总述
Graphical Model 通常应用在问题本身带有多个相互联系的变量的场景,并提供了一种基于图的表达方式让你去建模这些联系从而挖掘潜在的因果关系。在本文中,我们创新性地将概率图模型应用到了淘宝平台收藏作弊行为检测的任务中,取得了远超传统分类模型的结果(Top1% 记录中召回 60% 的作弊行为)。本文我们将从作弊行为分析,构建模型,求解模型三个部分对这个工作进行详细介绍。目前文章已被 WWW 2018 接收(接收率 14.8%)。
背景介绍
随着在线购物网站的发展,在线购物正在逐步取代传统的购物方式。2016 年普华永道的调查显示 54% 的购物者每周或每月都会在网上购买商品,其中 34% 的购物者认为手机是他们主要的购物工具。在购物网站中,搜索引擎是用户找到具体商品,款式或者品牌的主要入口。在搜索引擎的帮助下,用户能够方便地在购物网站上完成一系列加购,收藏,购买行为,而这些用户行为数据本身也蕴含着极大的价值,在优化购物网站的推荐和搜索中扮演了非常重要的角色。“加入收藏夹”作为淘宝一个重要的功能,可以方便用户收藏一些暂时不买的商品。与此同时,商品被“加入收藏夹”的数量,也称作人气,也是淘宝的搜索引擎提供的一种可选的排序策略;且对于默认的综合排序,人气值也常常作为一个参数被引入进去。
为了提升产品或店铺的排名及可见度,部分恶意商家采取虚假的作弊行为以提高销量,主要包括虚假推广行为(收藏、加购和转发)及虚假的评论行为。目前,针对于淘宝作弊活动的地下产业已趋近成熟,尤其是随着众包平台的发展,这些商家可以根据自己的需求,便捷地发布作弊任务,吸引众多的参与者来完成作弊活动,从而快速高效的实现产品或店铺的宣传推广。以虚假收藏为例,恶意商家通过发布任务,快速提高其商品的人气值,从而影响淘宝的推荐和搜索排序策略,进一步提高商品销量。这类借助众包平台的作弊行为能够在短时间内产生大量异常数据,且难以检测,会对用户以及购物网站本身造成恶劣的影响。因此,如何快速有效地找到这些作弊活动,对于淘宝来说非常重要。
作弊活动运作模式
通过调研灰产平台提供的收藏作弊服务,我们总结了如下图所示的作弊模式:

首先商家通过平台发布作弊任务,指定商品,搜索关键词,任务时间以及佣金。除了这些基本的信息之外,商家还会提出一些特殊的要求,例如在搜索结果页中浏览超过x 分钟,在搜索结果中随机点击y 个商品,再点击指定商品进行收藏,有一些任务还需参与者满足一定的等级要求。平台的用户看到任务之后会去申领,根据任务中提出的要求进行搜索,浏览,点击,收藏等一系列动作,最后还需要截图,以便去平台申领佣金。
此类平台的用户,多为兼职刷手,作弊行为只是其在淘宝平台留下的行为的一部分。此外,收藏作为一个隐私行为,无法被大众察觉,缺少类似于“对我有用”、“最佳答案”等显性的指标。因此,这类新兴的作弊任务,很难用已有的方法进行检测。
为了针对此类作弊行为进行识别,我们收集了作弊平台上一个月时间的任务,用于对用户行为进行标注。同时,我们分别从用户属性,商品属性以及行为属性三个角度,对收藏作弊进行了深入分析。我们将这些属性和用户,商品之间的关联关系用Factor Graph 模型进行了整合,并基于此设计了一个分类模型来检测可能的收藏作弊行为。
用户、商品以及行为属性对比分析
行为属性分析
首先,我们对作弊收藏行为和正常收藏行为之间的属性差异做了详尽的对比。

从加购角度看,作弊收藏行为中带有加购动作的只有6%,而在正常收藏行为中则有8%。这个差异主要是因为极少数的收藏作弊任务中会有加购物车的要求,另外作弊收藏的商品本身也不是用户想要的,自然加购的意愿也就差一些。在搜索过程中,用户可以通过一些筛选条件(发货地,价格区间等)来更有效的找到商品,这里作弊收藏对比正常收藏,使用筛选的比例反而更低一些。对于收藏前是否有其余的商品点击(在当前这次搜索过程中),作弊收藏行为明显高出正常收藏行为很多。这个主要还是因为作弊任务中很多都要求多点几个商品。从时间上看,作弊行为更倾向于发生在周末,这可能是与作弊用户是兼职的有关系。
在下图中,我们对更多的行为属性进行了对比,这其中包括了搜索关键词的长度,搜索结果页浏览深度,搜索结果页停留时间以及点击商品详情页的停留时间。

通过上面的分析,我们可以看到除了前序商品点击之外,其余的多种属性上,作弊收藏行为和正常收藏行为之间的差异性并不大,这也进一步印证了但从行为本身来区分作弊与非作弊是非常困难的。
用户属性分析
在接下去的分析中,我们将收集到的作弊样本涉及的用户定义为作弊用户,其余的用户称为正常用户,类似作弊样本中的商品成为作弊商品,其余的商品成为正常商品。

从上表中可以看到,作弊用户的行为(收藏,加购,购买,评论)明显要少于正常用户。这些行为能反映出一个用户在平台上投入的时间,很显然,作弊用户的活跃度远低于正常用户。

我们取了其中一个作弊用户,来观察其收藏行为的持续性。结果如上图中展现,作弊用户会在一段持续的时间里(前半个月)收藏一定数量的作弊商品。这个数据说明,作弊用户收藏作弊商品会在某个持续的时间窗口内。
商品属性分析
与用户属性分析类似,我们也对比了作弊商品和正常商品之间的差异性。数据见下表。很明显,作弊商品上的行为数据远低于正常商品,这也反映出,通常只有表现不是很好的商品会寻求作弊,同时这些作弊商品也很难吸引到正常的用户。

我们选取了一个作弊商品和一个正常商品,观察它们被收藏的持续性,结果见下图。可以看到,作弊商品上的作弊行为集中在一个很短的时间窗口内,这或许是对应的任务指定的时间。

作弊收藏检测
模型定义
根据对作弊活动的分析,我们提取了有区分能力的特征,并将提取的特征因素和关联因素统一整合到概率图模型框架中(Activity Factor Graph Model, AFGM),进行虚假收藏活动的识别。
在AFGM 模型中,我们一共引入了三方面的特征因素,包括行为特征,用户特征和商品特征,同时引入了基于用户和商品的关联因素,即对于一个固定的时间窗口内,相同用户或者相同商品产生的两条收藏记录建立边的关系,具体模型如下图所示。

图中,网络G 中的一组活动节点\(V={A_1,A_2,…,A_N}\) 被映射到了一组因子节点\(Y={y_1,y_2,…,y_N}\)。G 中的活动有一部分是有标签的,因此Y 可以被分为有标签的\(Y_L\)(训练集), 没有标签的\(Y_U\)(测试集)。 AFGM 可以根据训练集中已知的因子节点来推测未知的节点是否是作弊。根据上面对行为属性,用户属性和商品属性的分析,我们定义了以下4 种因子:
行为属性因子:\(f_b (y_i│b_i )\) 表示在给定行为属性向量\(b_i\) 的情况下,\(y_i\) 的后验概率。
用户属性因子:\(f_u (y_i│u_i )\) 表示在给定用户属性向量\(u_i\) 的情况下,\(y_i\) 的后验概率。
商品属性因子:\(f_p (y_i│p_i )\) 表示在给定商品属性向量\(p_i\) 的情况下,\(y_i\) 的后验概率。
另外根据前述的发现,作弊商品/ 用户的作弊行为具有持续性和集中性,所以我们定义了两种相关性因子:
\(g_u (y_i│C_u (y_i))\) 表示基于用户的行为相关性,其中\(C_u (y_i )\) 是与在概率图中与\(y_i\) 连接的相关性因子节点的用户集合。
\(g_p (y_i│C_p (y_i))\) 表示基于商品的行为相关性,其中\(C_p (y_i )\) 是与在概率图中与\(y_i\) 连接的相关性因子节点的商品集合。
有了这些因子之后,AFGM 中的行为概率就可以表达为:
\(P(Y│G)=1/Z ∏_if_b (y_i│b_i )∙ f_u (y_i│u_i )∙f_p (y_i│p_i )∙g_u (y_i│C_u (y_i))∙g_p (y_i│C_p (y_i))\)
模型的目标是将\(P(Y|G)\) 最大化。
模型求解
我们用指数线性函数来定义三个属性因子:
\(f_(b(y_i│b_i ) )=exp{λ_b^T Φ_b (y_i,b_i )}\)
\(f_(u(y_i│u_i ) )=exp{λ_u^T Φ_u (y_i,u_i )}\)
\(f_(p(y_i│p_i ) )=exp{λ_p^T Φ_p (y_i,p_i)}\)
这里,\(λ_b^T,λ_u^T,λ_p^T\) 是权重向量,\(Φ_b,Φ_u,Φ_p\) 则是特征向量函数。类似的,相关性因子的定义为
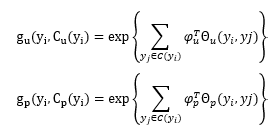
这里,\(φ_u^T,φ_p^T\) 是权重向量,\(Θ_u,Θ_p\) 是示性函数向量。学习AFGM 就是去估计一组参数设置\(θ=(λ_b^T,λ_u^T,λ_p^T,φ_u^T,φ_p^T )\),使得\(P(Y│G)\) 最大。
为了简洁,我们将一个因子节点\(y_i\) 的所有的因子函数连接在一起,记为
\(s(y_i )=(Φ_b (y_i,b_i )^T,Φ_u (y_i,u_i )^T,Φ_p (y_i,p_i )^T,Θ_u (y_i,y_j )^T,Θ_p (y_i,y_j )^T )\)
这样,我们可以把\(P(Y│G)\) 改写为
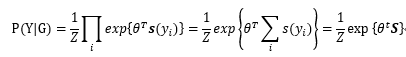
由于因子节点集合Y 是部分标注的,为了计算这个概率,我们定义\(Y|Y_L\) 为已知标签集\(Y_L\) 的前提下,所有节点的标签配置情况。进一步,我们定义log-likelihood 目标函数为

我们用梯度下降算法来求解这个目标函数,其中参数\(θ\) 的梯度为:

这里\(E_(Y|Y_L,G) (S)\) 表示在已知标签\(Y_L\) 的前提下S 的期望,\(E_(Y|G) (S)\) 则表示所有标签可能下的S 的期望。由于\(E_(Y|Y_L,G) (S)\),\(E_(Y|G) (S)\) 在计算上非常困难,我们利用loopy belief propagation(LBP)算法来求一个近似解。在每次迭代过程中,我们两次运用LBP 算法,第一次用于估计位未知节点的边际概率,第二次是用于估计所有节点的边际概率。有了这个边际概率之后,上述的两个期望可以近似为将所有相关节点的边际概率之和。最后根据梯度,我们会不断的更新参数直至收敛。
根据学到的参数\(θ\),我们在测试集上再一次用LBP 算法估计一个边际概率。这个边际概率就会作为一个节点是否为作弊的预测值。
实验结果
我们将AFGM 的结果与Support Vector Machine,Logistic Regression,Random Forest,以及AFGM 的三个变种
AFGM-UP:去掉用户因子与商品因子后的模型,用于说明加入用户因子与商品因子的必要性
AFGM-\(C_u\):去掉用户相关性因子后的模型,用于说明加入用户相关性因子的必要性
AFGM-\(C_p\):去掉商品相关性因子后的模型,用于说明加入商品相关性因子的必要性
我们对比 Top1% 中的作弊召回量: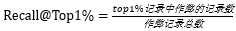 。同时,我们也是对比了 AUC 来检查我们的模型是否给予了作弊行为记录一个更高的概率。试验结果如下:
。同时,我们也是对比了 AUC 来检查我们的模型是否给予了作弊行为记录一个更高的概率。试验结果如下:

可以看到,传统方法在作弊检测这个问题上基本上没有效果,而利用概率图模型则均可得到一个较好的结果。相比之下,我们发现即便不考虑商品属性因子和用户属性因子,模型已经能到得到一个很好的结果了,加入这些因子之后只是对最终结果小幅提升。

上图显示了不同的概率图模型在topk% 下的检测效率,可以看到在top10% 中,我们就可以检测出近80% 的作弊行为,而AFGM 与AFGM-UP 两种模型的表现非常接近。这个可能是由于相关性因子已经包含了足够的信息用于检测作弊行为。AFGM-CP 的表现是四种模型中最差的,这说明商品相关性因子在检测作弊的时候更加重要。
小结
在本文中,我们对淘宝评上的收藏作弊行为从多个角度做了深入的分析,揭示了作弊行为与正常行为之间的差异性。通过这些分析,我们提取了多种特征,并提出了AFGM 来推断一次收藏行为是否为作弊。实验结果显示,AFGM 在top1% 的记录中能召回超过60% 的作弊行为。通过不同模型之间的对比,我们也发现商品相关性因子在检测作弊行为时更为重要。尽管我们提出的检测模型具有相当高的效率,但是也得指出目前的算法只能对一个时间周期内的作弊进行整体识别,尚不能对行为进行实时判别,这将是未来的一个研究方向。
如果您也有论文被国际会议录用或者对论文编译整理工作感兴趣,欢迎关注 AI前线(ai-front),在后台留下联系方式,我们将与您联系,并进行更多交流!





