
信息检索中经常出现的一个问题是查找相似的文本片段。正如我们在之前的文章中所描述的(一个新的搜索引擎以及从头构建一个搜索引擎),查询是 Cliqz 的一个重要构建块。在这种情况下,查询可以是用户生成的查询(即用户输入到搜索引擎中的文本片段),也可以是我们生成的合成查询。一个常见的用例是,我们希望将输入查询与索引中已有的其他查询进行匹配。在这篇文章中,我们将看到我们如何能够构建一个系统,在不投入(我们没有)大量服务器基础设施资金的情况下,使用数十亿查询解决这个任务。
正文
本文最初发布于 Clipz 技术博客,由 InfoQ 中文站翻译并分享。
信息检索中经常出现的一个问题是查找相似的文本片段。正如我们在之前的文章中所描述的(一个新的搜索引擎以及从头构建一个搜索引擎),查询是 Cliqz 的一个重要构建块。在这种情况下,查询可以是用户生成的查询(即用户输入到搜索引擎中的文本片段),也可以是我们生成的合成查询。一个常见的用例是,我们希望将输入查询与索引中已有的其他查询进行匹配。在这篇文章中,我们将看到我们如何能够构建一个系统,在不投入(我们没有)大量服务器基础设施资金的情况下,使用数十亿查询解决这个任务。
我们首先对这个问题下个形式化的定义:
对于特定的查询集合 Q、输入查询 q、整数 k,找出一个子集 R={q0,q1,…,qk}⊂Q,其中,qi∈R 与 q 的相似度比 Q∖R 中的任何查询都高。
例如下面这个 Q 的子集:
k=3,我们可能会得到以下结果:
请注意,我们还没有定义相似。在这种情况下,它几乎可以表示任何意思,但它通常归结为某种形式的关键字或基于向量的相似性。使用基于关键字的相似度,如果两个查询有足够多的相同词汇,我们可以认为它们是相似的。例如,opening a restaurant in munich 和 best restaurant of munich 这两个查询是相似的,因为它们共享 restaurant 和 munich 这两个词,而 best restaurant of munich 和 where to eat in munich 这两个查询则不太相似,因为它们只共享一个词。然而,对于在慕尼黑寻找餐馆的人,如果认为第二组查询相似,他们可能会得到更好的服务。这就是基于向量的匹配发挥作用的地方。
将文本嵌入到向量空间
词嵌入是自然语言处理中的一种机器学习技术,用于将文本或单词映射成向量。通过将问题移到向量空间中,我们可以使用数学运算,例如对向量求和或计算距离。我们甚至可以使用传统的向量聚类技术将相似的单词链接在一起。这些操作的意思在原来的单词空间中不一定那么明显,但好处是,我们现在有丰富的数学工具可以使用。要了解更多关于单词向量及其应用的信息,感兴趣的读者可以看下word2vec或GloVe。
一旦我们有了从单词生成向量的方法,下一步就是将它们组合成文本向量(也称为文档或句子向量)。一种简单而常见的方法是对文本中所有单词的向量求和(或求平均值)。
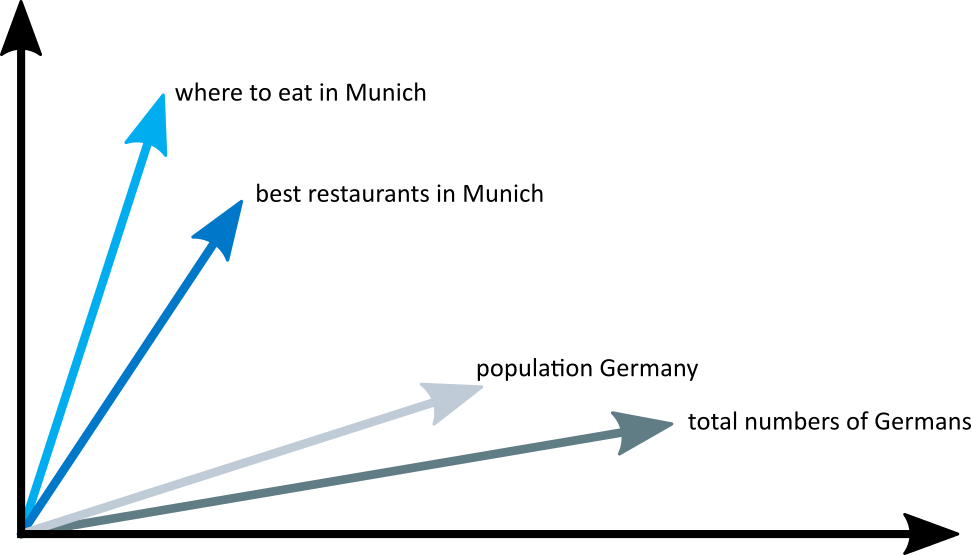
图 1:查询向量
我们可以通过将两个文本片段(或查询)映射到向量空间并计算向量之间的距离来确定它们有多相似。一个常见的选择是使用角距离。
总而言之,词嵌入允许我们做一种不同类型的文本匹配,以补充上面提到的基于关键字的匹配。我们能够以一种以前不可能的方式探索查询之间的语义相似性(例如,best restaurant of munich 和 where to eat in munich)。
近似最近邻搜索
我们现在准备将我们的初始查询匹配问题简化为以下问题:
对于特定的查询向量集 Q、向量 q 和整数 k,找出一个向量子集 R={q0,q1,…,qk}⊂Q,使得从 q
到 qi∈R 的角距离小于到 Q∖R 中向量的角距离.
这被称为最近邻问题,有很多算法可以快速解决低维空间的最近邻问题。另一方面,使用词嵌入,我们通常使用高维向量(100-1000 维)。在这种情况下,精确的方法会崩溃。
在高维空间中,没有快速获取最近邻的可行方法。为了克服这个问题,我们将通过允许近似结果使问题变得更简单,也就是说,不要求算法总是精确地返回最近的向量,我们接受只得到部分最近的邻居或稍微接近的邻居。我们称之为近似近邻(ANN)问题,这是一个活跃的研究领域。
分层可导航小世界图
分层可导航小世界图(Hierarchical Navigable Small-World graph),简称 HNSW,是一种快速的近似近邻搜索算法。HNSW 中的搜索索引是一个多层结构,每一层都是一个邻近图。图中的每个节点都对应于一个查询向量。
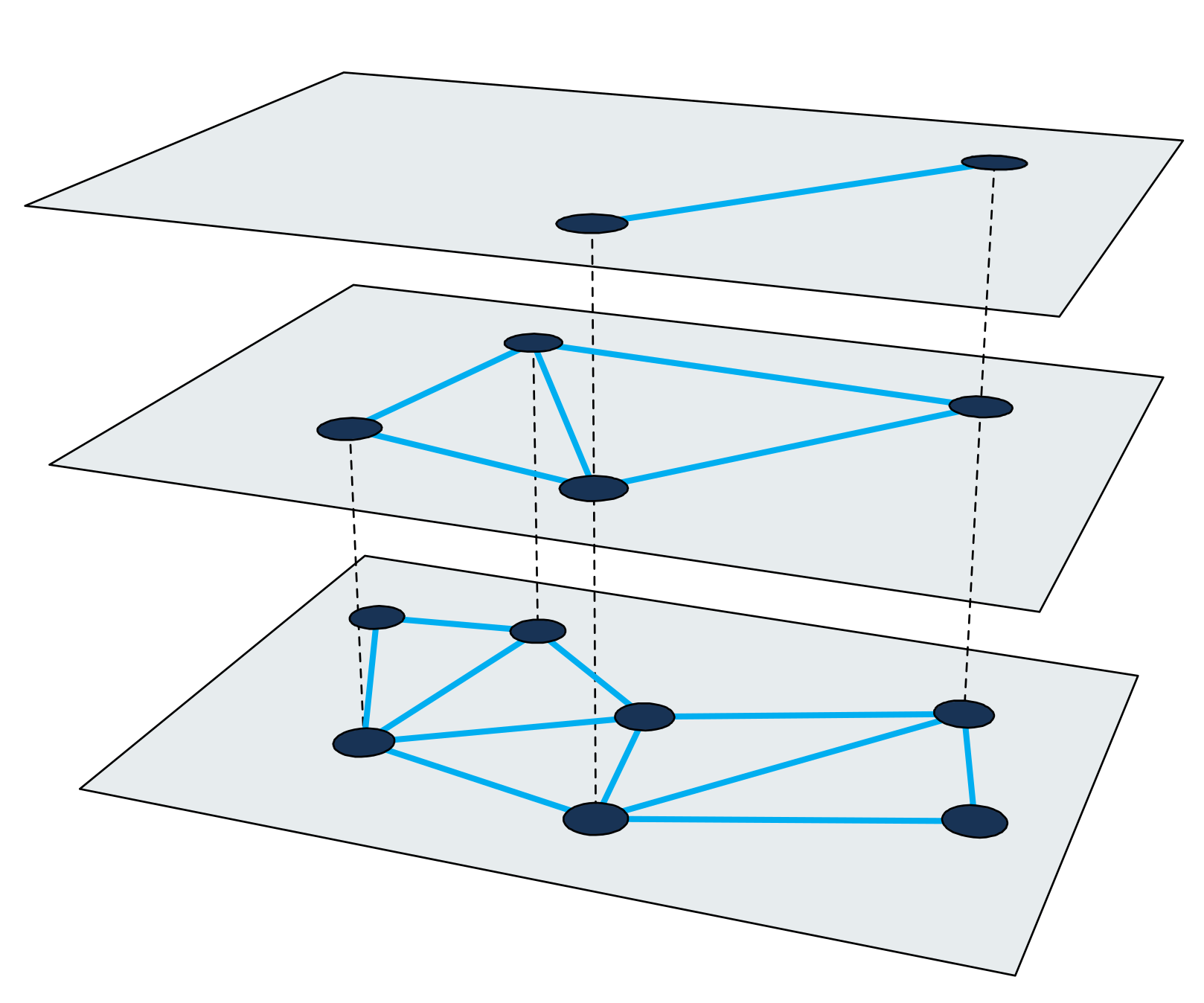
图 2:多层邻近图
在 HNSW 中,最近邻搜索使用放大方法。它从最上层的一个入口节点开始,在每一层上递归执行贪婪图遍历,直到到达最下层的局部最小值。
关于算法的内部工作原理以及如何构造搜索索引的细节在论文中有详细描述。重要的是,每个最近邻搜索都包含一个图遍历,需要访问图中的节点并计算向量之间的距离。下面几节将概述使用此方法在 Cliqz 构建大型索引所采取的步骤。
索引数十亿查询面临的挑战
我们假设目标是索引 40 亿个 200 维的查询向量,其中每一维由一个4字节的浮点数表示。一个粗略的计算告诉我们,向量的大小大约是 3TB。由于许多现有的 ANN 库都是基于内存的,这意味着我们需要一个非常大的服务器来将向量放入 RAM 中。注意,这个大小不包括大多数方法中需要的额外搜索索引。
纵观我们的搜索引擎历史,我们有几种不同的方法来解决这个大小问题。让我们回顾一下其中的几个。
数据子集
第一个也是最简单的方法,它并没有真正地解决问题,就是限制索引中向量的数量。仅使用所有可用数据的十分之一,与包含所有数据的索引相比,我们可以构建只需要 10%内存的索引,这并不奇怪。这种方法的缺点是搜索质量受到影响,因为可供匹配的查询更少。
量化
第二种方法是包含所有数据,但通过量化使其变小。通过允许一些舍入错误,我们可以将原始向量中每一个 4 字节的浮点数替换为量化后的 1 字节版本。这可以将向量所需的 RAM 减少 75%。尽管如此,我们仍然需要在 RAM 中容纳 750GB(仍然忽略索引结构本身的大小)的数据,这仍然需要使用非常大的服务器。
使用 Granne 解决内存问题
上述方法确实有其优点,但在成本效率和质量上存在不足。即使有 ANN 库在不到1毫秒的时间内内产生合理的召回率,但对于我们的用例,我们可以接受牺牲一些速度来降低服务器成本。
Granne(基于图的近似近邻)是一个基于 HNSW 的库,Cliqz 开发并使用它来查找类似的查询。它是开源的,仍在积极开发中。一个改进版本正在开发中,并将于 2020 年在crates.io上发布。它是用 Rust 编写的,提供了 Python 语言绑定。它针对数十亿个向量进行设计,并充分考虑了并发。更有趣的是,在查询向量上下文中,Granne 有一个特殊的模式,它使用的内存比前面那些库少得多。
查询向量的压缩表示形式
减少查询向量本身的大小将带来最大的好处。为此,我们必须后退一步,首先考虑如何创建查询向量。因为我们的查询由单词组成,而我们的查询向量是词向量的和,所以我们可以避免直接存储查询向量,而是在需要时计算它们。
我们可以将查询存储为一组单词,并使用查询表查找对应的词向量。但是,为了避免间接取值,我们将每个查询存储为一个整数 id 列表,其中的每个 id 对应查询中的一个词向量。例如,我们将查询 best restaurant of munich 存储为:
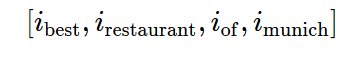
其中,i_{\mathrm{best}}是 best 的词向量的 id,以此类推。假设我们有不到 1600 万个词向量(再多的话就要付出每个词 1 字节的代价),我们可以用 3 个字节表示每个单词的 id。因此,我们不用存储 800 字节(或 200 字节的量化向量),我们只需要为这个查询存储12个字节。
关于词向量:我们仍然需要它们。然而,通过组合这些单词可以创建的查询要比这些词多得多。由于它们与查询相比非常少,所以它们的大小没有那么重要。通过将词向量的 4 字节浮点版本存储在一个简单的数组 v 中,每百万个词向量的大小不足 1GB,可以很容易地存储在 RAM 中。由此可以得出,上例中的查询向量为:
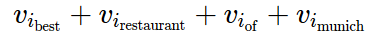
查询表示的最终大小自然取决于所有查询中单词组合的数量,但是对于我们的 40 亿个查询,总大小最终约为 80GB(包括词向量)。换句话说,我们看到,与原始查询向量相比大小减少了 97%以上,或者与量化向量相比减少了 90%左右。
还有一个问题需要解决。对于单个搜索,我们需要访问图中的大约 200 到 300 个节点。每个节点有 20 到 30 个邻居。因此,我们需要计算从输入查询向量到索引中的 4000 到 9000 个向量的距离,而在此之前,我们需要生成这些向量。动态创建查询向量的时间代价是否过高?
事实证明,使用一个相当新的 CPU,它可以在几毫秒内完成。对于之前花费 1 毫秒的查询,我们现在需要大约 5 毫秒。但与此同时,我们正在将向量的 RAM 使用量减少 90%——我们很乐意接受这种折衷。
内存映射向量和索引
到目前为止,我们只关注向量的内存占用。然而,在上述显著的大小缩减之后,限制因素变成了索引结构本身,因此我们也需要考虑它的内存需求。
Granne 中的图结构被紧凑地存储为每个节点具有可变数量邻居的邻接表。因此,在元数据存储上几乎不会浪费空间。索引结构的大小在很大程度上取决于结构参数和图的属性。尽管如此,为了了解索引大小,我们可以为 40 亿个向量构建一个可用的索引,其总大小大约为 240GB。这在大型服务器上的内存里使用是可能的,但实际上我们可以做得更好。
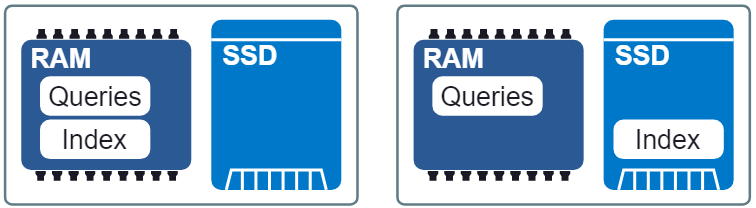
图 3:两种不同的 RAM/SSD 布局配置
Granne 的一个重要特性是它能够将索引和查询向量进行内存映射。这使我们能够延迟加载索引并在进程之间共享内存。索引和查询文件实际上被分割成单独的内存映射文件,可以与不同的 SSD/RAM 布局配置一起使用。如果延迟要求不那么严格,那么可以将索引文件放在 SSD 上,将查询文件放在 RAM 中,这仍然可以获得合理的查询速度,而且不需要付出过多的 RAM。在这篇文章的最后,我们将看到这种权衡的结果。
提高数据局部性
在我们当前的配置中,索引放置在 SSD 上,每次搜索需要对 SSD 进行 200 到 300 次读取操作。我们可以尝试对元素相近的向量进行排序,从而增加数据的局部性,进而使它们的 HNSW 节点在索引中也紧密地排列在一起。数据局部性提高了性能,因为单个读取操作(通常获取 4KB 或更多)更可能包含图遍历所需的其他节点。这反过来减少了我们在一次搜索中需要获取数据的次数。

图 4:数据局部性减少了取数次数
应该注意的是,重新排列元素并不会改变结果,而仅仅是加速搜索的一种方法。这意味着任何顺序都可以,但并不是所有的顺序都会加快速度。很可能很难找到最优的排序。然而,我们成功使用的一种启发式方法是根据每个查询中最重要的单词对查询进行排序。
小结
在 Cliqz,我们使用 Granne 来构建和维护一个数十亿的查询向量索引,用相对较低的内存需求实现了相似查询搜索。表 1 总结了不同方法的需求。应该对搜索延迟的绝对数值持保留态度,因为它们高度依赖于可接受的召回率,但是它们至少可以让你对这些方法之间的相对性能有个大概的了解。
表 1:不同设置下的延迟需求对比
我们想指出的是,这篇文章中提到的一些优化,并不适用于具有不可分解向量的一般近邻问题。但是,它可以适用于任何元素可以由更小数量的块(例如查询和单词)生成的情况。如果不是这样,那么仍然可以对原始向量使用 Granne;它只是需要更多的内存,就像其他库一样。
英文原文:
Indexing Billions of Text Vectors

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论