

在 2016 年的 Build 大会上,微软宣布全球有 12 亿人在使用 Excel,而在同一年,全球的人口为 74 亿。也就是说,使用 Excel 的人占全球人口的 16.2%。
2019 年的一份报告( https://slashdata-website-cms.s3.amazonaws.com/sample_reports/ZAamt00SbUZKwB9j.pdf)显示,Python 拥有 820 万活跃开发者,占全球人口的 0.001%。
从这些数据可以看出,增强 Excel 和 Python 之间的交互性对我们是有好处的,这为更多人打开了一扇使用 Python 工具的大门。
Python 在 Excel 前端方面的机会是巨大的。在本文中,我们将分享如何实现一个“典型的”财务 Excel 表格。
先工具,后 Excel
在几乎所有我能想到的场景中,通常是先写 Python 代码,不过必须要保持数据“输入”格式的灵活性。

改变输入数据集格式不应该影响到代码
假设我们使用 Pandas 读取一个或两个 CSV/Excel 表格,可能会依赖一组给定的列名。
如果有数千行这样的代码,我们就依赖了很多硬编码的列名,当我们试图使用 Excel 动态输入列名时,就会遇到问题。
因此,在最初的原型设计阶段,在还没有使用 Excel 工作表时,可以在代码里将列名和内部标签名映射起来:
稍后,这种映射将被 Excel 工作表取代。
Excel 前端
等到 Python 初具模型,就可以开始构建 Excel 前端了。首先,我们要确定哪些变量可以放在 Excel 工作表中。
在开发这类工具时,一般都是要假设输入数据的格式是会变的。
这点要么很重要,要么不那么重要,具体取决于你所在的工作环境以及你要开发什么样的工具。有些工作流程定义得比较好,数据格式不太可能会发生变化。
但是,我总是会倾向于保持谨慎,希望通过 Excel 来增加灵活性,但要注意不要将事情复杂化。

使用 Excel 将 Python 内部列名与外部 CSV/Excel 列名映射起来
使用内部命名系统并允许 Excel 用户指定列映射,这是保持灵活性的一个很好的例子。现在,Excel 用户不再依赖于硬编码的列名,他们可以在不修改 Python 代码的情况下调整列映射。
映射
mappings 是集成的核心部分,它的内容来自 Excel 中的一张表(我通常会叫它 Mapping)。
要得到 mappings,我们需要一个函数来读取 Excel。为此,我们使用了 openpyxl。
我们可以这样读取 Excel 中的单元格:
我们可以通过这种方式得到 mappings。我们将代码稍作调整,添加 Excel 工作簿“tool_setup.xlsx”本地路径。
我们还要假设 Excel 的当前工作表可能不是我们想要的那个,而且可能会新增、被删除或被移动,所以我们需要通过遍历找到目标工作表的索引位置:
现在,我们可以填充 mappings 内容了 :
保持灵活性
如果工作表里添加了新行或者把旧行删除,有可能会得到一个不正确的 mappings。为了避免这种情况,我们需要 search_col 函数,它会遍历查找每个单元格,直到找到包含我们想要的值(或超过 limit 限制)的单元格。
search_col 返回我们想要的数据的列和行。
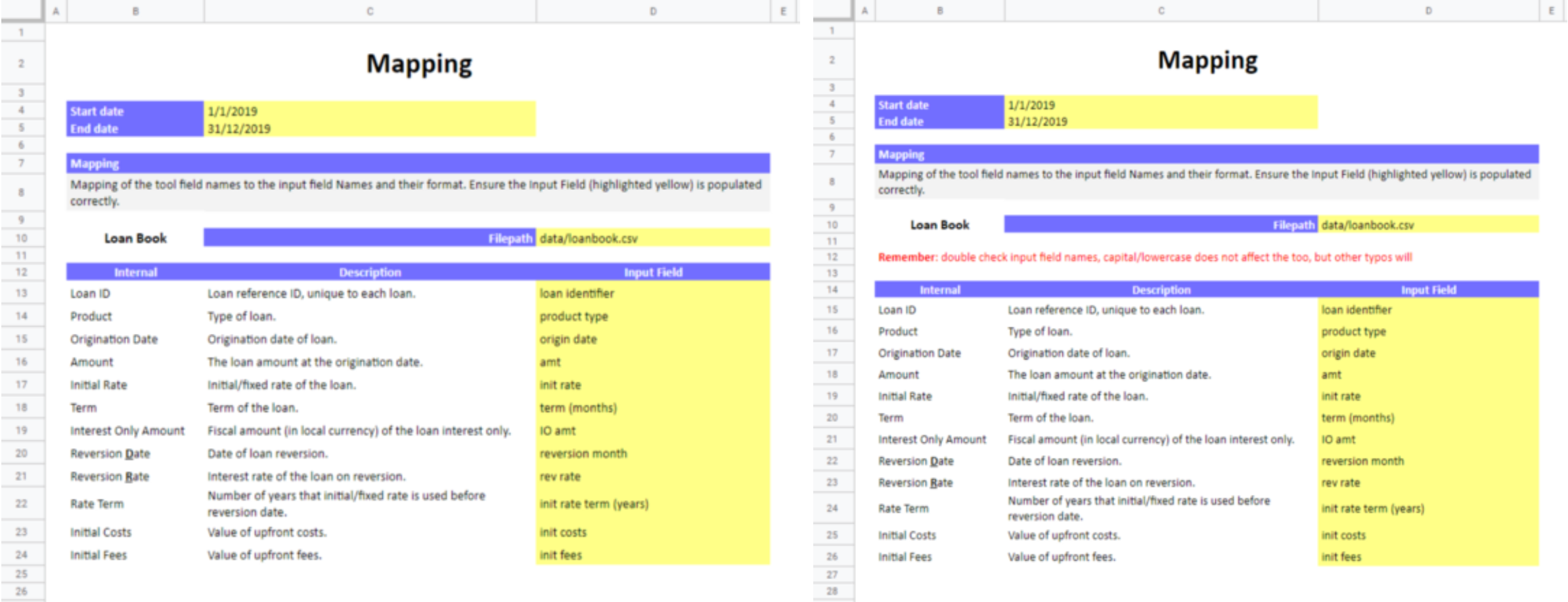
如果没处理好,哪怕是在工作表里添加一个注释也会让工具不可用。左边的“Internal”在第 12 行,而右边是第 14 行。
我们可以像下面这样找到“Internal”的单元格位置:
接下来,我们通过循环往 mappings 添加其他列映射。在遇到两个或者更多个空的单元格后,我们就知道映射内容已经全部读取完毕,就可以结束循环了:
运行上面的代码,就可以得到像下面这样的 mappings:
如果要引入其他变量,比如文件路径(filepath),我们只需要找到包含“Filepath”的单元格,并把它的值赋给“filepath”:
集成
最后一步,也是最容易的一步——在 Python 脚本中使用列名。
我们使用上面得到的 mappings,将输入列名转成内部标签。
在将输入列名转成内部标签之前,我们必须翻转键值对,即把键-值转成值-键。
对于这个简单的例子,或许在构建 mappings 时就进行翻转会更方便些。对于复杂一点的工具,我发现使用内部到外部的映射格式会更好。但不管怎样,这一切取决于你自己。
最后,将输入列名转成内部标签:
我们可以做得更灵活一些。为了处理不必要的空格或大小写拼写错误,我们重写了一小部分代码:
另外,我们在 Excel 中显示内部标签时通常会使用首字母大写和正常空格,而在内部我个人还是选择蛇形命名格式。
结论
我曾见过无数家重度使用 Excel 的公司,这么做可以节省数百个小时用于检查单元格、输入值或等待 Excel 模型处理数据的时间。
尽管自动化和机器学习时代正在迅速地将 Excel 的很多领域自动化,但 Excel 不会很快就消失掉。
目前,世界上发展最快的编程语言(Python)和世界上使用最为广泛的软件(Excel)之间的紧密集成可以给很多行业带来巨大收益。
原文链接:
https://towardsdatascience.com/excel-to-python-79b01638f2d9

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论