

如果您曾经写过访问关系数据库的代码,那您肯定轻车熟路。您会打开一个连接,使用它来处理一个或多个 SQL 查询或其他语句,然后关闭连接。您也许使用过操作系统、编程语言和数据库特定的客户端库。有时,您会意识到创建连接需要大量的时钟时间,消耗数据库引擎内存,并且很快发现您可以(或者必须)处理连接池和其他陷阱。听起来很熟悉?
上面我描述的这种模式以连接为导向,对于长时间运行的传统程序而言足够,设置时间可以经历数小时,甚至几天。但对于会频繁调用并且运行间隔仅为数毫秒至几分钟的无服务器函数,这就不太适合了。由于不再有长时间运行的服务器,也就没有地方存储连接识别符以便重复使用。
Aurora Serverless 数据 API
为了解决无服务器应用程序与关系数据库之间的这种错位,我们推出了一种适用于 MySQL 兼容版 Amazon Aurora Serverless 的数据 API。该 API 免除了传统连接管理所涉及的复杂性和开销,让您能够快速、轻松地执行访问和修改 Amazon Aurora Serverless 数据库实例的 SQL 语句。
数据 API 旨在满足传统应用程序和无服务器应用程序的需求。它负责管理和扩展数据库的长期性连接,并以 JSON 格式返回数据,以便于解析。所有流量都通过安全的 HTTPS 连接运行。它包含下列函数:
ExecuteStatement – 运行单个 SQL 语句,可以在一个事务中运行。
BatchExecuteStatement – 跨大量数据运行单个 SQL 语句,可以在一个事务中运行。
BeginTransaction – 开始事务处理,返回一个事务识别符。事务预计会很短(一般 2 至 5 分钟)。
CommitTransaction – 结束事务并提交其中发生的操作。
RollbackTransaction – 结束事务但不提交其中发生的操作。
每个函数都必须在 1 分钟内完成运行,并且最高可以返回 1MB 的数据。
数据 API 的使用
我可以通过 Amazon RDS 控制台、命令行或者编写调用上述函数的代码来使用数据 API。我将在本博文中向大家介绍所有这三种方式。
数据 API 的使用异常简单! 第一步是为需要的 Amazon Aurora Serverless 数据库启用此功能。我打开 Amazon RDS 控制台,找到并选中集群,然后单击修改:
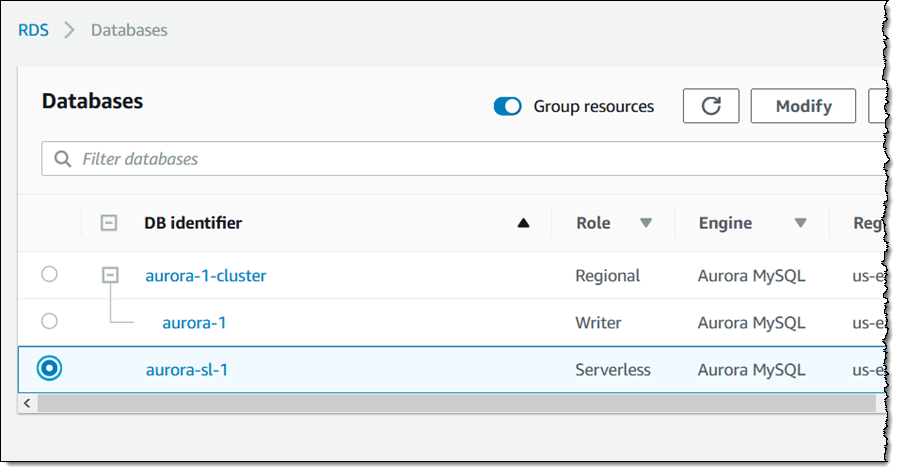
然后我下翻至网络与安全性部分,单击数据 API,然后单击继续:
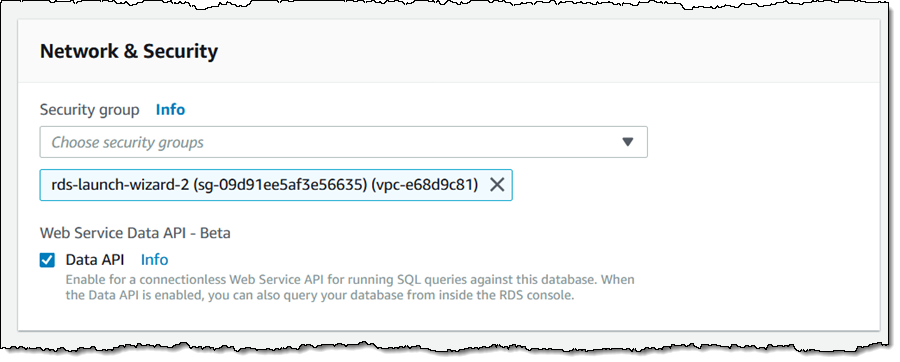
在下一页,我选择立即应用设置,然后单击修改集群:
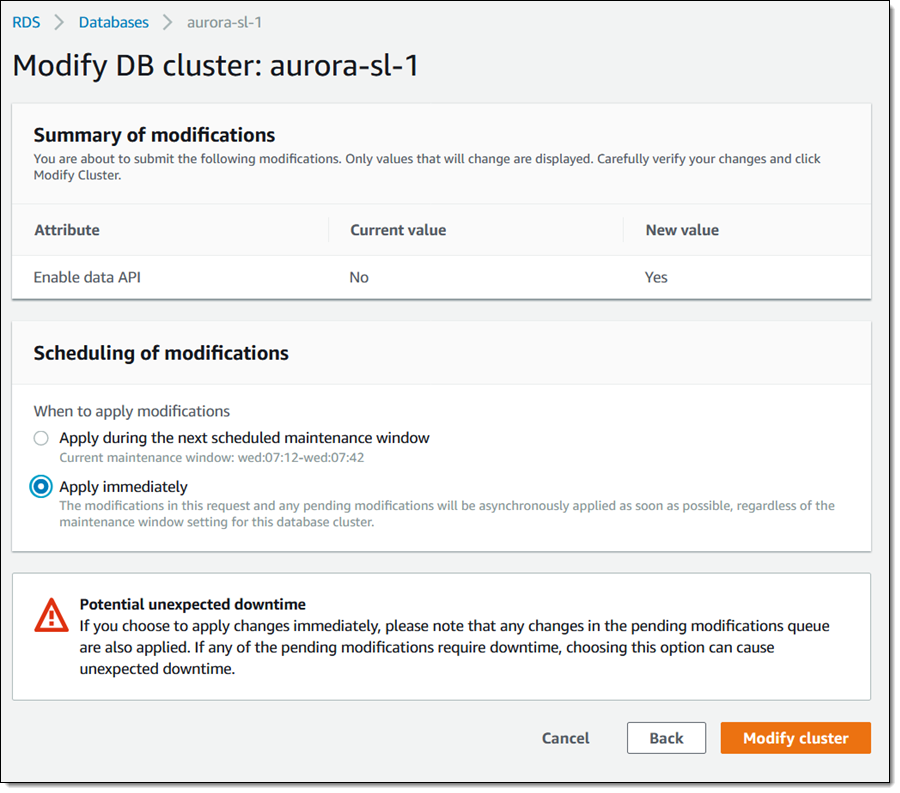
现在我需要创建一个密钥,以便存储访问我的数据库所需的凭证。我打开 Secrets Manager 控制台,然后单击存储新密钥。我选中 RDS 数据库凭证,输入有效的数据库用户名和密码,也可选择一个非默认的加密密钥,然后选中我的无服务器数据库。然后我单击下一步:
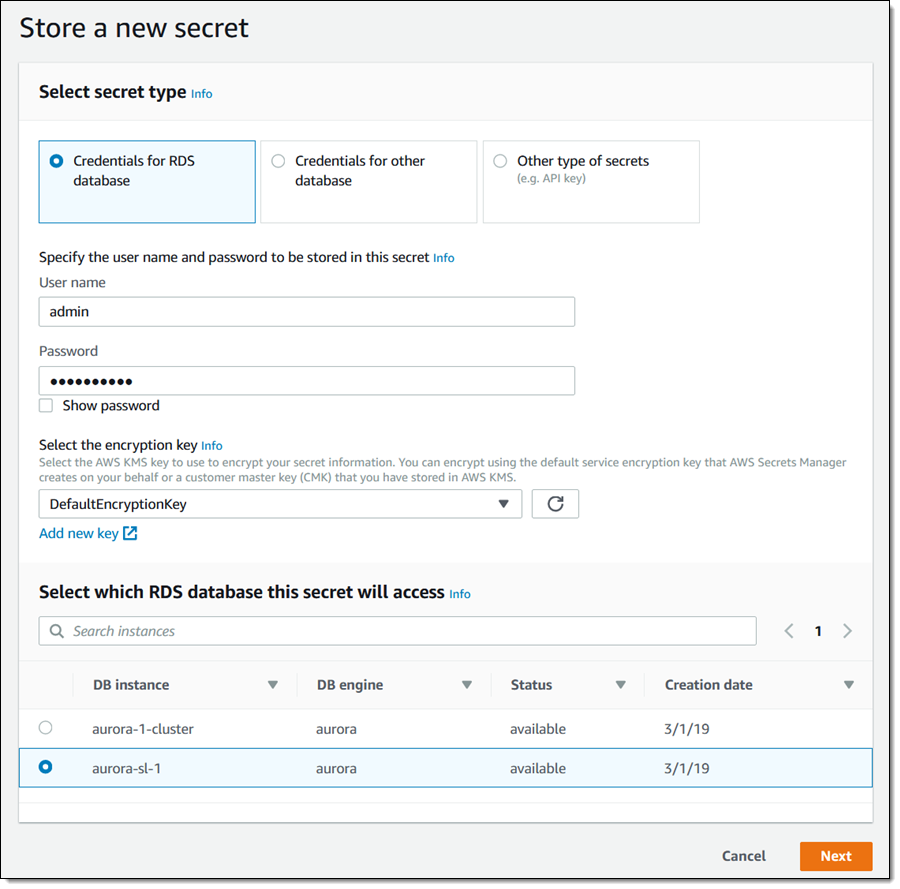
我给我的密钥命令并添加标签,然后单击下一步进行配置:
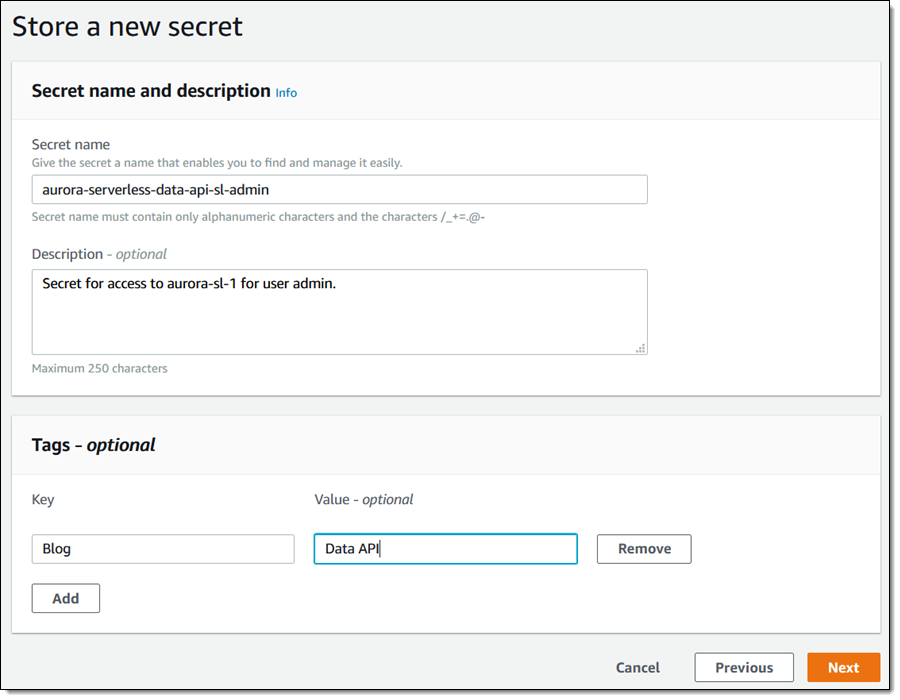
我在下一页使用默认值,然后再次单击下一步,这时我将拥有一个全新的密钥:
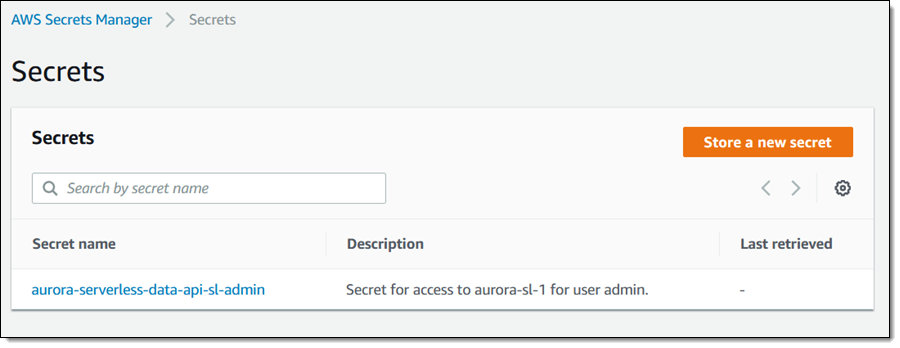
现在我需要两个 ARN,即数据库的 ARN 和密钥的 ARN。我从控制台中找到这两个 ARN,第一个是数据库的:
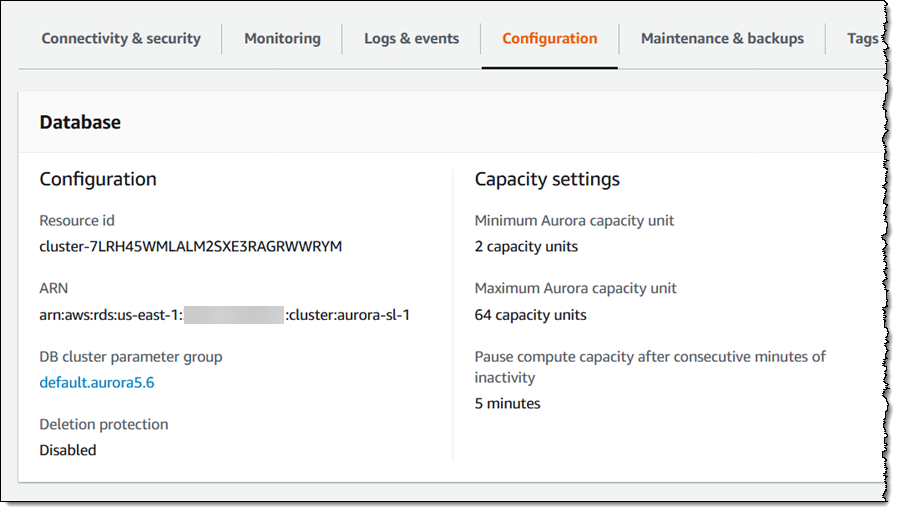
然后是密钥的:
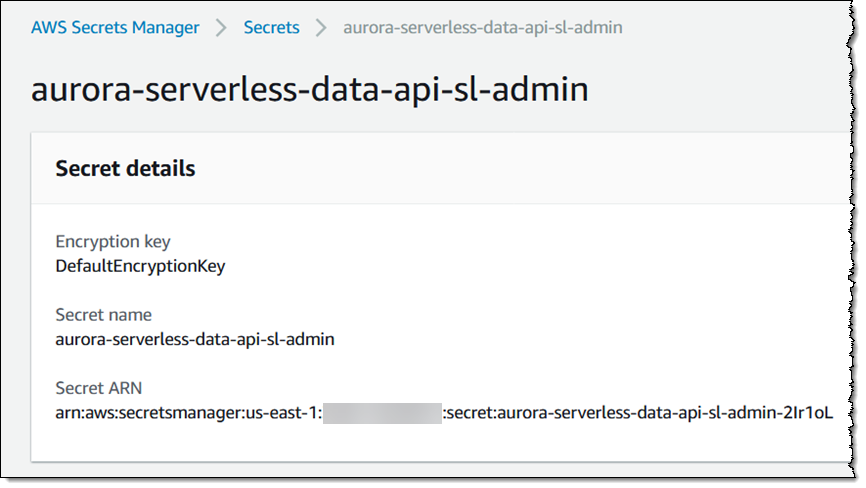
这一对 ARN(数据库和密钥)让我能够访问我的数据库,我将妥善保管它们!
通过 Amazon RDS 控制台使用数据 API
我可以在 Amazon RDS 控制台使用查询编辑器来运行调用数据 API 的查询。我打开控制台并单击查询编辑器,然后创建一个到数据库的连接。我选择集群,输入我的凭证,然后预选择需要的表。然后我单击连接到数据库继续:
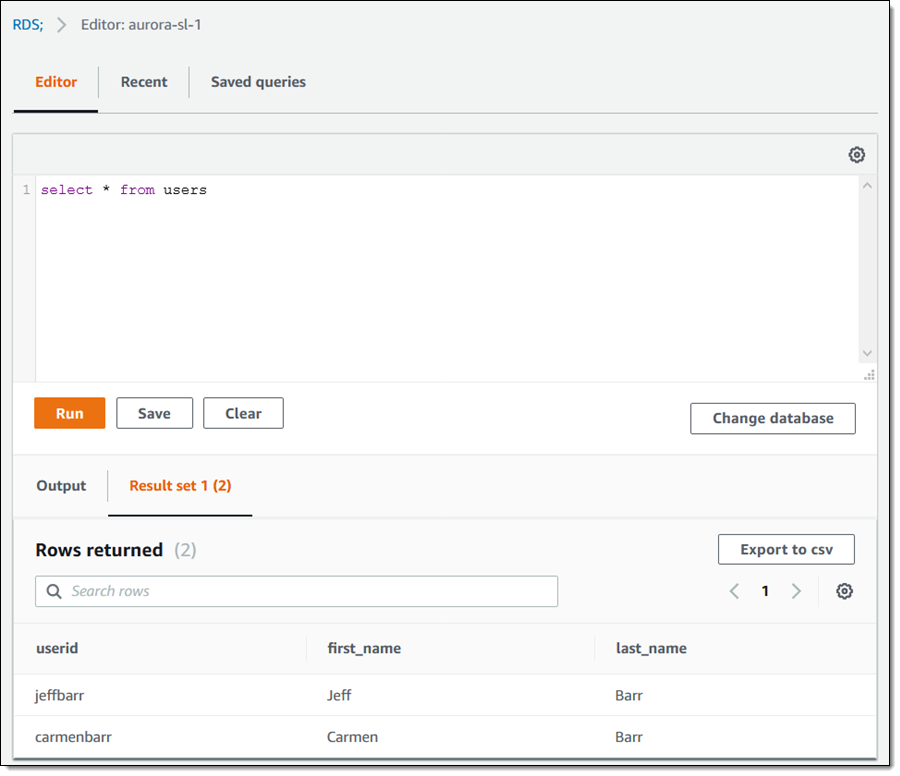
我输入一条查询,单击运行,然后在编辑器中查看结果:
通过命令行使用数据 API
我可以通过命令行来练习使用数据 API:
我可以使用 jq 来从结果中选出我感兴趣的部分:
我可以查询该表并得到结果
如果我指定 --include-result-metadata,则该查询还将返回描述结果列的数据(为节约篇幅,我将仅显示第一个):
借助数据 API,我还可以将一系列的语句打包装入一个事务中,然后提交或回滚。下面是我的操作方式(为明确起见,我将省略 --secret-arn 和 --resource-arn):
如果我决定不提交,我会改为调用 rollback-transaction。
通过 Python 和 Boto 使用数据 API
由于它是一种 API,非常方便通过编程方式访问。下面是一个非常简单的 Python/Boto 代码:
输出将是:
真正生产质量的代码将使用作为应答的一部分返回的元数据,通过符号的方式引用表中的列。
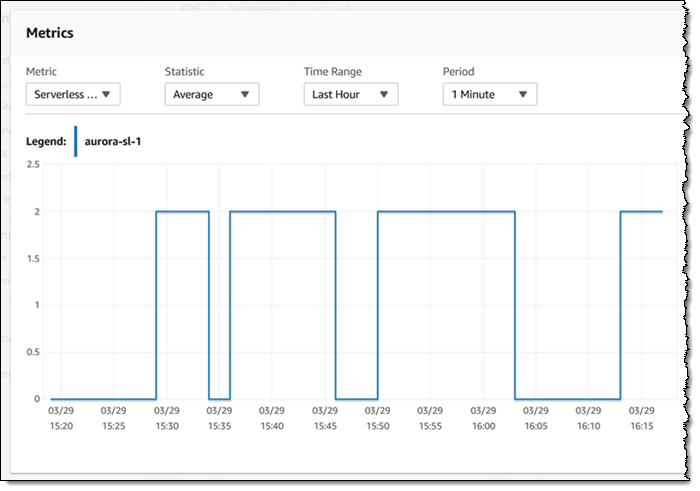
再说一句,根据我的 Amazon Aurora Serverless 集群配置,它的容量将在不活动时一直缩减至零。例如在我编写此博文并运行查询过程中,扩展活动就是下面这个样子:
现已推出
您可以在美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、亚太地区(东京)以及欧洲(爱尔兰)区域立即使用数据 API。该 API 不会产生其他费用,仅需按照将数据传出 AWS 的正常价格付费。
作者介绍:
Jeff Barr
AWS 首席布道师; 2004 年开始发布博客,此后便笔耕不辍。
本文转载自 AWS 技术博客。
原文链接:
https://amazonaws-china.com/cn/blogs/china/new-data-api-for-amazon-aurora-serverless/


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论