

webpack 处理这些模块引入 import 的时候,有一个重要的步骤,就是如何正确的找到 ‘./xxx’、‘something-in-nodemodules’ 或者 ‘@/xxx’ 等等对应的是哪个文件。这个步骤就是 resolve 的部分需要处理的逻辑。这篇文章将主要介绍针对普通文件的 resolve 流程 和 loader 的 resolve 主流程。
0.目录
介绍
resolve 主流程介绍
获取不同类型 resolver 处理实例
普通文件的 resolve 过程
module 的 resolve 过程
loader 的 resolve 过程
从原理到优化
1.介绍
webpack 的特点之一是处理一切模块,我们可以将逻辑拆分到不同的文件中,然后通过模块化方案进行导出和引入。现在 ES6 的 Module 则是大家最常用的模块化方案,所以你一定写过 import ‘./xxx’ 或者 import ‘something-in-nodemodules’ 再或者 import ‘@/xxx’(@ 符号通过 webpack 配置中 alias 设置)。webpack 处理这些模块引入 import 的时候,有一个重要的步骤,就是如何正确的找到 ‘./xxx’、‘something-in-nodemodules’ 或者 ‘@/xxx’ 等等对应的是哪个文件。这个步骤就是 resolve 的部分需要处理的逻辑。
其实不仅是针对源码中的模块需要 resolve,包括 loader 在内,webpack 的整体处理过程中,涉及到文件路径的,都离不开 resolve 的过程。
同时 webpack 在配置文件中有一个 resolve 的配置,可以对 resolve 的过程进行适当的配置,比如设置文件扩展名,查找搜索的目录等(更多的参考官方介绍)。
下面,将主要介绍针对普通文件的 resolve 流程 和 loader 的 resolve 主流程。
2.resolve 主流程介绍
首先先准备一个简单的 demo:
然后针对这个 demo 来看主流程。在 webpack 系列之一总览 文章中有一个 webpack 编译总流程图,图中可以看到在 webpack 处理每一个文件开始之前都会有一个 resolve 的过程,找到完整的文件路径信息。
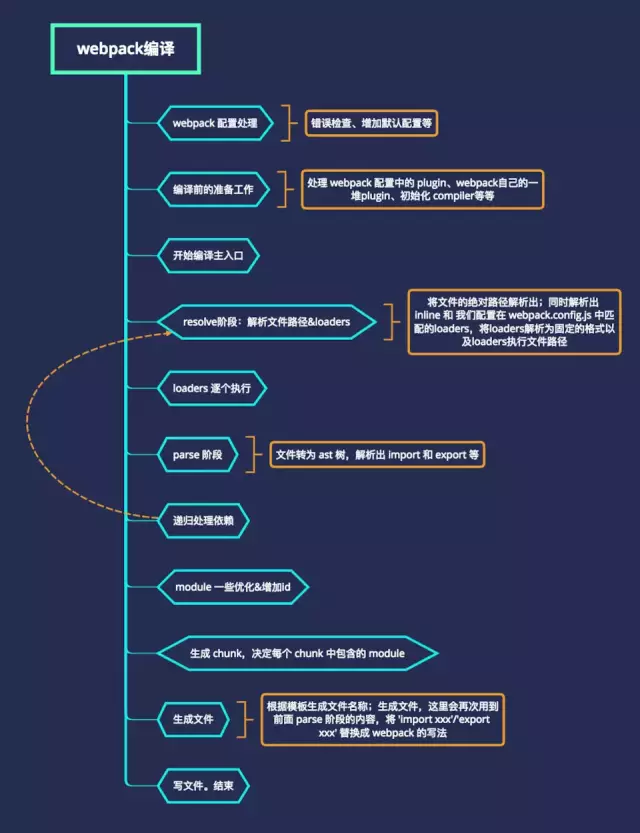
webpack 源码中 resolve 流程开始的入口在 factory 阶段, factory 事件会触发 NormalModuleFactory 中的函数。先放一张粗略的总体流程图,在深入源码前现有一个大概的框架图:

接下来我们就从 NormalModuleFactory.js 文件中开始看起:
因此 this.hooks.resolver.call(null); 结束后,将得到一个函数。然后接下来就是执行该函数获得 resolver 结果。resolver 函数中,从整体看分为两大主要流程 loader 和 文件。
loader 流程
1.获取到 inline loader 的 request 部分。例如,针对如下写法:
会从中解析出 style-loader 和 css-loader。由于此步骤只是为了解析出路径,所以对于 loader 的配置部分并不关心。
2.得到 loader 类型的 resolver 处理实例,即 const loaderResolver = this.getResolver(“loader”);
3.对每一个 loader 用 loaderResolver 依次处理,得到执行文件的路径。
文件流程
得到普通文件的 resolver 处理实例,即代码 const normalResolver = this.getResolver(“normal”, data.resolveOptions);
用 normalResolver 处理文件,得到最终文件绝对路径。
下面是具体的 resolver 代码:
结合上面的步骤和代码看,其实 loader 类和普通文件类型(后面称为 normal 类),大致流程是相似的。我们先看获取不同类型的 resolver 实例部分。
获取不同类型 resolver 处理实例
getResolver 函数,会调用到 webpack/lib/ResolverFactory.js 中的 get 方法。该方法中获取 resolver 实例的具体流程如下图。
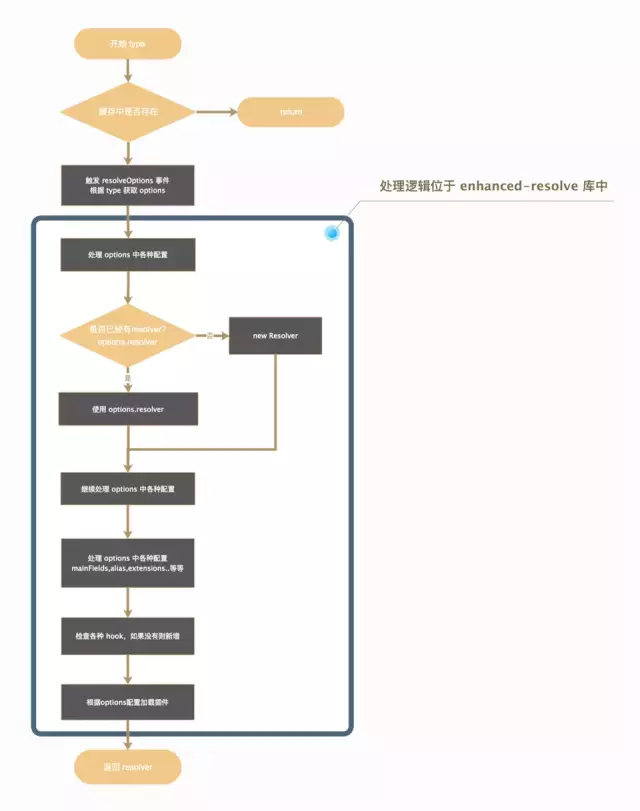
上图中,首先根据不同 type 获取 options 。那么这些 options 配置都存在哪里呢?
webpack 中 options 配置
webpack 直接对外暴露的 resolve 的配置,在配置文件中 resolve 和 resolveLoader 部分,详细的字段见官网。但是其内部会有一个默认的配置,在 webpack.js 入口处理函数中,初始化了所有的默认配置。
在 WebpackOptionsDefaulter() 中,配置了很多关于 resolve 和 resolveLoader 的配置。process 方法将我们写的 webpack 的配置 和默认的配置合并。
webpack.js 中,接下来有一句:
其中 process 过程里会注入关于 normal/context/loader 的默认配置的获取函数。
options 介绍到此先结束,我们继续沿着上面流程图往下看。当获取到 resolver 实例后,就开始 resolver 的过程:根据类型的不同,会有 normalResolver 和 loaderResolver,同时在 normalResolver 中会区分文件和 module。
webpack 中有很多针对路径的配置,例如 alias, extensions, modules 等等,node.js 中的 require 已经无法满足 webpack 对路径的解析的要求。因此,webpack 封装出一个单独的库 enhanced-resolve,专门用来处理各种路径的解析,仍然采用了 webpack 的插件模式来组织代码。接下来会深入到这个库中,依次介绍普通文件、module 和 loader 的处理过程(webpack 中还有一个 context 的 resolve 过程,由于其过程没太多特别之处,放在 module 过程中一起介绍)。先看普通文件的处理过程。
普通文件的 resolve 过程
普通文件 resolver 处理入口为 webpack 中 normalResolver.resolve 方法,而整个 resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。
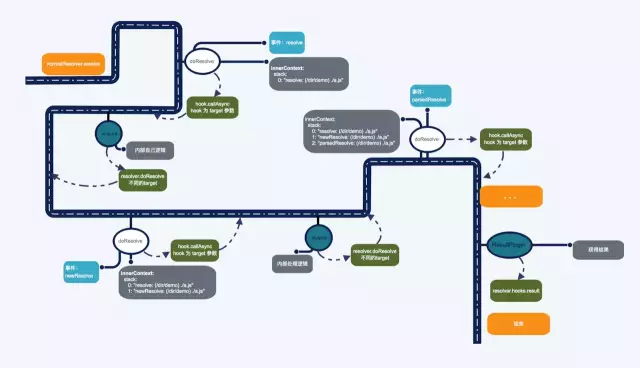
将这些事件一个一个串联起来的关键部分在 doResolve 和每个事件的处理函数中。这里以 doResolve 和调用的 UnsafePlugin 为例,看一下衔接的过程。
调用到 hook.callAsync 时,进入 UnsafeCachePlugin,然后看 UnsafeCachePlugin 中部分实现:
UnsafeCachePlugin 分为两部分:事件注册(new 和 执行 apply) 和事件执行(resolver.getHook(this.source).tapAsync 的回调部分)。事件注册阶段发在 webpack 获取不同类型 resolve 处理实例时(前面获取不同类型 resolver 处理实例小节中,getResolver 的时候),这时会传入一个 source 值(字符串类型)和一个 target 值(字符串类型),代码如下:
在 apply 中,将 UnsafeCachePlugin 的处理逻辑注册为 source 事件的回调,同时确保 target 事件的存在(如果没有则注册一个)。
事件执行阶段,完成 UnsafeCachePlugin 本身的逻辑之后,递归调用 resolver.doResolve(target, …),这时第一个参数为 UnsafeCachePlugin 中的 target 事件。如此,再进入到 doResolve 之后,再触发 target 的事件,这样就形成了事件流。而整体的调用过程,简化来看整体逻辑就是:
通过对 doResolve 的递归调用,事件之间就衔接了起来,形成完整的处事件流,最终得到 resolve 结果。在 ResolverFactory.js 文件的 createResolver 方法中各个 plugin 的注册方法,决定了整个 resolve 的事件流。
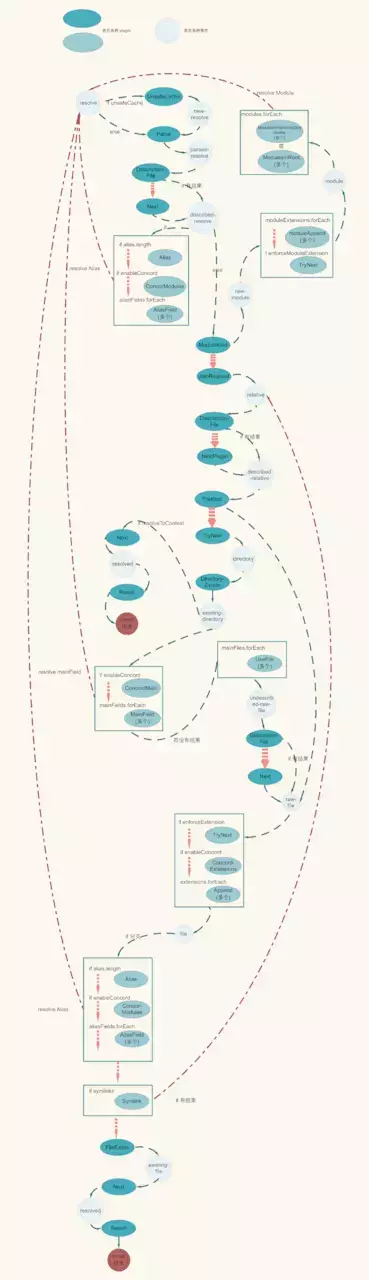
上面代码整理一下,可以得到完整的事件流图(下图为简化版本,完成版本附图):
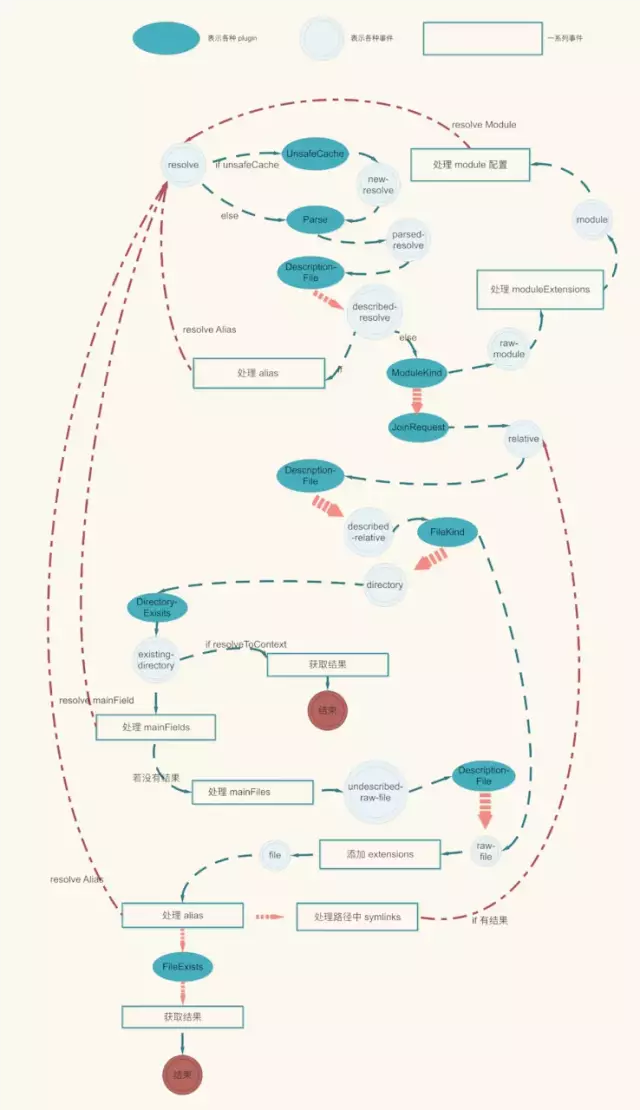
结合上面的图和 demo,我们来一步一步看这个事件流中每一环都做了什么。(ps:下面步骤中,会涉及到 request 参数,这个参数贯穿所有事件处理逻辑,保存了整个 resolve 的信息。)
1. UnsafeCachePlugin
增加一层缓存,由于 webpack 处理打包的过程中,涉及到大量的 resolve 过程。所以需要增加一层缓存,提高效率。webpack 默认会启用 UnsafeCache。
2. ParsePlugin
初步解析路径,判断是否为 module/directory/file,结果保存到 request 参数中。
3. DescriptionFilePlugin 和 NextPlugin
DescriptionFilePlugin 中会寻找描述文件,默认会寻找 package.json。首先会在 request.path 这个目录下寻找,如果没有则按照路径一层一层往上寻找。最后读取到 package.json 的信息和其所在的目录/路径信息,存入 request 中。我们在 demo 的根目录有 package.json 文件,所以这里会获取到根目录的文件。
NextPlugin 起一个衔接的作用,内部逻辑就是直接调用 doResolve,然后触发下一个事件。当 DescriptionFilePlugin 中未找到 package.json 文件时,会进入 NextPlugin,然后让事件流继续。
4. AliasPlugin/AliasFieldPlugin
这一步开始处理别名,由于 AliasFieldPlugin 中依赖于 package.json 的配置,所以这一步放在了 DescriptionFilePlugin 之后。除了我们在配置文件中写一些别名外,webpack 还会有一些自带的 alias;每一个 alias 配置,都会注册一个函数。这一步将执行所有的函数,一一对比。若命中某一 alias 的配置或者 aliasField,那么就会进入上图红色虚线的分支。用新的别名替换 request 参数内容,然后再次开始 resolve 过程。没有命中,则进入下一个处理函数 ModuleKindPlugin。
5. ModuleKindPlugin
根据 request.module 的值走不同的分支。如果是 module,则后续进入 rawModule 的逻辑。前面 ParsePlugin 中得到的结果中 request.module 为 false,所以这里返回 undefined,继续进入下一个处理函数。
6. JoinRequestPlugin
将 request 中 path 和 request 合并起来,将 request 中 relativePath 和 request 合并起来,得到两个完整的路径。在这个 demo 中会得到 /Users/didi/dist/webpackdemo/webpack-demos/demo01/a.js 和 ./demo01/a.js。
7. DescriptionFilePlugin
这时会再次进入 DescriptionFilePlugin 。不过与第一次进入时不同之处在于,此时的 request.path 变成了 /dir/demo/a.js`。由于 path 改变了,所以需要再次查找一下 package.json
随后触发 describedRelative 事件,进入下一个流程。
8. FileKindPlugin
判断是否为一个 directory,如果是则返回 undefined, 进入下一个 tryNextPlugin,这时会进入 directory 的分支。否则,则表明是一个文件,进入 rawFile 事件。我们的 demo 中,这里将走向 rawFile 分支。
9. TryNextPlugin/ConcordExtensionsPlugin/AppendPlugin
由于 webpack 中默认的 enforceExtension 值为 true,所以这里会进入 TryNextPlugin,同时 enableConcord 为 false,不会有 ConcordExtensionsPlugin。
TryNextPlugin 和 NextPlugin 类似,起一个衔接的作用,内部逻辑就是直接调用 doResolve,然后触发下一个事件。所以在这个阶段会直接走到触发 file 事件的分支。当 TryNextPlugin 有返回,且返回为 undefined 。这时意味着没有找到 request.path 所对应的文件,那么会继续执行后续的 AppendPlugin。
AppendPlugin 主要逻辑:webpack 会设置 resolve.extensions 参数(配置中设置或者使用 webpack 默认的),AppendPlugin 会给 request.path 和 request.relativePath 逐一添加这些后缀,然后进入 file 分支,继续事件流程。
10. AliasPlugin/AliasFields/ConcorModulesPlugin/SymlinkPlugin
这时会再次进入到 Alias 的处理逻辑,注意在此步中 webpack 内部自带的很多 Alias 不会再有。与前面相同,这里依然没有 ConcorModulesPlugin SymlinkPlugin 用来处理路径中存在 link 的情况。由于 webpack 默认是按照真实的路径来解析的,所以这里会检查路径中每一段,如果遇到 link,则替换为真实路径。由于 path 改变了,所以会再回到 relative 阶段。若路径中没有 link,则进入 FileExistsPlugin。
11. FileExistsPlugin
读取 request.path 所在的文件,看文件是否存在。文件存在则进入到 existingFile 事件。
12. NextPlugin/ResultPlugin
通过 NextPlugin 衔接,再进入 Resolved 事件。然后执行 ResultPlugin,到此 resolve 整个流程就结束了,request 保存了 resolve 的结果。
3.module 的 resolve 过程
在 webpack 中,我们除了会 import 一个文件以外,还会 import 一个模块,比如 import Vue from ‘vue’。那么这时候,webpack 就需要正确找到 vue 所对应的入口文件在哪里。针对 vue,ParsePlugin 结果中 request.module = true,随后在 ModuleKindPlugin 就会进入上面图中 rawModule 的分支。我们就以 import Vue from ‘vue’ 为 demo,看一下 rawModule 分支流程。
1. ModuleAppendPlugin/TryNextPlugin
ModuleAppendPlugin 和上面的 AppendPlugin 类似,添加后缀。TryNextPlugin 进入 module 事件。
2. ModulesInHierachicDirectoriesPlugin/ModulesInRootPlugin
ModulesInHierachicDirectoriesPlugin 中会依次在 request.path 的每一层目录中寻找 node_modules。例如 request.path = 'dir/demo’那么寻找 node_modules 的过程为:
如果 dir/demo/node_modules 存在,则修改 request.path 和 request.request;
对于 ModulesInRootPlugin,则默认为在根目录下寻找,直接进行替换;
随后,由于改变了 request.path 和 request.request,所以重新回到 resolve 开始的阶段。但是这时 request.request 从一个 module 变成了一个普通文件类型./vue。
3. 与普通文件 resolve 过程分叉点
按照普通文件的方式查找 dir/demo/node_module/vue 的过程与前文中普通文件 resolve 过程类似,经历上一节中 1-7 的步骤,然后触发 describedRelative 事件(这个事件下注册了两个函数 FileKindPlugin 和 TryNextPlugin)。 首先进入 FileKindPlugin 的逻辑,由于 dir/demo/node_module/vue 不是一个文件地址,所以在第 8 步 FileKindPlugin 中最终会返回 undefined。 这时候会进入下一个处理事件 TryNextPlugin,然后触发 directory 事件,把 dir/demo/node_module/vue 按照文件夹的方式来解析。
4. DirectoryExisitsPlugin
确认 dir/demo/node_module/vue 是否存在。(ps: 针对 context 的 resolve 过程,到这里如果文件夹存在,则就结束了。)
5. MainFieldPlugin
webpack 默认的 mainField 为 [‘browser’, ‘module’, ‘main’]。这里会按照顺序,在 dir/demo/node_module/vue/package.json 中找对应字段 vue 的 package.json 中定义了:
所以找到该字段后,会将 request.request 的值替换为 ./dist/vue.runtime.esm.js。之后又回到 resolve 节点,开始新一轮,寻找一个普通文件 ./dist/vue.runtime.esm.js 的过程。当 MainFieldPlugin 执行完,都没有结果时,会进入 UseFilePlugin。
6. UseFilePlugin
当我们 package.json 中没有写 browser、module、main 时,webpack 会自动去找目录下的 index 文件,request 变成如下:
然后触发 undescribedRawFile 事件。
7. DescriptionFilePlugin/TryNextPlugin
针对新的 request.path ,重新寻找描述文件,即 package.json。
8. AppendPlugin
依次为 ‘dir/demo/node_modules/vue/index’ 添加后缀名,然后寻找该文件是否存在。与前文中 file 之后的流程相同。直到最后找到存在的文件,整个针对 module 的 resolve 过程就结束了。
4.loader 的 resolve 过程
loader 的 resolve 过程和 module 的过程类似,我们以 url-loader 为例,入口在 NormalModuleFactory.js 中 resolveRequestArray 函数。这里会执行 resolver.resolve,这里的 resolver 为之前得到的 loaderResolver,resolve 过程开始时 request 参数如下:
在 ParsePlugin 中,request: “url-loader” 会被解析为 module。随后过程中整个和 module 执行流程相同。
到此 webpack 中关于 resolve 流程就结束了。除此之外 webpack 还有不少的细节处理,鉴于篇幅有限这里就不展开细细讨论了,大家可以结合文章看 webpack 代码时去细细品味。
5.从原理到优化
webpack 中每涉及到一个文件,就会经过 resolve 的过程。而 resolve 过程中其中针对一些不确定的因素,比如后缀名,node_modules 路径等,会存在探索的过程,从而使得整个 resolve 的链条很长。很多针对 webpack 的优化,都会提到利用 resolve 配置来减少文件搜索范围:
1. 使用 resolve.alias
我们日常开发项目中,常常会存在类似 common 这样的目录,common 目录下的文件,会被经常引用。比如 ‘common/index.js’。如果我们针对 common 目录建立一个 alias 的话,在所有用到 ‘common/index.js’ 的文件中,可以写 import xx from ‘common/index.js’。 由于 UnsafeCachePlugin 的存在,当 webpack 再次解析到 ‘common/index.js’ 时,就可以直接使用缓存。
不止如此,重点是解析链条变短,缓存只是一部分吧。
2. 设置 resolve.modules
resolve.modules 的默认值为 [‘node_modules’],所以在对 module 的 resolve 过程中,会依次查找 ./node_modules、…/node_modules、…/…/node_modules 等,即沿着路径一层一层往上找,直到找到 node_modules。可以直接设置:
如此会进入 ModulesInRootPlugin 而不是 ModulesInHierachicDirectoriesPlugin,避免了层层寻找 node_modules 的开销。
3. 对第三方模块设置 resolve.alias
对第三方的 module 进行 resolve 过程中,除了上面提到的 node_modules 目录查找过程,还会涉及到对 package.json 中配置的解析等。可以直接为其设置 alias 为执行文件,来简化整个 resolve 过程,如下:
4. 合理设置 resolve.extensions,减少文件查找
当我们的文件没有后缀时,AppendPlugin 会根据 resolve.extensions 中的值,依次添加后缀然后查找文件。为了减少文件查找,我们可以直接将文件后缀写上,或者设置 resolve.extensions 中的值,列表值尽量少,频率高的文件类型的后缀写在前面。
明白了 resolve 的细节之后,再来看这些优化策略,便可以更好的了解其原因,做到“知其然知其所以然”。
附图(resolve 事件流完整版):
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:
https://mp.weixin.qq.com/s/L5-YTEko8klcs_4XGc1MNw

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论