

你是否在 MacOS 的 PostgreSQL Docker 容器中遇到过这样神奇的情况:用 EXPLAIN ANALYZE 查看一个查询实际的执行计划,竟然比正常执行查询慢 60 倍?!今天让我们一起来研究一下 PostgreSQL 和 Linux 的内部实现,看看到底发生了什么!
clock_gettime 系统调用
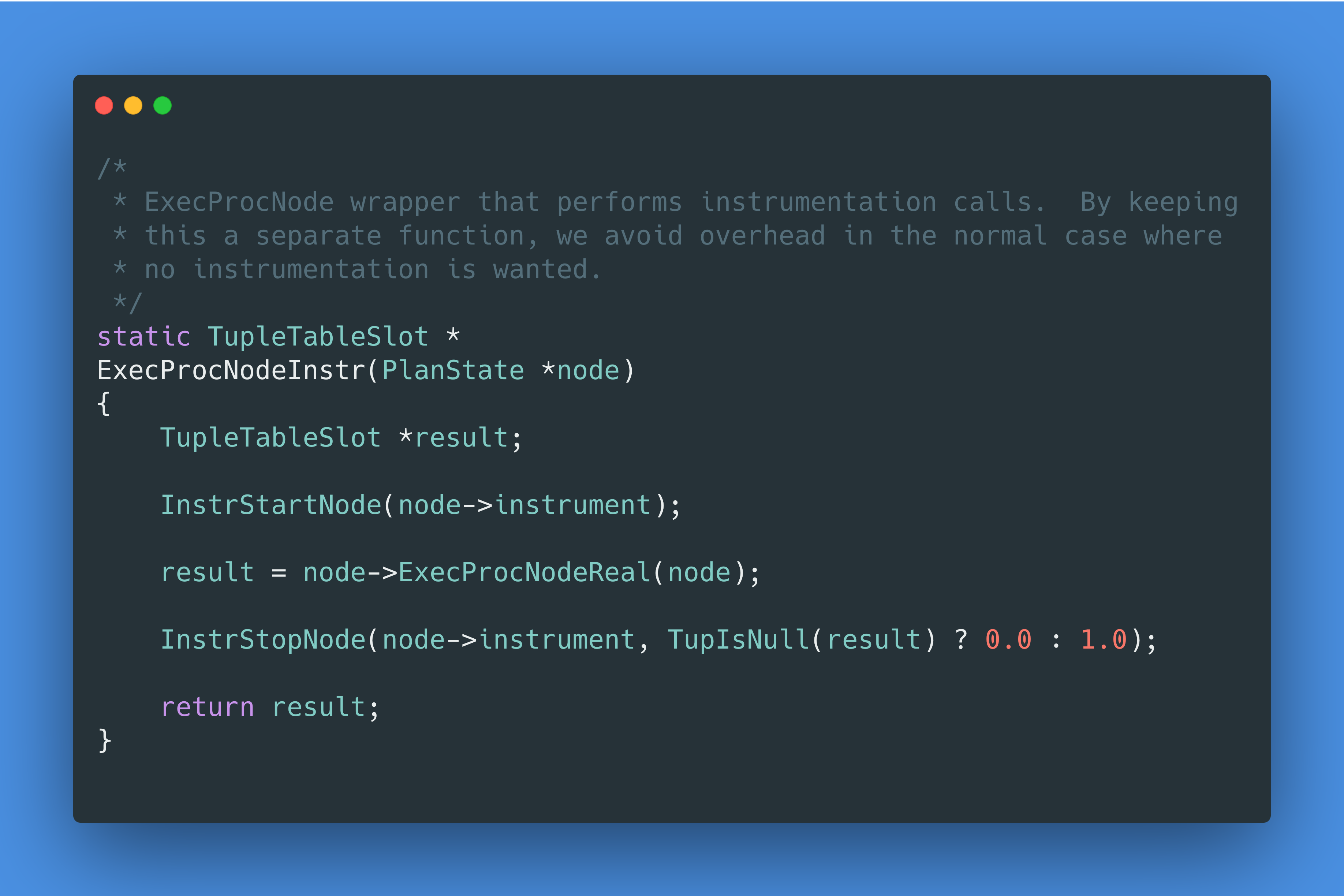
首先,我们需要对 EXPLAIN ANALYZE 是如何工作的有一定的理解。让我们一起来看看 PostgreSQL 的代码,我们发现 EXPLAIN ANALYZE 的代码可以大致归结为如下伪代码:
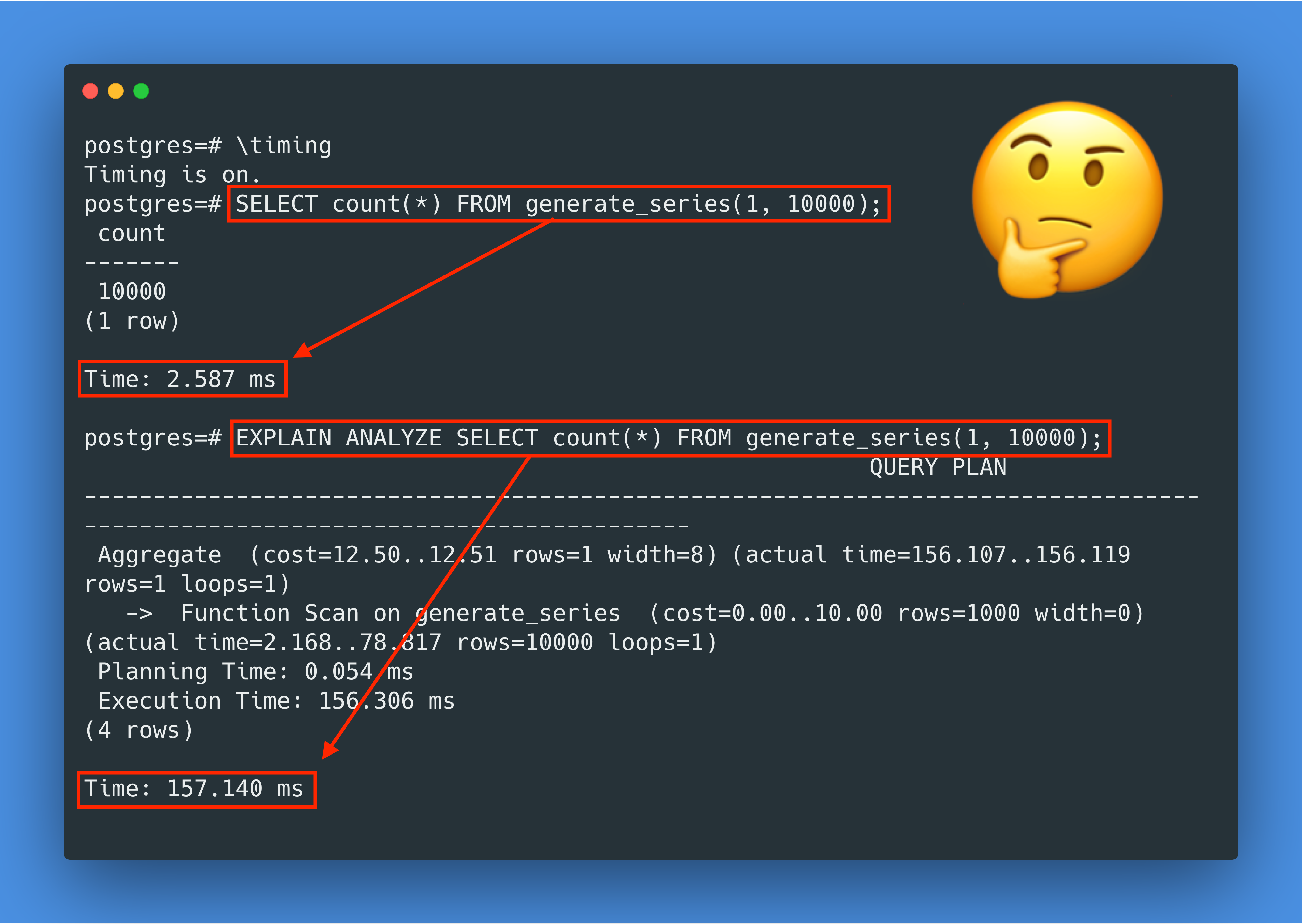
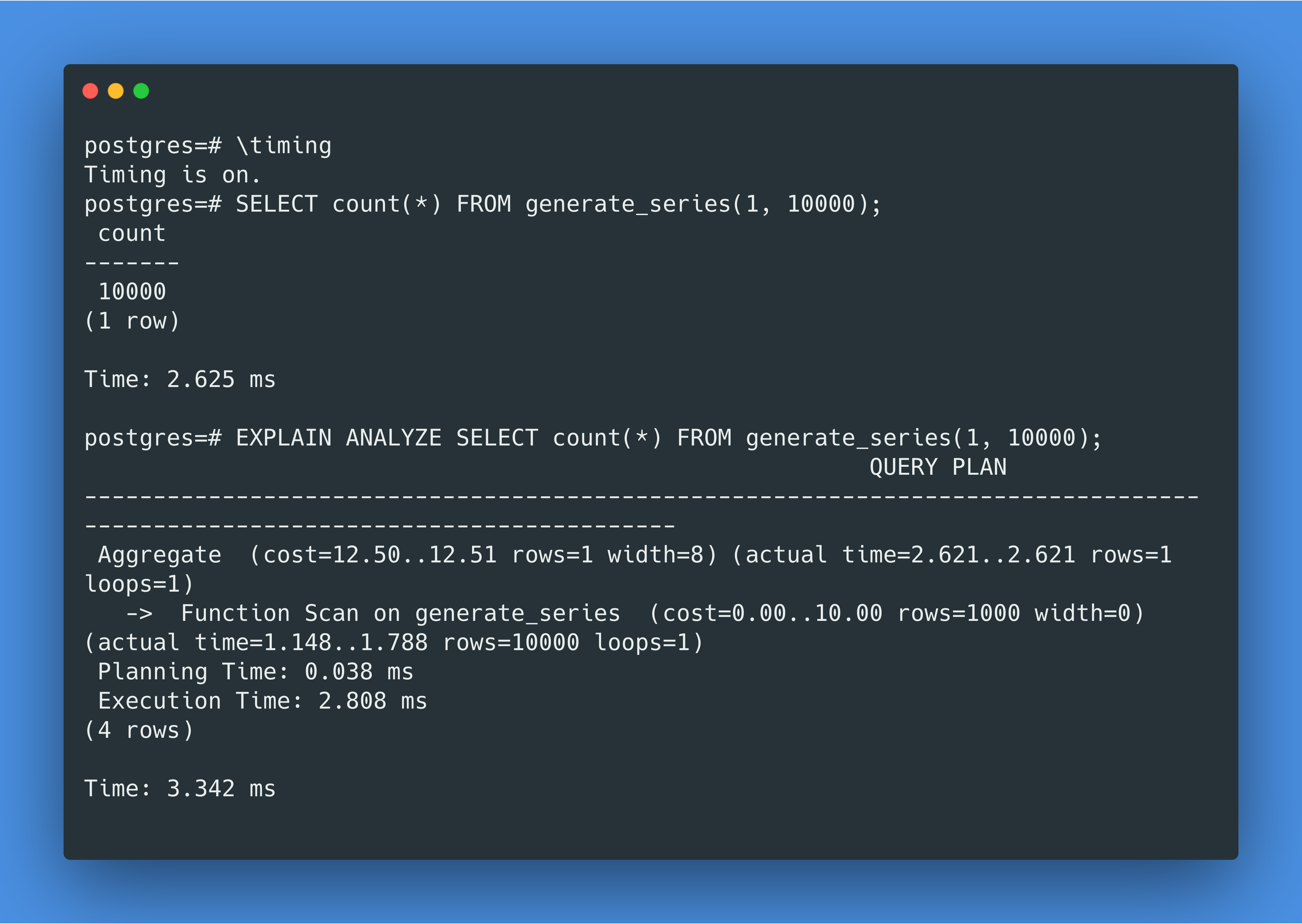
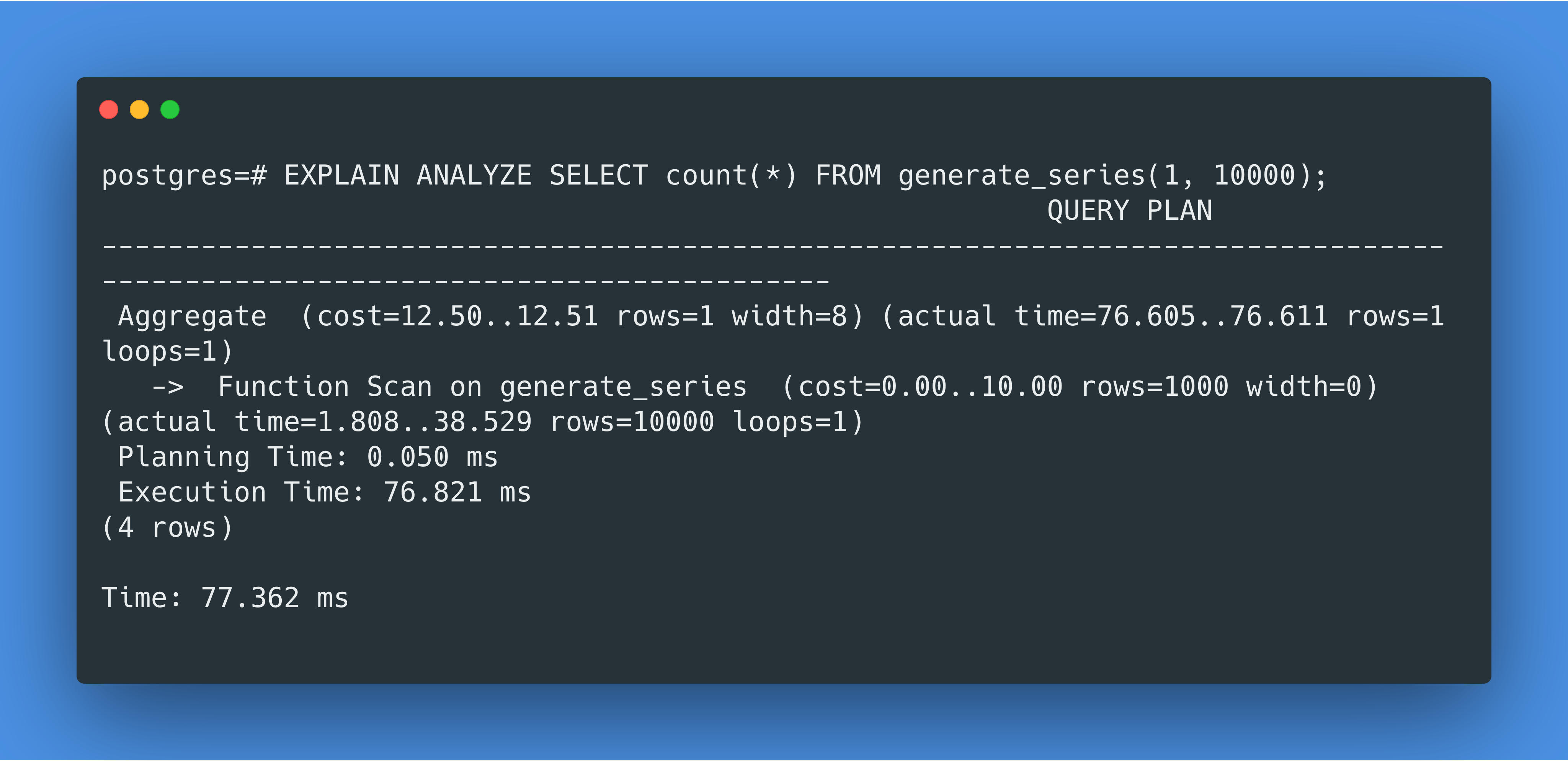
由于generate_series(1, 10000)会产生 10000 行结果,而对于每一行,PostgreSQL 会在开始和结束的时候各调用一次clock_gettime syscall,那么这样不难发现 PostgreSQL 一共调用了 20000 个clock_gettime的 syscall,并且这个clock_gettime的调用不知道为什么在 Docker for Mac 上很慢。那到底为什么慢呢,让我们再深挖一下。
pg_test_timing
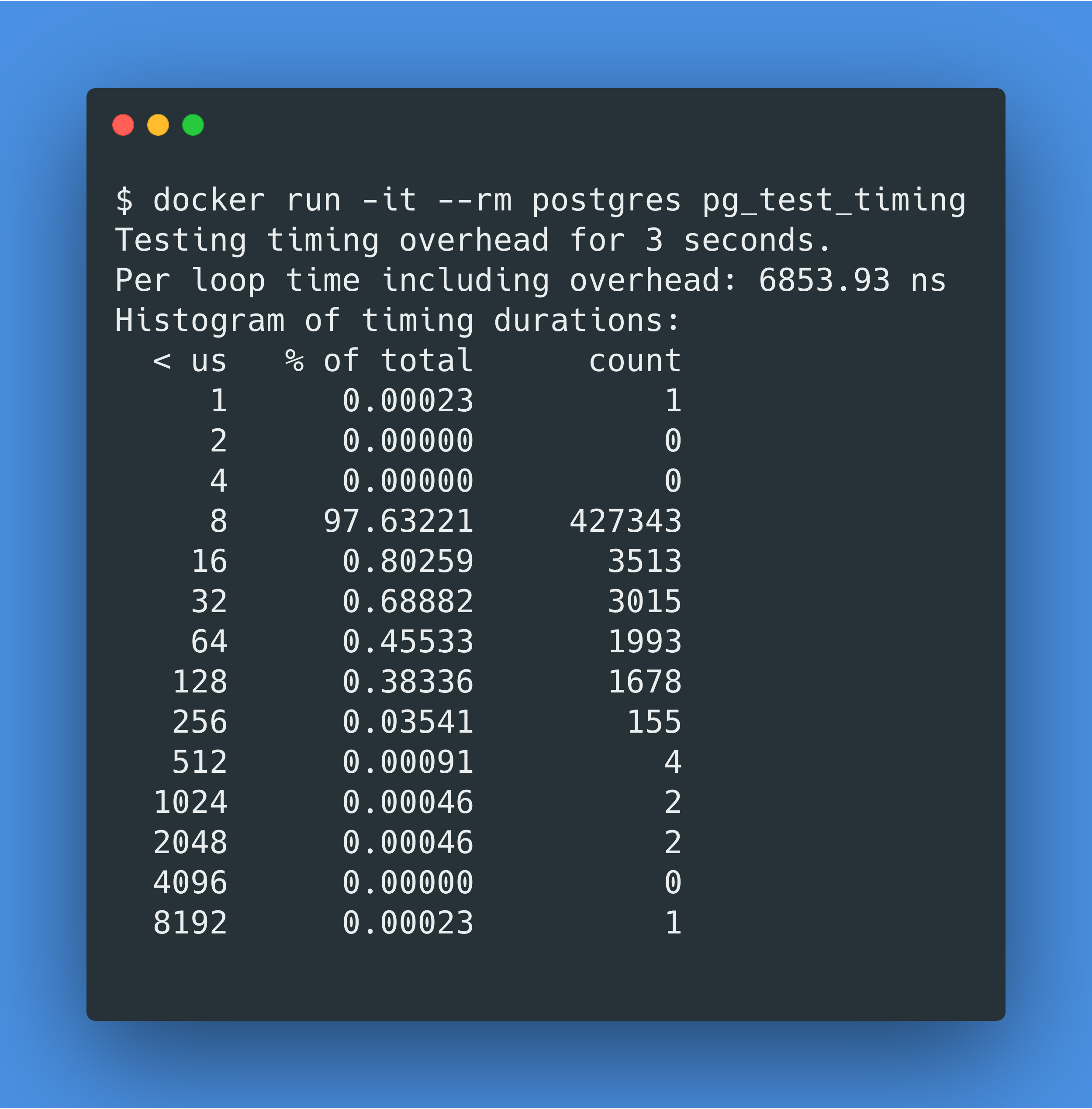
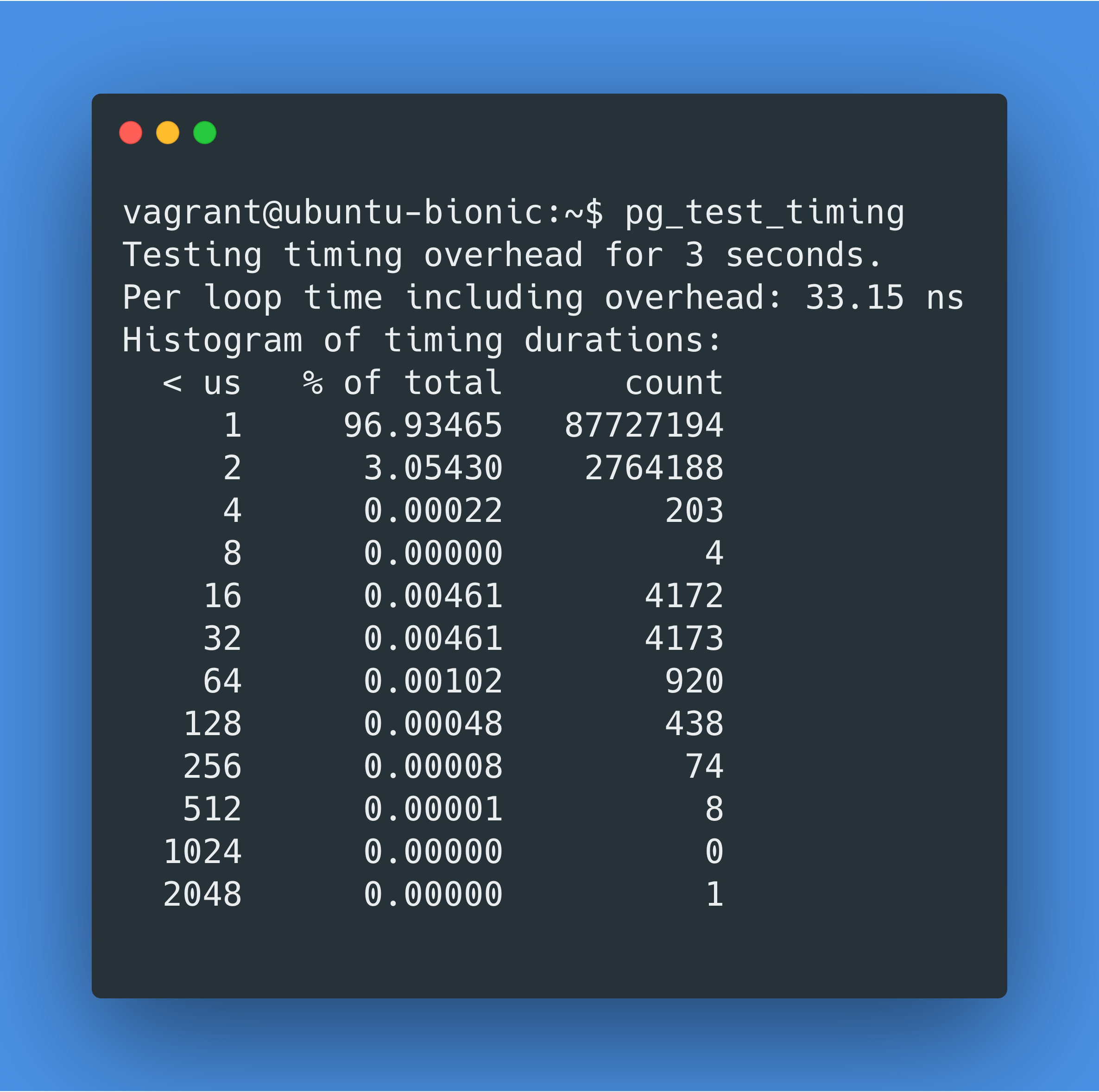
让我们先来确保一下我们关于clock_gettime是罪魁祸首的猜想方向是正确的,那用pg_test_timing来试试吧。pg_test_timing是一个用来测量 PostgreSQL 计时到底需要多少开销的工具,它是 PostgreSQL Docker Image 自带的一个工具。查看pg_test_timing代码,我们可以知道它也调用了clock_gettime syscall。
pg_test_timing的官方文档里说到:大多数(超过 90%)的计时本身消耗的时间应该小于 1 微秒,循环计时的平均消耗会更低,低于 100 纳秒。
good results will show most (>90%) individual timing calls take less than one microsecond. Average per loop overhead will be even lower, below 100 nanoseconds.
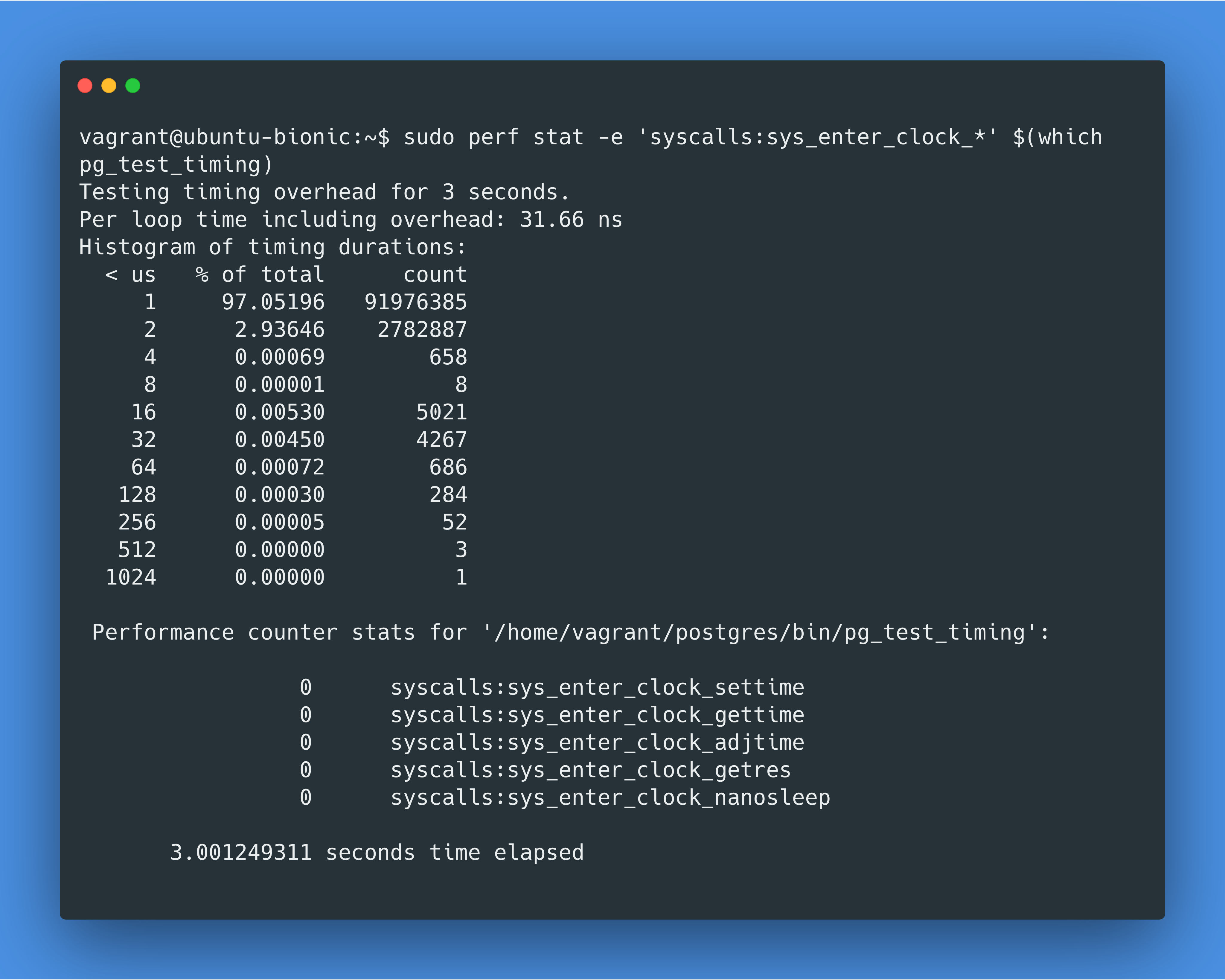
在 MacOS 上 PostgreSQL Docker 容器里跑pg_test_timing,我们得到的结果是每次计时需要 6853 纳秒!那么我们最初的查询调用了 20000 次计时,那就需要 20000*6853ns=137ms,这就能解释我们为什么在 EXPLAIN ANALYZE 里看到的总用时是 157.140ms 了。
同样的pg_test_timing,在部署在 MacOS 主机上的 PostgreSQL 上运行的话,只要 65 纳秒,比 Docker 里快 100 多倍。
到这里,我突然意识到 Docker for Mac 的运行机制是在后台启动了一个 Linux 虚拟机,那会不会是由于多出来的这层虚拟机带来了多余的开销呢?那可能不仅是 Docker 的问题,如果在 MacOS 上启动一个 Linux 虚拟机,并在虚拟机内运行 PostgreSQL,也许应该可以看到同样的计时高延迟问题。
那让我们来比较一下 Linux 虚拟机和 Docker 的虚拟机开销区别吧。我在 VirtualBox 上运行了 Ubuntu 18.04,运行了同样的查询EXPLAIN ANALYZE SELECT count(*) FROM generate_series(1, 10000);,这次运行时长只有 3 毫秒(Docker 的运行时长是 157 毫秒)。pg_test_timing在 Ubuntu 18.04 上的结果是单次计时开销为 33 纳秒(Docker 的单次计时开销是 6853 纳秒,MacOS 主机的单次计时开销是 65 纳秒)。那“虚拟机这层带来了多余开销”这个理论根本说不通😮!
数数 clock_gettime 调用
到这里,我们需要做一个合理性检查了。之前我们是根据静态分析(查看代码)的结论提出clock_gettime是罪魁祸首的假设,那clock_gettime是不是真的如我们所料,在我们的查询期间被调用了 20000 次呢?
那现在让我们用perf这个工具来查查clock_gettime这个系统接口到底被调用了多少次吧。顺便说一句,perf 的功能很强大,是一个值得学习的好工具。
我们用下面这个命令来查看clock_gettime在我们的查询运行时,到底被系统调用了多少次:
我们首先通过SELECT pg_backend_pid();来看我们 PostgreSQL 运行的 pid 是什么,之后在 perf 命令运行开始后,运行我们的查询:
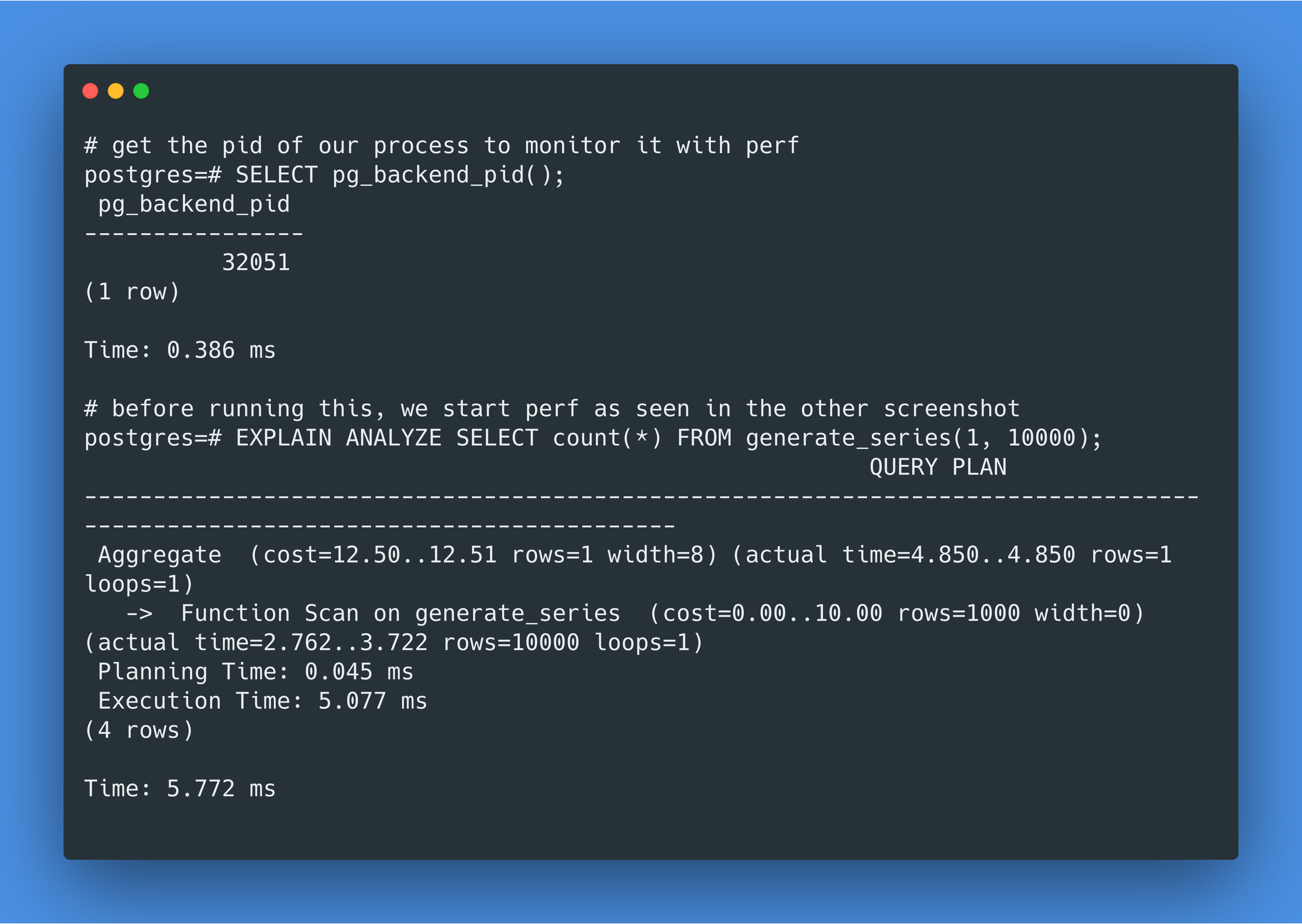
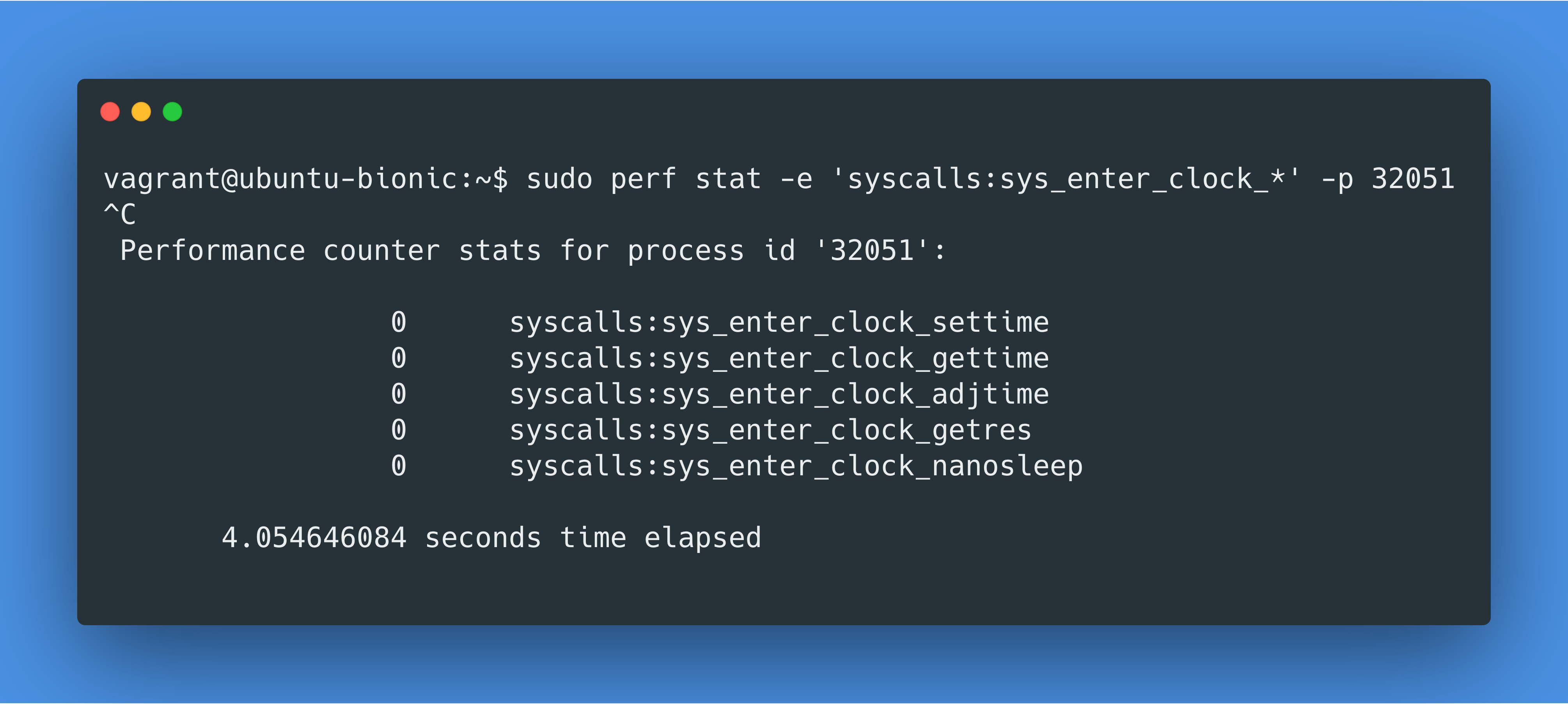
这个结果告诉我们clock_gettime syscall 没有被调用过。什么?!那pg_test_timing总该调用clock_gettime syscall 了吧,试一下:
没有,竟然还是没有clock_gettime syscall 被调用。计算机太难了😩
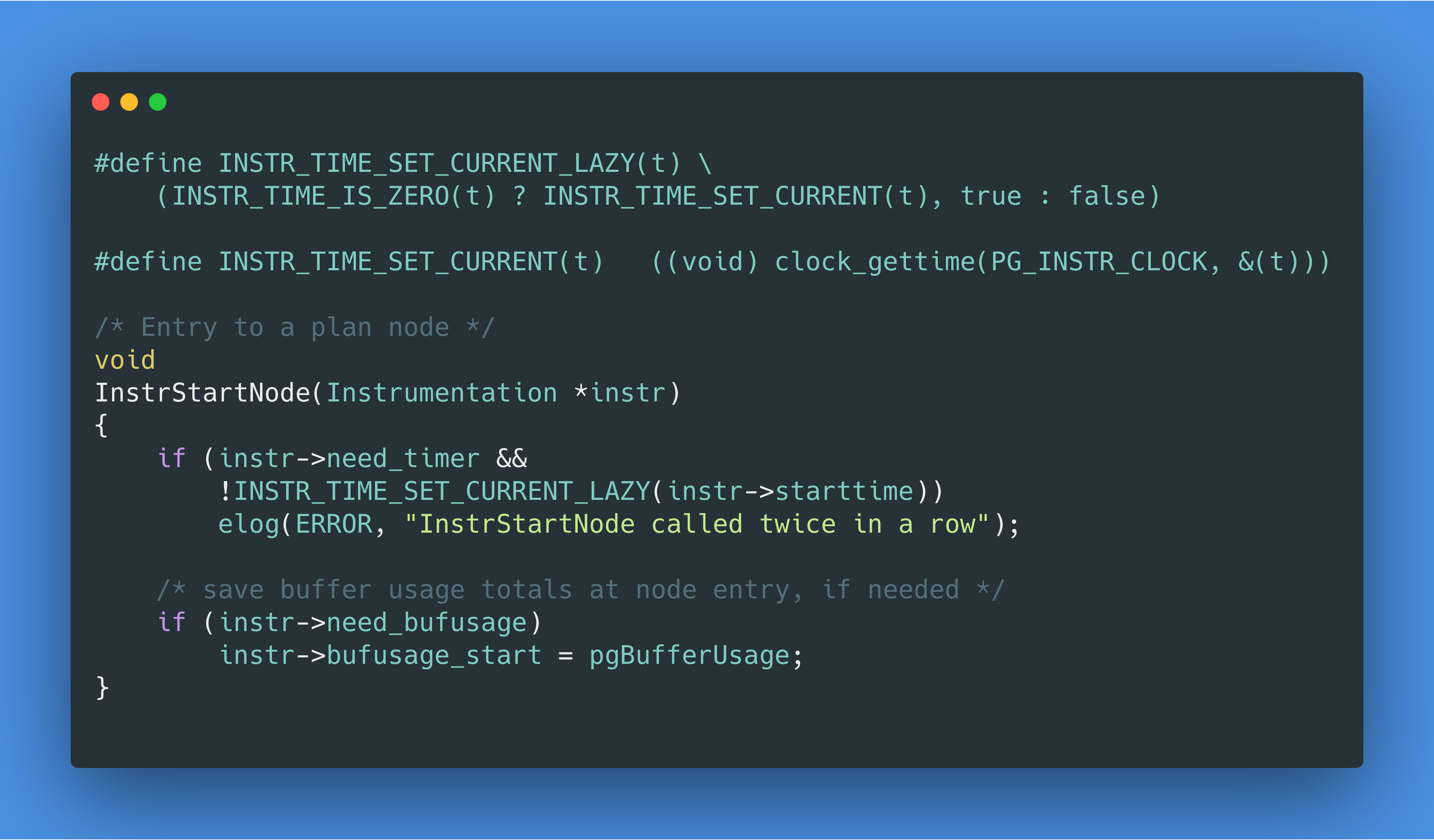
好吧,是时候拿出秘密武器了。查看 EXPLAIN ANALYZE 的代码,我们知道InstrStartNode是计时开始时调用的方法,我们用 gdb 来反汇编一下,看看我们是不是真的调用了clock_gettime syscall:
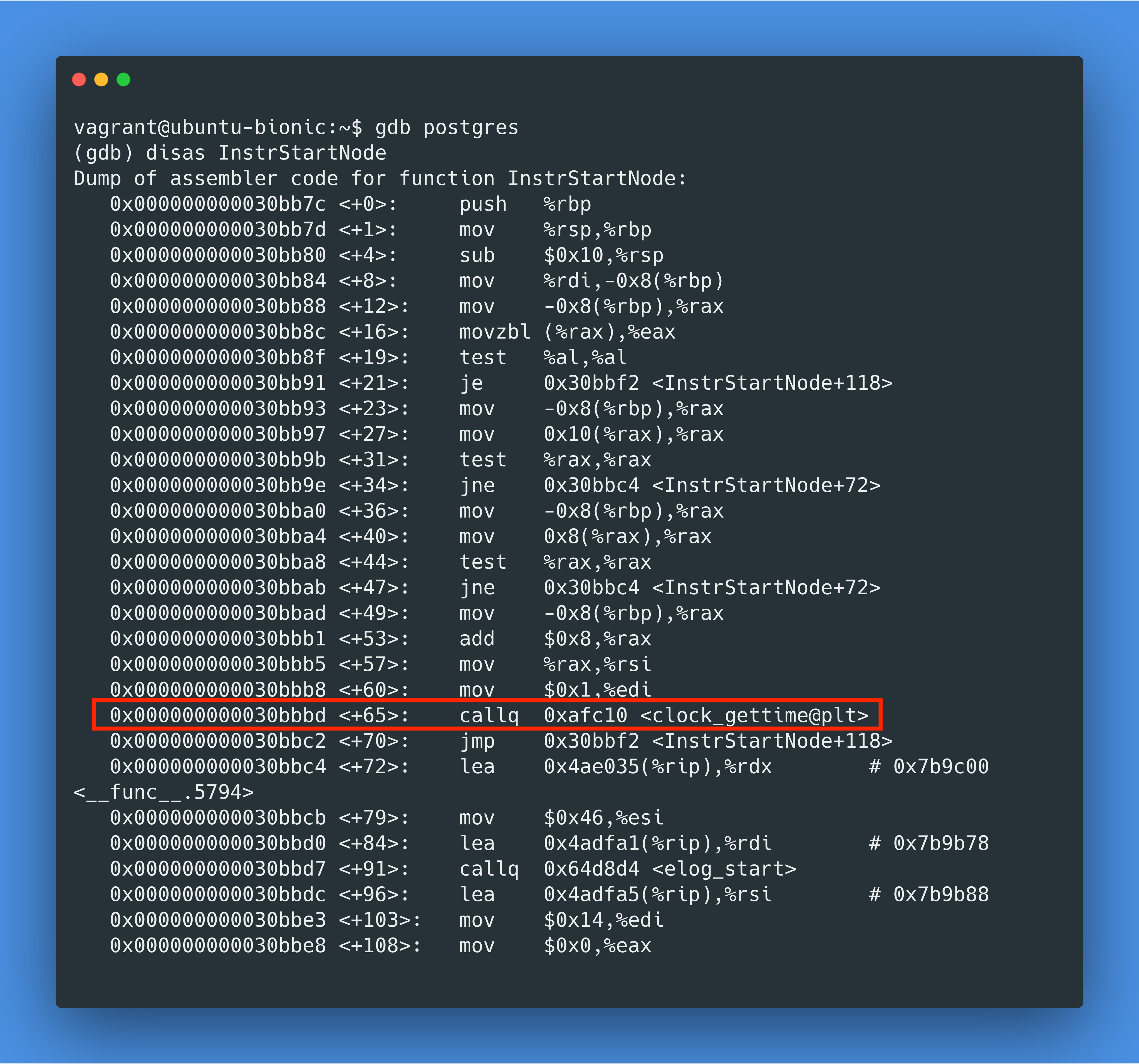
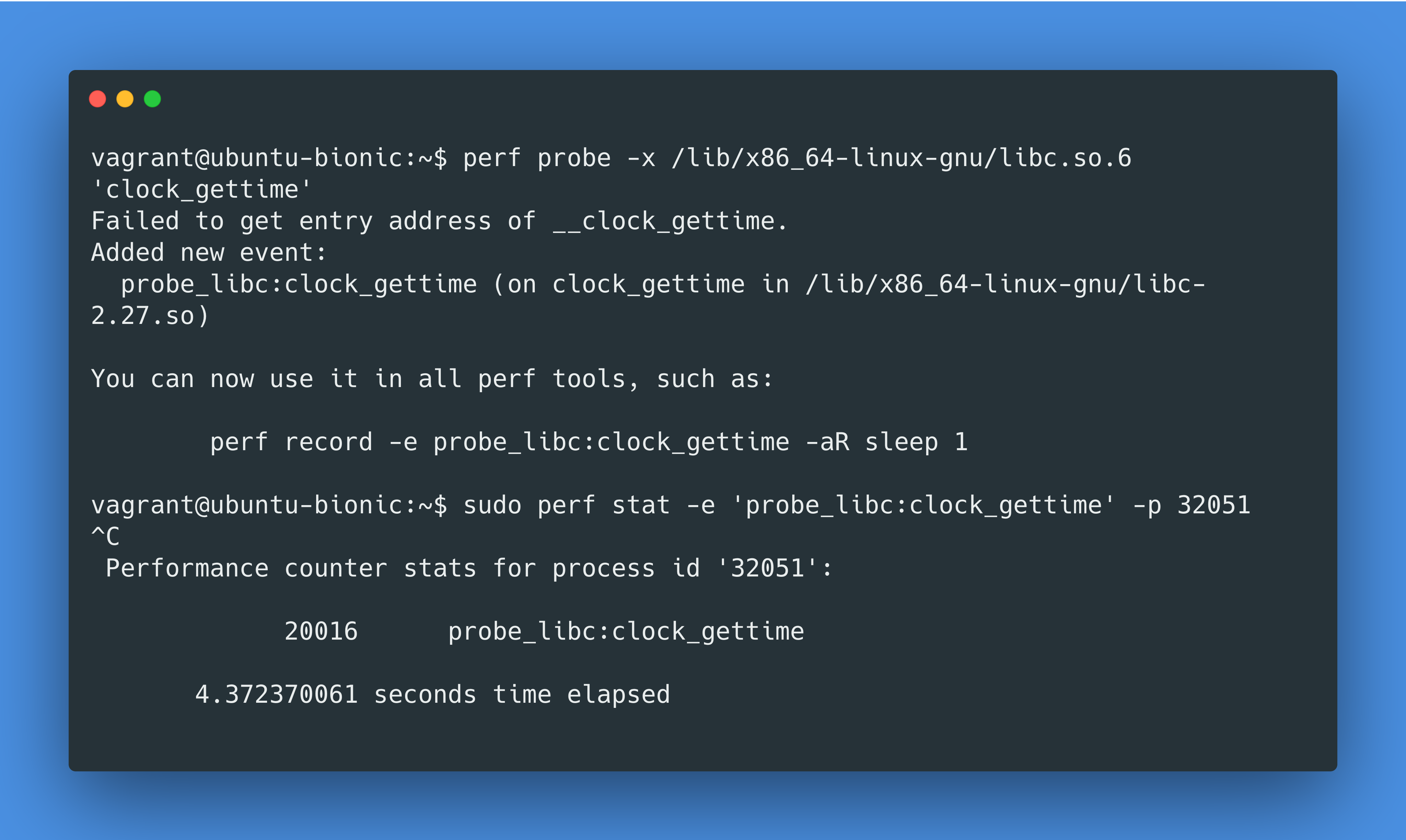
我们看到了callq 0xafc10 <clock_gettime@plt>,这里的@plt表示 Procedure Linkage Table,这代表我们调用了 libc 的接口!我们再快速用 perf 工具的动态追踪功能确认一下,确认了有 20016 次clock_gettime libc 调用:
vDSO 优化
接下来,我又继续尝试用 gdb 了解更多,并且阅读了一些 libc 的源代码,我终于发现了 vDSO 这个东西。简而言之 vDSO 是避免调用 syscall 的一个优化。而对于clock_gettime的优化更是写在了文档中:
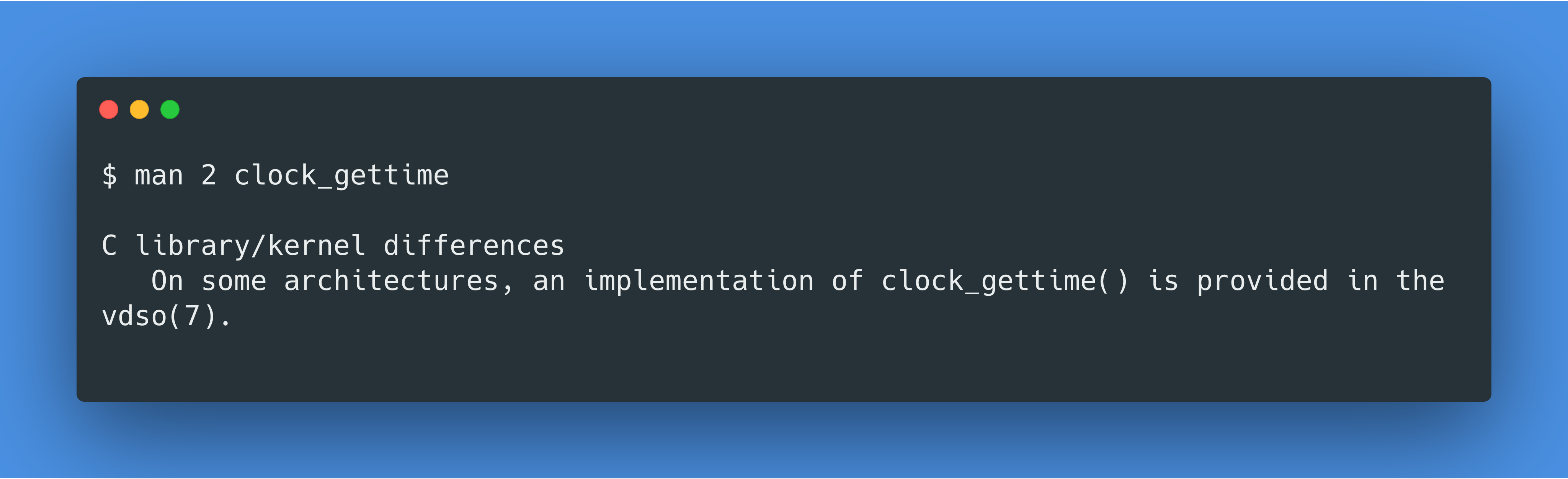
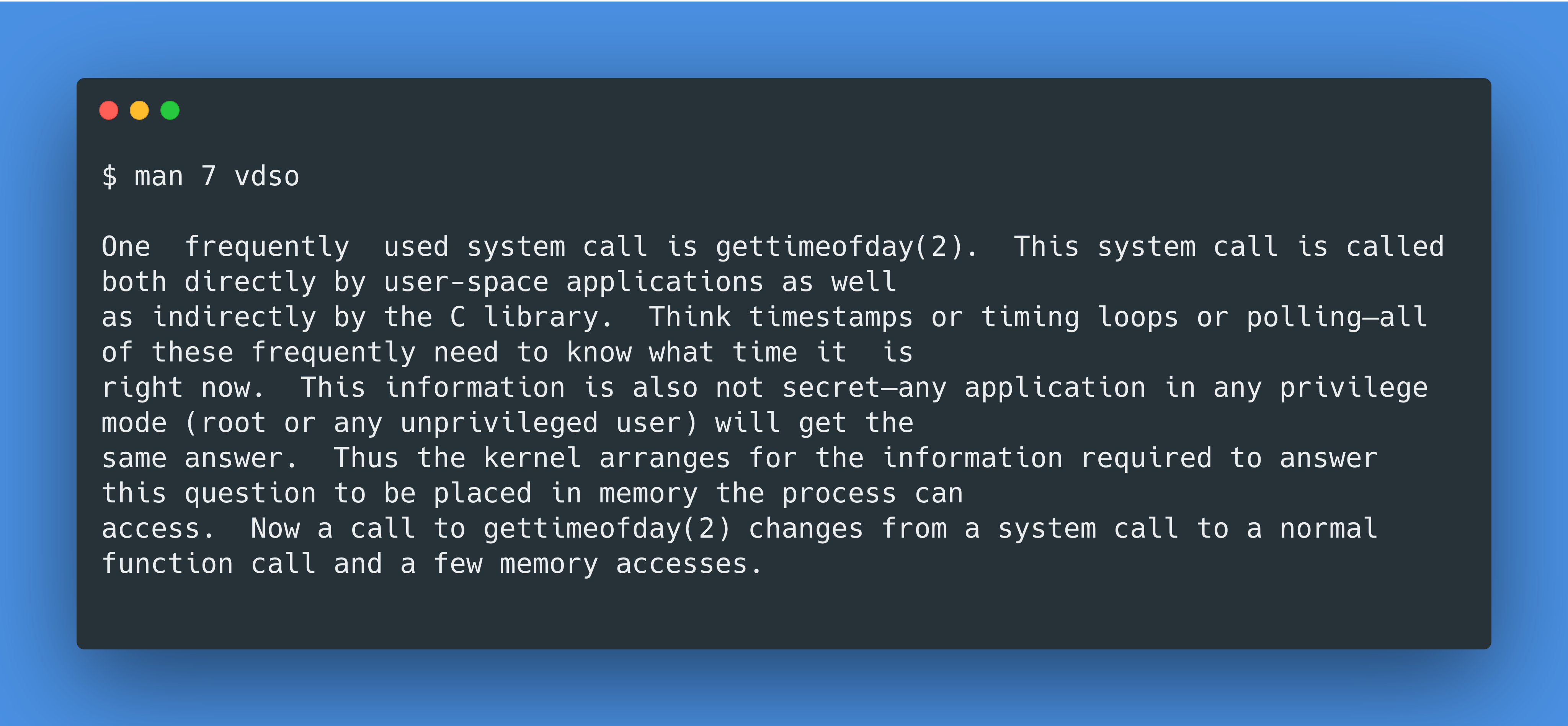
译:一个会被经常调用到的 syscall 是gettimeofday()。这个 syscall 既被用户空间的应用所直接调用,也间接地被一些 C 库所调用。比如时间戳,循环计时,或者轮询,都需要准确地得到当前时间。时间信息并不是秘密,任何应用,任何有无权限的人都会得到相同的时间答案。所以内核把回答时间问题所需要的信息都放在用户进程可以读到的地方。从而gettimeofday()本来是一个系统调用,现在变成了一个正常的函数调用,并且只需访问内存即可得到时间。
罪魁祸首:clock_gettime 系统调用没有使用 vDSO 优化
现在让我们回到我们最初的问题,为什么clock_gettime在 Docker for Mac 上很慢?当我到处 google 这个问题的时候,我在这篇博客中发现“时间偏移”问题会改变时钟脉冲源(clocksource)。运行如下命令,你会发现一开始的TSC时钟脉冲源由于被认为不稳定而自动切换到了hpet时钟脉冲源:
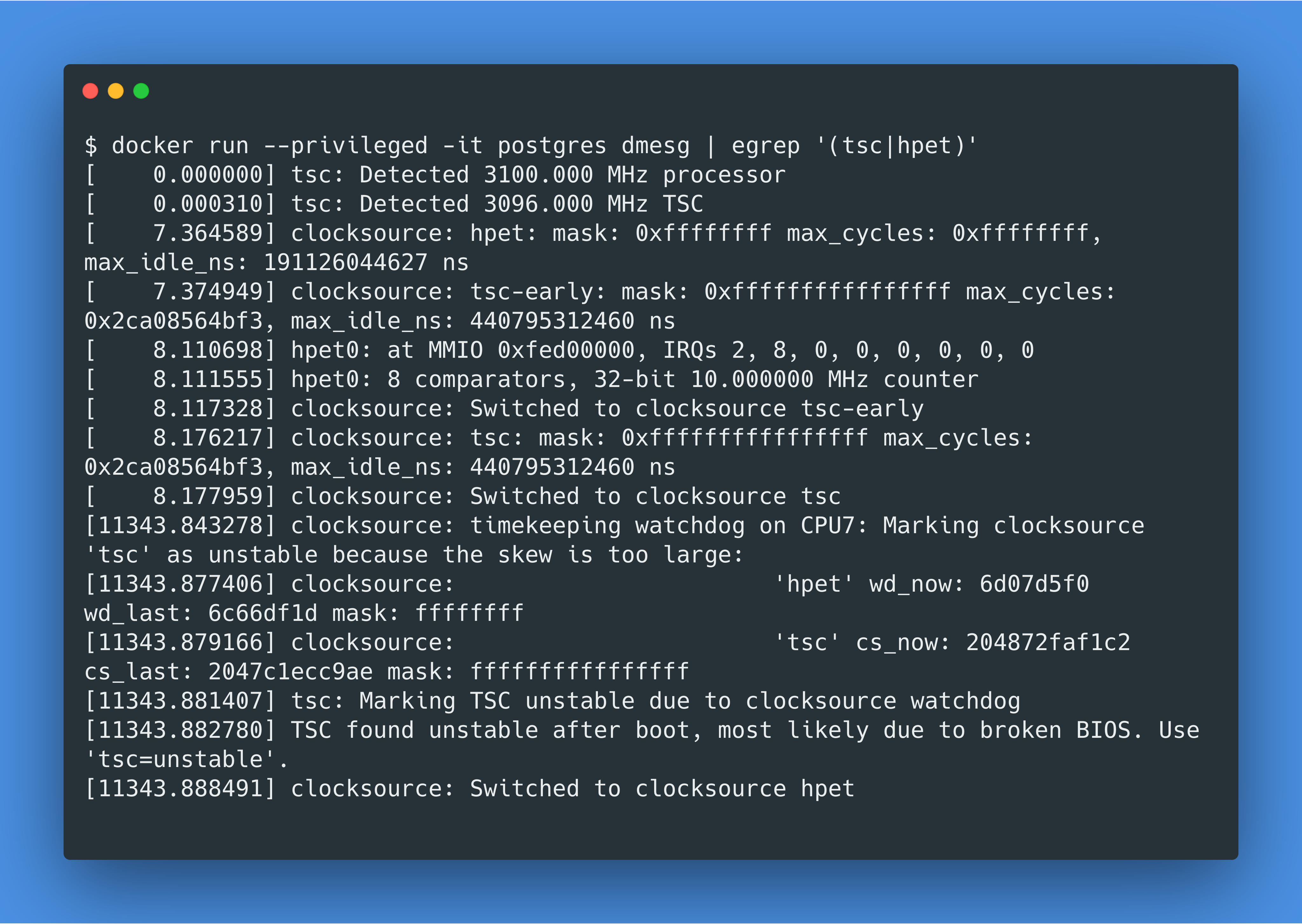
根据 Linux vDSO 的维护者所述,hpet这个时钟脉冲源太差了,所以他决定在 vDSO 中完全禁用对hpet的支持。
至此,我们终于找到了根源问题:
在 MacOS 主机和 Docker 虚拟机的时间偏移太大时,Docker 后台的虚拟机决定把时钟脉冲源从TSC切换至hpet。原本TSC的gettimeofday调用非常快,因为gettimeofday调用的并不是 syscall,而是通过 vDSO 发生在用户空间。在 vDSO 中,当系统当前的时钟脉冲源不支持通过 vDSO 调用时,gettimeofday就会退而求其次调用 syscall,其中包括发生内核调用和各种其他开销。而 hpet 不支持通过 vDSO 调用,所以每个gettimeofday都是一个 syscall,最终 20000 个 syscall 的多余开销使得性能差强人意。
主机和 Docker 之间的时间偏移问题,曾经在 Docker 18.05 的版本中被尝试修复过。这个修复本应该解决时间偏移问题,所以理论上没有时间偏移就不会有切换时钟脉冲源的事情发生。然而,他们的修复看上去仍然是有缺陷的,尤其是在虚拟机 sleep 的时候仍会发生时间偏移问题。可惜的是,尽管这个问题对很多应用产生了影响,用户在 github 上提出的问题却并没有得到太多的关注,这里是一个用户说 PHP 请求由于 Docker 时间偏移的问题响应慢了 3 倍。当我在 google 上到处浏览的时候,发现 vDSO 不支持某些时钟脉冲源的问题过去严重影响了如 AWS 的一些云厂商。
解决方案
重启 Docker for Mac 是一个变通的方法,但是时钟脉冲源自动切换的问题再次发生只是时间问题。在我工作的团队里,同事们一致同意在做性能测试方面的工作时,直接在 MacOS 主机上使用 PostgreSQL,而不用 Docker。
收获
无论如何,这次重要的收获是,现代的技术栈既复杂又脆弱,作为一个应用开发者,你也许不能完全掌握这些难点,但是你会经常需要解释为什么你的应用性能不好。所以,增强你的调试技能吧。学习足够的 C 语言让自己有能力阅读源代码,使用足够的 gdb 去设置断点,掌握足够的 perf 功能去追踪系统调用和方法调用。这样的话,不久那些最令人生畏的 PostgreSQL 性能谜题将得到解答。
如果你读到了这里,并且你对 PostgreSQL、Golang 或者 DevOps 相关职位很有兴趣,欢迎与我们联系。
原文链接:
https://twitter.com/felixge/status/1221512507690496001
译者邮箱:stoneapple0920@163.com

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论