
大语言模型(LLM)的快速发展彻底颠覆了聊天机器人系统,实现了前所未有的智能水平。OpenAI 的 ChatGPT 就是其中最典型的代表。虽然 ChatGPT 的性能令人印象深刻,但目前我们并不清楚 ChatGPT 的训练和架构细节,这也阻碍了该领域的研究和开源创新。
受 Meta LLaMA 和 Stanford Aplaca 项目的启发,近日,来自加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣迭戈分校的研究人员们共同推出了一个开源聊天机器人 Vicuna-13B。这是一款通过 LLaMA 模型微调和 ShareGPT 用户共享对话训练而成的开源聊天机器人。以 GPT-4 作为比照对象的初步评估表明,Vicuna-13B 的质量可达 OpenAI ChatGPT 和 Google Bard 的 90% 以上,并在超过 90% 的情况下优于 LLaMA 和 Stanford Alpaca 等其他模型。
值得一提的是,Vicuna-13B 的训练成本仅为 300 美元(约合 2062 元人民币)。目前,Vicuna-13B 训练和服务代码及在线演示可向非商业用例开放。
在首个版本中,研究人员将在 GitHub repo 上共享训练、服务和评估代码: https://github.com/lm-sys/FastChat。
Vicuna-13B 模型的权重链接:https://github.com/lm-sys/FastChat#vicuna-weights
Vicuna-13B 演示链接:https://chat.lmsys.org/
Vicuna 是如何炼成的?
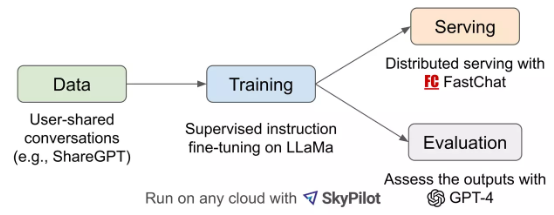
在一篇文章中,研究人员介绍了整体的工作流程。
首先,研究人员从 ShareGPT.com(一个供用户分享 ChatGPT 对话内容的网站)收集了约 7 万个对话,并增强了 Alpaca 提供的训练脚本,以更好地处理多轮对话和长序列。训练是在一天内通过 8 个 A100 GPU 配合 PyTOrch FSDP 完成的。为了提供演示服务,研究人员建立起一个轻量级的分布式服务系统,创建了一组 80 个不同问题,利用 GPT-4 来判断模型输出,借此对模型质量做初步评估。
为了比较两套不同模型,研究人员将各个模型的输出组合成各问题的单一提示,再将提示发送至 GPT-4,由 GPT-4 评估哪个模型做出的响应更好。LLaMA、Alpaca、ChatGPT 和 Vicuna 的具体比较如下表一所示。
表一:几大知名模型间的性能比较
前文提到,Vicuna 是通过从 ShareGPT.com 的公共 API 收集到的约 70K 用户共享对话对 LLaMA 基础模型微调而成。为了确保数据质量,研究人员将 HTML 转换回 markdown 并过滤掉了一些不合适或低质量的样本。此外,研究人员还将冗长的对话拆分成多个小部分,以适应模型所能支持的最大上下文长度。
训练方法以 Standford Alpaca 为基础,并做出以下改进。
内存优化:为了使 Vicuna 能够理解长上下文,研究人员将 Alpaca 的最大上下文长度从 512 扩展至 2048,但这也大大增加了 GPU 内存需求。研究人员利用梯度检查点和闪存注意力的方式来解决内存压力。
多轮对话:研究人员调整训练损失以考虑多轮对话,并仅根据聊天机器人的输出计算微调损失。
通过竞价实例降低成本:40 倍的大规模数据集和 4 倍的训练序列长度对训练成本提出了很大挑战。为此研究人员使用 SkyPilot 托管点来降低成本,希望使用更便宜的竞价实例并配合自动恢复以抢占/切换区域。该解决方案将 7B 模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元削减至 300 美元。研究人员构建了一套服务系统,能够使用分布式工作节点为多个模型提供服务,它支持来自本地集群和云 GPU 工作节点的多种灵活插件。通过使用 SkyPilot 中的容错控制器和托管点功能,这套服务系统能够很好地与来自多种云环境的低成本竞价实例配合运作,借此降低服务成本。其目前还只是轻量级实现,研究人员正努力将更多最新研究成果集成进来。
Vicuna 的优势与局限性
研究人员展示了 Alpaca 和 Vicuna 在基准问题上的回答示例。在使用 70K 用户共享的 ChatGPT 对话对 Vicuna 进行微调之后,与 Alpaca 相比,Vicuna 能够给出更详尽、结构更合理的答案(参见下图),且质量几乎与 ChatGPT 持平。

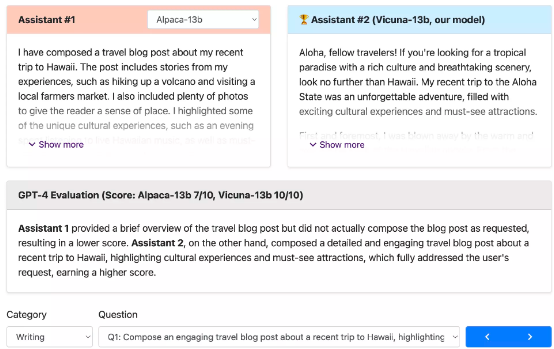
然而,评估聊天机器人绝非易事。随着 GPT-4 的最新进展,研究人员很好奇其能力是否已经达到了与人类相仿的水平,甚至可用于实现基准生成及性能评估的自动化框架。初步调查发现,在比较聊天机器人的答案时,GPT-4 可以给出非常一致的排名和详细评估(参见上图中的 GPT-4 判断示例)。
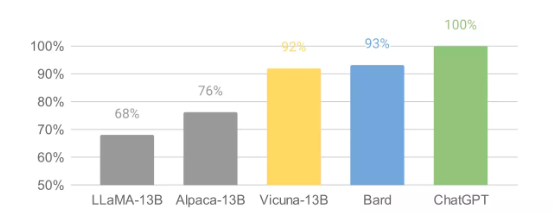
基于 GPT-4 的初步评估(见下图),可以看到 Vicuna 的能力已经达到 Bard/ChatGPT 的 90%。虽然这套框架能在一定程度上反映聊天机器人的潜力,但方法本身并不够严格。目前为聊天机器人建立评估系统仍是一个悬而未决的难题,尚需进一步研究。
与其他大语言模型类似,Vicuna 也具有一定局限性。例如,它不擅长涉及推理或数学的任务,而且在确切识别自身或确保所输出事实的准确性方面可能存在局限。此外,它并没有得到充分优化以保证安全性,或缓解潜在的毒性或偏见。为了解决安全问题,研究人员使用 OpenAI 的审核 API 来过滤掉在线演示中的不当用户输入。尽管还有问题,但研究人员预计 Vicuna 将作为未来解决这些局限的开放起点。
如何评估聊天机器人?
对 AI 聊天机器人的评估是个老大难问题,需要验证其语言理解、推理和上下文感知能力。随着 AI 聊天机器人变得越来越先进,当前的开放基准可能不足以做出准确判断。例如,Standford Alpaca 使用的评估数据集 self-instruct,在领先聊天机器人中就能得到有效解答,导致人类很难辨别各模型间的性能差异。更多限制还包括训练/测试数据污染及创建新基准可能带来的高昂成本。
为了解决这些问题,研究人员提出了一套基于 GPT-4 的评估框架,借此自动评估聊天机器人性能。
首先,研究人员设计了 8 种问题类型,包括费米问题、角色扮演场景及编码/数学任务,借此测试聊天机器人的各方面性能。通过认真设计的提示工程,GPT-4 得以生成基准模型难以解决的多样化、极具挑战的问题。研究人员为各个类别具体选择 10 个问题,并从 5 款聊天机器人处收集答案:LLaMA、Alpaca、ChatGPT、Bard 以及 Vicuna。
之后,研究人员要求 GPT-4 根据指导性、相关性、准确性和细节度秋评估答案质量。最终发现,GPT-4 不仅能够生成相对一致的评分,还能具体解释为什么给出这样的评分(详见https://vicuna.lmsys.org/eval)。但是,研究人员也注意到 GPT-4 似乎不太擅长判断编码/数学任务。
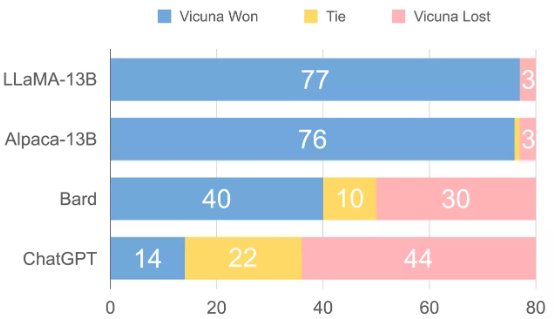
如上图所示,为各基准与 Vicuna 间的比较结果。在超过 90%的问题中,GPT-4 更支持 Vicuna 而非其他先进开源模型(LLaMA 和 Alpaca)的答案,而且在性能上与专有模型(ChatGPT、Bard)等相差不大。在 45%的问题中,GPT-4 都将 Vicuna 的回答评为优于或等于 ChatGPT 的回答。GPT-4 会以 10 分为满分为各个回答做出定量评分,因此研究人员将各个模型在 80 个问题上获得的分数相加以计算其与 Vicuna 之间的总分比较。
如表二所示,Vicuna 的部分为 ChatGPT 的 92%。尽管近来取得巨大进步,但这些聊天机器人仍有自己的局限,例如难以解决基本的数学问题且编码能力有限。
表二:GPT-4 给出的评估总分
虽然这套评估框架确实具有一定的聊天机器人评估潜力,但尚不足以作为严格或成熟的评判方法,特别是无法处理大语言模型容易产生的幻觉问题。为聊天机器人开发一套全面、标准化的评估系统,仍是一个悬而未决、有待进一步研究的问题。
参考链接:




