

本文最初发布于 Zalando 网站 Technology Blog 板块,经原作者授权由 InfoQ 中文站翻译并分享
最近,我在用Apache Flink构建小型的流处理应用。在 Zalando,我们默认使用 Kubernetes 进行部署,所以计划将 Flink 和开发的一些作业都部署到 Kubernetes 集群上。在这个过程中,我学到了很多关于 Flink 和 Kubernetes 的知识,在这篇文章里会和大家分享一下。
一些挑战
首先是合规性。在 Zalando,正产环境运行的代码必须经过至少 2 人的审核,并且所有部署的内容都可以追溯到 git commit。通常部署Flink任务会将包含有任务和依赖的 JAR 包上传到运行中的 Flink 集群,但这不符合我们内部的合规流程。
其二是容器编排的成熟度。Flink 一个重要的卖点是支持容错的流处理。但如下一节所述,在容器编排系统中没有设计可靠性相关的功能,这使得在 Kubernetes 上运行 Flink 集群并不是你想的那么简单。
其三是碎片化的文档。不论是 Flink 还是 Kubernetes 都在快速的发展中,这使一些文档很容易就过时了(就像我这篇 blog,或者是论坛/新闻组的帖子)。可惜的是,对于如何在 Kubernetes 上可靠地运行 Flink,现在官方文档能提供的信息还不够完善。
Flink 的架构和部署模式
为了理解如何在 Kubernetes 集群上部署 Flink,需要先对其架构和部署模式有个大致的了解。如果你已经很熟悉 Flink 了,可以跳过本节。
Flink 由作业管理器(Job Manager)和任务管理器(Task Manager)两个部分组成。作业管理器协调流处理作业,管理作业的提交及其生命周期,并将工作分配给任务管理器。任务管理器执行实际的流处理逻辑。同一时间只可能有一个活跃的作业管理器,但任务管理器可以有 n 个。
为了实现弹性的、有状态的、流式的处理,Flink 使用了检查点(Checkpointing)来周期性地记录各种流处理操作的状态,并进行持久化存储。从故障中恢复时,流处理作业可以从最新的检查点继续执行。检查点的操作由作业管理器进行协调,它知道最新完成的检查点的位置,这在后面会很重要。
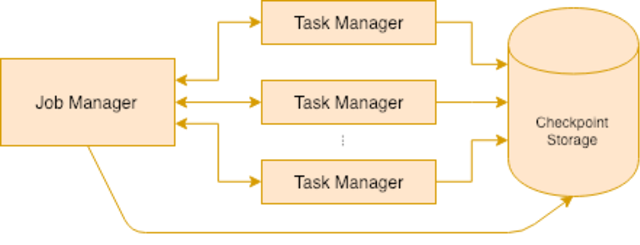
Flink 集群可以以两种独立的模式运行:第一种叫 Standalone 或者叫 Session Cluster,是一个可以运行多个流处理作业的单一集群。任务管理器在作业之间共享。第二种叫作业集群 Job Cluster,专门用于运行单个流处理作业。
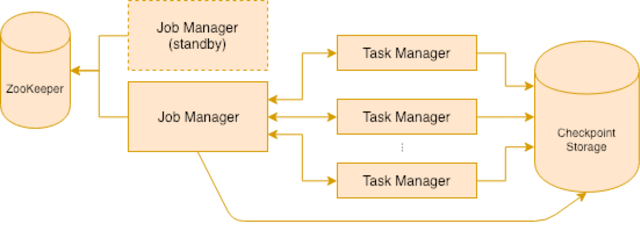
Flink 集群可以在HA模式下运行。在这个模式下,多个作业管理器的实例同时运行,其中的一个会被选举为 leader。如果 leader 失效了,会从其他运行的作业管理器中选出一个新的 leader。Flink 使用 Zookeeper 来进行 leader 选举。
部署 Kubernetes
在上文提到的两种模式中,我们选择了 Job Cluster 模式来运行 Flink。有两个原因:第一是因为 Job Cluster 的 Docker 镜像需要包含有 Flink 作业的 JAR 包。这能很好地解决合规性问题,因为我们可以重复使用与常规 JVM 应用相同的工作流程。第二个原因是这种部署模型能为每个 Flink 作业独立地扩展任务管理器。
我们将作业管理器作为一个部署(Deployment)并设置了 1 副本,任务管理器设置了 n 副本。任务管理器通过 Kubernetes 服务发现作业管理器。这个设置和官方文档不太相同,官方文档是建议将 Job Cluster 的作业管理器当做 Kubernetes 的作业来运行。但我们认为这种场景下(一个永不停止的流任务)使用部署的方式会更可靠,因为可以确保有一个 pod 一直在运行,而作业是可以完成的,使得集群可以没有任何作业管理器。这就是为什么我们的设置比较类似于文档中关于 session cluster 的描述。
作业管理器 pod 的失效由部署控制器(Deployment Controller)来处理,它会负责生成新的作业管理器。鉴于这是相对较快的操作,我们无需在热备份中维护多个作业管理器,不然会增加部署的复杂性。任务管理器使用 Kubernetes 服务来定位作业管理器。
如上文所述,作业管理器会在内存中保留一些和检查点相关的状态。在作业管理器崩溃时,这些状态会丢失,所以我们会在 Zookeeper 中持久化这些状态。这意味着即使没有选举 leader 的需求以及 Flink HA 模式的发现功能(就像 Kubernetes 本身处理的那样),仍然需要用到 Zookeeper 来存储检查点的状态。
我们在 Kubernetes 集群上已经部署了 etcd 集群和 etcd-operator,所以不想再引入另一个分布式调度系统了。我们试了一下 zetcd,这是一个基于 etcdv3 的 Zookeeper API。用着挺顺利,所以我们决定坚持下去。
在这种设置下我们会遇到另一个问题,作业管理器有时会陷入不健康的状态,而只有通过重启作业管理器才能解决。这个我们会通过 livenessProbe 来解决,它会检查作业管理器是否健康、作业是否仍然在运行。
还需要注意的是,这个设置仅适用于 Flink 大于 1.6.1 的版本,因为存在无法从 job cluster 的检查点恢复的 bug。
小结
上面的设置在生产环境中已经运行了好几个月,并能很好地服务于我们的用例。这也说明,即使在实现的过程中会遇到一些小障碍,在 Kubernetes 上平稳地运行 Flink 还是可行的。
原文链接:https://jobs.zalando.com/tech/blog/running-apache-flink-on-kubernetes/index.html

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论