

从 2016 年起,字节跳动开始着手服务云原生化改造,截至今日,字节服务体系主要包含四类:传统微服务(大多是基于 Golang 的 RPC Web 服务)、推广搜服务(传统 C++ 服务)、机器学习和大数据服务以及各类存储服务。
在字节跳动,基础设施面临的是一个规模巨大且持续快速变化的业务场景,而云原生技术体系需要同时聚焦资源效率和研发效率。在资源效率上,云原生要解决的核心问题之一就是如何提高集群的资源利用效率。
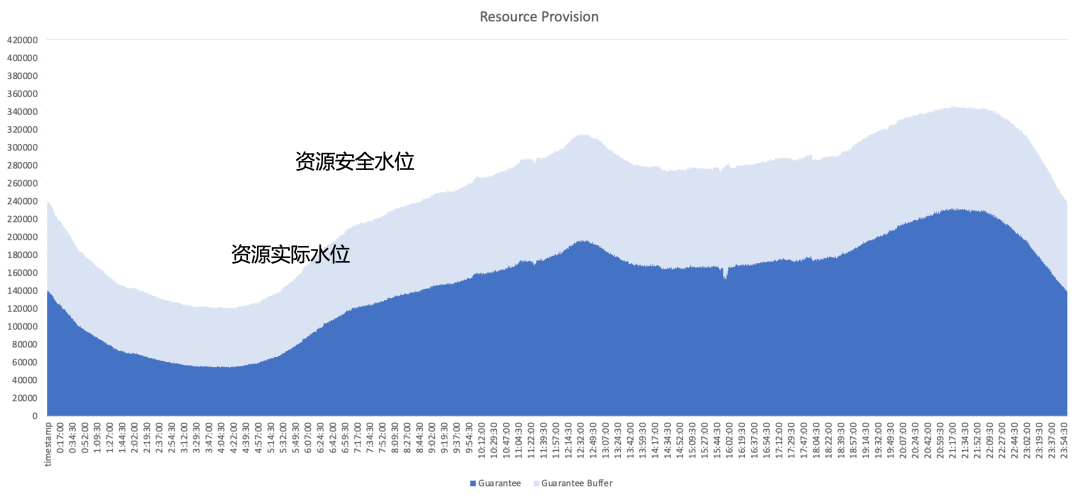
以典型的在线服务的资源使用情况为例,下图深蓝色部分是业务实际使用的资源量,浅蓝色部分为业务提供的安全缓冲区。即使增加缓冲区,仍有很多资源处于业务已申请但未使用的状态,因此我们的优化重点是从架构的角度尽可能地利用这些未使用的资源。
针对上述情况,字节跳动内部尝试过若干不同类型的资源治理方案,包括
资源运营:定期帮助业务跑资源利用情况并推动资源申请治理,问题是运维负担重且无法根治利用率问题;
动态超售:在系统侧评估业务资源量并主动缩减配额,问题是超售策略不一定准确且可能导致挤兑风险;
动态扩缩:问题是如果只针对在线服务扩缩,由于在线服务的流量波峰波谷类似,无法充分实现全天利用率提升。
最终我们决定采用混合部署,将在线和离线同时运行在相同节点,充分利用在线和离线资源之间的互补特性,实现更好的资源利用。我们期望达到如下图的效果,即二次销售在线未使用的资源,利用离线工作负载能够很好地填补这部分超售资源,实现资源利用效率在全天保持在较高水平。

字节跳动混部发展历程
随着字节跳动各业务云原生化的推进,我们根据不同阶段业务需求和技术特点,选择合适的混合部署方案,并在此过程中不断迭代我们的混部系统。
2.1 阶段一:在离线分时混部
第一个阶段主要进行在线和离线的分时混合部署。
对在线:在该阶段我们构建了在线服务弹性平台,用户可以根据业务指标配置横向伸缩规则;例如,凌晨时业务流量减少,业务主动缩减部分实例,系统将在实例缩容基础上进行资源 Bing Packing 从而腾出整机;
对离线:在该阶段离线服务可获取到大量 spot 类型资源,由于其供应不稳定所以成本上享受一定折扣;同时对于在线来说,将未使用的资源卖给离线,可以在成本上获得一定返利。
该方案优势在于不需要采取复杂的单机侧隔离机制,技术实现难度较低;但同样存在一些问题,例如:
转化效率不高,bing packing 过程中会出现碎片等问题;
离线使用体验可能也不好,当在线偶尔发生流量波动时,离线可能会被强制杀死,导致资源波动较强烈;
对业务会造成实例变化,实际操作过程中业务通常会配置比较保守的弹性策略,导致资源提升上限较低。

2.2 阶段二:Kubernetes/YARN 联合混部
为解决上述问题,我们进入了第二个阶段,尝试将离线和在线真正跑在一台节点上。
由于在线部分早先已经基于 Kubernetes 进行了原生化改造,但大多数离线作业仍然基于 YARN 进行运行。为推进混合部署,我们在单机上引入第三方组件负责确定协调给在线和离线的资源量,并与 Kubelet 或 Node Manager 等单机组件打通;同时当在线和离线工作负载调度到节点上后,也由该协调组件异步更新这两种工作负载的资源分配。
该方案使得我们完成混部能力的储备积累,并验证可行性,但仍然存在一些问题:
两套系统异步执行,使得在离线容器只能旁路管控,存在 race;且中间环节资源损耗过多;
对在离线负载的抽象简单,使得我们无法描述复杂 QoS 要求;
在离线元数据割裂,使得极致的优化困难,无法实现全局调度优化。

2.3 阶段三:在离线统一调度混部
为解决第二阶段的问题,在第三阶段我们彻底实现了在离线统一的混合部署。
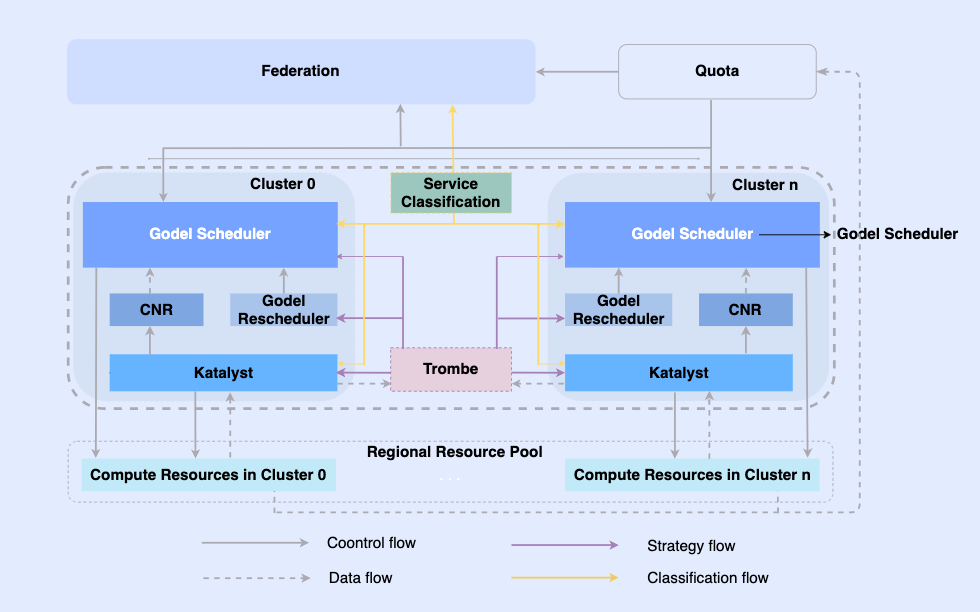
通过对离线作业进行云原生化改造,我们使它们可以在同一个基础设施上进行调度和资源管理。该体系中,最上面是统一的资源联邦实现多集群资源管理,单集群中有中心的统一调度器和单机的统一资源管理器,它们协同工作,实现在离线一体化资源管理能力。
在该架构中,Katalyst 作为其中核心的资源管控层,负责实现单机侧实时的资源分配和预估,具有以下特点:
抽象标准化:在离线元数据打通,在 QoS 的抽象上更加复杂和丰富,更好地满足业务对性能的要求;
管控同步化:在容器启动时下发管控策略,避免在启动后异步修正资源调整,同时支持策略的自由扩展;
策略智能化:通过构建服务画像提前感知资源诉求,实现更智能的资源管控策略;
运维自动化:通过一体化的交付,实现运维自动化和标准化。
Katalyst 系统介绍
Katalyst 引申自英文单词 catalyst,本意为催化剂,首字母修改为 K,寓意该系统能够为所有运行在 Kubernetes 体系中的负载提供更加强劲的自动化资源管理能力。
3.1 Katalyst 系统概览
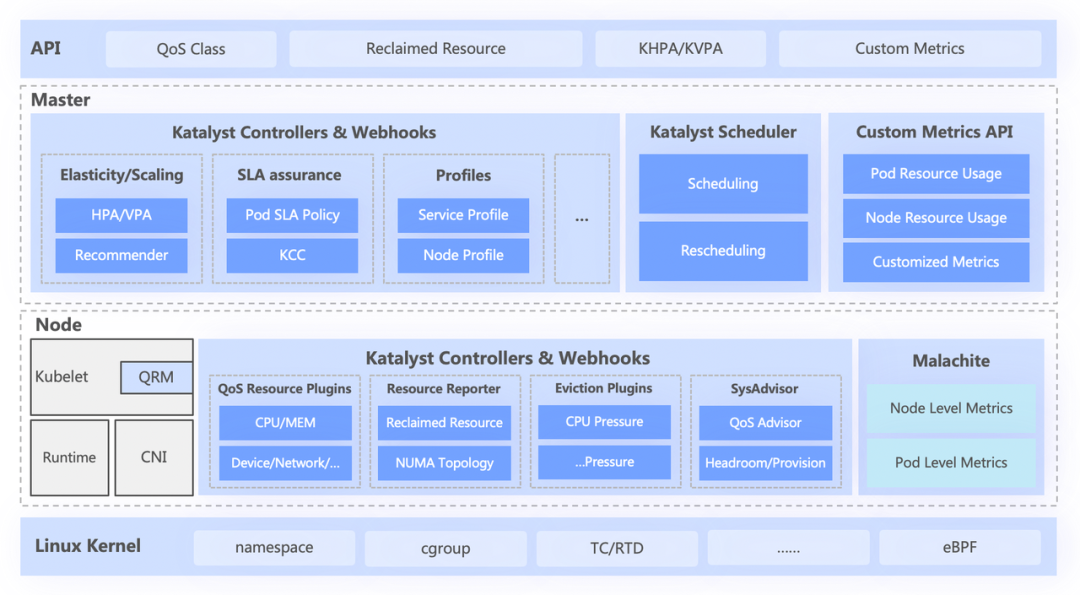
如下图所示,Katalyst 系统大致分为四层,从上到下依次包括:
最上层的标准 API,为用户抽象不同的 QoS 级别,提供丰富的资源表达能力;
中心层则负责统一调度、资源推荐以及构建服务画像等基础能力;
单机层包括自研的数据监控体系,以及负责资源实时分配和动态调整的资源分配器;
最底层是字节定制的内核,通过增强内核的 patch 和底层隔离机制解决在离线跑时单机性能问题。
3.2 抽象标准化:QoS Class
Katalyst QoS 可以从宏观和微观两个视角进行解读。
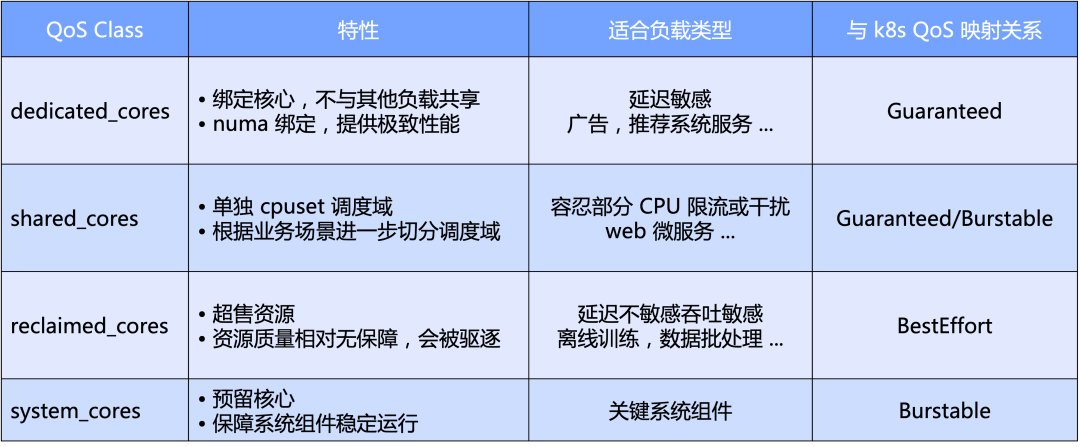
宏观上,Katalyst 以 CPU 为主维度定义了标准的 QoS 级别;具体来说我们将 QoS 分为四类:独占型、共享型、回收型和为系统关键组件预留的系统型;
微观上,Katalyst 最终期望状态无论什么样的 workload,都能实现在相同节点上的并池运行,不需要通过硬切集群来隔离,实现更好的资源流量效率和资源利用效率。
在 QoS 的基础上,Katalyst 同时也提供了丰富的扩展 Enhancement 来表达除 CPU 核心外其他的资源需求:
QoS Enhancement:扩展表达业务对于 NUMA / 网卡绑定、网卡带宽分配、IO Weight 等多维度的资源诉求;
Pod Enhancement:扩展表达业务对于各类系统指标的敏感程度,比如 CPU 调度延迟对业务性能的影响;
Node Enhancement:通过扩展原生的 TopologyPolicy 表示多个资源维度间微拓扑的组合诉求。
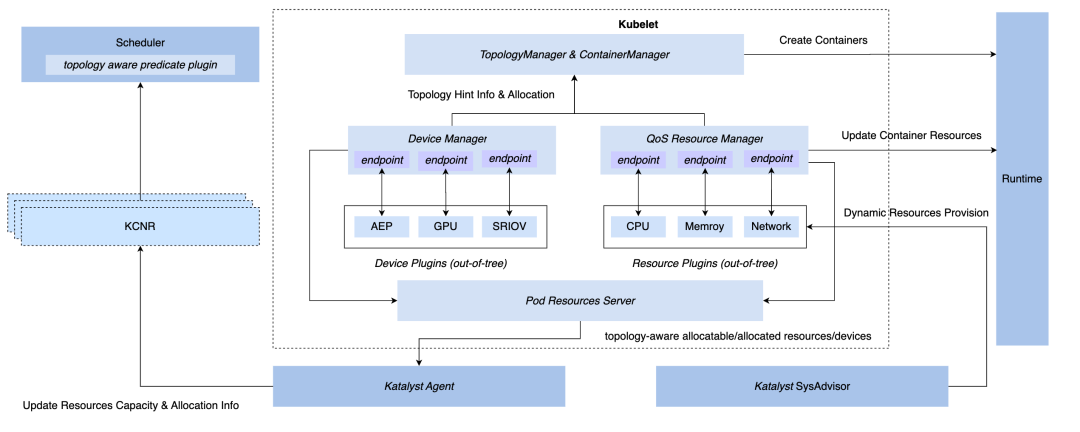
3.3 管控同步化:QoS Resource Manager
为在 Kubernetes 体系下实现同步管控的能力,我们有三种 hook 方式:CRI 层、OCI 层、Kubelet 层。最终 Katalyst 选择在 Kubelet 侧实现管控,即实现和原生的 Device Manager 同层级的 QoS Resource Manager,该方案的优势包括:
在 admit 阶段实现拦截,无需在后续步骤靠兜底措施来实现管控;
与 Kubelet 进行元数据对接,将单机微观拓扑信息通过标准接口报告到节点 CRD,实现与调度器的对接;
在此框架上,可以灵活实现可插拔的 plugin,满足定制化的管控需求。
3.4 策略智能化:服务画像和资源预估
通常,选择使用业务指标构建服务画像比较直观,例如服务 P99 延迟或者下游的错误率。但其也存在一些问题,比如相对系统指标而言,业务指标的获取通常更不容易;业务通常会集成多个的框架,他们生产的业务指标含义并不完全相同,如果强依赖这些指标,整个管控的实现就会变得非常复杂。
因此,我们希望最终的资源调控或服务画像是基于系统指标而非业务指标来实现,其中最关键的就是如何找到业务最关心的系统指标。
我们的做法是使用一套离线的 pipeline 去发现业务指标和系统指标之间的匹配。例如,对于图中服务来说,最核心的业务指标是 P99 调用延迟,通过分析发现与其相关度最高的系统指标是 CPU 调度延迟,我们会不断调整服务的资源供应量,尽可能地逼近它的目标 CPU 调度延迟。
在服务画像的基础上,Katalyst 针对 CPU、内存、磁盘和网络等方面提供了丰富的隔离机制,必要时还对内核进行了定制以提供更强的性能要求。然而对于不同的业务场景和类型,这些手段并不一定直接适用,因此需要强调的是,隔离更多是一种手段而不是目的,我们在承接业务的过程中,需要根据具体的需求和场景来选择不同的隔离方案。
3.5 运维自动化:多维度动态配置管理
尽管我们希望所有的资源都在一个资源池系统下,但是对于在大规模生产环境中,我们不可能把所有节点都放在一个集群里。此外,一个集群中可能同时有 CPU 与 GPU 的机器,虽然可以共享控制面,但在数据面上需要一定的隔离。在节点级别,我们也经常需要修改节点维度配置以进行灰度验证,导致在同一节点上运行不同服务的 SLO 存在差异。
为解决这些问题,我们需要在业务部署时,考虑节点的不同配置对服务的影响。为此,Katalyst 针对标准交付提供了动态配置管理的能力,通过自动化的方法评估不同节点的性能和配置,并根据这些结果来选择最适合该服务的节点。
Katalyst 应用与案例分析
在本章节,我们将结合字节内部的案例分享一些最佳实践。
4.1 利用率效果
从 Katalyst 实施效果上来说,基于字节内部业务的实践,我们在季度周期内,资源都可以保持在相对较高的状态;在单个集群中,每天的各个时间段内资源利用率也呈现出比较稳定的分布;同时,集群中大部分机器利用率也比较集中,我们的混合部署系统在所有节点上运行都比较稳定。

4.2 实践:离线无感接入
在进入第三阶段后,我们需要对离线进行云原生化改造。改造方式主要有两种,一种是已经在 K8s 体系中的服务,我们将基于 Virtual Kubelet 的方式实现资源池的直接打通;另外一种 YARN 架构下的服务,如果直接基于 Kubernetes 体系对业务接入框架进行彻底的改造,这对于业务来说成本非常高,理论上会导致所有业务都滚动升级,这显然不是一个理想的状态。
为了解决这个问题,我们引用 Yodel 的胶水层,即业务接入仍然使用标准的 Yarn API,但在这个胶水层中,我们将与底层 K8s 语义对接,将用户对资源的请求抽象为像 Pod 或容器的描述。
这种方法使得我们在底层使用更成熟的 K8s 技术来管理资源,实现对离线的云原生化改造,同时又保证了业务的稳定性。
4.3 实践:资源运营治理
在混部过程中,我们需要对大数据和训练框架进行适配改造,做好各种重试、checkpoint 和分级,才能确保在我们将这些大数据和训练作业切到整个混部资源池之后,它们的使用体验不至于太差。
同时,在系统上我们需要具备完善的资源商品、业务分级、运营治理以及配额管理等方面的基础能力。如果运营做得不好,可能使得在某些高峰时段将利用率拉得很高,但在其他时段可能会出现较大的资源缺口,从而导致利用率无法达到预期。

4.4 实践:极限资源效率提升
在构建服务画像时,我们采用的是基于系统指标去做管控,但基于离线分析得到的静态系统指标无法实时跟上业务侧的变化,需要在一定时间周期内分析业务性能的变化来调整静态值。
为此,Katalyst 引入了模型来微调系统指标。例如,如果我们认为 CPU 调度延迟可能是 X 毫秒,过一段时间后,通过模型算出业务目标延迟可能是 Y 毫秒,我们就可以动态地调整该目标的值,以更好地评估业务性能。
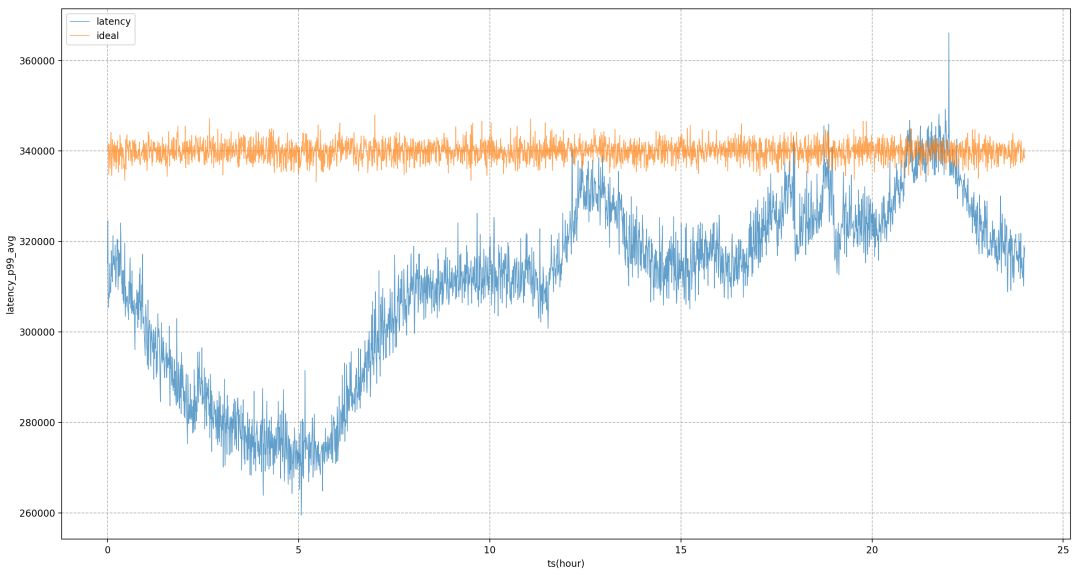
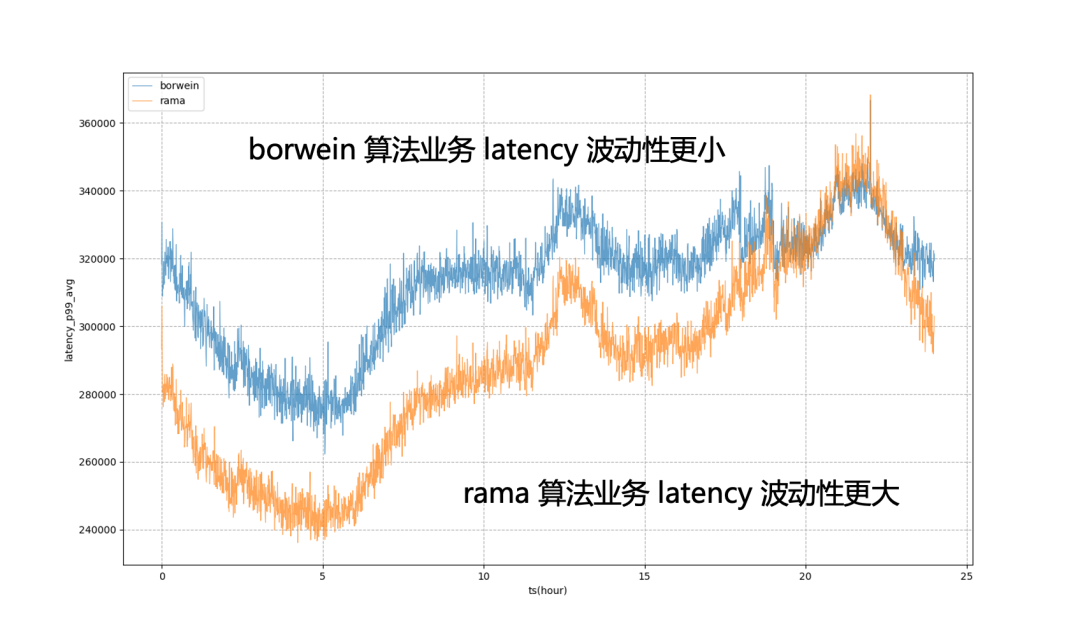
以下图为例,完全使用静态的系统目标来进行调控,业务 P99 将处于剧烈波动状态,这意味着在非晚高峰时段,我们无法将业务资源使用压榨到更极致的状态,使其更接近业务在晚高峰时可承受的量;引入模型后,可以看到业务延迟会更加平稳,使得我们可以全天将业务的性能拉平到一个相对平稳的水平,获得资源的收益。
4.5 实践:解决单机问题
在混部推进的过程中,我们会不断遇到在线和离线各种性能问题和微拓扑管理的诉求。例如,最初所有机器都是基于 cgroup V1 进行管控,然而由于 V1 的结构会使得系统需要遍历很深的目录树,消耗大量内核态 CPU。
为了解决该问题,我们在将整个集群中的节点切换到 cgroup V2 架构,使得我们能够更加高效地进行资源隔离和监控。对于推广搜等服务来说,为追求更加极致的性能,我们需要在 Socket/NUMA 级别实现更加复杂的亲和与反亲和策略等等,这些更加高阶的资源管理需求,在 Katalyst 中都可以更好地实现。

总结展望
目前,Katalyst 已正式开源并发布 0.3.0 版本,后续将会持续投入更多精力进行迭代。社区将在资源隔离、流量画像、调度策略、弹性策略、异构设备管理等多方面进行能力建设和系统增强,欢迎大家关注、参与该项目并提供反馈意见。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论