
在软件世界中,已经有大量所见即所得的 HTML 编辑器,绝大多数的编辑器都是用 JavaScript 及基于 JavaScript 的库构建而成。这些编辑器在处理各种与 HTML 相关的格式化以及生成 HTML 源数据时运转良好,但并不具备我们在商业报告中所需要的各种能力。例如,在一个具有典型的审阅 / 批准生命周期的发布中,创建图形、图表、跟踪变化以及插入注释是非常实用的。加之,Word 天生就是离线工作的。创建新的文档或编辑现有文档时,无需网络连接。而浏览器 /JavaScript 的离线能力仍然有限。考虑到这些能力,有效利用为此目的专门开发的原生应用看起来是更好的解决方案。
Apache Poor Obfuscation Implementation (POI)是一个以加强版面向商业的报告和预览为目的,读取 MS Word 和 MS Excel 等 Microsoft 文档的杰出 Java 框架。它通过将 Word 文档转化为易读的 HTML 格式,提供了增强的数据读取能力。
设计
POI 库支持 Office Open XML 文件格式——OOXML(文字处理和电子表格的一种表示形式)。它包含了用于读取文档中各种区块的 API。在将文档加载到 POI 内存中时,它会获取文档所有的元数据和内容。我们可以通过遍历文档中的各个区块(例如,段落、表格、单元格等。),很容易就读取到这些信息。不过,仅仅使用 POI,我们还无法实现 HTML 等效元素的生成。
例如,一段带有背景颜色的文本会被渲染为带有字体类型、背景颜色等格式化样式的 HTML span 元素。我们应该可以根据从 POI 中读取到的该文档区块的所有相关属性或样式,用 Simple API for XML (SAX) API 创建 HTML 元素。为了实现读取低级别文档区块的功能,应该有一个访问者模式风格的 API 顺序地读取文档中各个区块的内容和属性(格式化风格等)。
Xdocreport 是在 POI 内核和 POI-OOXML 基础上用通用的 OOXML-SCHEMA 构建而成。它会在 POI 内核的帮助下加载文档,然后在 poi-ooxml 和 ooxml-schemas 的帮助下读取内容和元数据。由于使用了模式库,Xdocreport 可以很方便地浏览文档中的元素。Xdocreport 提供了访问者风格的 API 用于读取文档中的每个区块并以 HTML 格式生成内容。通过扩展该库,就可以处理各种格式的 HTML 样式并且克服对表结构和编号渲染的限制。下面的代码片段展示了如何使用所见即所得的方法完成这项工作。
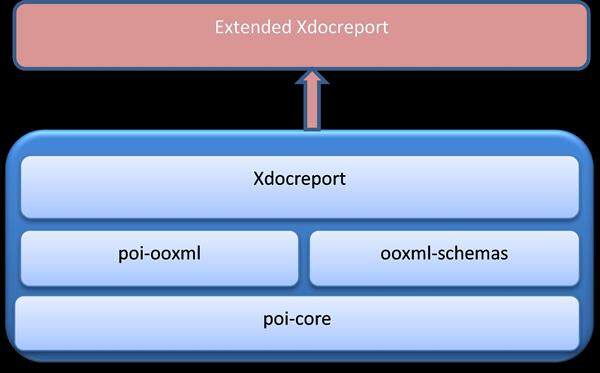
关于如何使用扩展的 xdocreport 控制 HTML 渲染,请参考下方的体系架构图
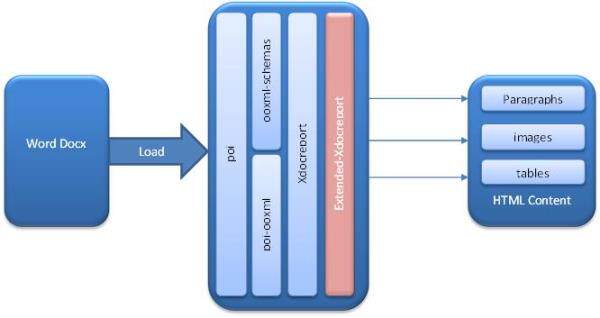
现在,我们开始尝试将包含各种组件的扩展 docx 文档,例如段落、表格、编号以及图片等,转换为 HTML 格式。
Docx 到 HTML 转换的实现
加载 docx 文件流用于创建 XWPFDocument 对象
FileInputStream fstream = new FileInputStream("Example.docx"); XWPFDocument document = new XWPFDocument (fstream); // 创建选项。这些选项用于控制图片的渲染等, XHTMLOptions options = XHTMLOptions.create(); // 创建输出流用于存储生成的 HTML 源文件 ByteArrayOutputStream out = new ByteArrayOutputStream(); IContentHandlerFactory factory = DefaultContentHandlerFactory.INSTANCE; options.setIgnoreStylesIfUnused(false); XHTMLMapper mapper = new XHTMLMapper (document, factory.create(out, null, options), options); mapper.start(); out.close();
我们可以将输出流转化成 String 对象并创建 HTML 文件。
String html = new String(out.toByteArray(), “UTF-8”);
我们可以很容易地将生成的 HTML 源数据附在 servlet 响应输出流当中。
自定义格式化样式和组件
我们可以扩展 xdocreport 中的 XHTMLMapper 类自定义从 MS Word 转化而来的默认的组件样式。我们还可以自定义 HTML 组件的渲染行为。
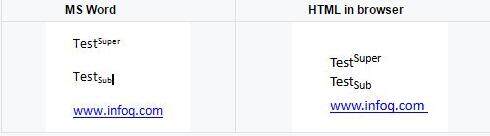
例如,上标 / 下标是作为附加在 span 元素上的 CSS 样式生成的。但是,如果某个较早版本的浏览器无法理解这些 CSS 样式,而只能理解 sup 和 sub 标签该怎么办?所以,作为渲染的一部分,会强制生成 sup/sub HTML 标签,而不是 CSS 样式。下面的例子展示了如何重写 visitRun 方法以生成 sup/sub HTML 标签:
@Override protected void visitRun(XWPFRun run, boolean pageNumber, String url, Object paragraphContainer) throws Exception { boolean isSuper = false; boolean isSub = false; if (rPr.getVertAlign() != null) { int align = rPr.getVertAlign().getVal().intValue(); if (STVerticalAlignRun.INT_SUPERSCRIPT == align) { isSuper = true; } else if (STVerticalAlignRun.INT_SUBSCRIPT == align) { isSub = true; } } . . . if (isSuper || isSub) { startElement(isSuper ? "SUP" : "SUB", null); } . . . if (isSuper || isSub) { endElement(isSuper ? "SUP" : "SUB"); }
我们还可以自定义组件。例如,默认情况下,所有生成的超链接都会直接打开目标,不会在链接上附加任何属性。虽然我们无法将所有的配置都转化成 HTML,我们仍需要支持在新的窗口中打开所有的超链接。我们可以通过重写 visitRun 方法达成这一目的:
@Override protected void visitRun(XWPFRun run, boolean pageNumber, String url, Object paragraphContainer) throws Exception { boolean isUrl = url != null; if (isUrl) { AttributesImpl hyperlinkAttributes = new AttributesImpl(); SAXHelper.addAttrValue(hyperlinkAttributes, "href", url); SAXHelper.addAttrValue(hyperlinkAttributes, "target", "_blank"); startElement("a", hyperlinkAttributes); } . . . if (isUrl) { characters(" "); endElement("a"); }
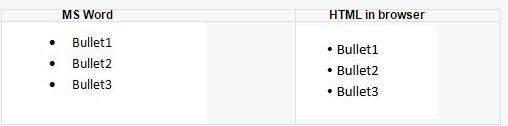
项目编号到 HTML 列表的转换
对于项目编号,对应生成的 HTML 可以使 ul 和 li 元素。不过,并不是所有的 MS Word 编号类型或样式都可以转化成等效的 HTML 列表项,因为 MS Word 有自己的渲染能力和图片或剪贴画库。简单的 ul 和 li HTML 元素无法满足这个要求。这时我们可以利用 span 元素。第一个 span 元素中将包含实际的编号字符,第二个包含具体数据。因此,实现基本的项目编号,我们可以重写“startVisitParagraph”方法。下面的代码片段展示了如何渲染基本的 ASCII 字符项目编号(一个小圆点)。
startElement(SPAN_ELEMENT, attributes); String text = itemContext.getText(); if (StringUtils.isNotEmpty(text)) { text = text.replace('\u2020', '\u2022'); //loop to replace all text = text + " "; SAXHelper.characters(contentHandler, StringEscapeUtils.escapeHtml(text)); } endElement(SPAN_ELEMENT);
在 HTML 中,制表符没有直接的表示法。我们可以输出固定数量的空格字符作为制表符的近似替代品。代码片段如下:
@Override protected void visitTabs(CTTabs o, Object paragraphContainer) throws Exception { if (paragraph != null && o == null) { startElement(SPAN_ELEMENT, null); characters(" ");// 所需添加一定数量的空格 endElement(SPAN_ELEMENT); return; } super.visitTabs(o, paragraphContainer); }
图片抽取
到现在为止,我们已经将具有格式化样式的文本数据转化为 HTML 源。不过,文档中可能还有一些内嵌或外链一些图片在其中。这些图片需要被抽取出来并在浏览器中展示。
内嵌图片
我们可以用默认的附带 XHTMLOptions 选项的 URIResolver 解析内嵌图片。默认的解析器会扫描“word/media/”下的 docx 压缩文件夹,所有的内嵌图片都存储在这里。渲染后的 HTML 图片代码如下所示
<img src="word/media/image1.jpeg" width="189pt" height="141pt"/>
但是,浏览器无法理解 src 的值(源路径),这会导致图片无法访问。我们可以通过自定义的解析器解决这个问题——构建一个 URL 传给要加载这个图片的 servlet
final String imgUrl = "/MyImageLoader?imgeId="; XHTMLOptions options = XHTMLOptions.create().URIResolver(new IURIResolver(){ @Override public String resolve(String uri) { if (imgUrl == null) return "/no_image.gif"; int ls = uri.lastIndexOf('/'); if (ls >= 0) uri = uri.substring(ls+1); return imgUrl+uri; }});
上述代码所创建的选项解析并渲染的图片代码如下:
<img src="/MyImageLoader/imageId=image1.jpeg" width="189pt" height="141pt"/>
典型的 serclet 实现会包含内联的 java 注释:
resp.setContentType("image/jpeg");// 根据文件类型设置正确的内容类型 ServletOutputStream img = resp.getOutputStream(); InputStream fis = getFileInputStream(); // docx 文件输入流 if(fis != null) { String imageId = req.getParameter("imageId"); XWPFDocument document = new XWPFDocument(fis); // 加载文档 XWPFPictureData pic = document.getPictureDataByID(imageId);// 获取图片 if (pic != null) img.write(pic.getData()); }
实现自定义的图片解析器的一个主要优点是我们可以控制需要渲染的图片格式。转换的 HTML 在浏览器中的呈现效果如下:

外部链接图片
如果需要在多个文档中复用同一个图片,外部图片(通过菜单插入 - 图片 - 文件名(指定图片 URL)并选择“链接到文件”插入到 MS Word 中)更加实用。这样我们只有一个该图片的拷贝而且因为不需要将其内嵌到每个文档中还能够节省磁盘空间。这些图片会被渲染成如 url 所指定的 HTML 图片标签和源。如果我们要自定义渲染器,如渲染前的防病毒扫描,渲染的图片是否在图片格式的白名单中,我们可以重写 XHTMLMapper 中的“visitPicture”方法。
// 插入的外部链接图片 String link = picture.getBlipFill().getBlip().getLink(); PackageRelationship rel = document.getPackagePart().getRelationships().getRelationshipByID(link); if (rel != null) { String src = rel.getTargetURI().toString(); // 图片 url
一旦获取到图片的 URL,我们就可以基于渲染前的执行操作,如扫描、认证、授权以及允许的图片格式检查等,决定渲染行为。
下一步研究及限制
我们可以进一步扩展 Xdocreport,以支持更多的组件或区块。MS Word 可以展示或保存在不同的布局视图中(如 Web 版式视图、打印视图等)。对于 Web 布局,HTML 不应该有页边界。而且,页面背景色和页边界都可以转化成等效的 HTML 元素或格式。不过,仍有一些组件或区块没有等效的 HTML 元素,例如页码和多段落分列。
总结
我们已经看到了如何将 MS Word 用作所见即所得的 HTML 生成器。MS Word 提供了许多功能,包括可用在业务审阅和批准周期中的变更追踪。因为有可以在客户端完成编辑工作的原生应用,我们还可以离线工作。这种方式的一大优势在于通过 Java 可以很容易控制 HTML 源码的生成。从 Github 上可以找到相关的示例源代码。
关于作者
 Prasadu Babu Dandu是 MetricStream 公司平台部门的技术主管,MetricStream 是在企业 GRC 软件业内领先的公司。其主要工作是基于 J2EE 技术构建企业级软件。他是开源社区的狂热贡献者。
Prasadu Babu Dandu是 MetricStream 公司平台部门的技术主管,MetricStream 是在企业 GRC 软件业内领先的公司。其主要工作是基于 J2EE 技术构建企业级软件。他是开源社区的狂热贡献者。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论