快速的创新。
而阿里也期望 Havenask 的开源能吸引更多优秀的开发者参与共创,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。
阿里目前已经基于 Apache 2.0 许可开源了 Havenask 核心代码,并表示未来几个月内将发布正式版,保持与内部主干代码一致。后续有计划逐步开源阿里 AI·OS 体系更多的系统,下一个可能开源的系统是图计算引擎(内部代号 igraph)。
今日好文推荐
程序员离职后为泄私愤远程锁公司服务器硬盘;前程无忧宣传语嘲讽“996”职场人;Twitter 开源工作停摆| Q资讯




