

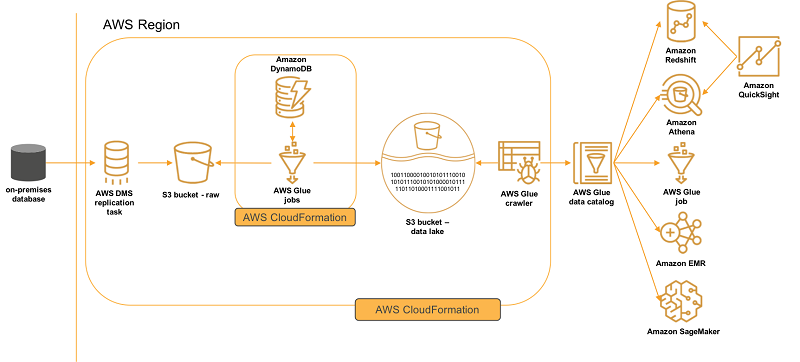
在 Amazon S3 上构建数据湖可让组织受益无穷。它允许您访问各种数据源,确定独特的关系,构建 AI/ML 模型来提供定制的客户体验,并加速新数据集的管理以供消费。但是,无论是在本地还是在 AWS 上,从运营数据存储中捕获不断变化的更新并将其加载到数据湖,都可能会非常耗时且难以管理。下文演示了如何部署一个解决方案,将来自热门数据库源(如 Oracle、SQL Server、PostgreSQL 和 MySQL)的持续更改加载到您的数据湖中。该解决方案会将新数据和发生更改的数据流式传输到 Amazon S3。它还会创建和更新相应的数据湖对象,根据您配置的计划提供与数据源类似的数据视图。然后,AWS Glue Data Catalog 公开新更新和经过重复数据删除的数据,以供分析服务使用。
解决方案概览
我将此解决方案分为两个 AWS CloudFormation 堆栈。您可以从公共 S3 存储桶下载我在此博文中引用的 AWS CloudFormation 模板,也可以使用稍后提供的链接启动这些模板。同样,您还可以下载本文后面引用的 AWS Glue 作业。
第一个堆栈包含可重用的组件。您只需部署一次。它可启动以下 AWS 资源:
AWS Glue 作业:管理从原始 S3 文件到经重复数据删除和优化的 Parquet 文件这一加载过程的工作流程。
Amazon DynamoDB 表:保持每个数据湖表的数据加载状态。
IAM 角色:运行这些服务并访问 S3。此角色包含具有提升权限的策略。仅将此角色附加到这些服务,而不是 IAM 用户或组。
AWS DMS 复制实例:运行复制任务以通过 AWS DMS 迁移正在进行的更改。

第二个堆栈包含您应该为引入数据湖的每个源部署的对象。它可启动以下 AWS 资源:
AWS DMS 复制任务:读取每个表的源数据库事务日志的更改并将写入数据流式传输到 S3 存储桶。
S3 存储桶:存储原始 AWS DMS 初始加载并更新对象,以及查询优化的数据湖对象。
AWS Glue 触发器:计划 AWS Glue 作业。
AWS Glue 爬网程序:按计划构建和更新 AWS Glue Data Catalog。
堆栈参数
AWS CloudFormation 堆栈要求您输入参数以配置提取和转换管道:
DMS 源数据库配置:DMS 连接对象所需的数据库连接设置,例如数据库引擎、服务器、端口、用户和密码。
DMS 任务配置:AWS DMS 任务所需的设置,例如复制实例 ARN、表筛选条件、架构筛选条件和 AWS DMS S3 存储桶位置。表筛选条件和架构筛选条件允许您选择复制任务同步的对象。
数据湖配置:堆栈传递给 AWS Glue 作业和爬网程序的设置,例如 S3 数据湖位置、数据湖数据库名称和运行计划。
部署后
部署解决方案后,AWS CloudFormation 模板将启动 DMS 复制任务并填充 DynamoDB 控制器表。在查看和更新 DynamoDB 控制器表之前,数据不会传播到您的数据湖。
在 DynamoDB 控制台中,配置以下字段以控制下表中显示的数据加载过程:
至此,设置完成。在下一个计划的时间间隔,AWS Glue 作业会处理任何初始和增量文件,并将其加载到您的数据湖中。在下一次计划的 AWS Glue 爬网程序运行中,AWS Glue 会将表加载到 AWS Glue Data Catalog 中,以用于您的下游分析应用程序。
Amazon Athena 和 Amazon Redshift
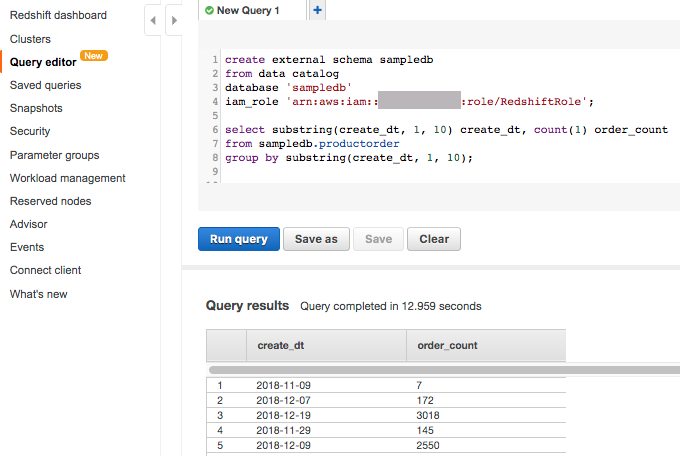
您的管道现在会自动创建和更新表。如果您使用 Amazon Athena,可以立即开始查询这些表。如果您使用 Amazon Redshift,可以将这些表公开为外部 schema 并开始查询。
您可以直接分析这些表,也可以将它们连接到数据仓库中已有的表,或者将它们用作提取、转换和加载 (ETL) 过程的输入。有关更多信息,请参阅为 Amazon Redshift Spectrum 创建外部架构。
AWS Lake Formation
在撰写本文时,AWS Lake Formation 已经宣布但尚未发布。AWS Lake Formation 可以轻松设置安全的数据湖。要在此解决方案中加入 Lake Formation,请将启动期间指定的 S3 位置添加为“数据湖存储”位置,并使用 Lake Formation 向您的 IAM 用户提供凭证。
使用 AWS Lake Formation,无需通过用户、组或存储桶策略授予 S3 访问权限,它提供了一个集中式控制台,用于授予和审核对数据湖的访问权限。
关键功能
一些内置的 AWS CloudFormation 密钥配置使该解决方案成为可能。了解这些功能有助于您将此策略复制用于其他目的,或根据需要自定义应用程序。
AWS DMS
第一个 AWS CloudFormation 模板会部署一台 AWS DMS 复制实例。在启动第二个 AWS CloudFormation 模板之前,请确保复制实例已经连接到本地数据源。
S3 目标的 AWS DMS 终端节点具有额外的连接属性:addColumnName=true。此属性会告知 DMS 将列标题添加到输出文件。该过程使用此标题为 Parquet 文件和 AWS Glue Data Catalog 构建元数据。
当 AWS DMS 复制任务开始时,初始加载过程将文件写入以下位置:s3://///。它为每个表写入一个为初始负载命名为 LOAD00000001.csv 的文件。它每分钟的所有数据更改最多写入一个文件,命名为.csv。加载过程使用这些文件名以增量方式处理新数据。
AWS DMS 更改数据捕获 (CDC) 过程会在数据集“Op”中添加一个附加字段。 该字段用于指示给定键值的最后一项操作。更改检测逻辑使用此字段以及存储在 DynamoDB 表中的主键来确定对传入数据执行哪项操作。该过程会将此字段传递到您的数据湖,您可以在查询数据时看到它。
AWS CloudFormation 模板部署了两个专用于 DMS 的角色(DMS-CloudWatch-logs-role、DMS-VPC-role),如果您以前使用过 DMS,则可能已经存在这两个角色。如果因为这些角色而无法构建堆栈,可以安全地从模板中删除这些角色。
AWS Glue 有两种类型的作业:Python shell 和 Apache Spark。Python shell 作业允许您使用一小部分计算资源以一小部分成本运行小型任务。Apache Spark 作业允许您通过使用分布式处理框架来运行计算和内存密集程度更高的中到大型任务。此解决方案使用 Python shell 作业来确定要处理的文件以及维护 DynamoDB 表中的状态。它还使用 Spark 作业进行数据处理和加载。
当更改从关系数据库流入时,您可能会看到新事务在给定文件夹中显示为新文件。此加载过程行为可最大限度地减少对已加载数据的影响。如果这会导致文件大小或查询性能不一致,请考虑合并压缩(文件合并)过程。
在作业运行之间,AWS Glue 会按文件名和顺序将事务复制到同一主键(例如,插入,然后更新)。它会确定最后一个事务并使用它将受影响的对象重新写入 S3。
配置设置允许 Spark 类型的 AWS Glue 作业最多具有两个 DPU 的处理能力。如果您的加载作业表现不佳,请考虑增大此值。增加作业 DPU 对于使用分区键设置的表或 DMS 流程在两次执行之间生成多个文件时最有效。
如果您的组织已经有一个长期运行的 Amazon EMR 集群,请考虑使用 EMR 集群中运行的 Apache Spark 作业替换 AWS Glue 作业,以优化您的支出。
该解决方案部署名为 DMSCDC_Execution_Role 的 IAM 角色。该角色附加到 AWS 服务,并与 AWS 托管策略和内联策略相关联。
该角色的 AssumeRolePolicyDocument 信任文档包括以下策略,这些策略附加到 AWS Glue 和 AWS DMS 服务,以确保作业具有所需的执行权限。AWS CloudFormation 自定义资源还使用此角色(由 AWS Lambda 实现)来初始化环境。
IAM 角色包括以下 AWS
托管策略。有关更多信息,请参阅托管策略和内联策略。
ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole - arn:aws:iam::aws:policy/AmazonS3FullAccess - arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole
IAM 角色包括以下内联策略。此策略包括执行 Lambda 实现的 AWS CloudFormation 自定义资源、初始化和管理 DynamoDB 表以及初始化 DMS 复制任务的权限。
Action: - lambda:InvokeFunction - dynamodb:PutItem - dynamodb:CreateTable - dynamodb:UpdateItem - dynamodb:UpdateTable - dynamodb:GetItem - dynamodb:DescribeTable - iam:GetRole - iam:PassRole - dms:StartReplicationTask - dms:TestConnection - dms:StopReplicationTask Resource: - arn:aws:dynamodb:{AWS::Account}:table/DMSCDC_* - arn:aws:lambda:{AWS::Account}:function:DMSCDC_* - arn:aws:iam::{AWS::Region}:${AWS::Account}::" Action: - dms:DescribeConnections - dms:DescribeReplicationTasks Resource: ‘*’
AWS Glue
IAM
Principal : Service : - lambda.amazonaws.com - glue.amazonaws.com - dms.amazonaws.com Action : - sts:AssumeRole
示例数据库
以下示例展示了使用示例数据库部署此解决方案后所看到的内容。
示例数据库包括三个表:product、store 和 productorder。部署 AWS CloudFormation 模板后,您应该会看到在原始 S3 存储桶中为每个表创建的文件夹。
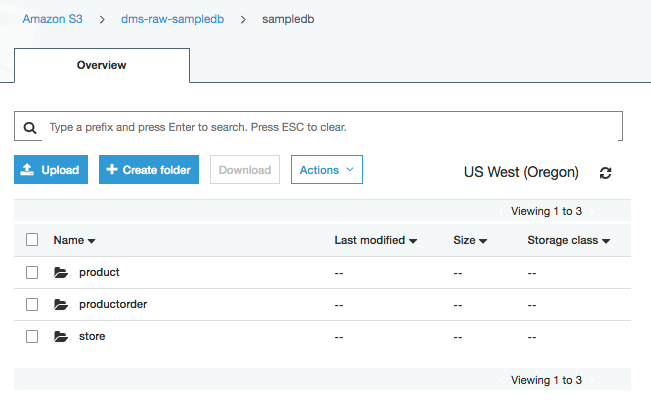
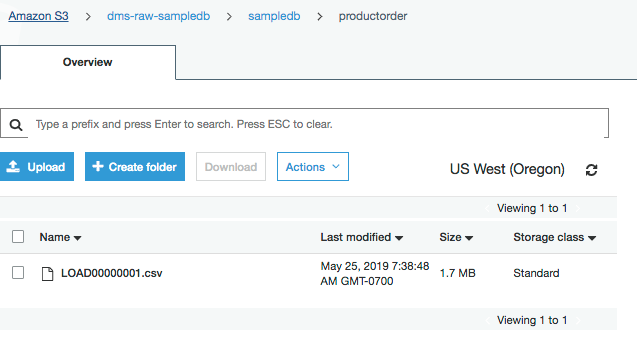
每个文件夹包含一个初始加载文件。
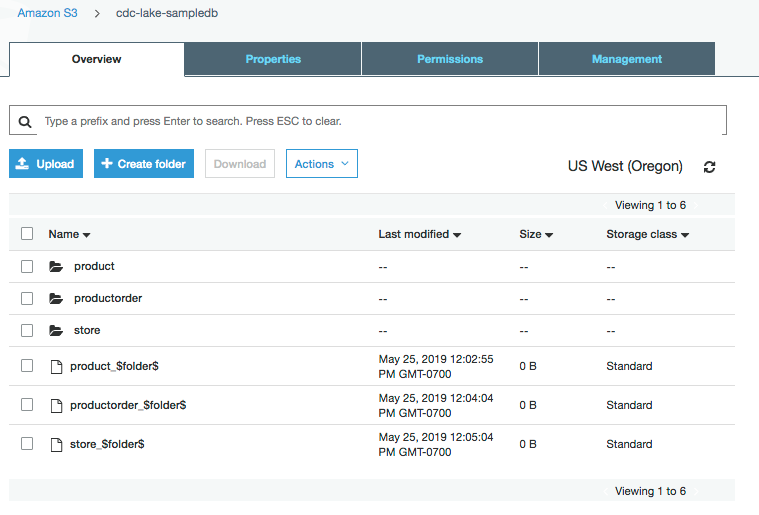
这些表的列表填充 DynamoDB 表。

为这些表设置活动标志、主键和分区键值。在此示例中,我为 product 和 store 表设置主键,以确保它可处理更新。我没有为 productorder 表设置主键,因为我不想更新事务。但是,我设置了分区键以确保按日期对数据进行分区。

当下一个计划的 AWS Glue 作业运行时,它会在数据湖 S3 存储桶中为每个表创建一个文件夹。
运行下一个计划的 AWS Glue 爬网程序时,您的 AWS Glue Data Catalog 会列出这些表。您现在可以使用 Athena 查询它们。
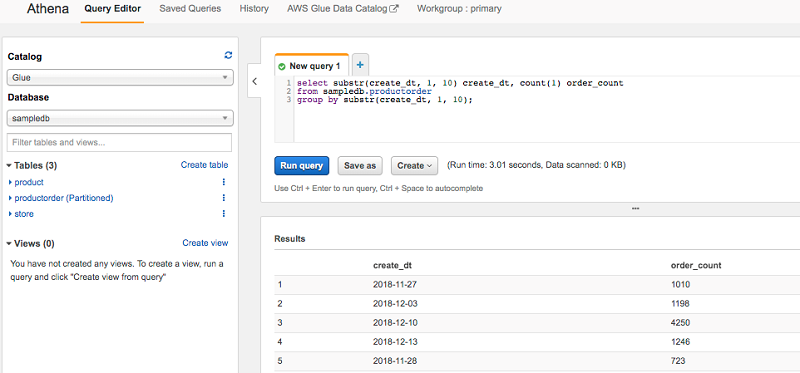
类似的,您可以在首次编目外部数据库之后从 Amazon Redshift 集群中查询数据湖。
在后续 AWS Glue 作业运行时,该过程会将初始文件的时间戳与 DynamoDB 表中的“LastFullLoadDate”字段进行比较,以确定它是否应再次处理初始文件。它还将新增量文件名与 DynamoDB 表中的“LastIncrementalFile”字段进行比较,以确定它是否应处理任何增量文件。在以下示例中,它为 product 表创建了一个新的增量文件。
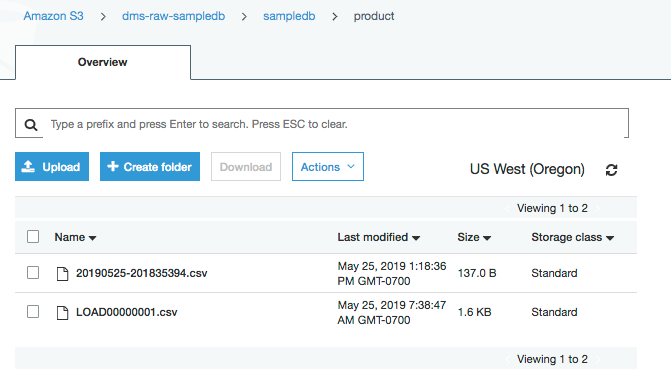
检查文件操作将显示两个事务:一个更新和一个删除。
当 AWS Glue 作业再次运行时,DynamoDB 表会更新以列出“LastIncrementalFile”的新值。

最后,解决方案重新处理 Parquet 文件。您可以查询数据以查看更新记录的新值,并确保移除已删除的记录。
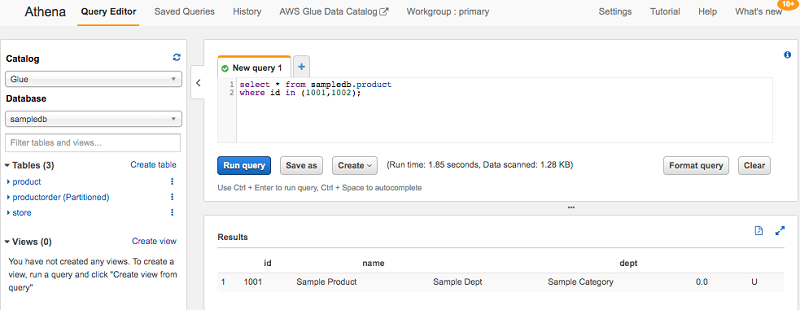
小结
在本文中,我提供了一组 AWS CloudFormation 模板,使您可以快速轻松地将事务数据库与 AWS 数据湖同步。利用 AWS 数据湖中的数据,您可以对来自多个数据源的数据执行分析、构建机器学习模型,并为数据使用者生成丰富的分析。
如果您有任何问题或建议,请在下方发表评论。
作者介绍
Rajiv Gupta 是 Amazon Web Services 的数据仓库专业解决方案架构师。
本文转载自AWS博客。
原文链接:
https://aws.amazon.com/blogs/big-data/loading-ongoing-data-lake-changes-with-aws-dms-and-aws-glue/


中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论