
讲述 Yelp 工程师如何协调其流量故障转移流程,并在可靠性、性能和成本效率之间实现微妙平衡的故事。
表面上看,这是很简单明了的流程:Yelp 的站点可靠性工程师有时会转移流量,以防止出现面向用户的错误。但是在幕后,这一流程涉及生产系统、基础架构团队以及成百上千开发人员和他们负责服务之间的复杂编排。这篇文章讲述的就是 Yelp 的生产工程和计算基础架构团队如何实现故障转移策略,在可靠性、性能和成本效率之间找到平衡的故事。
什么是流量故障转移?
Yelp 通过位于美国东西海岸的两个 AWS 区域数据中心来服务请求。大部分用户流量都是只读请求,它们被发送到最近的数据中心,并带有附加的逻辑以确保负载在两个区域之间平均分配。有时,一个区域会由于基础架构配置不正确、关键数据存储受损或(极少数情况下)AWS 自身的问题而变得不健康;当其中任何一种情况发生时,我们可能会向用户返回 HTTP 500 错误,于是需要迅速采取补救行动。
为缓解此类故障,Yelp 可以使用的一种工具是故障转移:它能将流量从不健康的区域快速转移到健康的区域。流量部分转移可以缓解故障系统上的压力并为其留出恢复的空间。流量也可以全部转移:也就是完整故障转移。转移流量时,我们需要做的就是更新一个由 Git 控制的 YAML 文件。但即使在紧急情况下,合并和推送更改也需要审核,通常需要二级待命生产工程师、一位经理,或一位参与当前事件的工程师来批准。

流量管理配置文件的摘录
Yelp 的待命工程师会定期演习部分和完整故障转移,以确保我们的基础架构能够应对负载的突然变化,且我们的团队随时都可以轻松执行这一流程。虽说故障转移本身不过是一个简单的配置更改,但需要完整转移的情况往往压力巨大且难以预测。主力待命工程师需要熟悉这个流程,以免造成额外的压力。
故障转移失效时
流量模式的重大变化可能会压垮正在为全球流量服务的健康区域。在 Yelp 的早年间,我们经常会将超量流量太快发送到一个健康区域,结果把这个区域“融化”掉。只要所有系统都能按预期正常工作的话,我们的大多数服务和机器集群都可以在几分钟之内完成规模扩展,但我们连这几分钟都没法等,因为它们太关键了。我们的响应必须在瞬间起效。
此外,在一个不断发展的基础架构中,向生产环境增加容量可能是很复杂的事情——最近的一项低级配置更改可能会减慢甚至阻止我们获得新的健康机器。这可能会迅速演变成最坏的情况,也就是我们无法扩展健康区域,最后只能向用户返回 HTTP 500 错误。
维持双倍容量
防止崩溃的一种好办法就是一直保持额外的计算能力。
要做到这一点,一种途径就是准备更多的可用机器。只要将运行中的计算机数量加倍,我们就能一直具备处理故障转移所需的计算容量。这也意味着我们无需在紧急情况下添加机器,从而减少了故障转移流程中的一个步骤,更重要的是减少了配置这些实例时出错的可能性,进而减轻了对计算基础架构团队的依赖。
但是,就为了故障转移就在平时准备很多闲置的机器看起来是在浪费资源,因此我们会把所需的容器分配到所有可用的机器之间。这样,每台机器在正常情况下只会将其计算资源的 50%分配给各种服务,这样它们就能应对负载峰值,并保持更一致的性能——并且成本是一样的。
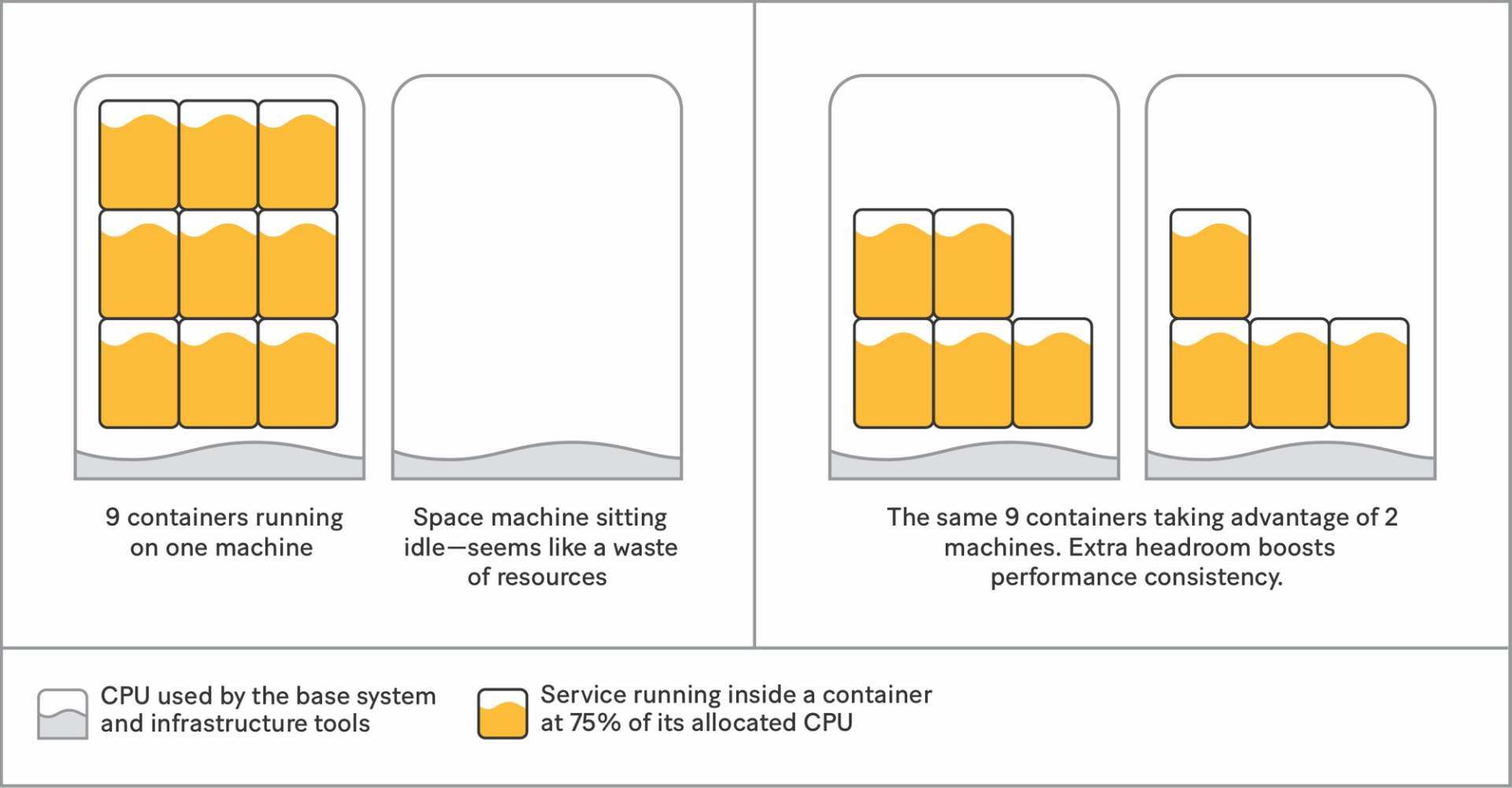
将容器均匀分布在多台机器上可以为服务提供更多空间。
有了足够的机器来处理故障转移情况后,我们就获得了可靠性(在多个主机上分布容器意味着单个主机发生的故障所影响的服务会更少)并提高了性能一致性,但是,我们仍然需要解决在紧急故障转移时安排我们服务的多个副本所需的关键几分钟延迟。我们需要流量转移在几秒钟而不是几分钟内完成,以最大程度地减少我们可能要返回的 500 错误。
随时做好流量转移的准备
在故障转移过程中,如果我们等待安排额外的容器来处理新负载、下载它们的 Docker 映像并为它们的 worker 热身,然后才为流量提供服务,我们就会一点点浪费宝贵的时间。为了抹掉这部分时间,我们决定在正常的服务配置中在容器里保留额外的容量,以确保在故障转移期间我们不需要添加任何内容。虽然这个细节看起来没那么显眼,但这是我们可靠性策略的关键所在,因为它让我们能够随时为故障转移做好准备。
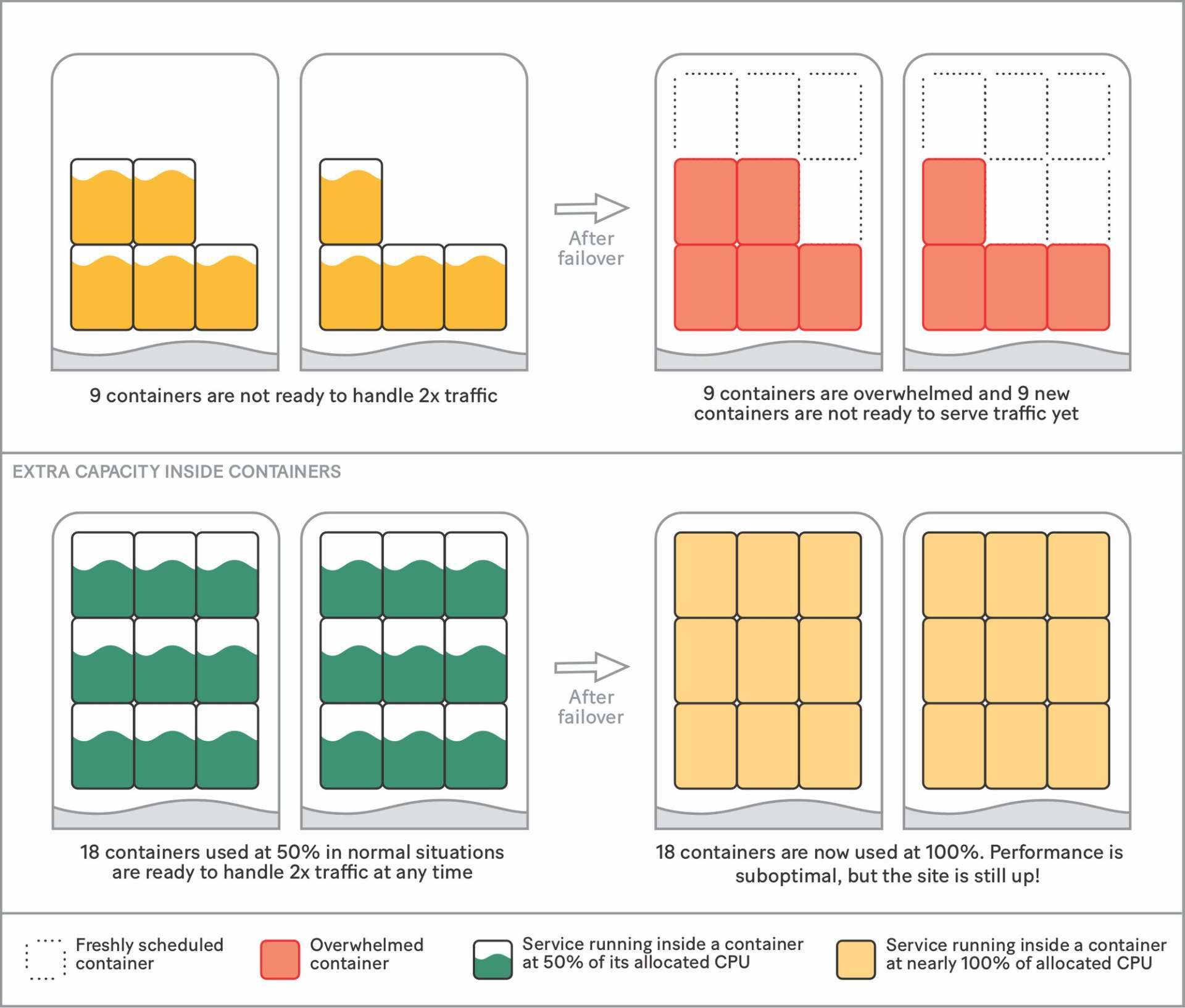
准备额外容器的策略有一些关键优势:
我们可以在所有机器上保留免费资源来保证用户的高性能一致性。这些资源已由服务保留。
我们有了足够的容器来应对流量突然翻倍的情况。
我们减少了对计算基础架构在关键时刻安排容器能力的依赖。
为了实现这一策略,我们必须为容器安排正确的大小,容器还要从计算平台申请正确的资源数量。在一个面向服务的架构中,开发人员直接负责其服务的配置。这种配置需要反映我们的故障转移策略,且每个服务都需要配置为恰好使用分配给它的资源的 50%,这是在故障转移期间处理翻倍负载所需的数字。
设置正确的数值
以简胜繁
这个例子适用于大多数具有单线程 worker 的服务。即使这种自动调整行为已经有了内部文档,也可能没那么直观。只有少数花了时间尝试了解这种行为的人们才能意识到这一点。
假设一个服务的 worker 数量有限,例如四个 worker(一个容器可以一次满足四个请求)请求四个 CPU。自动缩放器被配置为将该服务维持在 CPU 使用率的 50%上下。
现在,想象一下这项服务性能不足的情况。开发人员自然会认为:“只要给它更多的 CPU,让它变得更快或瓶颈减少即可。”因此,他们将 CPU 数量提高到了 8 个。
但至少有两个因素可能会让这样的更改进一步降低服务速度:
Worker 大多是单线程的:无论如何,一个容器永远不会使用四个以上的 CPU 内核。
在自动缩放时将 CPU 设置为 8,并保持 50%的目标使用率的话,该服务将永远不会达到目标使用率(4),于是自动缩放器将开始按比例缩小该服务的容器数量,从而降低该服务的总流量容量。
也许这很反直觉,但更好的配置是将你请求的 CPU 数量减少到两个,这是因为:
在一个面向服务的架构中,大多数服务都将时间花在等待其他服务上,因此每个 worker 不太可能需要一个完整的 CPU 内核算力。
现在你已经达到了自动缩放器的目标,并且一个 worker 平均使用一个 CPU 内核的 50%。自动缩放器增加了容器数量,从而提高了 worker 的总容量。
这说明了为什么生产环境中的自动缩放设置应始终适应服务的内部架构。
面向服务架构的主要优点是提高了开发人员的开发速度,开发人员可以每天多次部署自己负责的服务,而不必担心批量处理代码更改、合并冲突、发布时间表等问题。团队可以完全控制他们的服务及相关配置,包括 CPU、内存和自动缩放设置等资源分配细节。

在 Yelp 的计算平台 PaaSTA 上启用服务自动缩放是非常容易的。
资源分配是一个挑战,为了做好故障转移的准备,每项服务都需要精确的资源分配,以确保容器在正常情况下恰好使用其资源的 50%。我们怎么才能指望几十个团队的软件工程师都在生产环境中精确调整好这些设置呢?
找到最优设置
随着时间的推移,Yelp 的某些核心组件(例如搜索基础架构)已针对性能做好了优化工作。它们的所有者确切地了解了应用程序在繁重生产负载下的行为方式、服务可以使用多少线程、典型的等待时间与实际 CPU 时间都是多少、垃圾收集操作的频率和成本都是多少,等等。但是,Yelp 的大多数团队都不具备所有这些知识。大多数服务都在使用默认值,并且随着服务的规模和复杂度增加,我们要做的“调整”内容也越来越多,需要在各种位置增加资源,
抽象资源声明
我们需要帮助开发人员找到适合他们服务的设置,因此我们投资开发了用于监控、推荐甚至抽象出所有生产服务的自动缩放设置和资源需求的工具链。现在我们分析服务的资源使用情况并为 CPU、内存、磁盘等生成最优设置。开发人员在需要时可以选择取消自动设置:手动设置的数值总是优先于模板化的安全默认值和优化默认值。
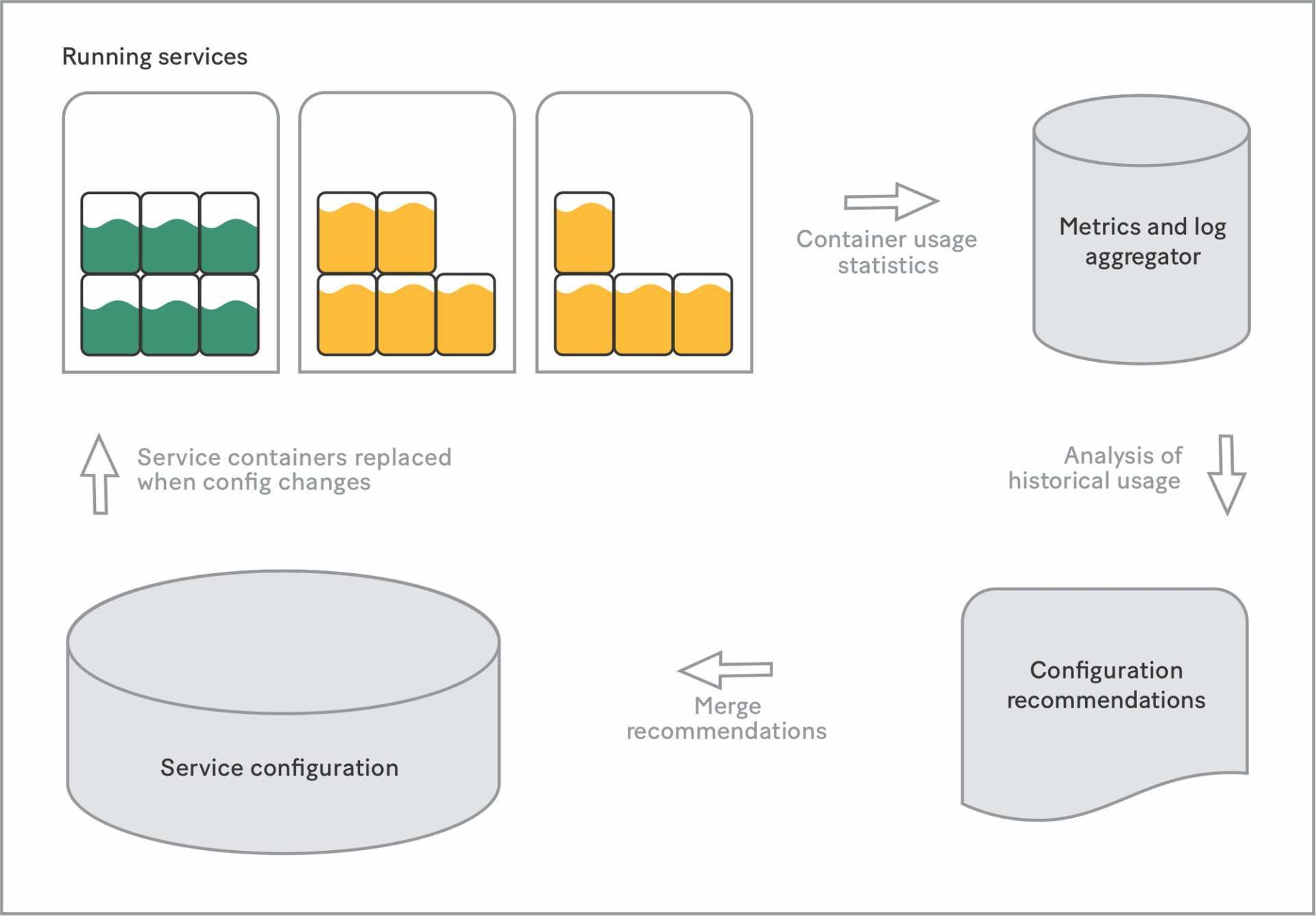
基于配置建议的新容器的使用率为 50%。
为 CPU 生成优化设置可以确保服务正确地自动缩放,并有足够的容量来进行故障转移,同时还可以获得可靠性方面的好处。例如,如果一项服务达到其内存限制并被终止,其优化默认值将在两小时内自动更新,提供更高的内存分配值。在部署自动调整以前,我们需要几天时间来诊断这类情况,而现在我们修复这类问题所需的时间要少很多。
自动调整所有默认值
在提供优化设置选项并构建了用于监控系统成功指标的工具几周后,我们积累了足够的信心来从一个推荐系统转变为默认启用的优化值。我们称其为“自动调整默认值”。除非这个默认值被开发人员手动选择关闭,否则每个服务现在都会自动声明并使用一个优化的资源数量。这一更改还有一个附带好处,那就是之前被分配过量资源的服务现在得到了合适的资源,从而显著减少了计算成本。最重要的是,开发人员可以享受更简单的服务配置。
为成功做好准备
为故障转移分配合适的额外资源,意味着我们随时都能具备所需的计算容量。自动化服务资源分配为服务所有者减轻了大量负担,并改善了整个流程。这些策略结合在一起简化了事件响应,并减少了最严重的崩溃事件中的停机时间。
我们的故障转移和自动缩放策略最有趣的一个方面是组织层面的。通过在每个容器中添加额外的故障转移余量,多个团队的工作效率得到了提高。生产工程团队现在可以控制所有服务的配置,这是成功的故障转移的先决条件。计算基础架构团队可以专注于增强平台,而不必过多担心其处理故障转移服务的能力。而且,开发人员无需通过费时的过程来为故障转移调整资源分配或自动扩展配置。相反,他们可以专注于自己的长处:为我们的用户和社区构建更好的产品。
作者介绍:
Mathieu Frappier 在 2015 年加入 Yelp,为其生产基础架构的多个领域做出了贡献。他对提升复杂系统的效率有着很大的热情。
Dorothy Jung 是 Yelp 的工程经理。她在 LISA 和 SREcon 上介绍了很多可靠性最佳实践。
Qui Nguyen 是 Yelp 的高级工程师兼技术主管。她喜欢利用计算机来解决各种解决问题。
原文链接:https://increment.com/reliability/yelp-traffic-failover-strategy/




