
编者按:UCloud 最新发布了名为“Sixshot”的可用区特性,用 UCloud VP 陈晓建的话说,“可用区就好比云计算的太祖长拳,看似平平淡淡,但要打得好着实不易。”太祖长拳属于南拳流派,共有四套拳路,讲求一胆、二力、三功、四气、五巧、六变、七奸、八狠。有鉴于此,解密「云计算的太祖长拳」系列将在接下来的三篇内容里,详细介绍 UCloud 可用区项目的“一胆、二力、三功”。
本文是解密「云计算的太祖长拳」系列的第一篇,将全面解析 UCloud 可用区特性技术内幕,阐述基础网络的改造和外网新特性技术实现。在项目研发过程中,UCloud 团队不因循守旧并力图有所创新、敢于打破常规改变一些已知的不合理设计,在编者看来,改革和创新皆需要胆识,本文作为系列的首篇,选太祖长拳之“一胆”开题。
从本文起,我们将会推出一个系列的分享文章,详细介绍为 UCloud 可用区项目中所涉及的软硬件技术实现,包括基础网络的改造、NFV 虚拟网关的实践、底层 SDN 控制面和数据转发面的演进以及建设在新老架构间平滑迁移海量用户数据的运营能力等各个方面,分享该项目中的一些心得和经验。
本文是这个系列的首篇,我们将介绍 UCloud 为支持可用区特性对基础网络所做的改造以及新架构下实现的外网特性。
本文大纲如下:
- 基础网络改造
- 可用区重点功能实现
- EIP 支持跨 AZ 漂移
- ULB 支持跨 AZ 后端 RS
- 共享带宽支持跨 AZ 的 EIP
- 可用区核心模块 UVER 技术实现
- 结语
基础网络改造:环网和 POP 点
从 2014 年起,UCloud 就开始致力于为分布各个地区的数据中心建设高可用高带宽的同城环网,其主旨设计思想就是将地理位置相近的多个数据中心(Data Center, 以下简称 DC)通过“双星型网络拓扑”结构连接起来,从而使任意两个数据中心之间都有高速、可靠、并具备全量冗余灾备能力的基础网络连接,如下图所示:
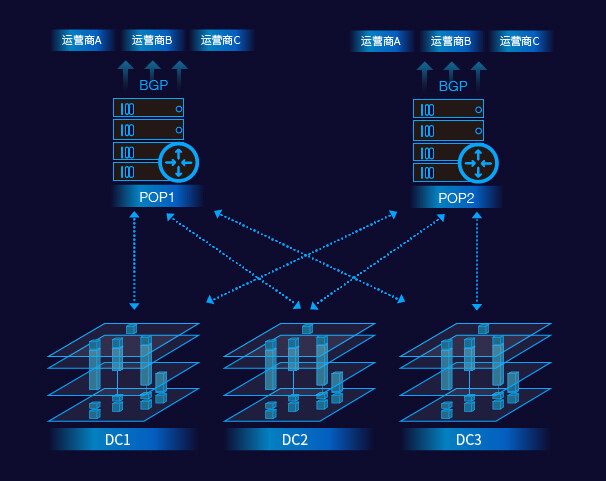
从图中可以看出,同一 Region 内的任意一个 DC 都是通过多条专有光纤和两个 POP 点相连。外网通信则是通过在 POP 点和各个上联运营商之间建设的 BGP 线路来保证的。任意两个 DC 之间都有两条全量冗余的逻辑线路(物理链路会依照现实的带宽和冗灾需要进行扩容),因此即使一个 POP 完全不可用,DC 和 DC 间,DC 和 Internet 间的网络连通也能保证联通性。
另外,由于在 POP 点和各大上联运营商都建立了 BGP peering,因此在某条运营商线路质量不佳或者出现中断的时候,可以通过调整 BGP 广播和路由的配置将用户的流量临时调度到其他的线路上去,保证网络的正常工作。
对于云计算服务商而言,具备同城多地的部署和冗灾能力是必经之路。这样的基础设施的设计和建设的能力,是一个 IaaS 服务商发展到一定规模和阶段后必然的选择。当然,所谓的一个“地域”(Region)的建设不是随意的,组成一个 Region 的数据中心除了单独在资质上需要满足各个方面的条件(供水、供电、空调、湿度、防火、防震、基础网络等等)之外,还要在协同组网上满足整体的需求,比如从 DC 到 POP 点之间的网络延迟在 0.5ms 以下,DC 与 DC 之间的网络延迟在 1ms 以下,以及 DC 到 POP 点之间的带宽要求等等。
在可用区项目的实施过程中,我们对几个 Region 的基础网络都做了大量的变更以满足我们的建设要求,比如 POP 点的建设、带宽的扩容、内外网核心的分拆调整等等。现在在华北、华东、华南,以及亚太等主力地域,我们都已完成了“双星型”POP 点的建设。
有一点需要注意的是,数据中心是一个物理概念,而可用区是一个逻辑概念,两者之间不一定是一一映射的关系。一个逻辑上的可用区(AZ)可以包含一个或多个数据中心(DC),只要这些组成同一可用区的数据中心之间的物理环境是符合我们建设标准的:

可用区重点功能实现
在一个 Region 内部署多个 AZ 并通过低延迟且全量冗余的“双星型”拓扑结构进行互联,只是满足了我们后续对可用区下平台能力改造的前提条件。在可用区产品介绍中,我们已经列举了在可用区框架下对应用服务跨地域互通、冗灾、平滑迁移等方面的一系列特性支持,如下图:
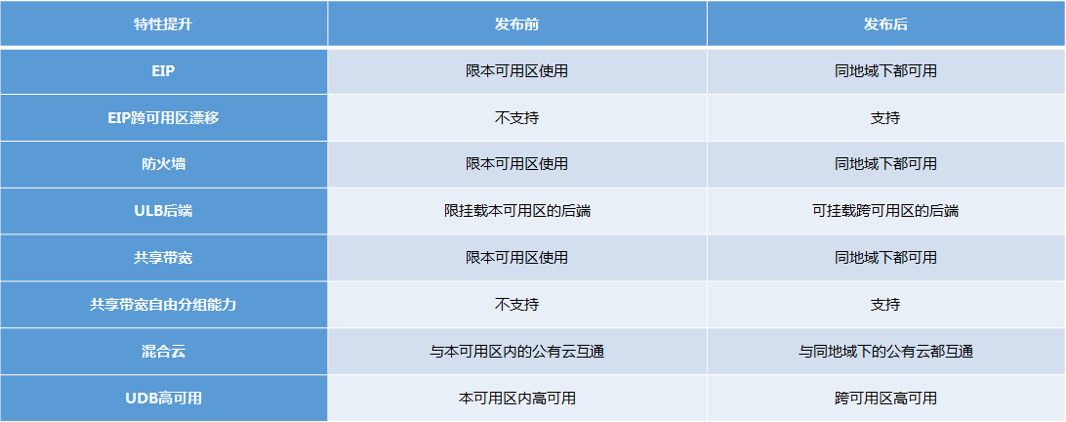
我们在这里着重针对 EIP、ULB、以及共享带宽三个产品做一个详细的技术层面的剖析,看看在可用区实现背后蕴含了哪些技术细节。
EIP 跨 AZ 使用
在原来的底层网络架构中,外网核心 (DC Core) 是下沉到每个数据中心内的。也就是说云主机在访问外网的时候,首先通过内网达到外网接入服务集群,然后报文经过处理后再经由外网核心选择合适的对端运营商线路访问 Internet。
然而,这样的架构决定了用户使用的 EIP (公网 IP 地址) 是无法跨 DC 漂移使用的。 因为上游的网络运营商一直只会和云平台之间动态交互段路由或者使用更简单的静态路由、而很少会支持云平台向他们广播全量的 BGP 明细路由,这么做的成本开销太大;另一方面,即使运营商愿意支持 BGP 交互全量明细路由,云平台自己的核心路由器也未必能支持那么大量的/32的明细路由(当然云平台可以选择购买更昂贵的高端路由器)。
因此,支持单个外网 IP 这样细粒度的跨 DC 网络流量调度一直是个难题——在实际实现中,我们发现不少友商使用的是一种变通的办法:即,不追求全部的公网 IP 地址都能跨可用区漂移,而是划分出一个特定地址段来,这个特定的 IP 段中分配的公网地址是具备跨 AZ 漂移能力的。比如 AWS EC2 所提供的 Elastic IP 就是这样的一个设计。只不过这些特殊的“弹性 IP”在使用中可能会造成一定的困扰:首先用户需要申请专门的 EIP,然后在使用时需将新申请的 Elastic IP 绑定到主机上,但此举也会同时将原主机上绑定的公网 IP 销毁,使用不方便之余,原有的 IP 也无法再找回,若有备案等原因导致原有的 IP 有一定特殊性必须要保留,这样的操作必然会带来更多的不便。
需要声明的是:这是我们根据友商所提供的产品形态,由此对其后端的实现逻辑进行的推断,可能并不一定正确,欢迎读者的讨论和指正。
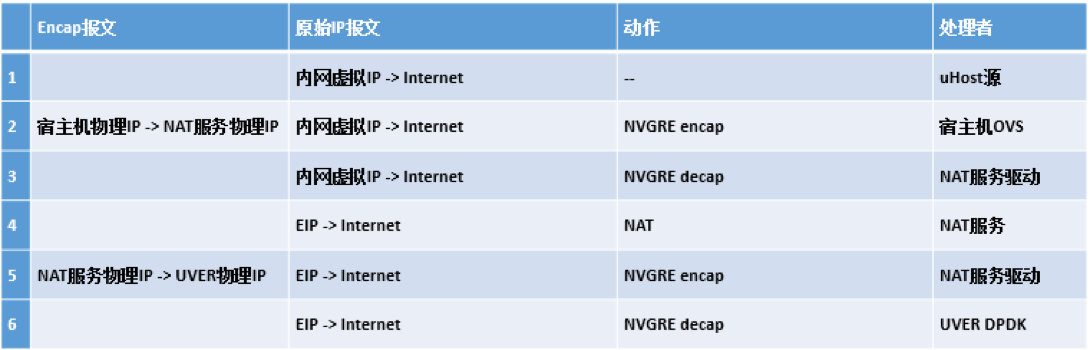
我们在对 EIP 可用区功能的扩展中,首先确定了“简化 EIP 概念”这一设计主导思想,坚决不引入第二类可能造成混淆的外网 IP 概念。在此前提下,我们决定将 DC 的外网核心上移至 POP 点,将和运营商之间的 BGP peering 终结在 POP 点。外网接入服务集群仍然分布式部署在各个 DC 中,它们能独立地为所在 DC 中的 UHost 云主机提供外网流量的报文转发处理能力。外网接入服务对报文处理的最后一步是将报文封装后通过 overlay 的隧道送达 POP 点内的虚拟边界路由服务 (UCloud Virtual Edge Router or UVER,关于 UVER 我们会在下文详细介绍),再经由 UVER 剥离 overlay 封装后送至外网的运营商线路上。UCloud 有多种的外网接入服务,以下我们以 NAT 服务为例来看一下整个数据转发面 (datapath) 经过的每一跳上的处理流程(关于 UVER 的处理动作,我们会在下文详细叙述):
我们来感受一下可用区改造前后整个架构上的区别:
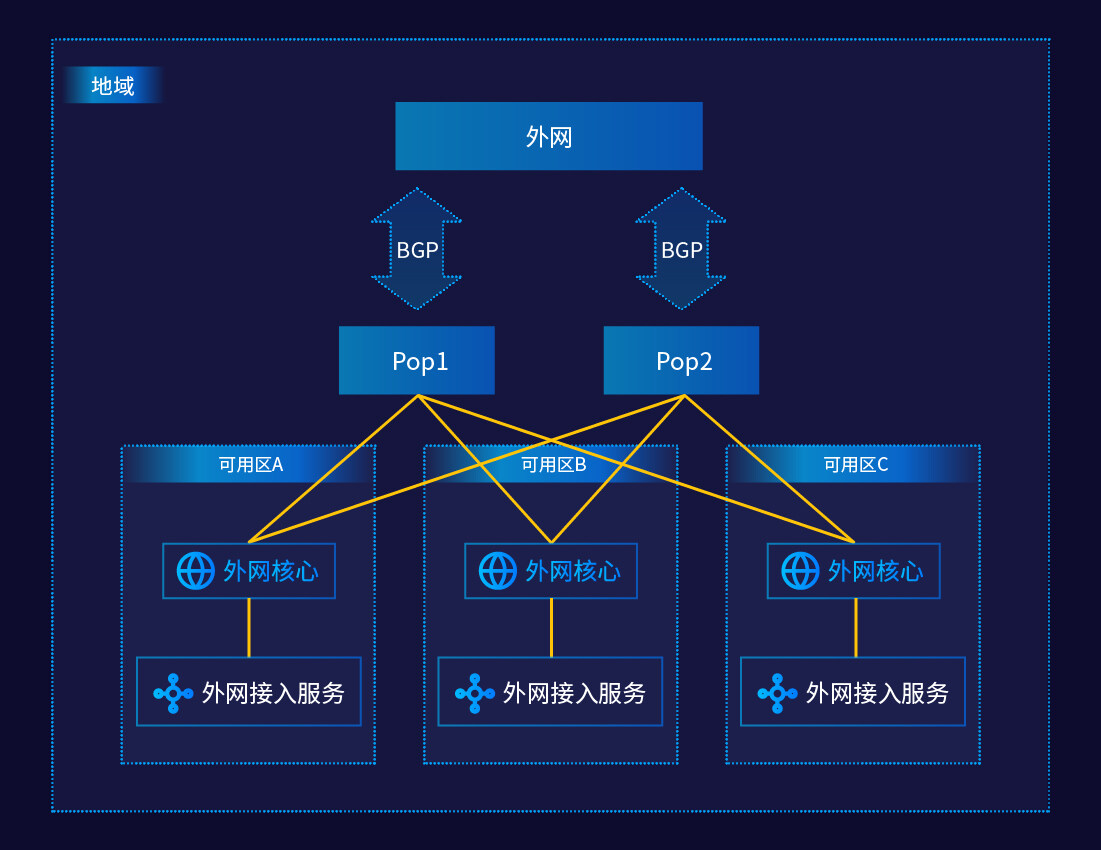
图:可用区改造前整个架构图
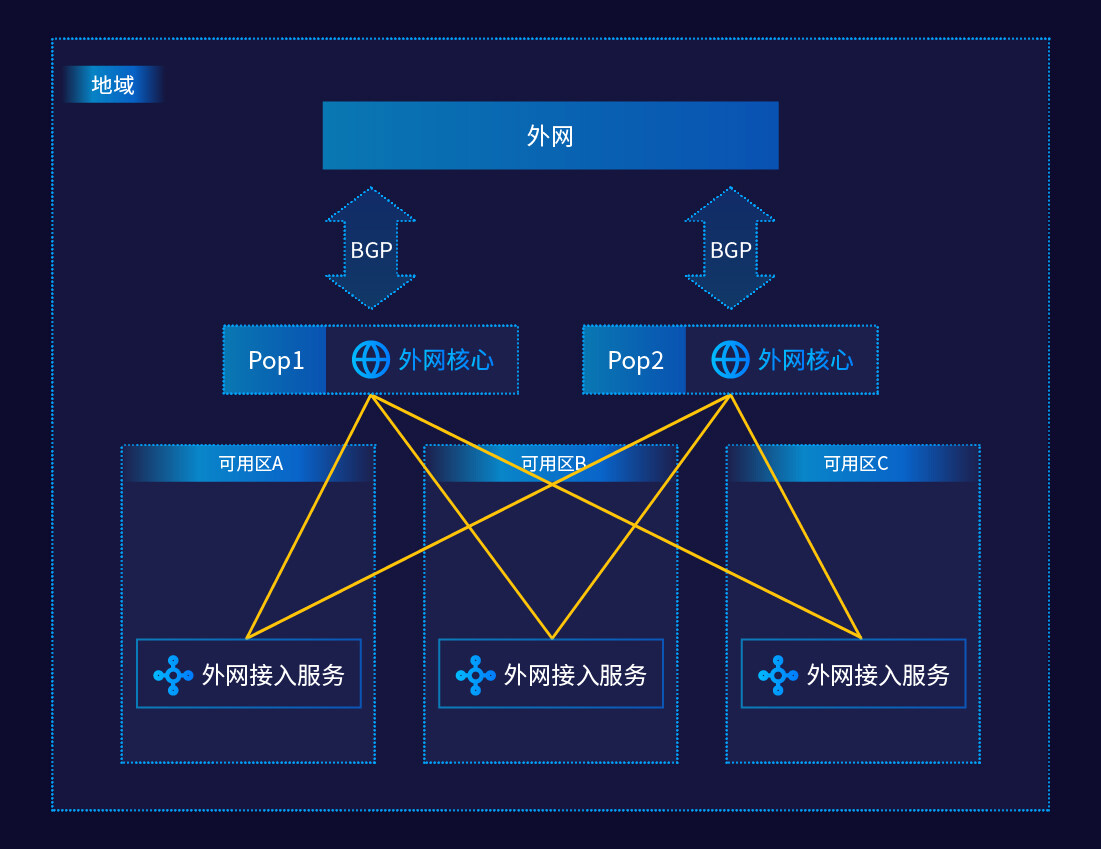
图:可用区改造后整个架构图
可以看出,通过将外网核心的上移,我们可以通过自身的 SDN 逻辑(即 UVER)将地址(源或目标)、将任意一个 EIP 的网络流量自由地在不同的 AZ 之间调度,从而实现了 EIP 的跨 AZ 漂移。
ULB 负载均衡绑定多个 AZ 的后端 RS
讨论完 EIP 之后,我们接下来看看 ULB 外网负载均衡的场景。从架构上而言,ULB 和 EIP 是很相近的:
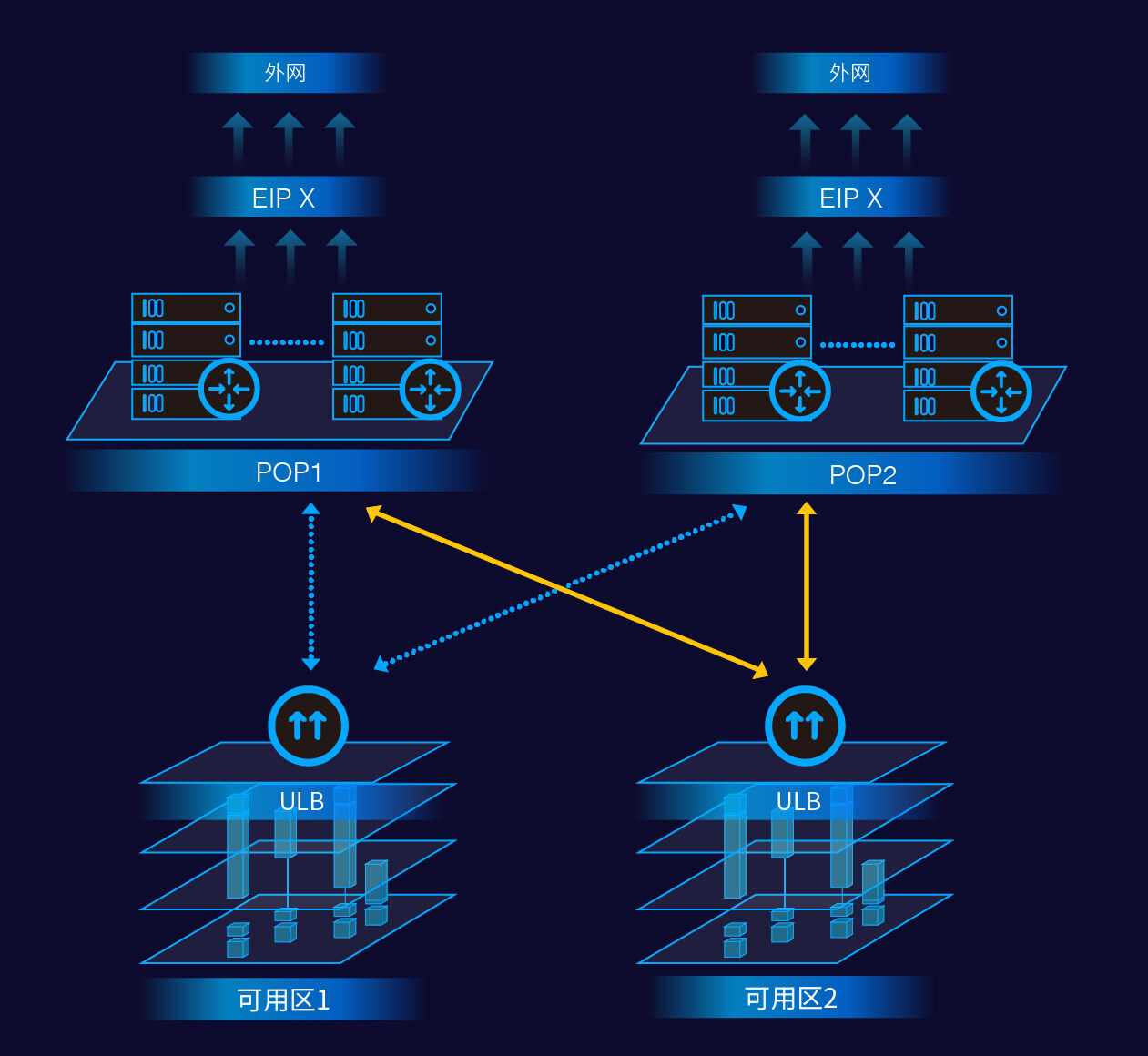
通过 UVER((UCloud Virtual Edge Router,虚拟边界路由)的调度,同一个 ULB 上的外网 IP 可以将流量分发到不同 AZ 内的后端 RS 上,这样的跨机房流量均衡和容灾的能力是很多应用层的程序架构所希望拥有的,也是云平台必须提供支持的。同样,我们来看一下整个数据转发面上各个节点的具体处理:
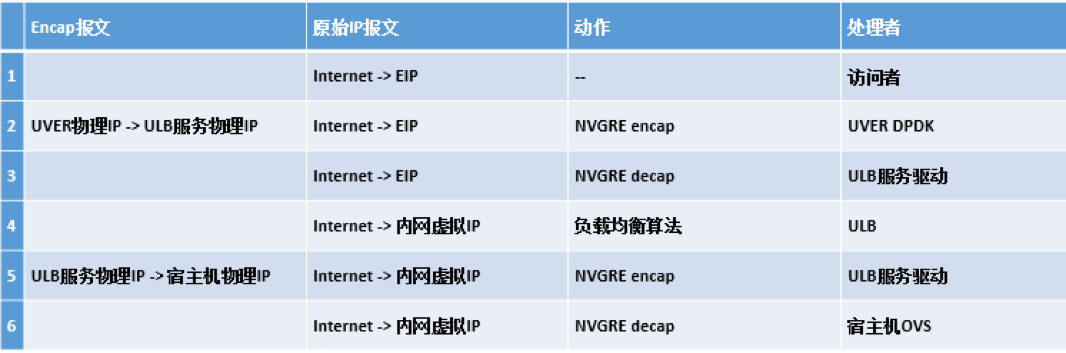
值得注意的是,如果需要的话,UVER 甚至可以将去向同一个目的 EIP 的相同端口的流量通过一致性哈希算法 ECMP 到不同的 ULB 服务器上从而大大提升单个 EIP 上可以承载的总体带宽。也可以将去向同一个目的 EIP 的不同端口的流量分发到不同类型的 ULB 服务集群。例如,80 端口分发到七层负载均衡,443 端口分发到四层负载均衡。这是 UVER 这个虚拟边界路由服务通过 SDN 的方式给平台带来的额外的弹性处理能力。
共享带宽支持不同 AZ 的 EIP
共享带宽是 UCloud 平台上一个比较特殊的带宽产品,它允许多个 EIP 共享一个带宽资源,后端控制面的程序在必要的时刻会根据每个带宽资源中包含的所有的 EIP 的实时使用数据来调整带宽的分配。在可用区之前,共享带宽只能作用于隶属同一个 DC 下的 EIP 组。但由于在可用区下,EIP 是可以跨 AZ 的,因此很自然的,共享带宽的功能也必须要能支持跨 AZ 的 EIP 组。
原先 DC 级别的共享带宽服务的架构比较简单:
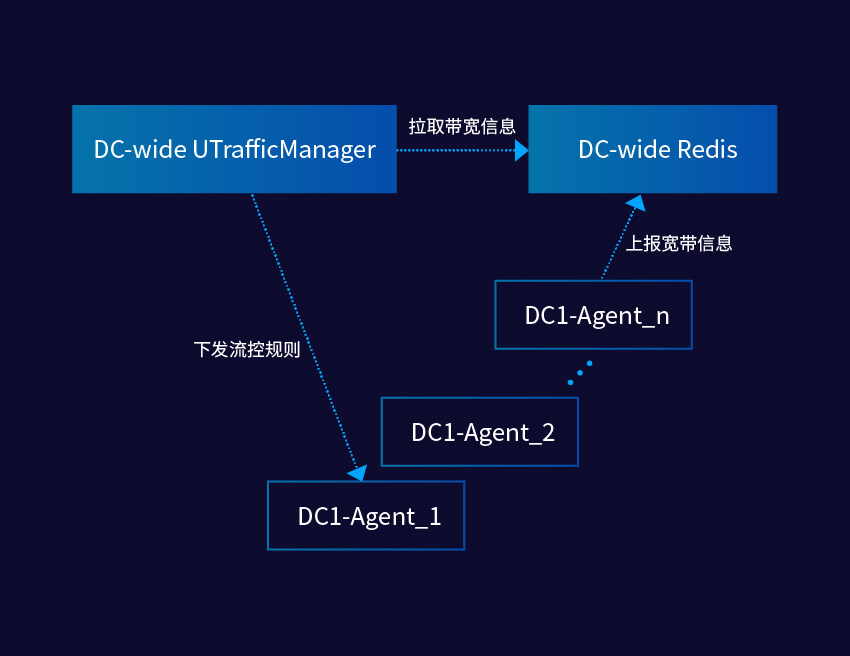
图:原先 DC 级别的共享带宽服务的架构
在每台主机上,SDN Agent 会采集 UHost 云主机实时的带宽使用数据,然后上报到后端的 Redis 缓存服务中,控制面的管理程序 (UTraffic Manager) 根据上报的结果做实时的统计并计算需要调整的带宽设置,然后通过 SDN Agent 来推送调整信令。
在可用区中,由于每个 AZ 间物理网络都是可以直连的,因此我们最初的想法就是将 Redis 缓存和 UTraffic Manager 进行扩容即可。但在进行了一番计算推演后,我们推翻了这个设计。主要原因在于,如果我们的架构在一个 Region 内只使用一套共用的后台缓存服务(当然为了容灾起见,我们会将 Redis 的集群分布在多个 AZ 内)的话,整个 Redis 缓存服务需要承载的峰值流量将是巨大的。此外,在考虑了每个 Region 后续的扩容计划之后,这个矛盾只会在日后更加凸显出来。因此我们决定对整个后台架构做一次分层的拆分:
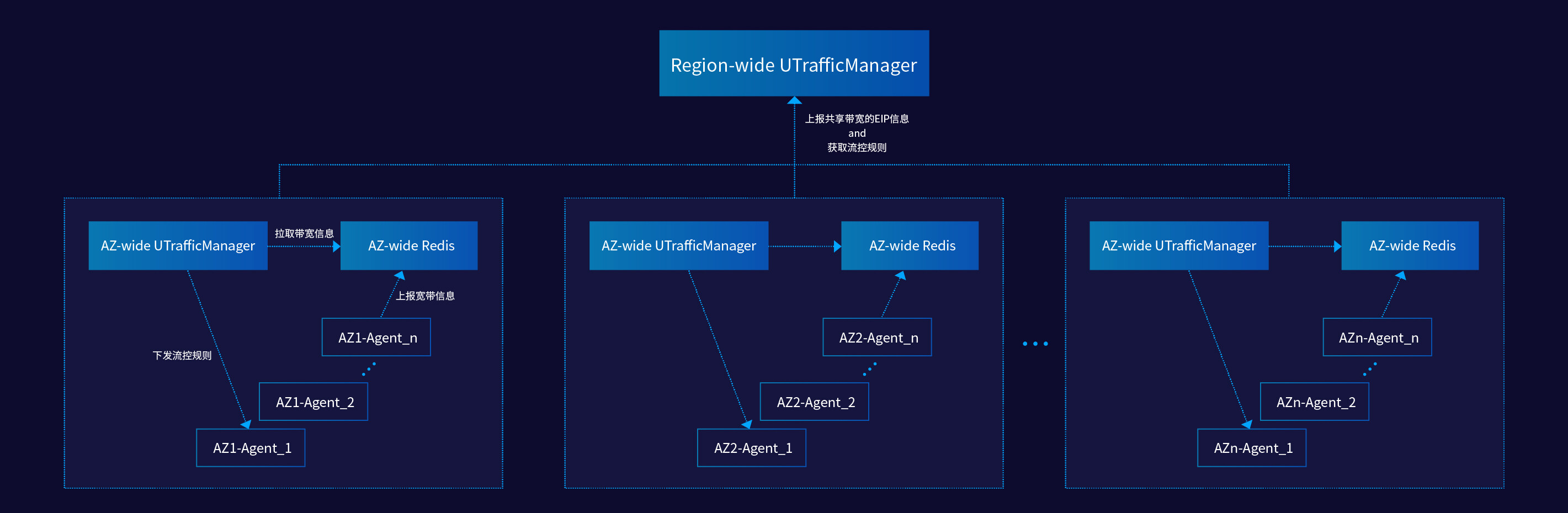
图:共享带宽服务新架构
在这个新架构下,我们在每个 AZ 会部署一套 Redis 服务。主机上的 SDN Agent 根据 AZ 属性,上报到各自 AZ 的 Redis。AZ-wide 的 UTraffic Manager 会负责拉取本 AZ 的 Redis 数据,进行第一次本地的汇总计算后,将共享带宽的 EIP 带宽信息定期上报到 Region-wide 的 UTraffic Manager。Region-wide 的 Manager,负责计算最终的实时带宽使用情况,然后决定流控策略。AZ-wide 的 UTraffic Manager 会从 Region-wide 的 UTraffic Manager 处获得指定的 EIP 的流控规则,然后主动向 SDN Agent 推送。这个新架构很好地平衡了我们对实时性和系统可用性的要求,也为之后的水平扩展做了良好的铺垫。
可用区的核心模块:UVER
跨 AZ 的网络流量调度能力是整个 UCloud 平台 SDN 基础架构上的一个简单的应用,但这一切的关键都在于拥有一个具备高性能处理能力和自适应容灾能力的边界转发服务——这就是 UVER(UCloud Virtual Edge Router)诞生的初衷。这也是本文介绍的最后一部分。
为什么需要 UVER
在 UVER 诞生之前,虽然所有的 EIP 访问都已经集中到了两个 POP 点机房,POP 点仍然是通过配置 C 段静态路由的方式将 EIP 的下一跳设置为具体某个机房的外网核心路由器。而用户可以在同 Region 内任意可用区绑定 EIP 后,EIP 的路由设置将不可能再通过静态 C 段路由的方式来设置,必须引入动态明细路由配置。而对硬件路由器来说动态路由的条目数是有限制的,虽然我们可以选择更高端型号的硬件路由器来提升支持的动态路由条目数,但是考虑到未来 UCloud 的快速发展会对硬件选型带来极大的限制,我们还是决定通过软件的方式来解决这个问题。
UVER 实现细节
我们首先来看一下 UVER 的整体架构:
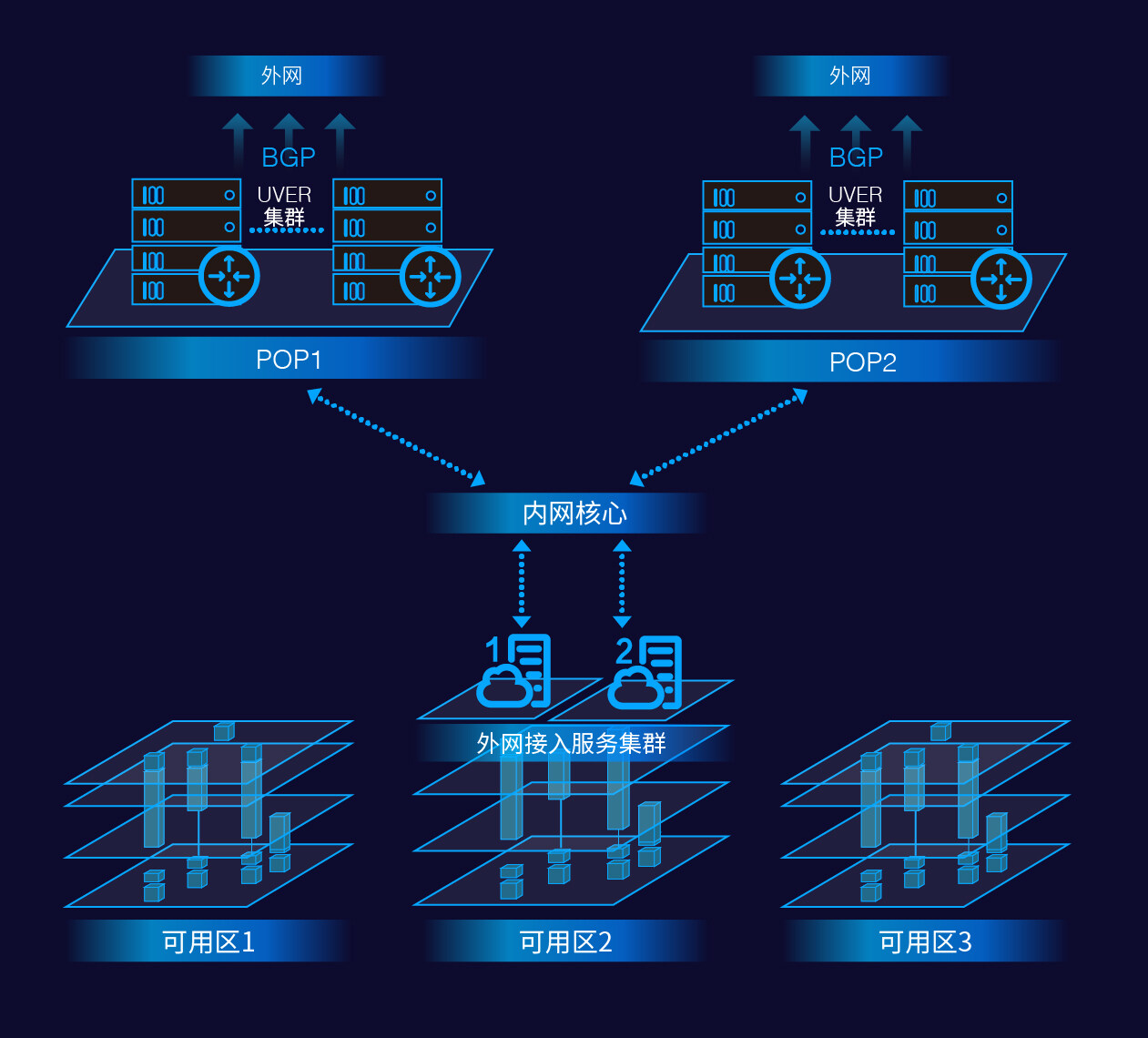
图:UVER 的整体架构
- UVER 集群部署在 POP 点,向外网接入路由器广播 C 段路由,引导 Internet 流量进入 UVER。UVER 根据数据包的目的 IP 地址,查找内存中的明细路由表中的下一跳服务器信息。
- 进行内网标准的 NVGRE 封装后通过内网接入路由器转发到具体的可用区机房的下一跳服务器上。
- 下一跳服务器需要出 Internet 的时候同样通过内网标准的 NVGRE 封装后发送到 UVER。
- UVER 服务器解除 NVGRE 封装后通过外网接入路由器发送到 Internet。UVER 采用无状态的路由模式设计,实现简单,容灾性能好。
UVER 的高可用设计
总体而言,UVER 从以下几个方面来保证集群服务的高可用性:
- 将一致性哈希算法应用于 ECMP;
- 异地容灾;
- 分 SET 部署。
目前在同一个 Region 部署了多个 UVER 的 SET,每个 SET 广播不同的 C 段 EIP 路由负责一部分 EIP 的流量。SET 间互相独立,彼此不会互相影响。同时每个 SET 内包含 2 个 POP 点的服务器,每个 POP 点服务器的规划容量都能承载整个 SET 的业务。如果有部分 EIP 的流量特别大,将通过 32 位明细路由的方式,将该 EIP 的流量牵引到独立 SET 进行服务。同时在每个 Region 还有一个特殊的 SET,称为隔离区 SET。所有检测到突发不正常流量(DDoS)的 EIP,将会被自动牵引到隔离区 SET,防止影响其他用户的正常使用。
在选择转发目标时,UVER 将一致性哈希算法应用于 ECMP,从而实现了对后端有状态的服务集群的容灾支持。即,在后端服务集群中发生宕机时,在 UVER 这层能最大限度地避免全局性的影响(比如全局哈希移位之类的问题)——理论上,只有发生宕机的那台后端服务器上的连接会发生中断需要重连,而其他通过 UVER 转发的连接是不受影响的;另一方面 UVER 集群服务器本身又是无状态的,因此 UVER 集群内部发生宕机的话,其他服务器仍能正常地对所有经过 UVER 集群的报文进行转发处理。从用户的角度看,他们的连接是不受影响的。
UVER 的性能
因为采用了 DPDK 技术设计 UVER,UVER 的单机转发性能达到 20M pps,能够提供 20G bps 的吞吐(10G 入、10G 出)。单个 UVER SET 可以最多由 32 台服务器组成 ECMP 集群,能够提供最大 320G 入、320G 出的吞吐量。而每个 Region 可以部署的 UVER SET 并没有限制。
结语
在本篇技术分享中,我们分别介绍了可用区架构下基础物理网络需要进行的改造,以及外网新特性的具体实现。第一期功能发布后,我们同时也在着力于新特性的快速迭代开发。比如,支持 ULB 实例本身跨可用区部署等。希望通过这样的分享,能够和大家一起学习和探讨那些我们乐此不疲的技术难点和解决方案。在下一篇连载中,我们将详细讨论和可用区相关的内网特性和改造的一系列技术细节,敬请期待。
关于作者
Y3(俞圆圆),UCloud 基础云计算研发中心总监,负责超大规模的虚拟网络及下一代 NFV 产品的架构设计和研发。在大规模、企业级分布式系统、面向服务架构、TCP/IP 协议栈、数据中心网络、云计算平台的研发方面积累了大量的实战经验。曾经分别供职于 Microsoft Windows Azure 和 Amazon AWS EC2,历任研发工程师,高级研发主管,首席软件开发经理,组建和带领过实战能力极强的研发团队。
感谢魏星对本文的策划与审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论