

背景与介绍
大都数传统的推荐系统(协同过滤、基于内容的推荐、learning-to-rank)只是将推荐过程当做一个静态的过程,并且在一段时间内是根据固定的模型来进行推荐。当用户的兴趣发生动态变化时,这些传统方法推荐的内容就不能捕捉到用户兴趣的实时变化。因此本文提出了一种 DRL 算法,可通过推荐系统和用户不断交互来持续提升推荐质量。
在电商领域,用户有正反馈和负反馈(比如用户点击了商品为正反馈,用户对商品没有任何操作称为负反馈),并且负反馈的数量远远大于正反馈。因此正反馈给模型带来的影响经常被负反馈给“冲刷”掉。本文提出的 deep recommender system(DEERS)的算法框架可将正、负反馈同时融入到模型中。
文中将了将 RL 引入到推荐系统中的两个优势:1. 通过用户与推荐系统的不断交互,可持续更新 try-and-error 策略,直到模型收敛到最优;2. 在当前状态动作对下,通过带延迟奖赏构造的 value 值可不断训练推荐模型。对于一个用户来讲,其最优的策略就是最大化该用户的期望累计奖赏。因此推荐系统通过很小的即时奖赏就可筛选出商品。
问题建模
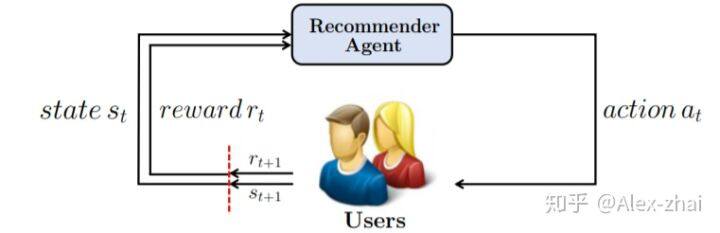
环境:用户 agent:推荐系统
MDP 中各元素的定义为:
状态空间 S:用户之前的浏览历史,包括点击/购买过的和略过的,二者分开进行处理。同时,物品是按照先后顺序进行排序的。
动作空间 A:一次只给用户推荐一个物品,那么推荐的物品即动作。
即时奖励 R:在给用户推荐一个物品后,用户可以选择忽略、点击甚至购买该物品,根据用户的行为将给出不同的奖励。
状态转移概率 P:状态的转移主要根据推荐的物品和用户的反馈来决定的。
折扣因子 r:对未来收益进行一定的折扣
模型框架
基本的 DQN 模型,只考虑正向的反馈
状态 s: [公式],用户之前点击或购买过的 N 个物品同时按照时间先后进行排序
s 转移到 s’:假设当前的推荐物品 a,用户若点击或购买,则 [公式] ,若用户略过,则 s’=s 。
需要注意的是,仅仅使用离散的 indexes 去表示 items 是表达力不够的,比如相似的商品仅从 index 上也是无法推断的。一个常见的做法是,在表示 item 的时候加入额外的信息,比如 brand,price 和月销量等等。本文则是采用了另外一种方法,将用户的浏览历史当做一个 session 下的序列,然后通过 word embedding 技术去训练得到每个 item 的 embedding 表示(有点像 Airbnb 的做法)。
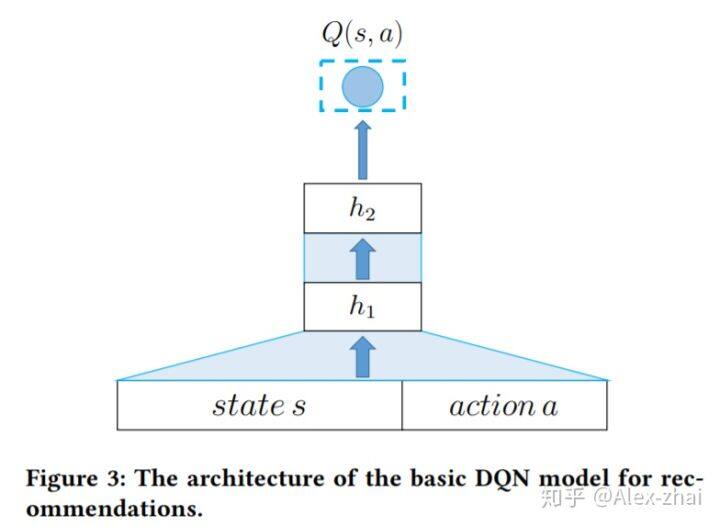
训练得到 item 的 embedding 之后,将状态和动作的 embedding 表示 concat 起来作为模型的输入,输出为该状态动作对的 Q 值。更新方法和传统的 DQN 是一样的。这里就不详细介绍了
DEERS 模型,同时考虑正向和负向反馈
对于基本的 DQN 模型来说,一个明显的缺点是,当推荐的物品被用户忽略时,状态是不会发生变化的。因此 DEERS 模型在状态中也考虑被用户忽略过的商品。
当前状态 s: 当前状态 s 包含两部分 s=(s+,s-),其中 s+={i1,i2,…,iN},表示用户之前点击或购买过的 N 个物品,s-={j1,j2,…,jN},表示用户之前略过的 N 个物品。同时物品按照时间先后进行排序。
s 转移到 s’:假设当前的推荐物品 a,用户若点击或购买,则 s’+={i2,i3,…,iN,a},若用户略过,则 s’-={j2,j3,…,jN,a} 。那么,s’ = (s’+,s’-)。
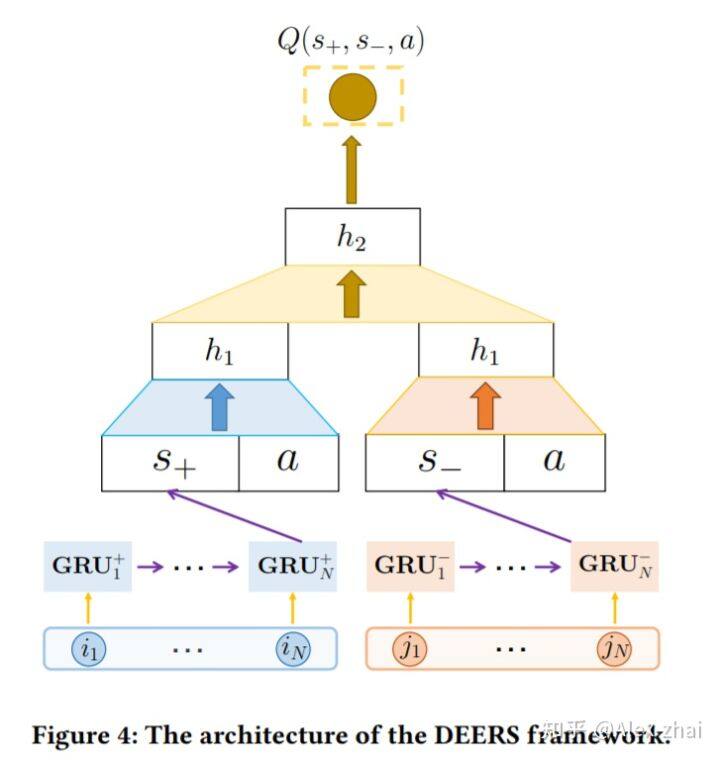
如上图,DEERS 模型使用 GRU 来抽取 s+,s-两个序列的表征。
另外,DEERS 模型还考虑了商品之间的偏序关系。对于一个商品 a,偏序对中的另一个商品称为 [公式] ,但只有满足三个条件,才可以称为[公式]。首先,[公式]必须与 a 是同一类别的商品;其次,用户对于[公式]和 a 的反馈是不同的;最后,[公式]与 a 的推荐时间要相近。
若商品 a 能够找到有偏序关系的物品[公式] ,此时不仅需要预估的 Q 值和实际的 Q 值相近,同时也需要有偏序关系的两个物品的 Q 值差距越大越好,因此模型的损失函数变为:
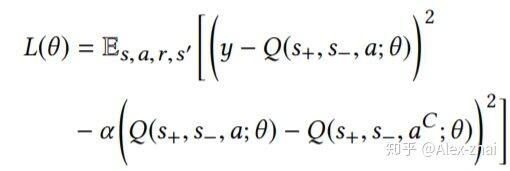
其中,目标 Q 值 y 的计算为:
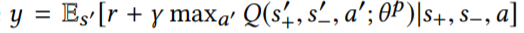
整个算法的流程为:

参考文献:
https://arxiv.org/pdf/1802.06501.pdf
https://www.jianshu.com/p/fae3736e0428
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/77224966

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论