在第一部分中,我们介绍了一些基本实践,然后通过一个具体的例子帮助大家开启Cassandra 数据模型设计之旅。你可以跳过第一部分直接阅读本篇文章,但是我推荐你看看第一篇文章中“术语和约定”部分。如果你是一个Cassandra 新手,我还是建议你先阅读第一部分。
以下列出的实践有些可能会发生变化,我将提供相关JIRA 地址给大家,以方便跟踪最新进展。下面让我们先从几个基本实践开始吧!
通过column name 存储数据是完全OK 的
同样让colunmn value 为空也是没问题的
通过column name 存储数据是一项常用的实践,同样如果没有必要保存column value,你也可以让它为空。这样做的动机是column name 是物理有序存储的的,而column value 不是。(译者注:比如某个column name 为字符串类型,那么插入005、001、003、007 最终的存储顺序将是001、003、005、007,这将意味着可以根据column name 顺序读取数据)。
注意:
column name(以及 row key)最大为 64KB,所以请不要存储如“物品描述”之类的信息。
不要单独使用 timestamp 作为 column name,那样会导致 2 个或者多个应用服务器同时写入 Cassandra 时造成数据覆盖(译者注:相同 row key,相同 column name 会覆盖 column value),推荐使用 uuid( type-1 uuid )代替(译者注:time-based UUID 主要由 cassandra 客户端时间戳、序列号、MAC 地址组成,这样的组合可以大大降低数据冲突)。
column value 最大为 2GB,它的采用非流式数据读取,cassandra 会将整个 value 加载到 heap 内存中,这是很危险的,所以请确保 column value 只存储不超过几 MB 的数据。(使用 column value 进行大数据存储一段时间内都不会被支持,参见 Cassandra-265 ,但是通过 Cassandra java 客户端——Astyanax,可以通过分块的方式解决这个问题)。
使用宽行(wide row)进行排序、分组和过滤
但不要搞的太长
这个实践与上面的内容相关,当实际数据通过 column name 存储,我们会考虑使用宽行。
宽行的好处:
- 因为 column name 是物理有序存储的,所以宽行对于排序和高效过滤(范围查找)有优势,而且如果需要,你仍然可以高效查找宽行中单独的 column。
- 如果一次要查询多个数据,你可以将数据分组然后保存到一个宽行中,如此可以快速读取数据。举个例子,跟踪和监控一些时间序列数据,我们可以通过“小时 / 日期 / 机器 / 事件”将数据分组到一个 wide row,每个 column 包含刻度数据或者累加数据。我们也可以使用 Super Column 或者 Composite Column 进一步分组数据到一个 row 中,这个我们后面会讨论。
- 在 Cassandra 中,宽行 column family 常常与 composite column 一起配合用于构建自定义索引。
- 这里还有个额外的好处,如果你希望数据被一同查出或者优化读性能,你可以通过反范式化(de-normalize)one-to-many 关系模型来实现这个功能。(译者注:还记得第一篇文章中的示例吗?一个 User 喜爱多个 Item,一个 User 就是一个 row key,column 为多个 Item)
示例:
假设我们系统存储一些事件日志数据,然后按照小时获取它们。请看下面的模型,row key 是日期和小时,column name 存储事件发生的时间,column value 保存负荷值(payload)。请注意,这是一个宽行,事件通过时间顺序进行存储。宽行的间隔刻度(当前示例中,小时刻度比分钟更适合)由实际用例、流量和数据大小决定,我们马上会讨论到它们。
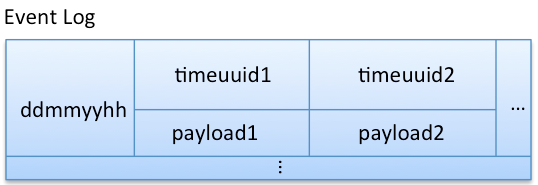
即使是宽行也不要太宽,因为一个 row**** 的数据不会跨节点保存
很难准确的说一个宽行多少个 column 才合适,这依赖于你的用例,下面是一些建议:
流量:所有流量相关数据保存到一个 row 中将导致只有一个节点能够提供服务(假设只有一个数据副本)。那样的 row 太庞大,当 row 的数量小于集群节点数(希望这不会发生),或者宽行与窄行(skinny row)混合使用,再或者一些行访问更频繁,都可能出现集群热点问题。但是,集群负载均衡最终依靠 rowkey 选择;相反地,rowkey 也决定 row 的长度。所以在设计模型的时候要谨记负载均衡。
大小:因为 row 不会跨节点分割,所以单个 row 必须适应节点磁盘大小。但是,row 可以拥有大量 column,因为它不会加载到内存。Cassandra 允许每个 row 包含 20 亿个 column。在 ebay,我们没有做任何宽行测试,我们从不保存超过百万 column 或者 MB 大小数据到单个 row(我们改变 rowkey 刻度或者分割为多个 row)。如果你有兴趣,可以看看 Aaron Morton 关于宽行性能的文章—— 《 Cassandra Query Plans 》(译者注:原文链接 404)。
但是,这些建议不意味你不应该使用宽行,只是不要搞的太长就好。
译者注:原文 Cassandra-4176 和 Cassandra-3929, 这两个 bug 的状态为永不修复,这里就不翻译了。
选择合适的 rowkey
否则,你将死于热点,即使你使用 RandomPartitioner
让我们再次考虑上面的示例,存储时间序列日志,同时按小时获取它们。我们使用日期小时作为 rowkey 以保证一小时数据在一个 row 里。但是,这里有个问题,当前时间的所有写入都集中到一个节点将导致热点问题。减少 rowkey 刻度从小时到分钟并不能真正解决问题,因为 1 分钟内的数据仍然只会写入一个节点。随着时间推移, 热点会移到其他节点但不会消失!
糟糕的 row key: “ddmmyyhh”
一种减轻问题的方式是添加一些信息到 rowkey——事件类型、机器 ID,或者适应你用例的类似值。
不错的 row key: “ddmmyyhh|eventtype”
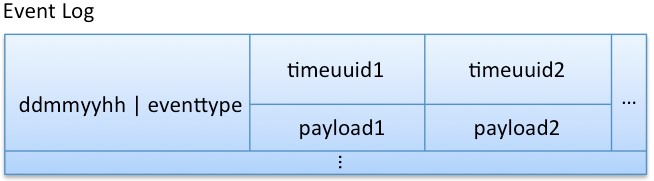
注意,在这个 column family 中,我们现在没有对所有事件按全局时间进行排序,如果我们是通过事件类型来查询数据的话, 这将不是问题,如果用例要求按照时间顺序获取所有事件,我们就需要使用 multi-get 方法一次查询多个 event rowkey,然后将数据在 Cassandra 客户端程序中将数据按照时间顺序合并即可。
如果你不能添加任何信息到 rowkey 或者的确需要时间周期作为 rowkey,另一个选择是将你的 row key 手工分割为:“ddmmyyhh | 1″, “ddmmyyhh | 2″,… “ddmmyyhh | n”, N 值为集群的节点数。一小时内,可以用轮询的方式写入各个节点。当读取数据的时候,你需要使用 multi-gets 方法获取所有节点的数据并做合并。(假设这里使用 RandomPartitioner,因此无法使用 rowkey 范围查询)
让读多数据与写多数据分离
这么做,你能够充分利用 Cassandra 的 off-heap 行缓存特性。(译者注:off-heap 是一种脱离 java gc 的用法,通过 api 可以直接分配、释放内存)
无论 NOSQL 与否,保持读写数据分离都是一个不错的实践。
注意:行缓存对于窄行来说很有用,但对宽行却无益,因为它会将整个行数据放到内存中。通过 Cassandra-1956 和 Cassandra-2864 未来可能改变这一现象,但是保持读写分离这项实践将仍然适用。
假如你的 column family 有大量数据 (超过可用内存),同时有热行,开启行缓存可能对你有用。
确保 column key 和 row key 是唯一的
否则,数据可能被覆盖
在 Cassandra(一个分布式数据库)中,row key 和 column key 是没有强制唯一性约束的。
同样地,cassandra 也没有 update 操作。cassandra 所有操作都是 upsert(不存在插入,存在则更新)操作。如果你插入的数据之前已经存在相同 row key 和 column key,那么之前的 column value 将会被悄无声息地覆盖(cassandra column value 是没有版本的,之前的数据将无法找回)。
使用合适的 comparator 和 validator
除非你真的需要,否则不要使用默认的 BytesType comparator 和 validator
在 Cassandra 中,column value(或者 row key)的数据类型称为“Validator”。一个 column name 的数据类型称为“Comparator”。虽然 Cassandra 不要求你全部定义它们,但你必须至少指定 comparator,除非你的 column family 是静态的(就是说,你不会存储实际的数据作为 column name 的一部分),或者你真的不关心 column 排序。
一个不合适的 comparator 将不能按照你预期所想的顺序将 column name 排序并存放到磁盘上。它将很难(或者不能)根据 column name 进行范围查询。
一旦完成定义,你将不能修改 comparator,除非重写所有数据。但是 validator 是可以事后变更的。
通过 Cassandra 文档看看 comparators 和 validators 支持的数据类型。
保持 column name 简短
因为它将会在被重复存储
如果你使用 column name 存储数据,那这个实践是不适用的。除此之外,保持 column name 简短,因为它将和每个 column value 一起被重复存储(根据数据副本数)。当 column value 的大小比 column name 小很多时,内存和存储的开销可能会是个问题。
比如,‘fname’ 优于 ‘firstname’,‘lname’ 优于 ‘lastname’。
注意:Cassandra-4175 可能会导致本实践在未来失效。
将数据模型设计为支持幂等操作
或者确保你能够接受用例数据不准确或者最终准确的情况
像 Cassandra 这样具有最终一致性以及完全分布式的系统,幂等操作非常有用。幂等操作允许系统因出现错误而导致的重试是安全的,它不会影响数据的最终结果。此外,幂等有时可以降低对强一致性的需求,因为它允许在不产生数据重复和其它异常的情况下实现最终一致性。让我们看看这些原则如何应用到 Cassandra 上。我将只讨论部分失败的情况,降低强一致性需求放到后续文章里讲,因为它非常依赖用例。
因为 Cassandra 具有完全分布式(多个 master)的特性,写失败不能确保数据没有被写入,这与关系型数据库不同。换句话说,即使客户端接收到一个写入操作失败的响应,数据仍可能被写入其中一个副本,数据将最终被传播到其它副本。没有回滚或者清理动作来处理已经写入的数据。因此,虽然客户端出现写失败,但数据最终是成功写入的。所以如果你的模型不具有更新幂等性,错误的重试将导致未知的结果。
注意:
- 这里的“更新幂等性”意味着模型的操作是幂等的。如果一个操作被多次调用却不影响最终结果,那它就具有幂等性。
- 在大多数情况,幂等性不会受到关注,因为将数据写入正常的 Colum Family 总是更新幂等的,Counter column family 是比较特殊的例子,后面我们会说到。有时你的用例可以设计为非更新幂等的。比如我们第一部分文章中,最终方案的模型 User_by_Item 和 Item_by_User 就不具有更新幂等性,因为当“User 喜爱某个 Item”的操作被执行多次将导致数据时间戳发生改变,从而无法获知真实的 User 喜爱某个 Item 的时间。但是,“User 喜爱某个 Item”的操作仍然是幂等的,因为我们在出现错误的时候重试多次。更多具体的例子,我可能会在后面讲到。
- 即使一致性层级为“ONE”,写入失败仍然不能确保数据没有被写入。数据仍然有可能最终传播到其它副本。
示例:
假设我们想计算某个 Item 被多少 User 所喜爱,一种方式是使用 counter column family 保存多少个 user 喜欢某个 item。因为 counter 增加(减少)特性不是更新幂等的,当出现失败并重试的时候就会导致数量被重复累加的情况。让模型具有更新幂等性可以通过维护 user id 来代替增加 counter 记数。无论何时 user 喜爱某个 item,我们都将 user id 写入 item,如果写入失败,我们可以安全的重试。如果希望获取所有喜爱某个 item 的 user,我们只需要读取 item 中 user id 信息手动累加就行。
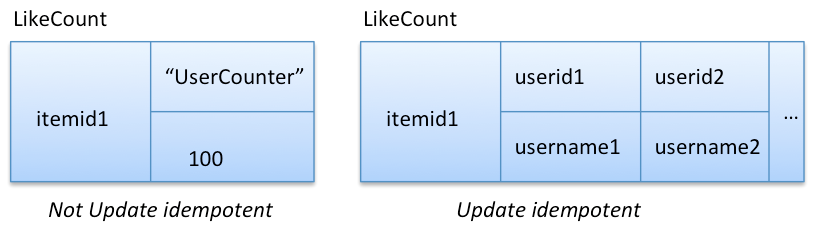
在上面更新幂等(Update idempotent)模型中,获取 counter 值要求读取所有 user id 值,这样的实现可能不够好(因为它可能有上百万个)。在本用例中,如果 counter 读操作很频繁,同时你能接受一个与真实值接近的值,counter column 将是一个更好的、更高效的选择。如果需要,counter 值也可以周期的通过 user id 计算出来并更新,这样的设计也是具有更新幂等性。
注意: Cassandra-2495 可能会为失败的 counter 请求添加一个合适的重试机制。但是,这个实践仍然有效。所以记得经常测试模型更新幂等性。
根据需要,围绕事务建模
但这可能不总是能够实现,具体情况具体分析
Cassandra 没有多行、集群范围的事务或者回滚机制,取而代之,它提供行级别原子性。换句话说,对某个 row key 的一次 mutation 操作是原子的。所以当你需要事务性的时候,尝试设计你的模型,让它一次永远只更新一行。但还是要考虑你的用例,这样的设计不总是有效,如果你的系统需要 ACID 事务,那你需要重新考虑数据库的选择了。
(译者注:Cassandra2.0.2支持多行事务,详见 CASSANDRA-5633 。)
如果可以的话,预先设计好合适的 TTL
因为很难改变既有数据 TTL
在 Cassandra 中,TTL(存活时间) 不是设置在 column family 上,它设置于每个 column value,一旦设置后就很难改变。或者说,如果创建 column 时候没有设置,那之后就很难对其设置 TTL。对于既有数据修改 TTL 唯一的方式就是读取然后再次插入所有数据,并赋予 TTL。所以要考虑好如何清除你的数据,如果可能进来在创建数据的时候设置合适的 TTL。
不要使用 counter column family 生成 key 信息
它不是干这个用的
counter column family 保存分布式 counter 信息,这意味着它要做分布式的累加(递减)运算。不要使用 counter 生成序列编号(比如 oracle 的 sequence 或者 MySQL 的自增列)来生成你的 rowkey(column key),否则你将可能得到重复序列编号,从而导致数据覆盖。大多数时间你真的不需要全局序列编号,更好的选择是使用 timeuuid ( type-1 uuid ) 来生成 key 信息。如果你真的需要一个全局序列编号生成器,这里有个可行的办法,就是需要一个中央协调器,但这会影响系统的扩展性和可用性。
composite columns 优于 super columns
使用 super columns 可能会产生性能瓶颈
在 Cassandra 中,super column 常被用于对 column key 进行分组,或者建立两层数据结构。但是 super column 有下列实现问题导致它并不那么美好:
问题:
- Super column 的子 column 不能被索引,读取一个字 column 意味着要反序列化整个 super column
- 子 column 无法使用内建二级索引
- Super column 无法实现超过两层的结构
类似的功能,可以通过 Composite column 实现,它是包含子 column 的标准的 column,因此标准 column 所有的好处它都具备,比如排序、范围查询,同时你可以设计出多层级的结构。
注意 composite columns 中子 column 顺序
因为排序决定数据存储位置
举个例子,一个 composite column key 为 <state | city>,将被先按照 state 然后按照 city 的顺序存储,换句话说,一个 state 的所有 cities 在磁盘存储上是紧挨着的。
优先使用内置的 composite types,而不是自定义类型
因为自定义类型不总是可用
避免使用字符串连接(如果通过分隔符“:”或者“|”)的 composite column key,取而代之,应该使用内置 composite types (以及 comparators),它在 cassandra0.8.1 版本以上被支持。
Why?
- 如果 sub-columns 是不同的数据类型,自定义类型将不能正常工作。比如,composite key<state|zip|timeuuid> 将不能适用于根据类型感知排序(state 是字符串,zip 是整型,timeuuid 是时间类型)。
- 你不能针对每个 sub-columns 进行不同的顺序查找。比如,上面的例子中,不能根据 state 升序,zip 进行降序。
注意:Cassandra 内置 composite types 有两种使用方法:
- 静态 composite type:composite column 的每部分的数据类型都在 column family 中被提前定义好。Column family 中所有 column name 必须是之前定义好的类型。
- 动态 composite type:这个类型允许你将不同的 composite type 的 column name 在一个 column family 中混合使用,甚至在一行中。
关于 composite type 更多信息,请查看这里: Introduction to composite columns
无论何时,尽量优先使用静态 composite type
因为动态 composite 太灵活
如果一个 column family 中的 column keys 都是相同的 composite type,则一定要使用静态 composite type。创建动态 composite type 最初的目的是为了在一个 column family 中保存多用户自定义索引。如果可能,请不要在一行中使用不同的 composite type,除非真的有必要这么做。 Cassandra-3625 已经修复了一些动态 composite 的严重问题。
注意:CQL3 支持 column name 使用静态 composite type。如果想知道 CQL3 如何处理 wide row,请参考这篇文章 DataStax docs 。
就这么多,如果您能从这些最佳实践中获益,非常欢迎看到您的回复,这就是我们 Cassandra 今天的使用情况。
– Jay Patel , architect@eBay.
译者介绍
张月
Java 程序员,7 年工作经验,目前就职于 ChinaCache 数据平台组,EasyHadoop 社区委员、讲师,博客: heipark.iteye.com 。
李娟
Java 程序员,2 年工作经验,目前就职于 ChinaCache 数据平台组,博客: essen.iteye.com 。




