

12 月 7 日,在 2018 ArchSummit 全球架构师峰会·运维与监控专场,七牛云资深运维开发工程师贺强带来了主题为《如何快速构建高效的监控系统》的内容分享。

大家好,今天给大家带来的分享是如何在创业公司去搭建一套高效快速的运维系统。我演讲的主要内容有:谈到高效,我们如何来定义所谓的高效的监控系统;如何做好一个监控系统的选型和设计;七牛云内部的监控系统介绍;最后会和大家一起来探讨监控的发展趋势以及未来展望。
如何定义「高效」的监控系统?
在我认为,高效的系统应该包含以下几个特性:高可靠、易扩展、自适应、开放性。

01 高可靠
所有的能够体现高可靠的几点信息,第一是整个系统没有单点的模块,无单点的风险,这是我们日常做系统或者做运维、做系统设计的时候需要首先考虑的问题。第二是本身会提供一个丰富的自采集系统层面的监控项,包括系统内核、设备、应用的一些资源消耗等信息。第三是它所支持的监控种类比较丰富,因为我们现在的应用的类型也比较多,像常见的对应用监控的需求,比如日志监控、端口监控、RPC 监控等等,这些能够很方便的进行添加和管理。第三点是比较基础的,高效、延时低,无论是数据采集、上报、计算处理、再到通知,以及到用户收到这个通知,整个效率是比较高的,这也是和高效能够对应起来的。最后是易于 debug,如果开发人员说监控没有报警或者误报警,如何 debug 这个信息,快速修复问题。这是我对高可靠的一些认识。
02 易扩展
它其实是我们系统的开发过程中,对于运维侧以及部署和扩容方面的考虑,这个系统很容易扩容和部署,它的依赖比较小。其次,它能够达到快速部署的基础是它的数据存储是要集群化管理,而不是数据和单机绑定,它的服务逻辑层需要去可水平扩展,随着业务对监控的需求不断增加,监控的压力变大的时候,能够快速地进行服务层面的水平扩展。
03 自适应
我认为这点比较重要。我们很多传统的监控系统都是比较机械一点,为什么说机械?就是说它监控的添加、修改之类的,都是需要我们人工手动的做一些很多冗余的操作,而不能随着服务器服务,我们监控对象的生命周期的运转,比如说服务器上线、下线、运维、维修、新添加的服务或者服务下线,能够进行动态关联,监控也随着这些对象的生命周期进行变化。还有是人员流转,我们经常会遇到公司内部的员工入职、转岗、离职等方面,还会随着他的岗位状态运转能够自动匹配,是否对它进行报警发送以及删除。
04 开放性
首先是要对外提供 SDK 或者 API ,除了我们自己运维侧采集一些监控,提供一些既有的监控,还允许第三方开发和其他的人员对监控人员 push 一些数据,以及对这些数据的读取、处理。
这样几个特征,我认为是构成高效监控系统的必要因素。
如何做好监控系统的选型和设计?

谈这点需要基于公司的现状去谈这个选型和设计。因为在创业初期,最开始可能对运维和监控的关注度并不高,我们在这块用于很粗粒度的方式去解决。拿七牛云来说,从现在往前推一年的时间,用的监控有 32 套单机版的 Prometheus。
具体说说它的问题。首先单机 Prometheus,它是一个开源很强大的单机版监控,它的问题也是它的特点,有一套很牛逼的查询语法,支持强大的数据查询功能,能够满足各种方位、各种姿势对数据的需求,通过它的语句组合。这样也导致了一个问题,运维人员如果没有深入研究这套语法的话,就很难掌握灵活的语句去配置你的报警,存在的问题是少数人能够掌握这个问题,学习成本比较高,而精通的人更少。
目前这个 Prometheus 没有比较好的分布式解决方案,所以出现了 32 套 Prometheus 分业务去构建它的监控,而且可能一个业务里面还存在多套 Prometheus,因为受到单机性能的影响,随着监控指标数据量不断增加,出现了这个瓶颈,出现之后我们还要再进行扩容。这样长时间下来,会出现多套集群套用,数据和配置分布杂乱,无统一入口。
我们做的更多是添加监控、修改阈值和条件,原生的 Prometheus 是通过配置文件的方式,Prometheus 启动的时候加载,然后会出现的配置文件大概有好几千行,一行代表一个监控,一行是一个非常复杂的查询语句,每天有好多监控的需求,需要重复的修改这些配置文件,无界面化管理,操作效率非常低。
最后一个问题,我认为比较重要的是监控和我们的业务服务器,还有业务服务之间没有一个动态关联关系。因为都是静态的,有任何一方的改动都可能出现误报的情况,我们调整了机器扩容或者下线机器,需要完全手动修改配置和 Prometheus。
基于这样的情况,我们期望改善这个现状,因为这样的规模只会让情况变的越来越糟,不符合高效运维的定义。
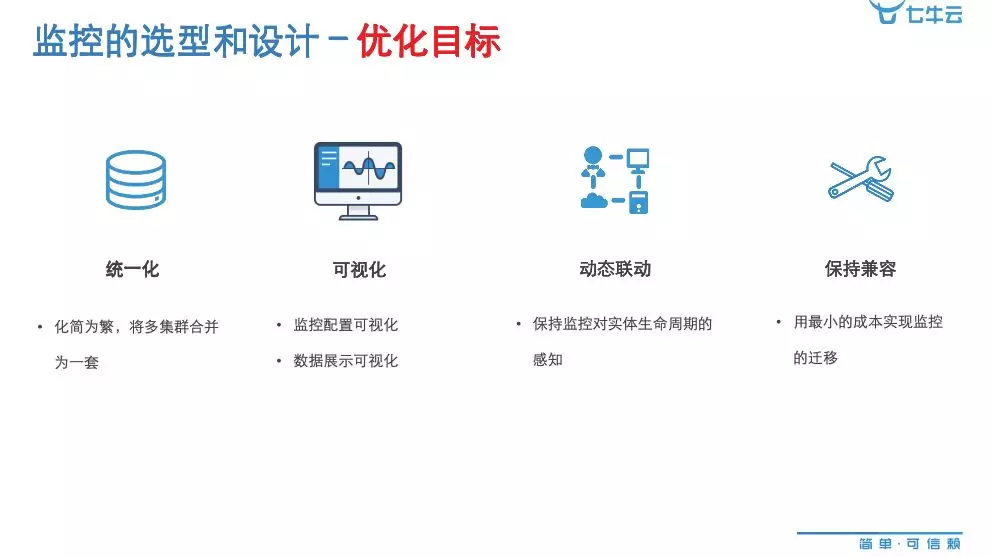
首先设立几个目标,第一个是如何把这 32 套 Prometheus 进行统一化、统一入口,作为一个运维的统一监控平台,来满足我们所有业务对于日常监控和数据处理、查询、报警的需求,第一个目标是化简为繁。第二是可视化,包括监控配置可视化和数据展示可视化。第三是动态关联,保持监控对象的动态感知能力。
第四个也比较重要,我们做一套新的监控,必须要考虑老的监控的东西需要往新的东西迁移,在迁移的时候,必须要考虑成本。如果做一套完全和新的结构迁移出东西,成本会非常高,还有历史数据的迁移,我们用了监控数据做一些东西,它的数据肯定还会迁移到新的数据上来,让它继续发挥作用。它如何迁移、如何进行兼容,我们首先定义了一个目标。
基于这个目标,我们做一个方案选型,首先还是考虑 Prometheus,因为我们以前用的是 Prometheus,它也很强大,我们不愿意放弃。

优点是组件少、部署很方便;PromQL 强大的数据查询语法。它有非常强大的查询数据的方法,比如说通常会对数据进行打标签,对这个数据的标签进行一些组合,然后查询到你需要的这些数据,在这些组合基础上,它还可以提供一些很方便的函数,比如说求和、求平均值、求方差、求最大最小、求分位数,我们通常需要写一些代码或者写一些脚本来满足这些函数能够简单达到的效果。
第三,它是一个非常高可靠的时序数库,类似于一些优秀的数据库,非常符合我们监控时序数据的存储和展示。第四,它具有非常丰富的开源社区 exporter。Prometheus 社区里面会有一些针对各种开源软件的数据收集的一些组件,都能找到对应的 exporter 组件,只要把它跑起来,不用作为一个 DBA 或者专业的运营人员,你也可以很方便的拿到数据库应该关注的指标,然后这些指标的数据表现形式是什么样的,而且配套的在平台上已经有很多开源的东西,甚至可以一键导入,可以很方便的生成数据库的大盘数据。
说完优点,我们直面它的缺点。主要是数据集群多、配置管理低下、配置报警起来没有界面,非常痛苦。

我们会调研下一个监控方案,就是 Falcon,这也是一套国内比较优秀的监控系统。它有以下几个优点:首先组件都是分布式的,没有单点模块,这符合我们高可靠的要求,每个稳定性都很高,因为它在设计的时候完全考虑到了用户的使用策略,所以所有的操作都是基于页面完成,这点比较人性化,而且支持了很丰富的监控方式和方法。
但是基于基于我们公司的原有监控,也有一些缺点。我们考虑迁移的时候,原有的监控都需要废弃,需要做两种格式的兼容,成本很高,历史数据也不能很方便的一键导入,这也是需要直面的两个问题。
我们怎么做呢?我们的选择方案是 Prometheus 分布式化,再加上 Falcon 高可用,希望能够打造一款既满足高可靠、兼容性好、配置比较简单的一套系统来解决我们监控的痛点,做到取长补短。
七牛云内部监控系统介绍
首先说一下我们监控系统在解决上面几个问题的时候,最终做出的一些比较有特色的地方。第一是联动服务树,很多公司里面都会拥有自己的监控平台,其中服务树是一个很核心的组件,联动服务树是刚才提到的一个动态关联的基石。第二个是分布式 Prometheus,可以进行数据存储和告警功能。还有一点是我们的监控是具有自动故障处理的特征功能。还有一个是监控自动添加。除了我们提供人工添加的途径外,还可以自动添加。
接下来具体介绍一下架构。
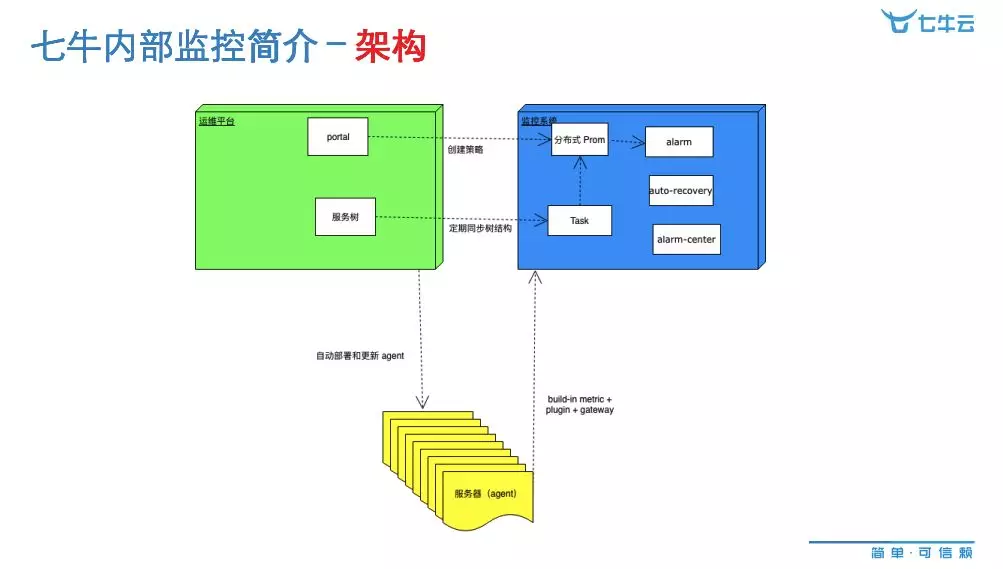
左侧绿色是我们内部的运维平台,里面的两个小块 Portal 和服务树是两个和监控有密切交互的组件。右侧是整个监控系统,监控系统里面核心是分布式 Prometheus,底下是我们的服务器集群,这是我们机房的业务机器,上面有一个 agent。具体它们之间工作的流程:我们的分布式 Prometheus 主要提供 API 层的一些策略管理、一些监控添加,还有一些数据的存储、告警触发。这边是把我们的操作进行界面化,以及 API 层面存储的工作。服务树是管理我们整个运维体系中这些对象的一个工具,它和分布式 Prometheus 之间会有一个同步的机制。Alarm 会负责告警处理、告警消息的处理,包括合并、分级、优先级调整等工作。还有我们的告警自动处理模块、数据聚合模块,用来计算出我们整个告警处理的效率和长尾统计分析的模块。还有 agent,它是系统数据收集模块。
接下来详细介绍以下几个主要的内容。
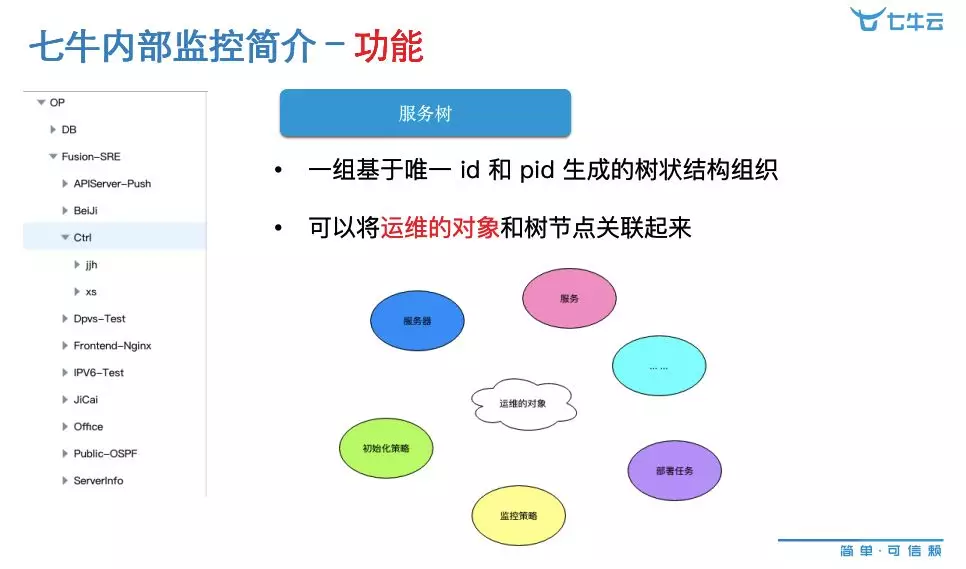
首先是服务树。左侧这一列可以看出它是树状结构的东西,它是一组基于唯一 id 和 pid 生成的树状结构组织,可以将运维的对象和树节点关联起来,包括日常的服务器、服务、初始化策略、监控策略、部署任务等等,可以称之为它的运维对象。它和某一个节点关联起来,就变成了某一个服务上面有哪些机器,以及它有哪些初始化策略、有哪些监控策略、有哪些部署任务,这些都可以和服务树关联起来。只要我们维护好这个服务树,就可以管理好日常的监控、发布、初始化等一切需求,包括服务署下面的服务器扩容、缩容,也可以在这个服务树上来管理,它是这样一个组织关系。
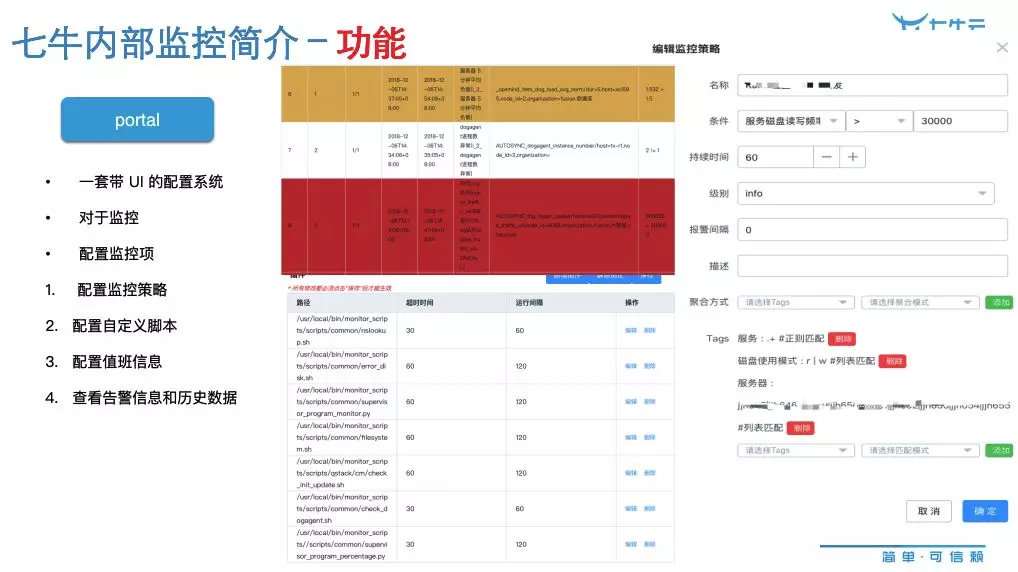
Portal 这块有很多功能,首先说一下监控性的功能,它是一套带 UI 的配置功能,对于监控,配置的监控项是配置监控策略、配置自定义脚本、配置值班信息、查看告警信息和历史数据。
我们配置的一些条件,可能是我们上报上来的东西,里面有一些 Tags,我们设置它的一些值,匹配好之后,可以对这个数据进行求和、求平均、求最大、求最小,基于此会生成一条查询语句,这样构成了一个监控策略,实际上是一条模板化的查询语句,然后在这边修改。还有告警级别、告警间隔、最大告警次数等信息。
还有自定义插件,因为现在监控的需求比较多,很多需求很难通过监控系统本身来实现,所以我们提供了插件的功能,只需要任意用脚本去写,然后按照我们的格式输出,就能把你的格式收集上来,配置对应的监控项就可以,它是绑定在某一个服务上面的脚本,针对这些服务做某些监控。
上图有一些告警数据的告警截图。我们分不同的颜色展示不同的告警级别,可能是一些微信的发送、以及对应的短信的分级通知机制。
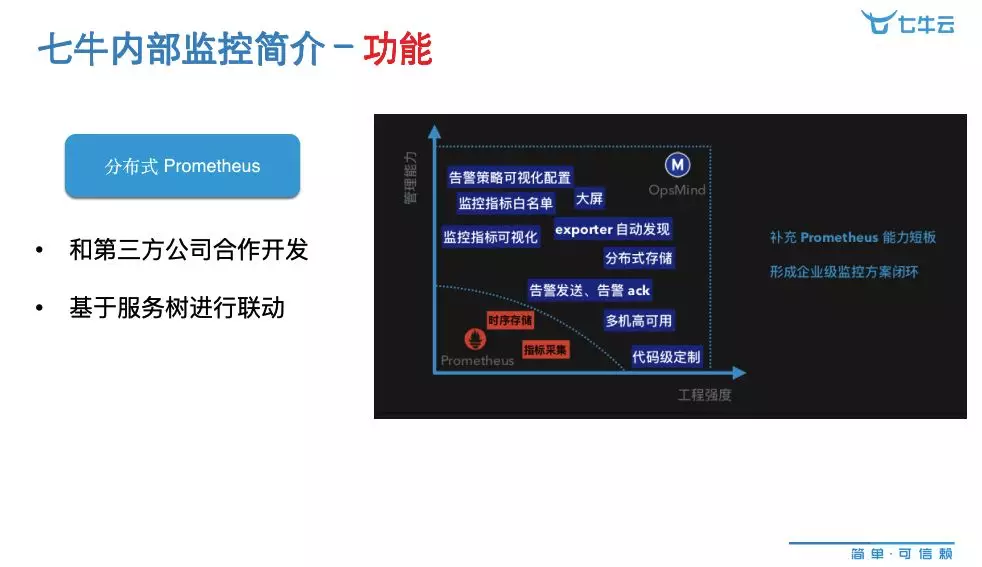
最重要的一点是分布式 Prometheus,因为 Prometheus 目前没有开源的集群化解决方案,我们是和第三方的公司进行合作开发的,用它们对原生分布式 Prometheus 进行改造,同时纳入我们服务树的一些核心的点,进行考虑合作开发一套适合公司使用的分布式 Prometheus。对于原生 Prometheus 的原生改动,主要就是把它对存储进行分离,然后把它的查询层和告警计算进行拆分,进行了多级的高可用素质,存储方面进行了存储分片、查询调动。其次是设计一些 API,能够把 Prometheus 的查询语句进行模板化,监控策略配置的时候,把它升级为一条条的存储语句存储起来,就是把原生 Prometheus 一万多条的配置文件进行系统化、界面化的过程。
因为模板语句比较复杂,所以我们提供了一个自动生成模板语句的功能,凡是用户自己配置的自定义脚本,比如要生成监控的某一个东西,只要这个监控脚本提交了这个系统,系统会自动调用它,然后给它生成模板语句,不需要关心就可以看到模板语句,有他要求的 Tags,有一些对应的约束值。
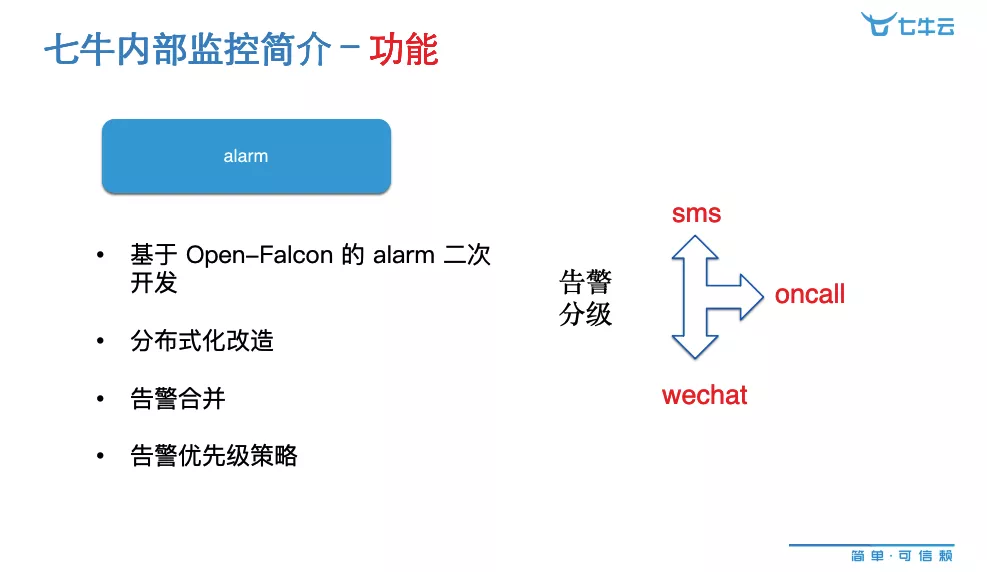
下面介绍我们的 alarm,基于 Open-Falcon 的 alarm,首先改造成分布式的,进行告警合并、告警优先级的策略,我们通常会遇到某些机器异构的情况,我们对一批机器加一个优先级告警,可能有一些机器满一两块都没有关系,我们对它进行一些特殊的策略设置。比如说告警的监控加在这块和子节点上,我们希望看到 95% 的告警进行告警,告警发生过来的时候,会有一些优先级策略的判断,会对它进行默认的屏蔽,不会通知到用户。
这个告警接入公司统一的信息通告平台,它支持我们几种用户的通知方式,重要的告警直接打电话,不重要的分别有短信、微信这些方式去通知。
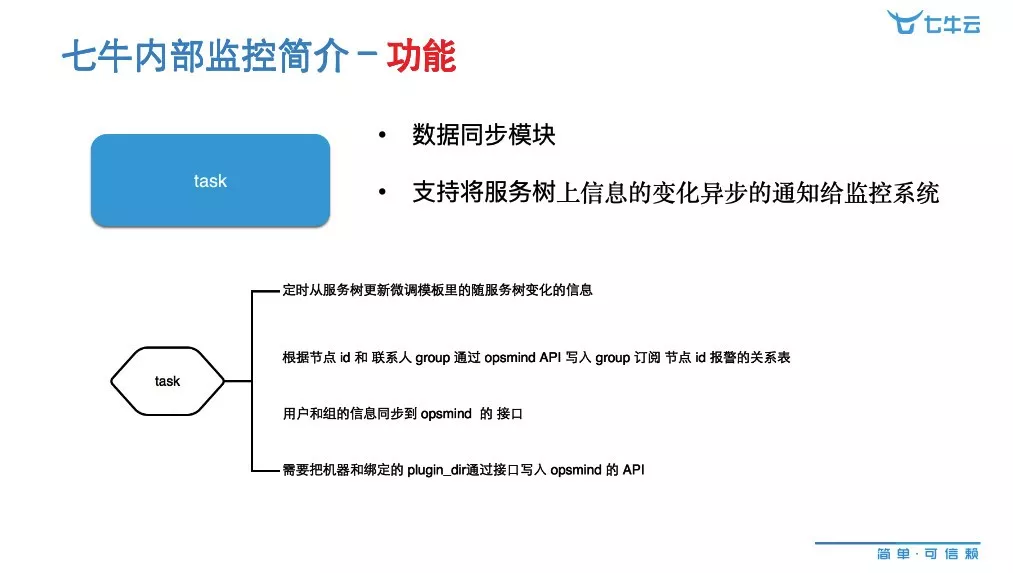
还有一个是 task,它是一个同步的模块。主要涉及到服务树上面关联的信息,通过异步的方式通知给服务器那边。就是我们服务上有哪些机器、端口是什么、进程名是什么、机器是否发生了变动、它的值班人员是什么,都会异步去通知给 Prometheus 那边,Prometheus 那边知道我这个服务上面加了哪些监控,然后从用户配置的监控策略去查询到这些数据之后去匹配这些阈值,接到告警之后,推送给值班人员,是这样一个过程,这是 task 模块起到数据同步的过程。
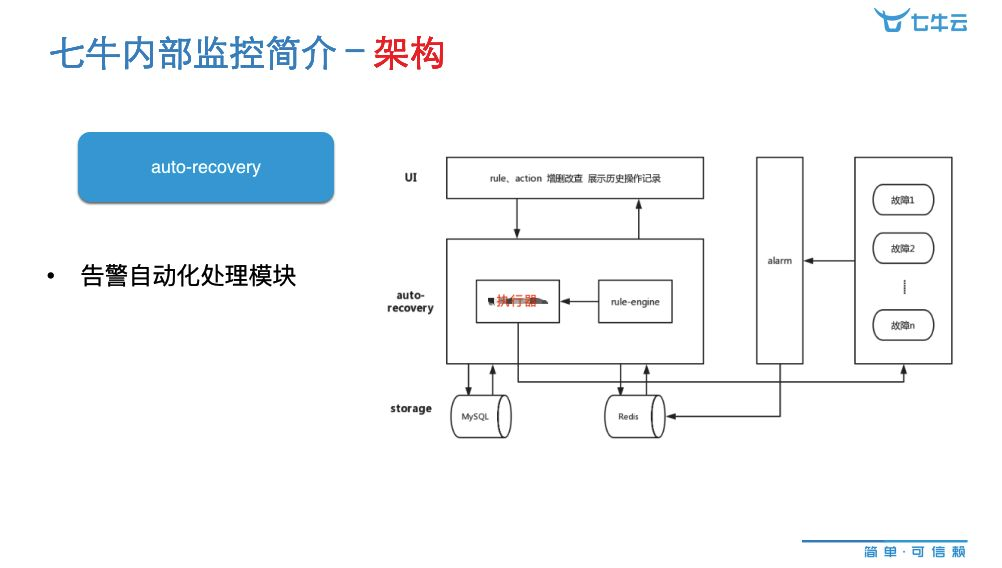
Auto-recovery 是我们做的监控自愈的模块。我们要针对某一个监控设定一定的处理机制,如果它满足某些条件,我们就对它进行自动处理。自动处理的东西是人工处理好,主要的工作流程是:在告警那边收到消息,但这个告警消息是分告警策略的,这个信息属于哪条策略,然后这个策略会对应一些规则,匹配到这些规则再去看,规定了这些告警在什么情况下满足我定义的条件,多长时间执行了多少次,然后进行 action。因为在每台机器上都会有服务器,我们有执行器,然后执行到对应的服务器,执行完之后,会把对应的结果推到微信群,历史记录和日志之类的可以去查看,这是监控自愈的情况。
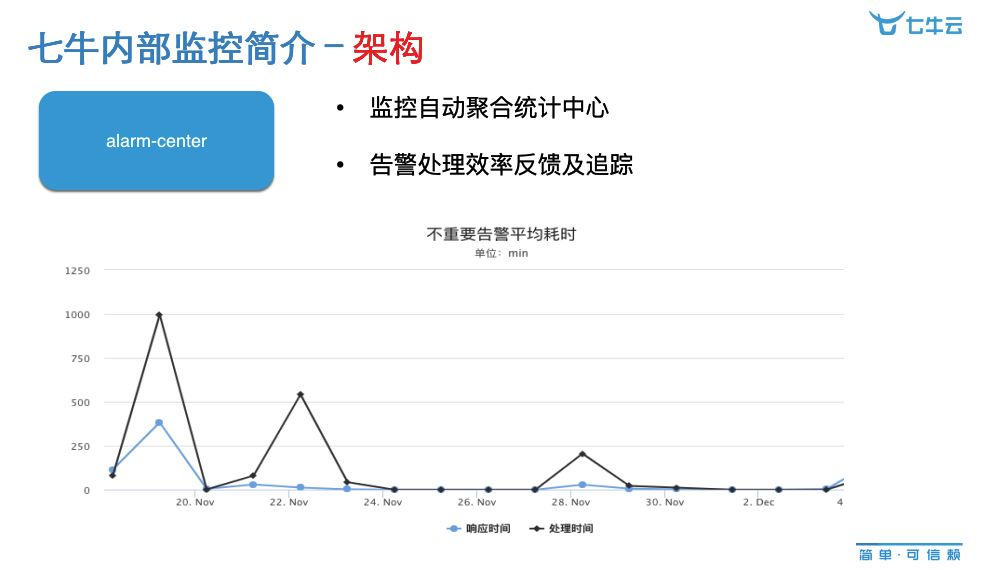
这是监控自动聚合统计的内容,告警发生了认领的过程,体现了故障处理的效率;还有一个是从认领到故障恢复,故障处理用了多长时间,它来体现我们的值班效率;还有一些告警,可能它发生的频次会比较多,我们去通过一些大数据计算的方法,然后提炼出在零散的告警里面体现不出来的一些问题,最后通过这个中心去把它发掘出来,并进行一个个的处理和追踪。

然后再说一下我们的 agent。我们这个 agent 的特点是除了收集常见的几百项监控指标之外,凡是绑定了端口的服务,这个服务进程所占用的系统资源、进程级别的,都会收集到。还有一些协议级别的,比如说我这个机器上有通过一些网络请求调动另外一个协议,这个开关比较耗资源,在某些部门才会用,打开之后它就会生成一些 Tags,然后在绘图的过程中可以看到两个服务之间消耗情况的一些指标。
还有插件执行器,我要在这个机器上执行某脚本,只要是可执行文件就行,符合我们监控系统的格式要求。
然后是 push-gateway,本地有一个 API,业务方希望把服务运行过程中的一些指标实时上报监控进行报警绘图,只要我有了 agent,就可以往 API 上面 push 数据,程序上面直接调用,就可以把数据推送到监控系统中来,进行对应的告警。
最后是探活,我们 agent 的存活保证了所有数据的可用性,可能我们 agent 已经挂掉了,如果没有收到告警就觉得一切都正常,可以探活每个 agent 的数据上报,如果有一段时间内没有收到 agent 的探活上报,说明所有的告警已经失效了,这是作为内部监控的数据。
以上就是我们内部监控的整体介绍。总结一下,目前这套系统首先已经代替了 32 套单机的 Prometheus 监控,所有的操作都在界面上进行完成,所有的监控都是具有一定的自动处理机制。在我们发布的时候,也会去自动添加这个服务相关的服务器基础建构和服务的进程端口、重要接口的一些监控。
监控的展望
第一个是说我们也比较想做好,因为现在的系统微服务比较多,相互调用的链比较复杂且比较长,现在在单机的告警情况下,客户报一个故障上来之后,我们很难快速的定位到底是哪个环节、甚至哪个函数出现了问题,而是需要人肉筛选在整个链路中到底哪个环节出了问题。这是我们下一步跟踪的方向。
第二个是基于大数据的智能化监控。现在大家都提 AIOps,我觉得 AI 要落地的话,首先要把基础的数据收集基本功做好,在这个基础上,积累一些现有的历史数据,分析一些趋势,做一些自动化的调度和自动化的处理,实现无人值守的目标。
以上是我的全部演讲内容,谢谢大家!
本文转载自公众号七牛云(ID:qiniutek)。
原文链接:
https://mp.weixin.qq.com/s/nUcy3Ieb_ifW9gdS_qUvfg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论