背景介绍
2015 年 12 月,InfoQ 的编辑魏星邀请作者撰写一篇关于中国公有云服务发展状况的文章。因为作者个人对公有云这个领域一直抱有很大的兴趣,便贸然答应了下来。在这篇文章的准备过程中,作者系统地阅读了国内较为知名的几份云计算白皮书 [1,2,3]。作者发现这些报告大都高瞻远瞩提纲挈领,缺乏对具体的公有云服务提供商的描述,未能让读者一窥国内公有云服务发展之真实面貌。在 InfoQ 的协调下,作者与国内多家公有云服务提供商的主要负责人进行了电话访谈,围绕团队建设、产品研发、服务运营这三个问题进行了讨论。除此之外,作者也在本文所探讨的所有公有云上都注册了账号,从用户体检的角度进行了一些小规模的测试。这篇文章的目的,便是从团队建设、产品研发、服务运营、用户体验等四个方面对中国的公有云服务发展状况做一个简要的综述。
根据美国国家标准技术研究院(NIST)的定义 [4],云计算在服务模型上可以划分为软件即服务(SaaS)、平台即服务(PaaS)和设施即服务(IaaS),在发布模型上又可以划分为私有云、社区云、公有云和混合云。需要说明的是,随着云计算技术的发展,如上所述服务模型和发布模型之间的界限也日趋模糊。在本文的范畴内,“公有云”一词泛指面向公众开放服务的平台即服务和设施即服务。除此之外,各种名义的私有云(Private Cloud)、专有云(Dedicated Cloud)、托管云(Managed Cloud)均未包括在本文的范畴之中。
本文中“团队建设”、“产品研发”、“服务运营”三个小节的数据来源有两个。一个是云服务提供商主动发布的新闻资讯,另一个是作者与云服务提供商的主要负责人之间的电话访谈。作者与黄允松(青云)、季昕华(UCloud)、李爽(美团云)、钱广杰(盛大云)、沈志华(又拍云)、王慧星(腾讯云)、许式伟(七牛云)、朱桦(金山云)等业内专家(按姓氏拼音排序)的访谈,是由 InfoQ 方面统一协调安排的,在此作者深表感谢。这个三个小节的内容,在定稿之前均经过受访者及其公关 / 市场团队的确认,反映的是云服务提供商自身的观点和思路。在审稿阶段,青云撤回了与作者进行访谈时所发表的一切言论;出于保护商业机密的考虑,阿里云拒绝了作者的访谈邀请。因此,如上三个小节未能包括青云和阿里云的观点。
“用户体验”和“其他讨论”这两个小节,是作者独立获得的数据以及由此引出的观点,在定稿之前未接受任何一家云服务提供商的审核。需要特别说明的是,如上所述云服务提供商的主要负责人接受作者的访谈并不代表他们认可作者在“用户体验”和“其他讨论”这两个小节中所报告的数据和观点。此外,作者本人也并不持有本文中所讨论的任何一家云服务提供商的内幕信息,作者独立获得的数据仅仅是基于作者所使用的测试方法得到的观测结果。受种种技术条件的限制,作者无法对这些数据的准确性进行背书,也无法对其误差范围进行估算。本文中报告的大部分数据是在 2016 年 3 月底之前获得的,这部分数据的获取时间在正文中不再特别说明;小部分数据是在 2016 年 8 月底获得的,这部分数据的获取时间在正文中会有特别说明。读者在引用本文所报告之数据时,应当考虑到数据的时效性。
本文中有多个小节对各个云服务提供商进行了逐一介绍。相关云服务提供商在这几个小节中出现的顺序是按照拼音字母次序排列的。
本文仅讨论中国本土的公有云服务提供商。Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform 等等进入或者未进入中国市场的外资企业不在本文的讨论范围之内。
其他讨论
弹性计算
弹性计算的核心,是负载均衡与自动伸缩的有机结合。负载均衡这个概念出现得比较早,在整个 IT 行业都已经被广泛接受和广泛应用。本文中所讨论的几家公有云服务提供商,基本上都提供了负载均衡的功能或者特性。自动伸缩则是云计算“按需获取、按量计费”理念的具体实现,最早的实现是 AWS 针对其 EC2 服务所提供的 AutoScaling Group(ASG)功能。本文中讨论的几家公有云服务提供商,只有阿里云(2014 年 9 月)、青云(2015 年 3 月)和 UCloud(2016 年 6 月)提供了类似于 ASG 的自动伸缩功能。
对于一个正常的 Web 应用,其负载通常可以划分成三个档次:长期平均负载,长期高峰负载,短期爆发负载。在每秒只有数百个请求的情况下,云主机集群具备每秒处理一万个请求的能力是没有必要的。在每秒达到数万个请求的情况下,云主机集群只有每秒处理一万个请求的能力是远远不够的。自动伸缩的目的,就是在应用负载降低时自动将多余的云主机从负载均衡上移除并销毁以节省成本,在应用负载升高时自动启动更多的云主机并加入负载均衡以应对压力。通过自动伸缩,用户自动地按照实际负载购买计算资源,既不存在处理能力不足的问题,也不存在浪费计算资源的问题。
显而易见,自动伸缩要求云主机集群中的每一台云主机都能够稳定地提供一定的处理能力。当云主机数量增加时,集群处理能力随之增加;当云主机数量减少时,集群处理能力随之减少。集群处理能力与云主机数量之间的关系不一定是线性的,但必须是正相关的。在理想的情况下,这种关系应该是可预测的。假设我们有一个网络 I/O 密集型应用,每处理 1 万个请求会产生 100MB 的内网流量,但是对 CPU、内存、存储的要求不高。当应用的负载为每秒 1 万个请求时,要求内网带宽大于 100MB/s。在阿里云上应对这样的负载,要求在云主机集群中部署 2 台云主机。在青云上应对这样的负载,要求云主机集群中部署 1 台云主机。当应用的负载为每秒 10 万个请求时,要求内网吞吐量大于 1,000MB/s。在阿里云应对这样的负载,需要在云主机集群中部署 17 台云主机。在青云上应对这样的负载,不管在云主机集群中部署多少台云主机都无能为力,因为需要的内网带宽超出了单个用户所能够使用的带宽上限。
因此,在弹性计算这个场景中,用户需要了解的不是某个产品最高可以达到什么性能,而是最低可以达到什么性能。在云主机网络带宽测试中,阿里云两台云主机之间的网络带宽只有 60MB/s,青云两台云主机之间的网络带宽达到 115MB/s。看起来似乎青云的网络性能要好得多,但是阿里云的网络性能是不随着用户使用量的增加而发生恶化的,青云的网络性能则是随着用户使用量的增加而发生恶化的。在云主机存储带宽测试中,阿里云单台云主机的存储带宽只有 400MB/s,青云单台云主机的存储带宽达到 800MB/s。看起来似乎青云的存储性能要好得多,但是阿里云的存储性能是不随着用户使用量的增加而发生恶化的,青云的存储性能则是随着用户使用量的增加而发生恶化的。
在云计算中,我们常常用坏邻居(noisy neighbours)效应来形容这种那个情形。一台云主机大量使用某种资源造成另一台云主机无法正常使用同种资源,属于坏邻居效应;一个用户大量使用某种资源造成另一个用户无法正常使用某种资源,也属于坏邻居效应。在针对阿里云的测试中,我们没有观察到的坏邻居效应。在针对青云的测试中,同一用户的多台云主机之间存在坏邻居效应,不同用户的云主机之间也存在坏邻居效应。在青云上,通过小规模测试即可在网络和存储两个方面观察到坏邻居效应。基于如上分析,青云虽然提供了自动伸缩的功能,但是其弹性计算能力并不能满足运营一个小规模(10 台云主机以下)高网络 I/O 或者高存储 I/O 型应用的要求。
基于同样的分析,我们在 UCloud 也观察到了如上所述的坏邻居效应。在云主机网络带宽测试中,可以观察到内网带宽存在一定程度的抖动,但是并未观察到明显的性能恶化。在云主机存储带宽测试中,则可以观察到存储带宽随着用户使用量的增加而不断发生恶化。根据作者的判断,UCloud 所提供的自动伸缩功能,可以满足运营一个中等规模(10 到 20 台云主机)高网络 I/O 型应用的要求,但是无法满足运营一个小规模(10 台云主机以下)高存储 I/O 型应用的要求。
不难看出,实现实用意义上的弹性计算要求公有云服务提供商具备两个技术条件。第一,通过细颗粒度的精准限流,保障任意计算资源(CPU、内存、网络、存储)的性能。阿里云的块存储已经具备了细颗粒度的精准限流,其 I/O 能力直接与块存储的容量挂钩,用户可以通过一个简单的公式计算出特定块存储的性能期望值。需要指出的是,阿里云仅对块存储进行了精准限流,但是未对网络 I/O 进行分级限流。在作者的测试中,最高配置的云主机和最低配置的云主机可以使用的网络带宽是相同的。因此,具备一定财务能力的用户依然可以在“合理使用”的原则下以很低的代价来探测阿里云的内网带宽上限。第二,通过储备大量的冗余资源,应对用户爆发性的资源需求。在这个方面,规模较大的公有云服务提供商比规模较小的公有云服务提供商具有明显的优势。在国内的公有云服务提供商中,只有阿里云具备了这个条件。
阿里云给所有配置的云主机提供相同的网络带宽,并不符合“按需获取、按量计费”的理念。目前阿里云所提供的内网带宽可能可以满足中小型 Web 应用的需求,但是尚远远不能满足大型 Web 应用和科学计算应用的需求。作者曾经试图在阿里云上运行一些对网络 I/O 和磁盘 I/O 同时有较高需求的科学计算应用,但是由于网络 I/O 方面的限制未能取得预期的效果。作者注意到阿里云团队在 2015 年 10 月高调发布了新的 100TB 数据排序世界记录 [13],但是这个世界纪录不是在阿里云上获得的,而是阿里云团队在物理机上获得的。出于好奇,作者将阿里云团队于 2015 年取得的进展与 Spark 团队于 2014 年报告的成绩 [14](基于 AWS EC2 服务,使用 i2.8xlarge 实例)以及加州大学圣地亚哥分校(UC San Diego,UCSD)和 Google 团队于 2014 年报告的成绩 [15](基于 AWS EC2 服务,使用 i2.8xlarge 实例)进行了对比。
下表是 UCSD 团队、Spark 团队、阿里云团队在 100TB 排序中的各项参数:
100TB 排序 UCSD (2014) Spark (2014) Aliyun (2015) 网络类型 10 Gbps,虚拟网络 10 Gbps,虚拟网络 10 Gbps,物理网络 网络配置 EC2 placement group EC2 placement group 3:1 subscription ratio 主机类型 EC2 i2.8xlarge EC2 i2.8xlarge 物理机 单机配置 Intel Xeon E5-2670 v2 @2.50GHz,单机 32 个虚拟核心,244GB 内存,8x800GB SSD 硬盘。 Intel Xeon E5-2670 v2 @2.50GHz,单机 32 个虚拟核心,244GB 内存,8x800GB SSD 硬盘。 3134 台:双路 Intel Xeon E5-2630 @2.30 GHz(单机 12 个物理核心),96GB 内存,12x2TB SATA 硬盘;
243 台:双路 Intel Xeon E5-2650 v2 @2.60GHz(单机 16 个物理核心),128GB 内存,12x2TB SATA 硬盘 操作系统 Amazon Linux 2014.03 Amazon Linux 2014.03 RHEL Server 5.7 主机总数 186 206 3,377 CPU 核心总数 5,952 个虚拟核心 6,592 个虚拟核心 41,496 个物理核心 内存总数(GB) 45,384 50,264 331,968 排序时间(秒) 1,378 1,406 377 单颗 CPU 核心每秒所处理的数据量(MB) 12.19 10.99 6.39 单节点每秒所处理的数据量(MB) 390 351.77 78.55 作者发现,同样是 100TB 数据排序,Spark 团队使用了 50TB 内存,UCSD 团队使用了 45TB 内存,阿里云使用了 332TB 内存。打个极度简化的比喻,Spark 团队和 UCSD 团队需要 5 个手指头来做 0 到 9 这十个数字的排序,而阿里云团队需要 33 个手指头来做 0 到 9 这十个数字的排序。
学习过算法的从业人员都知道,在内存富余的情况下进行数据排序,其算法复杂度远低于在内存不足的情况下进行数据排序。在内存不足的情况下,需要先将中间数据写入磁盘,再分批从磁盘读出进行排序操作。在 100TB 数据排序中,内存不足的情况产生 100TB 的网络 I/O 以及 200TB 的磁盘 I/O(读和写操作都是 200TB),内存富余的情况则产生 100TB 的网络 I/O 和 100TB 的磁盘 I/O(读和写操作都是 100TB)。在这种情况下,Spark 团队单颗 CPU 核心平均每秒钟处理的数据量(以 MB 计算)是阿里云团队的 1.72 倍,UCSD 团队单颗 CPU 核心平均每秒钟处理的数据量(以 MB 计算)是阿里云团队的 1.91 倍。我们也注意到阿里云团队所使用的处理器相对较老,其处理能力相对较低。就裸机单线程处理能力而言,Intel Xeon E5-2670 v2 @2.50GHz[18] 是 Intel Xeon E5-2630 @2.30GHz[16] 的 2.5 倍,是 Intel Xeon E5-2650 v2 @2.60GHz[17] 的 1.7 倍。此外,我们也注意到 EC2 实例使用的是虚拟处理器核心,存在一定的虚拟化损失。
基于如上两点,可以推测如果阿里云同样采用 Intel Xeon E5-2670 v2 @2.50GHz 处理器的话,则其单颗 CPU 核心平均每秒钟处理的数据量(以 MB 计算)表面上看来可以与 Spark 团队和 UCSD 团队所报告的成绩持平。问题在于,Spark 团队和 UCSD 团队所处理的是一个比较复杂的场景(数据量是内存的 2 倍),其算法复杂度较高;而阿里云所处理的是一个比较简单的场景(内存是数据量的 3.3 倍),其算法复杂度较低。因此,阿里云所报告的成绩只是集群规模增长的自然结果,其系统和算法远远不如 Spark 团队和 UCSD 团队的系统和算法。(阿里云所处理的场景与 Yahoo 团队于 2013 年所处理的场景 [19] 是类似的,并且其系统和算法优于 Yahoo 团队的系统和算法。)
阿里云所报告的 100TB 数据排序成绩,证明的是阿里云作为一家公司已经具备了管理和使用超大型集群的能力。这个能力与阿里云于 2014 年在 VLDB 上发布的关于伏羲的论文 [20] 所报告的能力是类似的。但是,这个能力与阿里云所提供的产品和服务的能力并不直接相关。譬如说,阿里云的 ECS(云主机)服务所提供的计算、网络和存储能力,尚远远不足以满足运行这个 100TB 数据排序的要求。作者认为,阿里云尚需加强其 ECS 服务所提供的计算、网络和存储能力。什么时候阿里云的用户能够自地主在阿里云所提供的 ECS 服务上运行这个 100TB 数据排序并且达到 Spark 团队于 2014 年所取得的成绩,那么阿里云的 ECS 服务就真的是达到 AWS 的 EC2 服务在 2014 年的水平了。
区域间网络状况
为了了解各个公有云服务提供商的不同区域间的网络状况,我们在阿里云、青云和 UCloud 的华南和华北区域各启动云主机一台,并在两台云主机之间进行 MTR 测试。这部分测试数据,是在 2016 年 8 月底获得的。
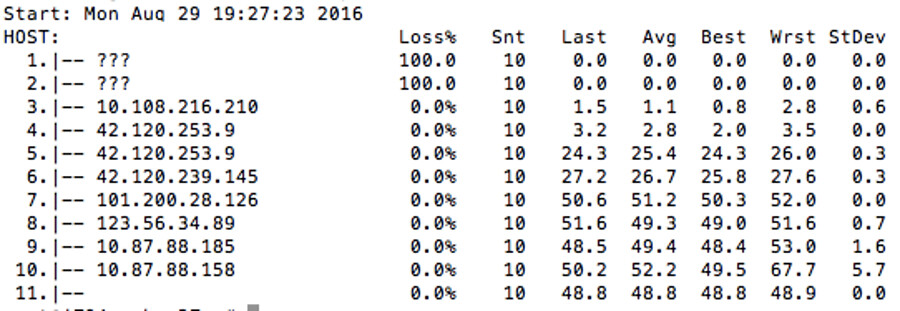
上图所示为阿里云华南 1 区到华北 2 区的测试结果,数据包经过 11 跳抵达目标云主机。在这个路由当中,有 5 跳(4~8)经过的设备使用公网 IP 地址,其余 6 跳经过的设备使用阿里云内网 IP 地址。值得说明的是,上图所示的 4 个公网 IP 全部属于阿里云(属于自治域 AS37963),说明从阿里云华南 1 区到华北 2 区的整个数据链路层都在阿里云的掌控之下。
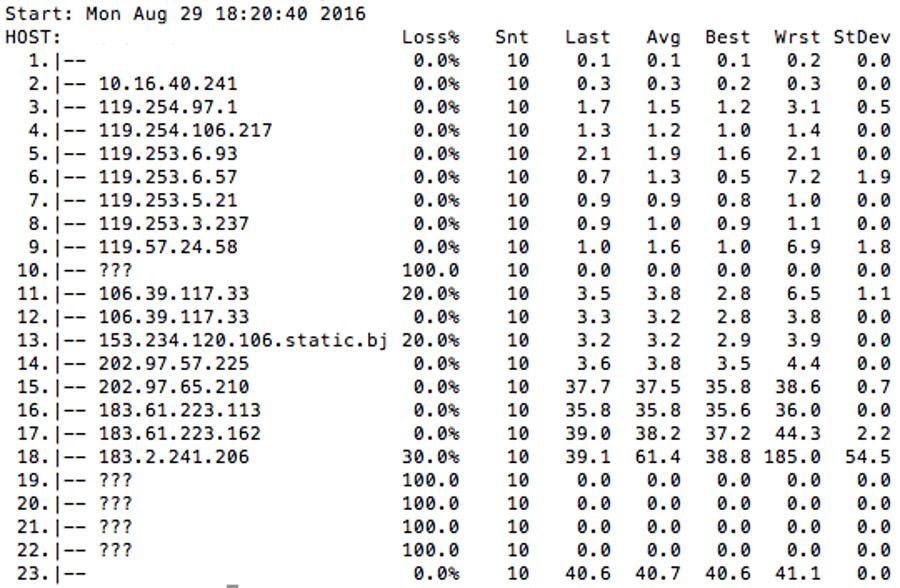
上图所示为青云北京 2 区到广东 1 区的测试结果,数据包经过 23 跳抵达目标云主机。在这个路由当中,有 16 跳(3~18)经过公网,其余 7 跳在青云自己的内网。在整个数据链路上,没有任何一个公网 IP 属于青云。因此,青云不同区域间的互联互通,完全依赖于数据中心服务提供商之间的互联互通。从从这个测试结果来看,青云“1 跳进入全球任何网络运营商的主干网”这个目标可能还需要很长时间方可达成。
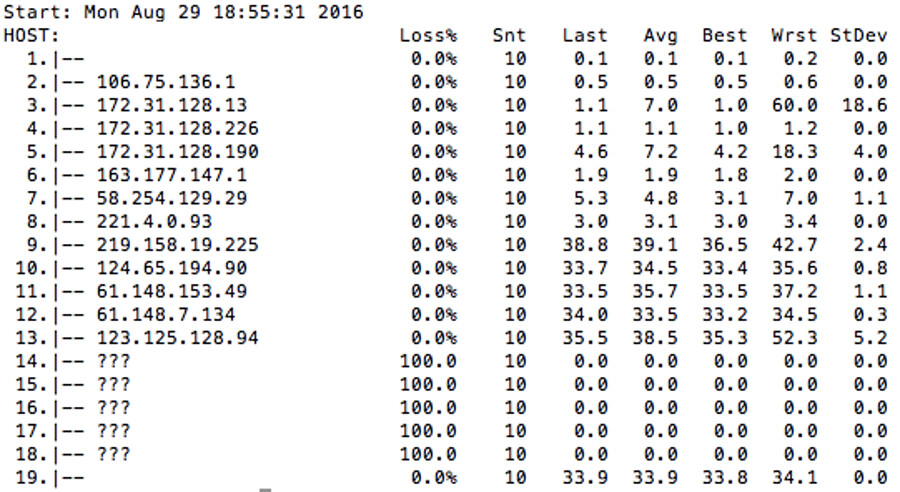
上图为 UCloud 广东 B 区到北京 C 区的测试结果,数据包经过 19 跳抵达目标云主机。在这个路由当中,有 8 跳(6~13)经过公网,其余 11 跳在 UCloud 自己的内网。在整个数据链路上,没有任何一个公网 IP 属于 UCloud。因此,UCloud 不同区域间的互联互通,也完全依赖于数据中心服务提供商之间的互联互通。
从网络拓扑来看,国内互联网可以分为主干网(公网)、地区网(广域网)、主节点(城域网)几个层次。在计算系统可靠度的时候,又可以进一步将其简化成一个串行系统来处理。我们知道,串行系统的可靠度等于系统中各个组件的可靠度的乘积。串行系统中包含的组件越多,则整个系统的可靠性越低。假设一个串行系统中包含 100 个组件,每个组件的可靠度为 0.999,则整个系统的可靠度为 0.999100=0.905。我们知道,中国 ChinaNet 骨干网的拓扑结构在逻辑上分为两层,即核心层和大区层。核心层由北京、上海、广州、沈阳、南京、武汉、成都、西安等 8 个城市的核心节点组成,其功能主要是提供与国际互联的接口以及大区之间互联的通路。全国 31 个省会城市按照行政区划,以上述 8 个核心节点为中心划分为 8 个大区网络。这 8 个大区网共同构成了大区层,大区之间通信必须经过核心层。
基于这样一个极度简化的模型,云服务提供商某个区域所在的数据中心与核心层之间的串行系统的组件数量,约等于如上所述 MTR 测试结果中数据包经过公网的跳数除以二。以此估算,阿里云的串行系统组件数量为 2,青云的串行系统组件数量为 8,UCloud 的串行系统组件数量为 4。假设这个串行系统中每个组件的可靠度是相同的(实际上并不相同),则阿里云数据链路的可靠度大于 UCloud,而 UCloud 数据链路的可靠度大于青云。
市场规模
根据 Gartner 的统计数据,在 2006 到 2014 年间,全球服务器硬件市场每年的出货量稳定地在 10,000,000 台上下波动。其中,亚太地区占比在 1/4 左右,也就是 2,500,000 台。中国境内服务器出货数量在亚太地区的占比不详,保守地按 1/5 计算也有 500,000 台。按照 5 年折旧周期进行估算,全国范围内现役的计算资源至少有 2,500,000 台物理服务器。(根据可靠的数据来源,仅阿里巴巴、百度、腾讯三家大型互联网公司所拥有的物理服务器总量就已经超过了 1,000,000 台。全国范围内现役的计算资源总量可能远大于 2,500,000 这个估值。)作为一家服务于“中国”的产业级别的公有云服务提供商,假设其业务成熟之后拥有全国计算资源的 1%,就是 25,000 台物理服务器。再按 1:4 的虚拟化比例进行估算(这个虚拟化比例也是一个偏低的估值),则虚拟机的数量为 100,000 台左右。
公有云作为一种新型服务,其市场规模尚有相当程度的自然增长空间。因此,五年之后的公有云可能达到的规模只会比这个数字更大。基于这些估算,我们可以根据其规模将一家公有云创业企业的成长分为五个阶段:
- 概念阶段,小于 5,000 台虚拟机。公司的终极目标相对模糊,在私有云解决方案提供商和公有云服务提供商之间摇摆不定。在战术层面,缺乏明确的技术路线图,产品形态相对原始并且没有明确的技术指标。
- 原型阶段,小于 10,000 台虚拟机。公司基本上将其终极目标定位为公有云服务提供商。由于公有云和私有云之间的巨大差异,必然要放弃私有云解决方案服务提供商的身份。在战术层面,基本形成相对清晰的技术路线图,基础产品(云主机)基本定型,在宕机时间和产品性能方面均有明确的技术指标。在云主机的基础上,提供能够承担中低负载的负载均衡、数据库、缓存等等周边产品。
- 成长阶段,小于 50,000 台虚拟机。基础产品(云主机)能够满足高性能计算的要求,同时发展出一系列模块化的周边产品。普通用户完全依靠云服务提供商所提供的不同模块即可自主创建大规模可伸缩型应用(无需云服务提供商进行干预)。
- 成熟阶段,小于 100,000 台虚拟机。在技术方面,资源利用率开始提高,规模效应开始出现。在市场方面,客户忠诚度开始提高,马太效应开始出现。这标志着公司在公有云领域已经获得了较有份量的市场份额,其产品和技术获得了一个或者多个细分市场的广泛认可。
- 产业阶段,大于 100,000 台虚拟机。只有进入这一阶段,才能够认为一个服务提供商已经站稳了脚跟,可以把公有云当作一个产业来做了。至于最后能够做多大,一个好看国内的大环境,另外一个还得看公司自身的发展策略。
根据本文的测试数据,作者认为国内公有云服务提供商中(仅考虑以设施服务 IaaS 部分)只有美团云尚处于原型阶段,盛大云处于成长阶段早期,青云和腾讯云处于成长阶段中期,UCloud 处于成熟中晚期,只有阿里云已经进入产业阶段。由于作者缺乏金山云相关数据,在此不对金山云进行判断。从 2016 年 9 月和 2016 年 3 月的端口扫描结果差异来看,马太效应在国内公有云服务行业内是非常显著的。
基于本文所述的网络规模探测数据,作者倾向于认为目前国内公有云市场所提供的云主机总量小于 500,000 台。考虑到公有云的早期用户大都是将云主机当作 VPS 来使用,并且偏向于使用配置较低的小型云主机实例,平均意义上的虚拟化比例可能远远高于本文前面提到的 1:4。因此,作者偏向于认为目前国内公有云市场所提供的计算能力尚低于国内现有计算能力总量的 2%。随着公有云服务的逐步成熟,企业采购计算资源时的偏好将逐渐从采购物理服务器或者使用数据中心托管服务过渡到使用公有云服务。未来五到十年里,各种运行在中小型数据中心内的负载还会稳步向大型公有云服务提供商迁移。在这种大趋势的影响下,公有云市场所提供的计算能力在全国计算能力总量中所占的比例也会稳步提高。
公有云服务的未来还远远不止于此。作者于 2012 年在《虚拟化、云计算、开放源代码及其他》[6]] 这篇博客里面提到了英国经济学家威廉杰文斯(William Stanley Jevons,1835-1882)在《煤矿问题》(The Coal Question)[5] 一书中指出的一个似乎自相矛盾的现象:蒸汽机效率方面的进步提高了煤的能源转换率,能源转换率的提高导致了能源价格降低,能源价格的降低又进一步导致了煤消费量的增加。这种现象称为杰文斯悖论,其核心思想是资源利用率的提高导致价格降低,最终会增加资源的使用量。在过去 150 年当中,杰文斯悖论在主要的工业原料、交通、能源、食品工业等多个领域都得到了实证。基于同样的原理,作者在这篇博客里面又进一步断言:“公共云计算服务的核心价值,是将服务器、存储、网络等等硬件设备从自行采购的固定资产变成了按量计费的公共资源。虚拟化技术提高了计算资源的利用率,导致了计算资源价格的降低,最终会增加计算资源的使用量。”。
因此,作者在多篇文章 [6,7,8,9] 中反复指出,公有云市场不是一个短期市场,而是一个未来五到十年尚有充分增长空间的市场。目前国内的公有云市场依然处于早期阶段,所谓“随着国内云计算市场逐步成熟,公有云市场份额基本上大势已定”的论调未免过于目光短浅。在国内现有的几家公有云服务提供商中,除了阿里云可以算是已经站稳了脚跟之外,其他几个公有云服务提供商当中的任何一个都有可能突然倒塌,还可能有新的公有云服务提供商脱颖而出。作者倾向于认为,至少要等到 2018 年才有可能发生中国公有云市场份额“大势已定”的情况。这也是为何作者一直强调公有云服务是一片刚刚显现的蓝海。现在国内各个公有云服务提供商杀得你死我活,看起来似乎已经是一片血海。在作者看来,这些不过都是假象。如果一家公有云领域的创业企业没有这样的大局观,那么作者只有一个建议:“认怂服输,割肉止损,是为美德。”
用户习惯
根据作者的观察,目前国内大部分公有云用户还是把云主机当作传统物理服务器的替代品来使用。这个观察在作者与各个公有云服务提供商负责人的访谈中也得到了验证。
在传统的 IT 架构中,操作系统是安装在物理服务器上的。由于重新安装操作系统需要造成很长的宕机时间,出现软件层面故障时运维或者开发人员往往倾向于寻找问题来源并予以排除。很多时候,运维或者开发人员需要花费很长时间来寻找一些不易发觉的输入或者拼写错误(例如四个空格和一个 tab)。在弹性计算这个场景中,操作系统是通过映像模板创建的,获得一台全新的包含正确配置的云主机只需要数分钟甚至更短的时间。在这个时间优势的基础上,云计算服务提供商终于可以直面长期以来被传统 IT 服务提供商所刻意回避的两个事实。第一个事实是组件的失效是必然的,是不可避免的;第二个事实是组件的失效是随机的,是不可预测的。用 AWS 首席技术长官 Werner Vogels 的原话来说,就是“任何组件可在任何时刻失效”(Everything fails, all the time.)。在负载均衡与自动伸缩的帮助下,一个集群中任意云主机均可以在任意时刻由于任意原因(底层硬件、网络环境、操作系统、应用软件)发生失效。在一台云主机发生失效时,自动伸缩功能自动地将其从负载均衡上移除并进行销毁,同时自动地启动一台新的云主机并加入负载均衡。因此,用户可以将云主机视为“即用即抛型”一次性资源。忽略云主机的失效,不仅不会牺牲应用服务质量,还可以将宝贵的资源集中投入到公司的关键业务。
可惜的是,由于缺乏对弹性计算的理解,大量系统管理员延续了在使用物理服务器时期培养的习惯。他们在云主机等计算资源失效时惊慌失措,并且热衷于寻找所谓的“根本原因分析”(root cause analysis)。他们在潜意识里还是将基础设施视为公司的资产,试图去了解和掌握云主机之下每一个层面的信息。他们没有意识到在弹性计算这个场景里这些努力不仅没有必要而且会阻碍整个公司技术进步。解决这个问题,需要所有的公有云服务提供商持之以恒地对用户进行教育。用户的认知水平提高了,也会进一步促进公有云市场的发展。
除了对用户进行教育之外,公有云服务提供商也需要加强对员工的教育。有些一线研发人员虽然是为公有云服务提供商工作,但是对弹性计算也缺乏理解。2016 年春节联欢晚会期间,新浪微博成功地使用阿里云承担了部分高峰负载。这本来是一个值得大书特书的成功案例,但是多位阿里云团队成员通过微博公开指责新浪微博“直到最后一刻才开通所需的计算资源”之举过于小气。虽然这样的指责近乎调侃性质,也不能不说是一个在 KPI 重压之下令人沮丧的失败案例。
安全问题
在“用户体验”这个小节的网络测试部分,作者仅报告了针对阿里云的 1433、3306 和 11211 端口扫描情况。主要的考虑在于小型公有云服务提供商更加需要保护,因此不宜对小型公有云服务提供商进行同类测试;次要的考虑在于公有云服务提供商无法独立承担安全重任,因此需要向从业人员披露公有云服务中存在的安全隐患。需要说明的是,作者在阿里云内网和外网获得的端口扫描结果,并非阿里云独有的现象。任何一个刚刚学会运行 bash 脚本的从业人员,都可以通过类似方法在 AWS 所在的 IP 段扫描到类似的结果。阿里云和 AWS 的不同之处,在于阿里云教育客户“选择云盾,让您的业务安全性如同阿里巴巴一般”,AWS 则教育客户“安全共担”(shared responsibility)模型。云盾的产品介绍页面宣称“每天防御超过 958 万次暴力破解攻击”,但是作者基于社会工程数据库的自动化登录测试也获得了部分成功。这样的结果,可以有三个解释:
- 大部分被成功登录的云主机没有使用云盾服务;
- 少部分被成功登录的云主机虽然使用了云盾服务但是其密码设置过于薄弱,因此在云盾未被激活之前就已经被成功登录;
- 类似于 Memcached 这样免登录的服务,云盾目前是完全无能为力的。在阿里云内网,作者还探测到大量其他免登录或者仅使用弱口令保护的网络服务,例如 RabbitMQ。
因此,不管用户是否使用服务提供商所提供的云安全服务,均应对客户进行“安全共担”的教育,引导客户采取必要的措施保护其所使用的计算资源。遗憾的是,阿里云作为国内规模最大的公有云服务提供商,向用户传达了完全错误的信息。作者建议阿里云安全团队针对阿里云内网进行常规性的分布式端口扫描,充分了解安全隐患的严重程度,并在此基础上向阿里云的用户提出针对性的改进建议。
作者也注意到阿里云于 2014 年 7 月获得了首批数据中心联盟授予的“可信云服务认证”。公开的资料表明,可信云服务认证由数据中心联盟组织、中国信息通信研究院测试评估,是我国唯一针对云服务可信性的权威认证体系。(据其官方网站介绍,数据中心联盟是工业和信息化部通信发展司指导下成立、由中国通信标准化协会管理的非营利性第三方组织。)作者对阿里云进行的测试表明,这个“可信云服务认证”如同虚设,无法保护公有云用户免于弱口令暴力破解等入门级网络攻击威胁。更为严重的是,通过数据中心联盟这样一个半官方机构所谓的“权威认证体系”给不安全的公有云服务背书,引导安全观念原本就极为淡薄的用户更加忽视公有云服务中的安全问题,给互联网信息安全带来了极大的安全隐患。
对公有云服务在安全方面的顾虑,是阻止金融行业等极度保守型客户使用公有云服务的重要原因。例如,招商银行信息技术部副总经理、数据中心总经理高旭磊 [23] 明确地认为“金融云在可靠和可用性方面远高于普通商业云”。高旭磊在文章中指出:“目前公有云的服务对象仍然是以互联网企业为主,但是运行关键业务(Mission Critical)的企业非常少,服务质量和数据安全是这些企业踌躇不前的主要原因。仅 2014 年,大型的公有云就出现了多起严重的宕机影响在线服务的事件,其中亚马逊 AWS CloudFront DNS 服务器宕机超过 2 小时,导致一些网站和云服务的内容传输网络全部下线;Microsoft Azure 公有云出现了 4 次严重宕机事件,累计时长超过 20 小时,导致大量用户无法使用。”尽管高旭磊的论据和论点之间缺乏必要的逻辑联系,又将可用性、可靠性、安全性等多个概念混为一谈,他的文章清楚地反映出金融行业客户对公有云服务在安全方面的不信任心态。作者注意到阿里巴巴旗下蚂蚁金服集团于 2015 年 10 月推出了针对金融行业客户的蚂蚁金融云,并将安全作为其卖点之一。蚂蚁金融云宣称“基于阿里云计算强大的基础资源”,但是在阿里云内部称为专有云服务(Dedicated Cloud Servicve)[24],并不与阿里云的公有云服务使用同一套基础设施。换句话说,蚂蚁金服云直接否定了阿里云的公有云服务在安全方面的能力。
其他
众所周知,国内的互联网创业环境并不单纯。创业公司夸大创始人资历、融资额度、经营规模、性能参数等等数据,在整个大环境中几乎是家常便饭。在国内的公有云服务领域,类似的现象同样存在并且非常严重,主要集中在服务规模和产品性能两个方面。在撰写本报告的过程中,作者系统地阅读了过去一年中不同公有云服务提供商通过不同渠道发布的各种官方和非官方的规模和性能数据。在服务规模方面,大部分伪造数据者对国内信息行业的总体规模缺乏基本了解。在产品性能方面,大部分性能报告都巧妙地利用了 AWS 在 10 年前发布的“标准型”EBS 卷,通过田忌赛马的技巧将产品层面的对比降级为 SSD 硬盘与机械硬盘的对比,进而得出超越 AWS 的结论。值得注意的是,这样的现象同样不仅仅出现在中小型公有云服务提供商,阿里云这样的大型公有云服务提供商也不能免俗。阿里云级别很高的资深员工也在微博上公开传播第三方伪造的性能测试数据,但是在作者提醒后很快删除类似言论。
除此以外,作者认为国内大部分公有云服务提供商在做事上是还是踏实靠谱的。在与作者的电话访谈中,各位公有云服务提供商的负责人不仅坦诚地阐述创业当中的决策过程,也坦诚地提出对行业发展的观点和疑问。尤其是七牛云的许式伟和 UCloud 的季昕华,与他们的访谈给作者留下了非常深刻的印象。他们所提供的产品和服务或许尚不完美,他们所报告的数据或许略有夸大,但是作者深深地感觉到他们在做事上是认真的,他们对客户是诚恳的。唯一的例外,却是青云。青云在国内云计算行业的名气很大,是一家有理想有情怀的创业公司。但是与青云 CEO 黄允松的访谈和对青云进行测试的结果都令作者对青云大失所望。作为一家创业企业,有理想有情怀不是坏事。但是,如果一昧沉溺在理想和情怀当中不能自拔,甚至是将理想和情怀当成产品和服务来卖,恐怕对创业企业的发展并无益处。
信息披露
作者蒋清野是悉尼大学信息技术学院的博士研究生,同时也是 AWS 悉尼技术支持中心的员工。他于 1999 年获得清华大学学士学位(土木工程),2000 年获得伊利诺伊大学香槟分校硕士学位(土木工程),2015 年获得悉尼大学硕士学位(计算机科学)。他的研究兴趣包括分布式与高性能计算、开源社区的社会学行为、信息技术领域的微观经济学分析。他是美国电子电气工程师学会(IEEE)的高级会员。
在接受 InfoQ 方面的邀请准备规划这篇报告的时候,作者的内心是兴奋的。在获得所有测试数据准备撰写这篇报告的时候,作者的内心是矛盾的。一方面,作为并行与分布式计算领域的学生,作者希望为业界提供一些有用的信息和观点;另一方面,作为公有云服务领域的从业人员,作者深知发表一份涉及多家友商的报告会带来诸多争议。在 InfoQ 方面的鼓励下,作者选择以真实的身份发布这些的数据和观点,希望能够对国内云计算从业人员有所帮助。
参考文献
- 工业和信息化部电信研究院(中国信通院,CAICT),《云计算白皮书(2014 年)》,2014 年 5 月
- 中国电子信息产业发展研究院工业和信息化部赛迪智库,《云计算发展白皮书(2015 版)》,2015 年 4 月
- 工业和信息化部电信研究院(中国信通院,CAICT),《云计算白皮书(2016 年)》,2016 年 9 月
- Peter Mell and Timothy Grance, “ The NIST Definition of Cloud Computing ”, NIST Special Publication 800-145, September 2011
- William Stanley Jevons, “ The Coal Question ”, 1866
- 蒋清野,《虚拟化、云计算、开放源代码及其他》,2012 年 10 月
- 蒋清野,《从王博士说起》,2013 年 12 月
- 蒋清野,《浅谈“中国”语境下的公有云发展》,2015 年 5 月
- Qingye Jiang, Young Choon Lee, Albert Y. Zomaya, “ Price Elasticity in the Enterprise Computing Resource Market ”, IEEE Cloud Computing, vol.3, no. 1, pp. 24-31, Jan.-Feb. 2016, doi:10.1109/MCC.2016.14
- 章文嵩,《淘宝软件基础设施构建实践》,第三届中国云计算大会,2011 年 5 月
- 高山渊,《阿里巴巴系统运维实践分享》,QClub 深圳站,2012 年 6 月
- Netcraft, “ Aliyun cloud growth makes Alibaba largest hosting company in China ”, May 2015
- Jiamang Wang, Yongjun Wu, Hua Cai, Zhipeng Tang, Zhiqiang Lv, Bin Lu, Yangyu Tao, Chao Li, Jingren Zhou, Hong Tang, “ FuxiSort “, Alibaba Group Inc, October 2015
- Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia, “ GraySort on Apache Spark by Databricks “, Databricks Inc., October 2014
- Michael Conley, Amin Vahdat, George Porter, “ TritonSort 2014 “, University of California at San Diego, 2014
- Intel Xeon E5-2630 基准测试数据
- Intel Xeon E5-2650 基准测试数据
- Intel Xeon E5-2670 基准测试数据
- Thomas Graves, “ GraySort and MinuteSort at Yahoo on Hadoop 0.23 “, Yahoo!, May 2013
- Zhuo Zhang, Chao Li, Yangyu Tao, Renyu Yang, Hong Tang, and Jie Xu. “ Fuxi: a fault-tolerant resource management and job scheduling system at internet scale. ” Proceedings of the VLDB Endowment 7, no. 13 (2014): 1393-1404.
- 华为集团,《华为服务器助力腾讯构建十万级高效部署》,2014 年 7 月
- 陈海泉,《下一代超大规模软件定义网络技术实践》,2016 年 1 月
- 高旭磊,《招商银行关于金融云的思考》,中国金融电脑,2016 年 8 月
- 阿里云,《阿里云生态路线图》,2015 年 7 月
感谢魏星对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




