

1.引言
随着各种深度学习方法的快速发展,基于神经网络的预测模型渐渐成为了主流,深度神经网络能够反应特征的高阶非线性变化,同时具有极强的参数训练和拟合能力,但是深度神经网络受参数的影响大,需要大量的实际数据,所以深度学习模型一般适用于大规模场景[1]。这些模型与以往的模型相比性能获得了巨大的提升,但仍然存在着一些问题。当神经网络的输入中包含高维离散型特征时,我们通常会将特征的值转换为低维稠密的向量,然后再与连续型特征拼接,共同输入到网络。当模型在预测时出现之前较少出现或从未出现的值,就可能导致过度泛化的问题,而且在部分场景如点击率预估中,输入的特征一般为大规模稀疏矩阵,如何对输入进行有效表达就成了深度学习在点击率预估中应用的关键所在。
01 深度广度模型提出
谷歌公司于 2016 年提出了宽深度模型(Wide&Deep)去解决上述问题, 该模型分为宽度(Wide)和深度(Deep)两部分[2]。宽度部分由传统的机器学习算法组成,更注重特征的低阶交互的模拟,具有“记忆性”;而深度部分相当于由多层神经网络组成,更注重特征间的高阶交互,具有“泛化性”。宽深度模型的提出具有重大意义,虽然直接在它上面的改动不多,但是它提出的宽度和深度模型融合成为了之后新模型中的主流思想。
02 深度广度模型的演化与应用
许多模型均是在宽深度模型的架构上演变而来。例如 PNN(Product-based Neural Network)模型设计了 Product 层对特征进行更细致的交叉运算[3]。Deep-FM 模型在华为应用商城上得到了非常好的实践,该模型可以看作是宽深度模型思想的继承,它的宽度部分是 FM 模型,深度部分是一个普通的 DNN 网络[4]。FM 模型进行 embedding 得到 Dense embeddings 的输出,将 Dense embeddings 的结果作为左边 FM 模块和右边 DNN 模块的输入。通过一定方式组合后,模型左边 FM 模块的输出完全模拟出了 FM 的效果,而右边的 DNN 模块则学到了比 FM 模块更加高阶的特征交叉,两者共享参数,共同训练,最终将两部分的输出结合共同预测。此外,Deep&Cross 模型从嵌入和堆积层开始,分成了两个部分,一个交叉网络和一个与之平行的深度网络,并在最后形成组合层,结合了两个网络的输出,并取得了不错的效果[5]。京东公司的研究者在推荐领域运用的强化学习方法也为点击率预估领域提供了新的思路,通过构造线上环境模拟器,对线下的模型进行评估,以应对线上线下环境不一致等问题[6]。
2.Wide & Deep 模型概述
Wide&Deep 是一种融合浅层模型(Wide)和深层模型(Deep)进行联合训练的框架,综合利用浅层模型的记忆能力和深层模型的泛化能力,实现单模型对推荐系统准确性和多样性的兼顾。模型框架如图 1 所示。
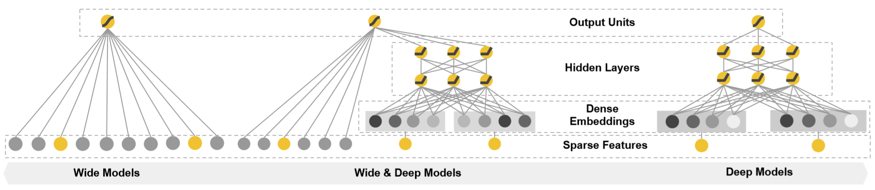
图 1 Wide&Deep 模型框架
Wide&Deep 模型的思想来源是,模仿人脑有不断记忆并且泛化的过程,将线性模型(用于记忆)和深度神经网络模型(用于泛化)相结合,汲取各自优势,从而达到整体效果的最优。
01 Wide 部分
Wide 部分的作用是让模型具有较强的“记忆能力”。“记忆能力”可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。一般来说,协同过滤、逻辑回归等简单模型有较强的“记忆能力”。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产生类似于“如果点击过 A,就推荐 B”这类规则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。这部分就是我们熟知的 LR 线性模型,这部分主要用作学习样本中特征的共现性,达到“记忆”的目的。该模型的表达式如下:
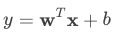
其中, y 是预估值, x 表示特征向量, w 为模型参数, b 是偏置项。
Wide 特征集合包括原始特征和转换后的特征,其中交叉特征在 Wide 部分十分重要,能够捕捉到特征间的交互,因此通常会对稀疏的特征进行交叉特征转换,定义如下:
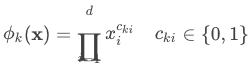
其中 cki 是一个布尔变量,当第 i 个特征是第 k 个转换 φk 的一部分时为 1,否则为 0。因此,通过特征之间的交叉变换,便捕获了二元特征之间的相关性,为广义线性模型增加了非线性。
02 Deep 部分
Deep 的主要作用是让模型具有“泛化能力”。“泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。深度神经网络通过特征的多次自动组合,可以深度发掘数据中潜在的模式,即使是非常稀疏的特征向量输入,也能得到较稳定平滑的推荐概率,这就是简单模型所缺乏的“泛化能力”部分。它是一个前馈神经网络,在训练过程中通过优化损失函数不断迭代更新,每个隐藏层执行下面的运算:
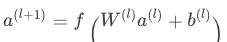
其中 l 是隐层的标号; f 是激活函数。
03 Wide 部分和 Deep 部分的结合
Wide 的部分和 Deep 的部分使用其输出对数几率的加权和作为预测,然后将其输入到联合训练的一个共同的逻辑损失函数,通过使用小批量随机优化同时将输出的梯度反向传播到模型的 Wide 和 Deep 部分来完成的。单层的 Wide 部分善于处理大量稀疏的 id 类特征;Deep 部分利用神经网络表达能力强的特点,进行深层的特征交叉,挖掘藏在特征背后的数据模式。这个联合模型如图 1 所示。对于逻辑回归问题,模型的预测是:
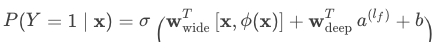
其中,Y 是二值分类标签, σ(.) 是 sigmoid 函数, φ(x) 是原始特征 x 的跨特征变换, b 是偏置项, wwide 是 wide 模型的权重向量, wdeep 是用于最终激活函数 α(lf) 的权重。
3.Wide&Deep 模型在贝壳用户购房意愿量化的应用
01 背景
贝壳找房作为技术驱动的品质居住服务平台,业务中涉及到用户购房意愿强度识别的场景,更精准地去描述用户购房意愿强度是我们需要长期优化的问题。在场景应用中很大一部分需要对用户在不同城市的行为去实施不同的策略,而且基于统计分析得出,不同城市的商机等转化率是存在明显差异的,偏好不同的用户的转化率也存在较大差异。在原有的模型中,并未引入这些特征,采用的是一些行为在各个业务线上通过不同算子进行聚合得到的特征去进行建模,但是在分城市的场景建模的过程中,会涉及到城市特征,用户的不同偏好等多维离散特征的引入,并且在类别属性组合的时候,会存在高维稀疏输入,传统基于树的模型并不能很好地处理此类输入。因此我们选择了深度广度学习模型以更好的对该场景进行建模。
02 问题抽象
房产场景购房意愿强度的识别,预测用户未来是否会发生关键行为如签约成交,优化目标定义为 top x%的准确性,该任务的核心问题包括特征处理与模型选择两部分,下面我们展开介绍。
03 特征处理
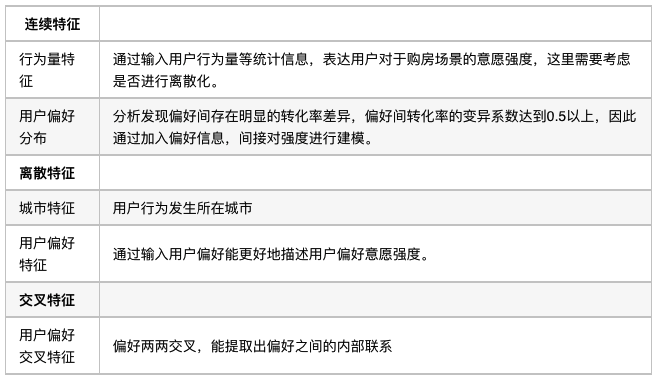
特征工程主要包括特征构建,特征分析,特征处理以及特征选择等。我们把特征分为三类,用户行为量特征,用户偏好特征,偏好交叉特征,接下来对特征处理进行详细说明。
低频过滤:对于超高维稀疏特征,可以考虑基于频率角度或基于业务先验证,进行筛选截取,以一定程度上降低输入样本量。从另一方面考虑,在叠加正则化的情况下,过于低频的特征往往也会被降权或忽略。
行为量的时间体现:对用户的各个行为量进行近一天,近两天,近五天,近一周,近两周,近三周,近一个月,近两个月等时间上的聚合。
归一化处理:我们对取值范围较大的连续值特征使用了最大最小归一化方法,将特征值都转化为 0-1 之间的数值。该方法能够使得特征拥有统一量纲,并且将数据归一化到 0 到 1 之间的数据,能够加快模型的训练速度,实验也证明模型效果确实有显著提升。
04 Wide 部分设计
特征设计
由于广度部分主要负责记忆功能,因此需要输入线性或近似线性的特征,同时需要人工进行交叉等特征工程,对离散特征进行 one-hot 之后得到原始特征和交叉积特征,和连续特征一起输入到 Wide 结构中。Wide 部分的特征设计主要分为连续特征,离散特征和交叉特征。
模型设计
Wide 部分我们选择 FTRL(Follow-the-regularized-leader)+ L1 正则化来进行训练,Wide 部分结构图如图 2 左所示。
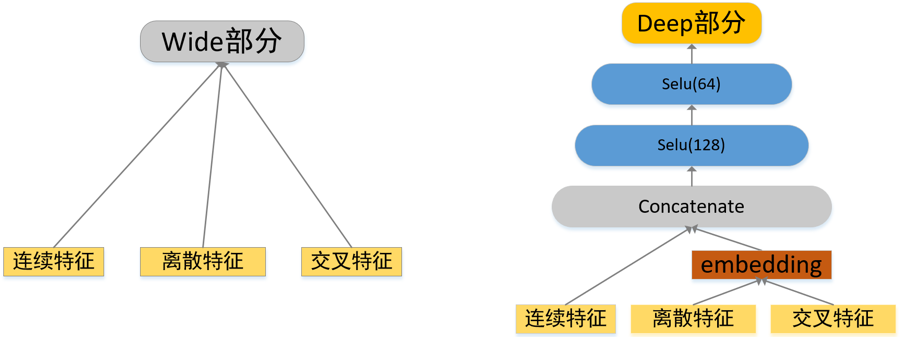
图 2 Wide 部分和 Deep 部分示意图
05 Deep 部分设计
特征设计
深度部分负责深度特征提取与高维稀疏特征的理解。因此 Deep 部分的特征设计主要分为连续特征,离散特征 embedding 和交叉特征 embedding[7]。
模型设计
Deep 部分采用的是两层 128->64 的 Selu 激活的 MLP 网络结构,batch_size 选用的是 4096,模型示意图如图 2 右所示。对离散特征和交叉特征进行 embedding 之后和连续特征一起输入到 Deep 网络中进行训练。
06 模型离线训练
经过上述的特征工程与模型设计,生成了训练集,作为 Wide & Deep 的训练样本,使用的模型结构如图 3 所示。
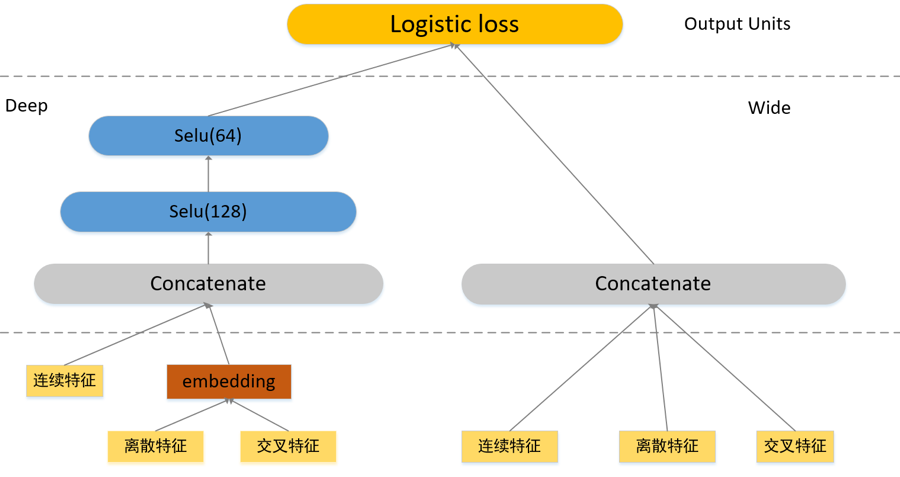
图 3 Wide&Deep 示意图
图中的 Hidden Layers 为两个全连接层,每个 layer 后面连接 Selu 激活函数,训练过程中,采用联合训练的方式,将 Wide 和 Deep 模型组合在一起,在训练时同时优化所有参数,并且在训练时进行加权求和,根据最终的 loss 计算出 gradient,反向传播到 Wide 和 Deep 两部分中。
07 实验结果与分析
模型训练后,需要将它进行预测,并对结果进行评价,评价指标我们选择了 topx%上的准确性,这是因为正负样本比例不平衡,关注整体的 auc 和准确率没有意义,所以选择了 topx%的准确率,分母一致的前提下,召回的 label 量越多,准确率越高,目前得到的实验结果与树模型相比在 topx%上的准确率相对提升 31.6%。
4.更好地平衡模型复杂度和表示能力
01 思考:模型复杂度和表示能力增强的博弈
在训练期间,Deep 侧的输入,在加入交叉特征的 embedding 之后,模型收敛变慢且不稳定,效果并没有提升,而在不把 cross feature 放入 Deep 时,提升比较明显,是由于模型对这部分特征没有学到很好的表达,无法发挥出 embedding 的优势。引入了新的信息,也增加了模型的复杂度,进而导致负向影响,因此我们决定对部分高维特征进行预训练(pre-train)的方式先对小区,商圈以及偏好组合进行 embedding,然后将得到的低维稠密向量作为连续特征输入到 Wide&Deep 模型中。
02 用预训练调和模型复杂度与表示能力
为此构造的数据集是有 N 个用户的点击会话序列组成, s=(L1,…,Ln)∈S 定义为一个用户点击的 n 个房源 id 组成的不间断序列,只要用户连续两次点击之间的时间超过 20 分钟就认为是一个新的会话。通过此序列来训练出一个 32 的实值向量来标识平台上的所有房源。
通过借鉴 Airbnb 的嵌入训练方法来对用户点击房源序列进行学习,采用滑动窗口的方式读取点击会话,通过随机梯度下降的方法更新。在每一步中,都会更新中心房源的向量并将其推正向相关的其他房源,如图 4 所示,并且我们采用同样的方法来进行偏好交叉特征的训练[7]。
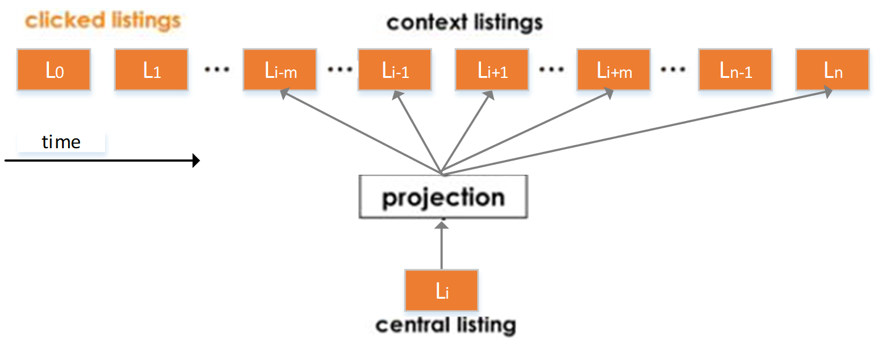
图 4 pre-train 房源嵌入训练示意图
那么网络结构更新如图 5 所示:
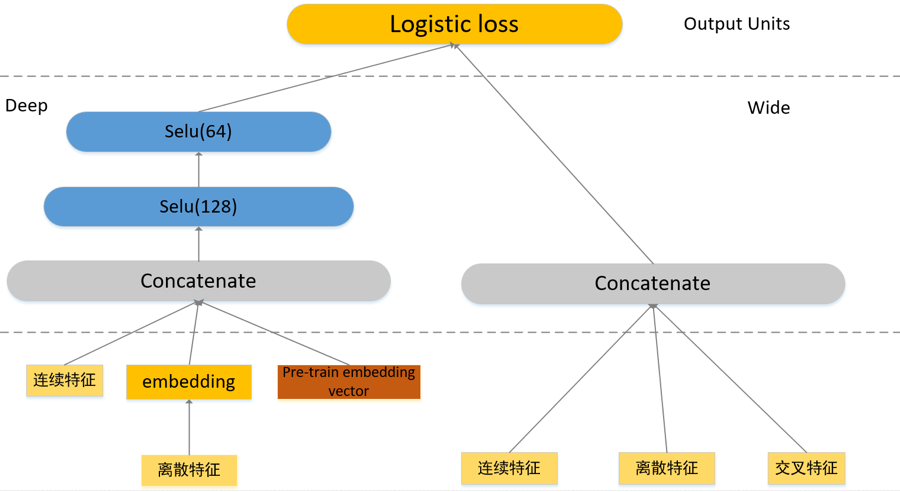
图 5 模型迭代后的示意图
03 实验结果与分析
为了防止模型过拟合,加入了 dropout;为了加快模型的收敛,引入了 Batch Normalization(BN);并且为了保证模型训练的稳定性和收敛性,尝试不同的 learning rate(deep 侧 0.01 效果较好)和 batch_size(目前设置的 4096);在激活函数的选择上,我们对比了 Selu、Relu、Prelu 等激活函数,最终选择了效果最好的 Selu。实验证明,通过参数的调整,能够明显的影响模型的训练效果。更新之后,网络收敛速度加快,减小了模型的复杂度,表达能力增强,提高了在 topx%的准确率。
5.力更好地表达用户行为-序列引入
01 再思考:时序表达我们学会了吗?
在探索新的特征的过程中,我们发现引入用户在时序上的行为量差特征会对模型后验效果有一定的提升,而且用户行为本身就是时间序列,前期我们是通过固定的时间窗口把问题简化进行模型训练,过程中会丢失一部分的信息,Wide &Deep 模型针对用户购房意愿量化的应用场景下,无需考虑模型对时间序列信息的表达问题,故对于时序问题的信息表达有所欠缺,所以我们在 Wide&Deep 的基础上引入 GRU 去更好的提取用户的时序特征,来进一步提升模型的准确率,进而给业务场景的应用带来进一步的提升。
02 GRU 时序模型
GRU 模型只有两个 gate,一个是 reset gate,也就是多大程度上擦除以前的状态 state,一个是 update gate,update gate 的作用类似于 input gate 和 forget gate,它的作用是多大程度上要用 candidate 来更新当前的 hidden layer,(1-z)相当于 input gate,z 相当于 forget gate,同样还混合了 cell 状态和隐藏状态,比标准 LSTM 简单,参数更少,比较容易训练[8]。模型结构如图 6 所示。
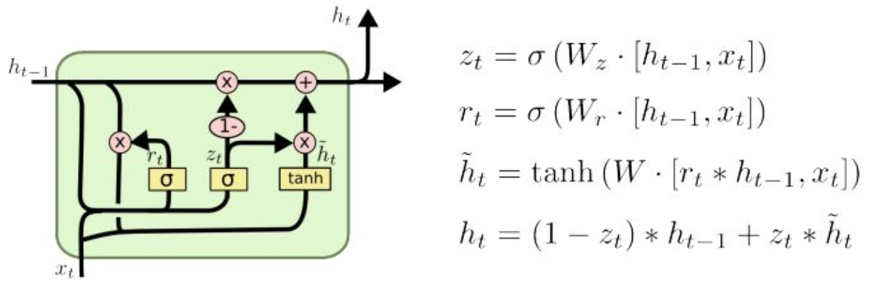
图 6 GRU 的示意图
特征设计
GRU+Wide & Deep 特征增加了时序模型的特征,通过用户行为量去提取时序特征,更好地表达用户随着时间的行为轨迹的变化。

模型设计
时序模型选择 GRU(64->32),Dense 层的激活函数选择 selu,优化器选择 adam,loss 选择 binary_crossentropy,整体的网络结构如图 7 所示。
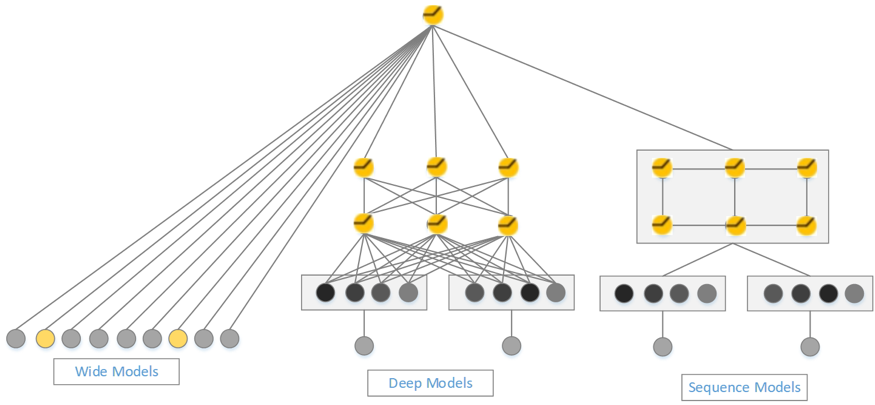
图 7 GRU+Wide & Deep 示意图
03 实验结果与分析
将 GRU 部分,Wide 部分和 Deep 部分一起加入到 loss 中进行模型训练,效果有了明显的提升,并且我们还尝试将 GRU 部分加入到 Deep 中进行训练等其他方法,大家可以自由发挥。
6.总结和展望
本文主要介绍了深度广度模型在用户价值量化上的应用,包括 wide&deep 的应用与迭代,端到端与预训练的讨论以及时序模型与深度广度模型的结合,在预测结果上也取得了较为明显的正向收益,提高了头部准确率。
目前我们正在进行模型的进一步优化,不断总结和尝试。例如从注意力角度着手,更好的学习用户的兴趣和行为量表达,进而优化价值判断精度,有相关进展,会在评论区做更新。
7.参考文献
[1] Bobadilla J, Ortega F, Hernando A, et al. Recommender systems survey[J]. Knowledge Based Systems, 2013, 46(1):109-132.
[2] Cheng H, Koc L, Harmsen J, et al. Wide & Deep Learning for Recommender Systems[J]. conference on recommender systems, 2016: 7-10.
[3] Qu Y, Han C, Kan R, et al. Product-Based Neural Networks for User Response Prediction[C]// IEEE International Conference on Data Mining. 2017.
[4] Guo H, Tang R, Ye Y, et al. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction[J]. international joint conference on artificial intelligence, 2017:1725-1731.
[5] Wang R, Fu B, Fu G, et al. Deep & Cross Network for Ad Click Predictions[J]. knowledge discovery and data mining, 2017.
[6] Zhao X, Zhang L, Ding Z, et al. Deep Reinforcement Learning for List-wise Recommendations.[J]. arXiv: Learning, 2018.
[7] Grbovic M , Cheng H . Real-time Personalization using Embeddings for Search Ranking at Airbnb[C]// 2018:311-320.
[8] Chung J , Gulcehre C , Cho K H , et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[J]. Eprint Arxiv, 2014.
本文转载自公众号贝壳产品技术(ID:beikeTC)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...












评论