
前文请见《Evernote 从自有数据中心到 Google 云平台的迁移》的第 1 篇、第 2 篇。
第四部分:全面迁移的计划和实施
在计划 Evernote 服务迁移的过程中,我们希望尽量最小化宕机时间,不过我们也知道,我们现有的架构不支持零宕机迁移。在制定迁移方法和维护时间窗口的计划时,我们提出了一些要求。
- 我们要最小化在“多站点”模式下运行的时间。
- 从迁移单个分片开始,随后逐渐增加到同时迁移 8 个分片。
- 在少量分片迁移到 GCP 之后,我们需要大概 48 小时的时间用于观察它们的运行状态。
- 最多同时支持迁移 32 个分片,再多就会有风险。如果出现问题,涉及的范围越大就越难以控制。
- 选择在周末时间迁移 UserStore,并把迁移时间保持在一个小时以下。因为 UserStore 的迁移会造成全面宕机,所以我们要最小化对用户造成的影响。
- 每个分片的迁移造成的宕机时间不能超过 30 分钟。宕机从来都不是一件好事,这也是我们一直要避免的。可惜我们的应用不支持透明的分片失效转移。不过好在用户客户端内容的同步间隔一般在 15 分钟以内,所以用户可能不会注意到宕机。
- 我们希望有足够的灵活性,以便在迁移过程中应对一些未知的状况。
- 一旦全局服务正式运行,就不再允许出现任何“停业整顿”之类的维护时间了。
基于上述几点考虑,以及我们对分片迁移速度的预期,我们最终做出了如下计划。我们在论坛和社交媒体上与用户就此事进行了沟通。
分片的迁移时间为每天的太平洋夏令时时间,从早上 9 点到晚上 9 点。
- 12 月 8 号到 9 号进行第一次分片迁移
- 12 月 11 号进行 UserStore 迁移
- 12 月 14 号到 16 号进行第二次分片迁移
从 12 月 16 号到 31 号,我们耐心观察等待。所有的运维工程师 24/7 待命,以便快速对问题和故障做出响应。
从 12 月 1 号开始,我们也一直在迁移那些不会影响用户体验的服务,比如图像识别服务和前端流量。
迁移的技术细节
NoteStore
在计划迁移 NoteStore 时,我们利用到了之前的“分片迁移”经验。之前,为了在数据中心的不同硬件间移动分片,我们开发了一套流程和脚本。虽然这套流程不能完全适用于这次迁移,但仍然成为这次迁移的核心基础。
首先,我们要在 GCP 端创建新的分片,然后开始同步数据。
创建空的分片
我们使用 Google 的部署管理器和我们已有的 Puppet 脚本创建新的 NoteStore。这些新分片的名字和配置与生产环境中的分片是一样的,只是没有用户数据,而且还没有被配置到负载均衡平台上。
同步数据
每个分片有两种用户数据需要同步:
- 存储用户笔记的 MySQL 数据库
- 复制生产环境 MySQL 最新的备份
- 处理备份
- 解压
- 解密
- 启动数据库实例
- 在源实例和目标实例上配置用于复制的用户角色
- 从备份点开始复制
- Lucene 索引。Lucene 与 MySQL 不一样,它并没有提供原生的数据复制支持,所以我们需要使用自定义工具来移动数据。我们基于 ubiquitous rsync utility 创建了一个工具,并通过 cron 在每台源主机上运行,向我们的 Graphite/Splunk 数据收集管道发送度量指标和日志。
我们在切换分片服务之前的 5 到 10 天启动数据复制流程。
在这个过程中,我们不断迭代更新我们的方法。
- 最初的 MySQL 配置使用日常备份和二进制日志进行数据复制。不过后来发现,我们的备份服务器无法满足多个进程并行运行的要求。
- 为了满足我们的并行要求,我们使用新的 GCS bucket 作为备份目标。我们通过重写 ansible playbook 进行基于流的 innobackupex 加密和压缩备份,并将其直接写入 GCS bucket。
- 在每个分片的备份可用之后,我们使用新的 playbook 在复制目标上挂载更多的 PD 存储,用于下载、解压备份数据。
- 另一个 playbook 会运行我们在之前的迁移中开发的工具“genesis”,这个工具会验证 MySQL 的配置、恢复备份、更改密码、启动和关闭检查、升级数据库,并最终启动 MySQL 复制进程。
- 我们的 Lucene 复制工具很稳定,不过很快我们就发现我们的交换机链路和数据中心到 GCP 之间的 VPN 连接逐渐趋于饱和。因为一些技术原因,我们不得不调整最初的 Lucene 复制进程数量(最初的同步复制严重消耗网络带宽,经过调整之后,后续的同步只复制变更的部分)。
- 我们对网络通道映射也做了一些调整,让 ansible 按需进行批次复制,先是观察初始的复制情况,再通过 cron 运行新的复制。
服务切换
服务切换的目标是尽快安全地完成切换,以便最小化宕机时间。
- 停止生产环境的分片,并将其移出负载均衡器,确保用户不会对其做任何更新。
- 运行最后阶段的增量数据同步。
- 启动新的分片(包含了同步过的数据)。
- 使用一套工具(我们把它们叫作“confidence”)检查数据是否复制成功,是否是最新的,校验和是否匹配,等等。
- 在新分片上运行 QA 脚本,验证分片的功能是否正常。
- 移除新分片的备份。
- 新分片向用户开放。
- 关闭日志、事务和告警监控。
为了加快速度,我们不能依靠手动工作。在确保这个流程可行之后,我们使用 ansible 对流程进行自动化。
我们的脚本可以在 30 分钟内自动迁移一个分片(平均包含了 30 万个用户的数据)。我们逐渐增加并行数量,直到可以并行迁移 32 个分片。这样我们就可以在 30 分钟内迁移大约 1 千万用户的数据。
我们的团队
在迁移过程中,来自运营团队的不同角色的人员一起协作,确保一切进展顺利。
- 项目经理:项目经理协调整个迁移项目,并作出决策,包括批处理的大小、何时开始批处理以及如何与外部沟通进度。
- 首席工程师:首席工程师对迁移有完全的控制权,他在迁移之前坚定大家的信心,管理迁移工具,并作出排查决策。
- 监控工程师:监控工程师查看我们的监控系统,找出异常情况,并在每个迁移完成之后通知大家。他们还会运行 QA 工具,最终确认迁移是否成功。
- 修复团队:我们有 2 到 4 个工程师排查和修复由首先工程师和监控工程师发现的问题。
UserStore
UserStore 的迁移步骤与 MySQL 的迁移基本步骤是一样的,不一样的地方在于需要将原先指向 NoteStore 的 JDBC URL 改成指向新的主机。
因为 UserStore 处在整个 Evernote 服务的中间,所以我们在一个周日早上特意安排了一个小时的维护时间。因为 UserStore 承担了整个服务的大部分事务,为了监控迁移过程,我们让一大组运营人员和工程师在办公室待命。还有一个来自 Google 的团队,他们也做好准备,以便应对可能出现的问题(他们还为整个团队带来了早点)。
这也许算得上整个迁移过程最为紧张的一小时,整个服务出于停机状态,时间在一分一秒地流逝。
其他服务
其他服务的迁移会简单一些,我们可以在迁移的同时创建新的服务,并逐步完成切换。我们可以重用一部分已有的 Puppet 代码,并借机对它们进行清理和简化。
那么我们是如何执行最初的计划的?
总得来说,我们基本是按照最初的计划进行的,尽管曾经有两次偏离了计划。
- 为了更新配置参数,我们在 12 月 15 号重启了 UserStore,确保它们在新的环境中能够正常运行。
- 我们使用了额外的一天时间(12 月 19 号)用于迁移最后的 96 个分片。我们本来可以很快地迁移这些分片,不过最后还是决定采取更安全的方式,为此多花了一天时间。
关于这些变更,我们都有在论坛和社交媒体上与用户进行过沟通。
分片迁移过程中的数据
下图的气泡代表迁移中的用户批次,气泡越大,用户批次就越大。Y 轴表示每分钟迁移的用户数量,X 轴表示批次。不同颜色代表不同的迁移工作日。
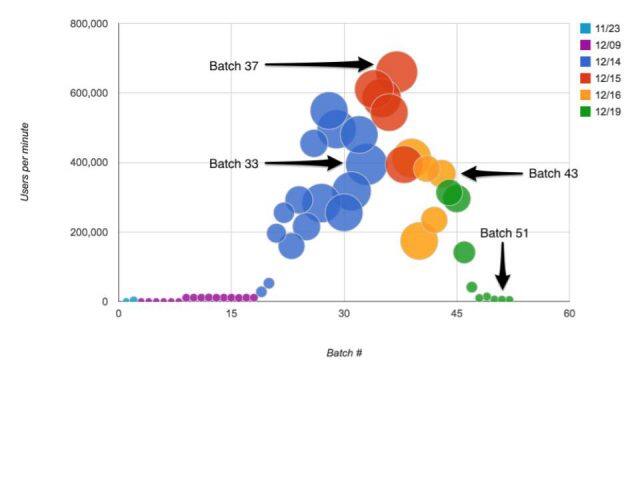
- 11 月 23 号,我们进行尝试性的用户分片迁移,用于确定最终的流程和工具。
- 12 月 8 号,没有迁移分片,因为我们发现了一些代码缺陷需要修复。
- 12 月 9 号,开始小规模的迁移。
- 12 月 14 号,我们开始大踏步,在一天内迁移了 7 千 7 百万个用户。
批次统计
- 最大的一个批次是 33 号,在 24 分钟内迁移了 9,463,546 个用户(每分钟 394,314 个用户)。
- 最快的一个批次是 37 号,在 14 分钟内迁移了 9,244,151 个用户(每分钟 660,297 个用户)。
- 耗费时间最短的一个批次是 43 号,在 11 分钟内迁移了 4,042,851 个用户(每分钟 367,532 个用户)。
- 耗费时间最长的一个批次是 51 号,在 30 分钟内迁移了 147,765 个用户(每分钟 4,926 个用户)。
- 所有用户的服务不可用时间都控制在 30 分钟以内。
第五部分:结论和展望
极度聚焦
为了达成我们的目标,我们尽量排除外界的干扰,避免浪费时间。我们不得不拒绝那些不重要的业务任务,而且要让整个公司都知道我们这样做的理由。我们通过分享会议让其他人了解我们的项目,同时给他们机会提问。
给力的伙伴
在项目开始的时候,我们讨论如何快速地完成迁移,我们希望避免平庸,所以设定了非常高的目标。与我们一起合作的 Google 团队对于我们提出的挑战也毫不畏惧。每次在我们发现可能导致偏离目标的问题时,Google 团队总能站出来一起解决。
为了完成共同的目标,来自两个不同公司的团队在一起合作,这是一件非常有意思的事情。
让事情落地,并尽快完成
传统的思维告诉我们,对于这类迁移,应该从小处着手。某种程度上说,这是对的,不过我们不能完全依照这种说法去做。我们认为我们应该快速完成迁移,并把迁移看作整个环境的组成部分,因为这是让所有潜在问题浮出水面的唯一方法。
从小处着手,或者从非关键路径开始迁移存在一些根本性的问题。
- 规模太小的东西一般不会暴露出什么问题,即使我们尽可能地进行基准测试或负载测试,也无法发现可能会在生产环境发生的问题。它们只会降低我们对安全的防范意识。
- 我们一般不太关注非关键的东西(不太重要的),所以即使出现问题也能接受。这些问题一般得不到修复,一旦进入生产环境就会给我们带来危害。
不过,从小处着手可以帮助我们熟悉新的平台,并做出一些基本的测试。这一步是必须去完成的,不过这并不代表在进入生产环境之后一切能够正常运行。
在迁移过程中,我们尽可能快速地对生产环境服务进行测试。如果我们的系统或应用能够被拆分成组件进行迁移,对于测试来说就非常有利。基于微服务的架构在这方面极具优势,不过对于古老的单体应用来说就非常困难。
简而言之,处在用户关键路径之外的高流量组件是最好的着手点。
自动化
我们尽可能借助自动化加快迁移过程。很多时候,我们使用已有的工具。不过基于一些原因,我们也会自己构建一些工具。
- 在 GCP 里创建实例。我们基于 Google 云部署管理器创建自定义工具,用于创建配置模板,并利用现有的 Puppet 基础设施进行配置管理。
- 我们创建了迁移脚本和整体控制框架,实现了 24/7 的高速文件拷贝。我们有大约 50 亿个用户文件需要拷贝,而每个用户文件又有相关的元数据文件(如缩略图),所以总的文件数量达到 120 亿个。
- 我们创建了基于 Ansible 的工具,用于初始化数据的迁移流程,并实现了分片迁移的完全自动化。
如果不注重自动化,根本不可能在如此短的时间内完成迁移。
打破约束
在制定迁移计划时,我们意识到数据中心和 GCP 之间的网络带宽会对我们造成约束。它不允许我们拷贝大块的数据,也限制了多站点运行能力。
我们知道网络约束会给我们的工作带来多个负面影响。于是在项目早期阶段,我们花了额外的时间和精力最大化站点间的带宽。我们对比了几个云供应商,并最终做出了选择,为我们节省了宝贵的时间。
我们从中学到了什么?
总得来说,我们对迁移过程感到很满意。我们也从中学到了很多。
应用程序可以运行在云端,但是……
云服务的成熟度已经达到一定高度。在大多数情况下,我们的应用可以正常运行在云端。不过,我们仍然需要“调节”我们的应用,因为在云端环境可能会受到一些约束。所以我们要提前做好准备,在迁移之后需要留出“调节”时间。
例如,为了解决磁盘吞吐量受限问题,我们不得不调节我们的运行环境。在我们的数据中心,我们可以尽快地运行备份,因为我们的环境或存储设备没有被共享,所以可以尽情地消耗所有可用的磁盘 IO。但在 GCP 上,我们的自动化备份会让虚拟机的 IO 达到顶峰,从而拖慢了上游应用。后来我们通过限定备份的速率来解决这个问题。
我们还通过调节环境来实现实时迁移。这是Google 后端的一个特性,允许在主机间迁移虚拟机,而且在大多数情况下对用户是不可见的。UserStore 和部分比较活跃的分片因为IO 很高,在进行实时迁移时不太顺畅,即使是一段很短时间的不可用也会造成破坏性的中断。我们通过调节MySQL 和应用来解决这个问题。尽管还不完美,但我们仍然会继续在Google 的协助下不断完善它。
和用户的沟通是关键
我们需要与用户沟通有关迁移维护的事情。我们不希望给用户发送大量的邮件,因为他们很可能不会查看邮件。我们希望通过Evernote 社区论坛和社交媒体就维护问题与用户进行沟通。这种方式确实奏效了,不过还是有一小部分用户因为不知道这些事情而受到了影响。我们希望消除这个问题,所以在未来,我们会考虑使用应用内置的方式与用户进行沟通。
总结
在新的环境里,我们总不可避免地会遇到各种小问题。有些问题还比较棘手,不过通过调整已有的配置,并与Google 团队展开通力合作,这些问题最终都得到了解决。
现在的状态
我们完成了整个迁移,现在可以展望下未来。我们之所以要迁移到云端,是为了让我们的工程流程更加顺畅,让我们的工程师可以使用更多的构建工具。我们知道,随着时间推移,我们将会逐渐远离虚拟机,并逐步拥抱容器和无服务器技术,从而把精力聚焦在重要的事情上。
初见成效
Evernote Hack Week
Evernote 每年都会有一个 Hack Week(一般在 1 月份)。对于公司里的每一个人来说,这是一个展示他们创造性想法的好机会。人们爆棚的创造力给我们带来惊喜,团队和想法在自由的环境里自主成形。
在过去,我们的运营团队会花时间来支持这个活动,他们需要为活动提供服务器和其他东西。不过今年很不一样,我们给了工程师单独的 GCP 项目访问权限,并让他们自由发挥。他们可以轻松地为自己的项目配置基础服务,尽可能少给运营同事增加负担,这样运营同事们就可以专注于迁移工作。
微服务平台
我们在去年还决定了要把我们的单体架构迁移到微服务架构,而使用容器是完成这个目标的第一步。我们做了很多调研,最终选择 Kubernetes 作为编排框架。运行生产级别的 Kubernetes 集群是一个艰巨的任务,所幸的是, Google Container Engine (GKE)简化了整个流程。
现在,我们在生产环境运行了一个 GKE 集群,为我们的下一代搜索基础设施提供支持。我们会在另一篇文章中详细介绍这方面的内容。
无服务器的未来
尽管我们对当前的架构进行了改进,为了能够运行 Evernote 的代码,仍然有上千个操作系统需要安装。理想情况下,我们应该只负责部署代码,然后让 Google 负责运行这些代码。
也就是说,我们只要负责使用计算能力来处理用户请求。不过我们还有很长的路要走,我们正在尝试使用 Google Cloud Functions 作为我们的核心构建块,这样我们就可以专注在用户代码和特性的开发上。
如何为云项目命名?
每个伟大的项目都需要一个名字。经过深思熟虑之后,我们从两个备选方案中选出一个作为项目的名称。我们的软件工程团队提议把这个项目叫作“Cloudy Meatballs”,其灵感源于 Judi Barrett 的著作《天降美食》(Cloudy with a Chance of Meatballs)。我们的运营团队则提议“Bob Ross”,源于著名的艺术家和电视名人 Bob Ross,他能够画出蓬松的云彩。最后我们通过整个公司的投票来决定,“Bob Ross”胜出。
查看英文原文: Cloud Migration

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论