

Kubernetes 已经成为企业新一代云 IT 架构的重要基础设施,但是在企业部署和运维 Kubernetes 集群的过程中,依然充满了复杂性和困扰。阿里云容器服务自从 2015 年上线后,一路伴随客户和社区的成长,目前托管着上万的 K8s 集群来支撑全球各地的客户。我们对客户在规划集群过程中经常会遇见的问题,进行一些分析解答。试图缓解大家的“选择恐惧症”。

如何选择 Worker 节点实例规格?
裸金属还是虚拟机?
在Dimanti 2019年的容器调查报告中,对专有云用户选择裸金属服务器来运行容器的主要原因进行了分析。
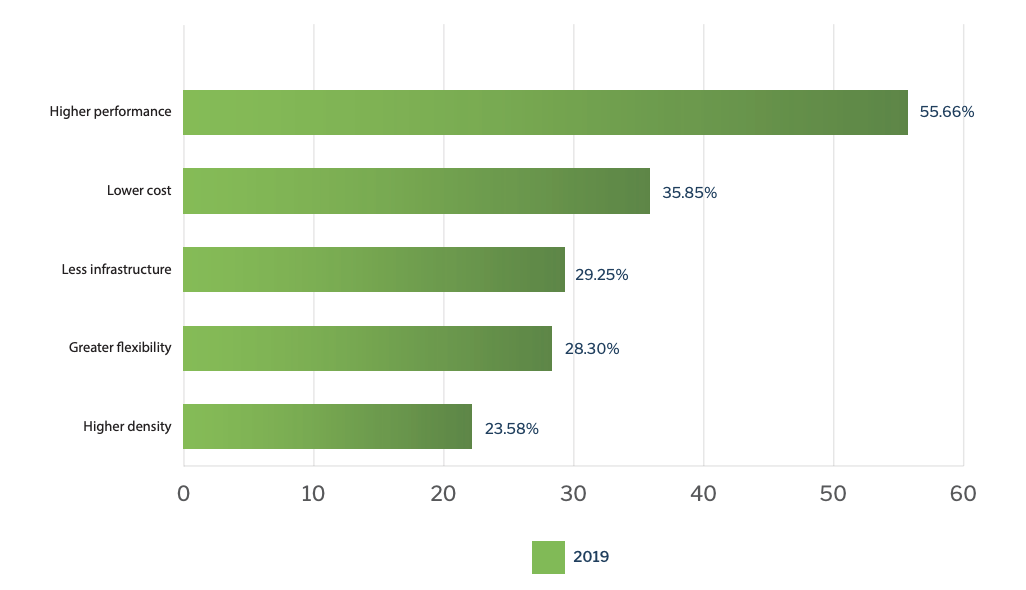
选择裸金属服务器的最主要原因(超过 55%)是:传统虚拟化技术 I/O 损耗较大;对于 I/O 密集型应用,裸金属相比传统虚拟机有更好的性能表现
此外近 36%的客户认为:裸金属服务器可以降低成本。大多数企业在初始阶段采用将容器运行在虚拟机的方案,但是当大规模生产部署的时候,客户希望直接运行在裸金属服务器上来减少虚拟化技术的 license 成本(这也常被戏称为“VMWare 税”)。
还有近 30%的客户因为在物理机上部署有更少的额外资源开销(如虚拟化管理、虚拟机操作系统等);还有近 24%的客户选择的原因是:可以有更高的部署密度,从而降低基础设施成本。
超过 28%的客户认为,在物理机上可以更加灵活地选择网络、存储等设备和软件应用生态。
在公共云上,我们应该如何选择呢?
2017 年 10 月,阿里云“神龙架构”横空出世。弹性裸金属服务器(ECS Bare Metal Instance)是一款同时兼具虚拟机弹性和物理机性能及特性的新型计算类产品,实现超强超稳的计算能力,无任何虚拟化开销。阿里云 2019 年 8 月重磅发布了弹性计算第六代企业级实例,基于神龙架构对虚拟化能力进行了全面升级
基于阿里自研神龙芯片和全新的轻量化 Hypervisor - 极大减少虚拟化性能开销
基于阿里云智能神龙芯片和全新的轻量化 VMM,将大量传统虚拟化功能卸载到专用硬件上,大大降低了虚拟化的性能开销,同时用户几乎可以获得所有的宿主机 CPU 和内存资源,提高整机和大规格实例的各项能力,尤其是 I/O 性能有了大幅度提升。
使用最新第二代英特尔至强可扩展处理器 - E2E 性能提升
使用最新一代 Intel Cascade Lake CPU, 突发主频提升至 3.2GHz, 各场景 E2E 性能大幅提升,并在深度学习的多种场景有数倍的提升。
给企业级场景带来稳定和可预期的表现 - 全球最高水准 SLA
针对软硬件优化以及更加实施更细致的 QoS 手段,给企业级客户的负载提供更稳定可预期的性能。
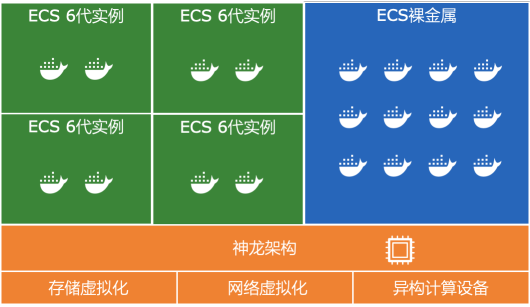
一般而言建议:
对性能极其敏感的应用,如高性能计算,裸金属实例是较好的选择。
如果需要 Intel SGX,或者安全沙箱等技术,裸金属实例是不二选择。
六代虚拟机实例基于神龙架构,I/O 性能有了显著提升,同时有更加丰富的规格配置,可以针对自身应用需求灵活选择,降低资源成本。
虚拟机实例支持热迁移,可以有效降低运维成本。
阿里云 ACK K8s 集群支持多个节点伸缩组(AutoScalingGroup),不同弹性伸缩组支持不同的实例规格。在工作实践,我们会为 K8s 集群划分静态资源池和弹性资源池。通常而言,固定资源池可以根据需要选择裸金属或者虚拟机实例。弹性资源池建议根据应用负载使用合适规格的虚拟机实例来优化成本、避免浪费,提升弹性供给保障。
此外由于裸金属实例一般 CPU 核数非常多,大规格实例在使用中的挑战请参见下文。
较少的大规格实例还是较多的小规格实例?
一个引申的问题是,如何选择实例规格?我们列表对比一下
默认情况下,kubelet 使用 CFS 配额 来执行 pod 的 CPU 约束。当节点上运行了很多 CPU 密集的应用时,工作负载可能会迁移到不同的 CPU 核,工作负载的会受到 CPU 缓存亲和性以及调度延迟的影响。当使用大规格实例类型时,节点的 CPU 数量较多,现有的 Java,Golang 等应用在多 CPU 共享的场景,性能会出现明显下降。所有对于大规格实例,需要对 CPU 管理策略进行配置,利用 CPU set 进行资源分配。
此外一个重要的考虑因素就是 NUMA 支持。在 NUMA 开启的裸金属实例或者大规格实例上,如果处理不当,内存访问吞吐可能会比优化方式降低了 30%。Topology 管理器可以开启 NUMA 感知 https://kubernetes.io/docs/tasks/administer-cluster/topology-manager/ 。但是目前 K8s 对 NUMA 的支持比较简单,还无法充分发挥 NUMA 的性能。
阿里云容器服务提供了 CGroup Controller 可以更加灵活地对 NUMA 架构进行调度和重调度。
如何容器运行时?
Docker 容器还是安全沙箱?
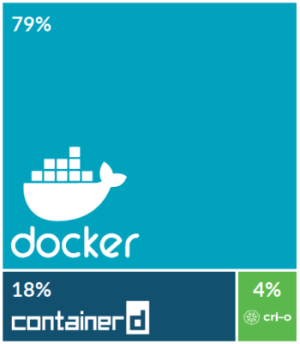
在 Sysdig 发布的 2019 容器使用报告中,我们可以看到 Docker 容器占据市场规模最大的容器运行时 (79%),containerd 是 Docker 贡献给 CNCF 社区的开源容器运行时,现在也占据了一席之地,并且得到了厂商的广泛支持;cri-o 是红帽公司推出的支持 OCI 规范的面向 K8s 的轻量容器运行时,目前还处在初级阶段。
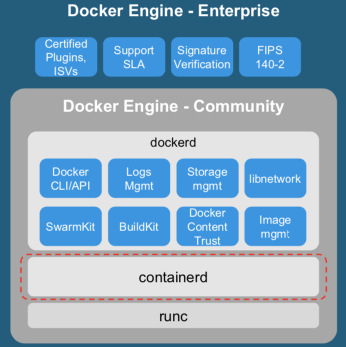
很多同学都关心 containerd 与 Docker 的关系,以及是否 containerd 可以取代 Docker?Docker Engine 底层的容器生命周期管理也是基于 containerd 实现。但是 Docker Engine 包含了更多的开发者工具链,比如镜像构建。也包含了 Docker 自己的日志、存储、网络、Swarm 编排等能力。此外,绝大多数容器生态厂商,如安全、监控、日志、开发等对 Docker Engine 的支持比较完善,对 containerd 的支持也在逐渐补齐。所以在 Kubernetes 运行时环境,对安全和效率和定制化更加关注的用户可以选择 containerd 作为容器运行时环境。对于大多数开发者,继续使用 Docker Engine 作为容器运行时也是一个不错的选择。
此外,传统的 Docker RunC 容器与宿主机 Linux 共享内核,通过 CGroup 和 namespace 实现资源隔离。但是由于操作系统内核的攻击面比较大,一旦恶意容器利用内核漏洞,可以影响整个宿主机上所有的容器。
越来越多企业客户关注容器的安全性,为了提升安全隔离,阿里云和蚂蚁金服团队合作,引入安全沙箱容器技术。19 年 9 月份我们发布了基于轻量虚拟化技术的 RunV 安全沙箱。相比于 RunC 容器,每个 RunV 容器具有独立内核,即使容器所属内核被攻破,也不会影响其他容器,非常适合运行来自第三方不可信应用或者在多租户场景下进行更好的安全隔离。
阿里云安全沙箱容器有大量性能优化,可以达到 90%的原生 RunC 性能
利用 Terway CNI 网络插件,网络性能无损。
利用 DeviceMapper 构建了⾼速、稳定的容器 Graph Driver
优化 FlexVolume 和 CSI Plugin,把 mount bind 的动作下沉到沙箱容器内,从而避开了 9pfs 带来的性能损耗。
而且,ACK 为安全沙箱容器和和 RunC 容器提供了完全一致的用户体验,包括日志、监控、弹性等。同时,ACK 可以在一台神龙裸金属实例上同时混布 RunC 和 RunV 容器,用户可以根据自己的业务特性自主选择。
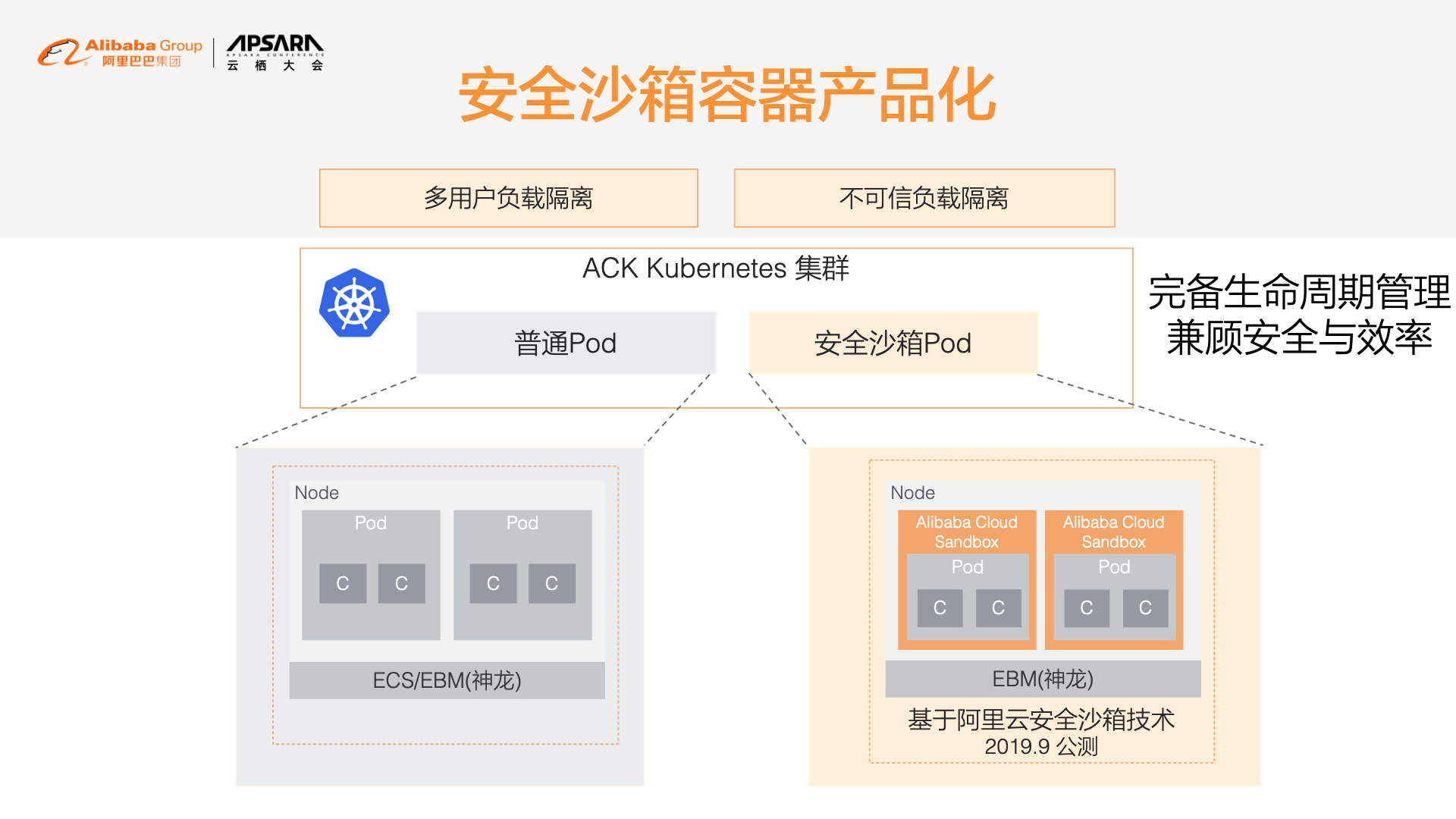
同时,我们也要看到安全沙箱容器还有一些局限性,现有很多日志、监控、安全等工具对独立内核的安全沙箱支持不好,需要作为 sidecar 部署在安全沙箱内部。
对于用户而言,如果需要多租户隔离的场景,可以采用安全沙箱配合 network policy 来完成,当然也可以让不同租户的应用运行在不同的虚拟机或者弹性容器实例上,利用虚拟化技术来进行隔离。
注意:安全沙箱目前只能运行在裸金属实例上,当容器应用需要资源较少时成本比较高。可以参考下文的 Serverless K8s 有关内容。
如何规划容器集群?
一个大集群还是一组小集群?
在生产实践中,大家经常问到的一个问题是我们公司应该选择一个还是多个 Kubernetes 集群。
Rob Hirschfeld 在 Twitter 上做了一个调查,
一个大一统的的平台,支持多种应用负载、环境和多租户隔离
或者,一组以应用为中心的小集群,支持不同应用和环境的生命周期管理。
https://thenewstack.io/the-optimal-kubernetes-cluster-size-lets-look-at-the-data/
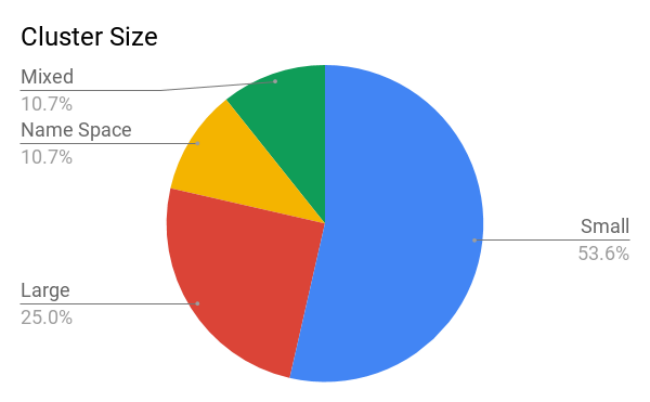
大多数的用户选择是后者,典型的场景是
开发、测试环境使用不同的集群
不同的部门使用不同的集群进行隔离
不同的应用使用不同的集群
不同版本的 K8s 集群
在用户反馈中,采用以多个小集群的主要原因在于爆炸半径比较小,可以有效提升系统的可用性。同时通过集群也可以比较好地进行资源隔离。管理、运维复杂性的增加是采用多个小集群的一个不足之处,但是在公共云上利用托管的 K8s 服务(比如阿里云的 ACK)创建和管理 K8s 集群生命周期非常简单,可以有效解决这个问题。
我们可以比较一下这两种选择
源自 Google Borg 的理念,Kubernetes 的愿景是成为 Data Center Operating System,而且 Kubernetes 也提供了 RBAC、namespace 等管理能力,支持多用户共享一个集群,并实现资源限制。 但是这些更多是 “软多租” 能力,不能实现不同租户之间的强隔离。在多租最佳实践中,我们可以有如下的一些建议
数据平面:可以通过 PSP (PodSecurityPolicy) 或者安全沙箱容器,提升容器的隔离性;利用 Network Policy 提升应用之间网络隔离性;可以通过将 nodes 和 namespace 绑定在一起,来提升 namespace 之间资源的隔离。
控制平面:Kubernetes 的控制平面包括 master 组件 API Server, Scheduler, etcd 等,系统 addon 如 CoreDNS, Ingress Controller 等,以及用户的扩展,如 3 方的 CRD (Customer Resource Definition) controller。这些组件大多不具备良好的租户之间的安全、资源和故障隔离能力。一个错误的 CRD contoller 实现有可能打挂一个集群的 API Server。
关于 Kubernetes 多租户实践的具体信息可以参考下文。目前而言,Kubernetes 对硬隔离的支持存在很多局限性,同时社区也在积极探索一些方向,如阿里容器团队的Virtual Cluster Proposal 可以提升隔离的支持,但是这些技术还未成熟。
另一个需要考虑的方案是 Kubernetes 自身的可扩展性,我们知道一个 Kubernetes 集群的规模在保障稳定性的前提下受限于多个维度,一般而言 Kubernetes 集群小于 5000 节点。当然,运行在阿里云上还受限于云产品的 quota 限制。阿里经济体在 Kubernetes 规模化上有丰富的经验,但是对于绝大多数客户而言,是无法解决超大集群的运维和定制化复杂性的。
对于公共云客户我们一般建议,针对业务场景建议选择合适的集群规模
对于跨地域(region)场景,采用多集群策略,K8s 集群不应跨地域。我们可以利用 CEN 将不同地域的 VPC 打通。
对于强隔离场景,采用多集群策略,不同安全域的应用部署在不同的集群上。
对于应用隔离场景,比如 SaaS 化应用,可以采用单集群方式支持多租,并加强安全隔离。
对于多个大规模应用,可以采用多集群策略,比如,在线应用、AI 训练、实时计算等可以运行在不同的 K8s 集群之上,一方面可以控制集群规模,一方面可以针对应用负载选择合适的节点规格和调度策略。
由于有 VPC 中节点、网络资源的限制,我们可以甚至将不同的 K8s 集群分别部署在不同的 VPC,利用 CEN 实现网络打通,这部分需要对网络进行前期规划。
如果需要对多个集群的应用进行统一管理,有如下几个考虑
利用Kubefed 构建集群联邦,ACK 对集群联邦的支持可以参考 https://help.aliyun.com/document_detail/121653.html
利用统一的配置管理中心,比如 GitOps 方式来管理和运维应用 https://github.com/fluxcd/flux
另外利用托管服务网格服务ASM,可以利用 Istio 服务网格轻松实现对多个 K8s 集群的应用的统一路由管理。
如何选择 K8s 或者 Serverless K8s 集群?
在所有的调查中,K8s 的复杂性和缺乏相应的技能是阻碍 K8s 企业所采用的主要问题,在 IDC 中运维一个 Kubernetes 生产集群还是非常具有挑战的任务。阿里云的 Kubernetes 服务 ACK 简化了 K8s 集群的生命周期管理,托管了集群的 master 节点被,但是用户依然要维护 worker 节点,比如进行升级安全补丁等,并根据自己的使用情况进行容量规划。
针对 K8s 的运维复杂性挑战,阿里云推出了 Serverless Kubernetes 容器服务 ASK。
完全兼容现有 K8s 容器应用,但是所有容器基础设施被阿里云托管,用户可以专注于自己的应用。它具备几个特点
首先它按照容器应用实际消耗的资源付费,而不是按照预留的节点资源付费
对用户而言没有节点的概念,零维护
所有资源按需创建,无需任何容量规划。
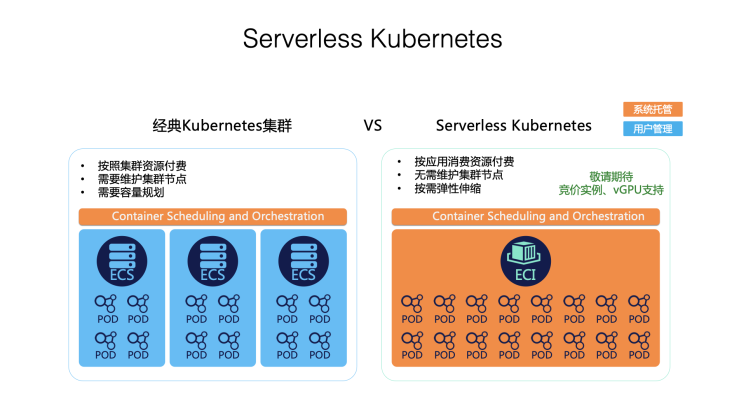
在 ASK 中,应用运行在弹性容器实例 - ECI (Elastic Container Instance)中,ECI 基于轻量虚拟机提供的沙箱环境实现应用安全隔离,并且完全兼容 Kubernetes Pod 语义。在 ASK 中我们通过对 Kubernetes 做减法,将复杂性下沉到基础设施,极大降低了运维管理负担,提升用户体验,让 Kubernetes 更简单,让开发者更加专注于应用自身。除了无需管理节点和 Master 外,我们将 DNS, Ingress 等能力通过阿里云产品的原生能力来实现,提供了极简但功能完备的 Kubernetes 应用运行环境。
Serverless Kubernetes 极大降低了管理复杂性,而且其自身设计非常适合突发类应用负载,如 CI/CD,批量计算等等。比如一个典型的在线教育客户,根据教学需要按需部署教学应用,课程结束自动释放资源,整体计算成本只有使用包月节点的 1/3。
在编排调度层,我们借助了 CNCF 社区的 Virtual-Kubelet,并对其进行了深度扩展。Virtual-Kubelet 提供了一个抽象的控制器模型来模拟一个虚拟 Kubernetes 节点。当一个 Pod 被调度到虚拟节点上,控制器会利用 ECI 服务来创建一个 ECI 实例来运行 Pod。
我们还可以将虚拟节点加入 ACK K8s 集群,允许用户灵活控制应用部署在普通节点上,还是虚拟节点上。
值得注意的是 ASK/ECI 是 nodeless 形态的 pod,在 K8s 中有很多能力和 node 相关,比如 NodePort 等概念不支持,此外类似日志、监控组件经常以 DaemonSet 的方式在 K8s 节点上部署,在 ASK/ECI 中需要将其转化为 Sidecar。
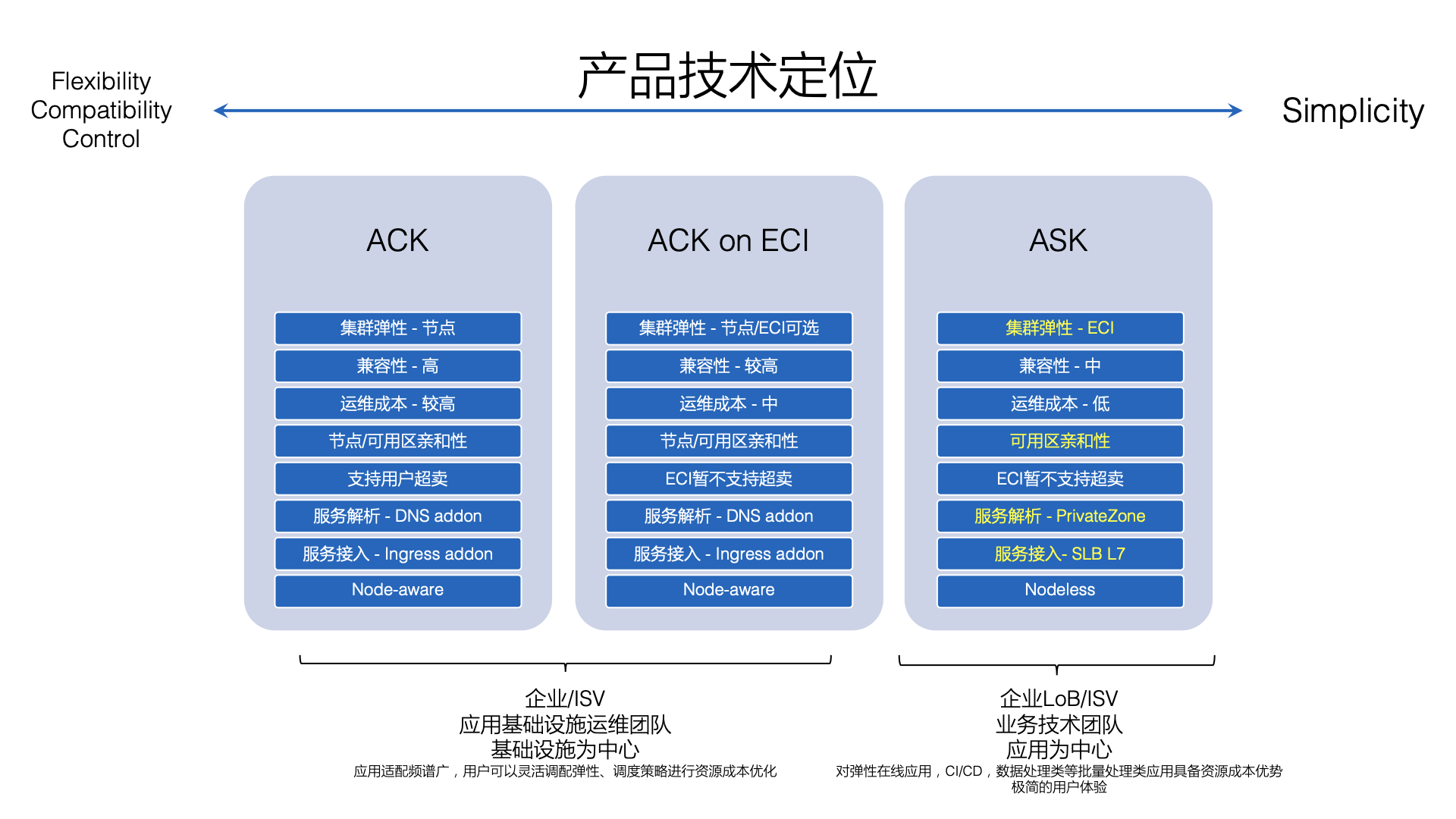
用户该如何选择 ACK 和 ASK 呢?ACK 主要面向的是基础设施运维团队,具备和 K8s 高度的兼容性和灵活性控制性。而 ASK 则是面向业务技术团队或者开发者,用户完全不需具备 K8s 的管理运维能力,即可管理和部署 K8s 应用。而 ACK on ECI,则同时支持用户负载运行在 ECS 实例或者 ECI 实例上,可以允许用户进行灵活控制。
ACK on ECI/ASK 则可以将弹性的负载通过 ECI 的方式运行,有几个非常典型的场景:
应对突发流量:ECI 基于面向容器的轻量安全沙箱,可以实现 30s 500Pod 的弹性伸缩能力,可以轻松应对突发的业务流量,在面对不确定的业务流量时,可以简化弹性配置。
批量数据处理:我们可以实现 Serverless Spark/Presto 这样的计算任务, 按需为计算任务分配计算资源。
安全隔离:有些业务应用需要运行 3 方不可信应用,比如一个 AI 算法模型,ECI 本身利用安全沙箱进行隔离,我们可以利用 ECI 隔离运行相关应用。
ACK on ECI 还可以和 Knative 这样的 Serverless 应用框架配合,开发领域相关的 Serverless 应用。
总结
合理规划 K8s 集群可以有效规避后续运维实践中的稳定性问题,降低使用成本。期待与大家一起交流阿里云上使用 Kubernetes 的实践经验。
原文链接:
https://developer.aliyun.com/article/743627

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...









评论 1 条评论