
备注: 本篇文章是关于先前相同主题文章的最新版本。先前文章主要介绍创建高性能解析器的一些要点,但它吸收了读者的一部分批评建议。原来的文章进行了全面修订,并补充了相对完整的代码。我们希望你喜欢本次更新。
如果你没有指定数据或语言标准的或开源的 Java 解析器, 可能经常要用 Java 实现你自己的数据或语言解析器。或者,可能有很多解析器可选,但是要么太慢,要么太耗内存,或者没有你需要的特定功能。或者开源解析器存在缺陷,或者开源解析器项目被取消诸如此类原因。上述原因都没有你将需要实现你自己的解析器的事实重要。
当你必需实现自己的解析器时,你会希望它有良好表现,灵活,功能丰富,易于使用,最后但更重要是易于实现,毕竟你的名字会出现在代码中。本文中,我将介绍一种用 Java 实现高性能解析器的方式。该方法不具排他性,它是简约的,并实现了高性能和合理的模块化设计。该设计灵感来源于 VTD-XML ,我所见到的最快的 java XML 解析器,比 StAX 和 SAX Java 标准 XML 解析器更快。
两个基本解析器类型
解析器有多种分类方式。在这里,我只比较两个基本解析器类型的区别:
- 顺序访问解析器(Sequential access parser)
- 随机访问解析器(Random access parser)
顺序访问意思是解析器解析数据,解析完毕后将解析数据移交给数据处理器。数据处理器只访问当前已解析过的数据;它不能回头处理先前的数据和处理前面的数据。顺序访问解析器已经很常见,甚至作为基准解析器,SAX 和 StAX 解析器就是最知名的例子。
随机访问解析器是可以在已解析的数据上或让数据处理代码向前和向后(随机访问)。随机访问解析器例子见 XML DOM 解析器。
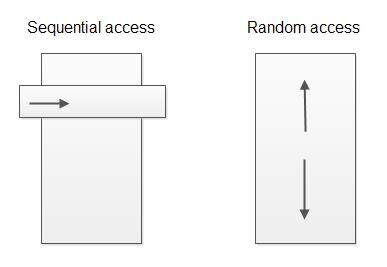
顺序访问解析器只能让你在文档流中访问刚解析过的“窗口”或“事件”,而随机访问解析器允许你按照想要的方式访问遍历。
设计概要
我这里介绍的解析器设计属于随机访问变种。
随机访问解析器实现总是比顺序访问解析器慢一些,这是因为它们一般建立在某种已解析数据对象树上,数据处理器能访问上述数据。创建对象树实际上在 CPU 时钟上是慢的,并且耗费大量内存。
代替在解析数据上构建对象树,更高性能的方式是建立指向原始数据缓存的索引缓存。索引指向已解析数据的元素起始点和终点。代替通过对象树访问数据,数据处理代码直接在含有原始数据的缓存中访问已解析数据。如下是两种方法的示意图:
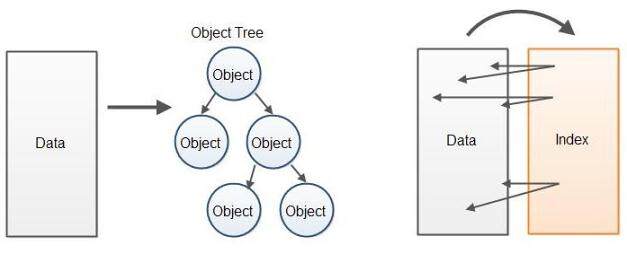
因为没找到更好的名字,我就叫该解析器为“索引叠加解析器”。该解析器在原始数据上新建了一个索引叠加层。这个让人想起数据库构建存储在硬盘上的数据索引的方式。它在原始未处理的数据上创建了指针,让浏览和搜索数据更快。
如前所说,该设计受 VTD-XML 的启发, VTD 是虚拟令牌描述符 (Virtual Token Descriptor) 的英文缩写。因此,你可以叫它虚拟令牌描述符解析器。不过,我更喜欢索引叠加的命名,因为这是虚拟令牌描述符代表,在原始数据上的索引。
常规解析器设计
一般解析器设计会将解析过程分为两步。第一步将数据分解为内聚的令牌,令牌是一个或多个已解析数据的字节或字符。第二步解释这些令牌并基于这些令牌构建更大的元素。两步示意图如下:
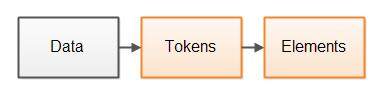
图中元素并不是指 XML 元素(尽管 XML 元素也解析元素),而更大“数据元素”构造了已解析数据。在我 XML 文档中表示 XML 元素,而在 JSON 文档中则表示 JSON 对象,诸如此类。
举例说明,字符串将被分解为如下令牌:
< myelement >
一旦数据分解为多个令牌,解析器更容易理解它们和判断这些令牌构造的大元素。解析器将会识别 XML 元素以 ‘<’令牌开头后面是字符串令牌(元素名称),然后是一系列可选的属性,最后是‘>’令牌。
索引叠加解析器设计
两步方法也将用于我们的解析器设计。输入数据首先由分析器组件分解为多个令牌。 然后解析器解析这些令牌识别输入数据的大元素边界。
你也可以增加可选的第三步骤—“元素导航步骤”到解析过程中。 若解析器从已解析数据中构造对象树,那么对象树一般会包含对象树导航的链接。当我们构建元素索引缓存代替对象树时,我们需要一个独立组件帮助数据处理代码导航元素索引缓存。
我们解析器设计概览参见如下示意图:
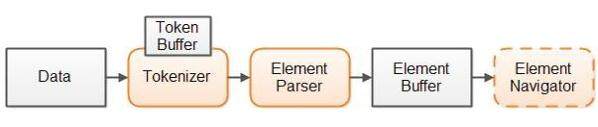
我们首先将所有数据读到数据缓存内。为了保证可以通过解析中创建的索引随机访问原始数据,所有原始数据必需放到内存中。
接着,分析器将数据分解为多个令牌。开始索引,结束索引和令牌类型都会保存于分析器中一个内部令牌缓存。使用令牌缓存使其向前和向后访问成为可能,上述情况下解析器需要令牌缓存。
第三步,解析器查找从分析器获取的令牌,在上下文中校验它们,并判断它们表示的元素。然后,解析器基于分析器获取的令牌构造元素索引(索引叠加)。解析器逐一获得来自分析器的令牌。因此,分析器实际上不需要马上将所有数据分解成令牌。而仅仅是在特定时间点找到一个令牌。
数据处理代码能访问元素缓存,并用它访问原始数据。或者,你可能会将数据缓存封装到元素访问组件中,让访问元素缓存更容易。
该设计基于已解析数据构建对象树,但它需建立访问结构—元素缓存,由索引(整型数组)指向含有原始数据的数据缓存。我们能使用这些索引访问存于原始数据缓存的数据。
下面小节将从设计的不同方面更详细地进行介绍。
数据缓存
数据缓存是含有原始数据的一种字节或字符缓存。令牌缓存和元素缓存持有数据缓存的索引。
为了随机访问解析过了的数据,内存表示上述信息的机制是必要的。我们不使用对象树而是用包含原始数据的数据缓存。
将所有数据放在内存中需消耗大块的内存。若数据含有的元素是相互独立的,如日志记录,将整个日志文件放在内存中将是矫枉过正了。相反,你可以拉大块的日志文件,该文件存有完整的日志记录。因为每个日志记录可完全解析,并且独立于其它日志记录的处理,所以我们不需要在同一时间将整个日志文件放到内存中。在我的文章—“使用缓存迭代访问数据流”中,我已经描述了如何遍历块中的数据流。
标记分析器和标记缓存
分析器将数据缓分解为多个令牌。令牌信息存储在令牌缓存中,包含如下内容:
- 令牌定位(起始索引)
- 令牌长度
- 令牌类型 (可选)
上述信息放在数组中。如下实例说明处理逻辑:
public class IndexBuffer { public int[] position = null; public int[] length = null; public byte[] type = null; /* assuming a max of 256 types (1 byte / type) */ }
当分析器找到数据缓存中令牌时,它将构建位置数组的起始索引位置,长度数组的令牌长度和类型数组的令牌类型。
若不使用可选的令牌类型数组,你仍能通过查看令牌数据来区分令牌类型。这是性能和内存消耗的权衡。
解析器
解析器是在性质上与分析器类似,只不过它采用令牌作为输入和输出的元素索引。如同使用令牌,一个元素由它的位置(起始索引),长度,以及可选的元素类型来决定。这些数字存储在与存储令牌相同的结构中。
再者,类型数组是可选的。若你很容易基于元素的第一个字节或字符确定元素类型,你不必存储元素类型。
元素缓存中标记的要素精确粒度取决于数据被解析,以及需要后面数据处理的代码。例如,如果你实现一个 XML 解析器,你可能会标记为每个“解析器元素”的开始标签, 属性和结束标签。
元素缓存(索引)
解析器生成带有指向元数据的索引的元素缓存。该索引标记解析器从数据中获取的元素的位置 (起始索引),长度和类型。你可以使用这些索引来访问原始数据。
看一看上文的 IndexBuffer 代码,你就知道元素缓存每个元素使用 9 字节;四个字节标记位置,四个自己是令牌长度,一个字节是令牌类型。
你可以减少 IndexBuffer 的内存消耗。例如,如果你知道元素从不会超过 65,536 字节,那么你可以用短整型数组代替整型来存令牌长度。这将每个元素节省两个字节,使内存消耗降低为每个元素 7 个字节。
此外,如果知道将解析这些文件长度从不会超过 16,777,216 字节,你只需要三个字节标识位置(起始索引)。在位置数组中,每一整型第四字节可以保存元素类型,省去了一个类型数组。如果您有少于 128 的令牌类型,您可以使用 7 位的令牌类型而不是八个。这使您可以花 25 位在位置上,这增加了位置范围最大到 33,554,432。如果您令牌类型少于 64,您可以安排另一个位给位置,诸如此类。
VTD-XML 实际上会将所有这些信息压缩成一个 Long 型,以节省空间。处理速度会有损失,因为额外的位操作收拾单独字段到单个整型或 long 型中,不过你可以节省一些内存。总而言之,这是一个权衡。
元素导航组件
元素导航组件帮助正在处理数据的代码访问元素缓存。务必记住,一个语义对象或元素(如 XML 元素)可能包括多个解析器元素。为了方便访问,您可以创建一个元素导航器对象,可以在语义对象级别访问解析器元素。例如,一个 XML 元素导航器组件可以通过在起始标记和到起始标记来访问元素缓存。
使用元素导航组件是你的自由。如果要实现一个解析器在单个项目中的使用,你可以要跳过它。但是,如果你正在跨项目中重用它,或作为开源项目发布它,你可能需要添加一个元素导航组件,这取决于如何访问已解析数据的复杂度。
案例学习:一个 JSON 解析器
为了让索引叠加解析器设计更清晰,我基于索引叠加解析器设计用 Java 实现了一个小的 JSON 解析器。你可以在 GitHub 上找到完整的代码。
JSON 是 JavaScript Object Notation 的简写。JSON 是一种流行的数据格式,基于 AJAX 来交换 Web 服务器和浏览器之间的数据,Web 浏览器已经内置了 JSON 解析为 JavaScript 对象的原生支持。后文,我将假定您熟悉 JSON。
如下是一个 JSON 简单示例:
{ "key1" : "value1" , "key2" : "value2" , [ "valueA" , "valueB" , "valueC" ] }
JSON 分析器将 JSON 字符串分解为如下令牌:
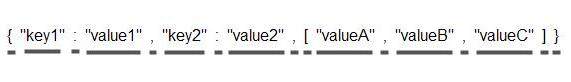
这里下划线用于强调每个令牌的长度。
分析器也能判断每个令牌的基本类型。如下是同一个 JSON 示例,只是增加了令牌类型:

注意令牌类型不是语义化的。它们只是说明基本令牌类型,而不是它们代表什么。
解析器解释基本令牌类型,并使用语义化类型来替换它们。如下示例是同一个 JSON 示例,只是由语义化类型(解析器元素)代替:
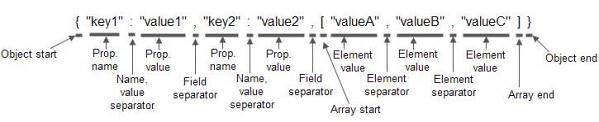
一旦解析器完成了上述 JSON 解析,你将有一个索引,包含上面打标记元素的位置,长度和元素类型。你可以访问索引从 JSON 抽取你需要的数据。
在 GitHub 库中的实现包含两个 JSON 解析器。其中一个分割解析过程为 JsonTokenizer 和 JsonParser(如本文前面所述),以及一个为 JsonParser2 结合分析和解析过程为一个阶段,一个类。JsonParser2 速度更快,但更难理解。因此,我会在下面的章节快速介绍一下在 JsonTokenizer 和 JsonParser 类,但会跳过 JsonParser2。
(本文第一个版本有读者指出,从该指数叠加分析器的输出是不是难于从原始数据缓冲区中提取数据。正如前面提到的,这就是添加一个元素导航组件的原因。为了说明这样的元素导航组件的原理,我已经添加了 JsonNavigator 类。稍后,我们也将快速浏览一下这个类。)
JsonTokenizer.parseToken() 方法
为了介绍分析和解析过程实现原理,我们看一下 JsonTokenizer 和 JsonParser 类的核心代码部分。提醒,完整代码可以在 GitHub 访问 。
如下是 JsonTokenizer.parseToken() 方法,解析数据缓存的下一个索引:
public void parseToken() { skipWhiteSpace(); this.tokenBuffer.position[this.tokenIndex] = this.dataPosition; switch (this.dataBuffer.data[this.dataPosition]) { case '{': { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_CURLY_BRACKET_LEFT; } break; case '}': { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_CURLY_BRACKET_RIGHT; } break; case '[': { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_SQUARE_BRACKET_LEFT; } break; case ']': { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_SQUARE_BRACKET_RIGHT; } break; case ',': { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_COMMA; } break; case ':': { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_COLON; } break; case '"': { parseStringToken(); } break; case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': { parseNumberToken(); this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_NUMBER_TOKEN; } break; case 'f': { if (parseFalse()) { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_BOOLEAN_TOKEN; } } break; case 't': { if (parseTrue()) { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_BOOLEAN_TOKEN; } } break; case 'n': { if (parseNull()) { this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_NULL_TOKEN; } } break; } this.tokenBuffer.length[this.tokenIndex] = this.tokenLength; }
如你所见,代码相当简洁。首先,skipWhiteSpace() 调用跳过存在于当前位置的数据中的空格。接着,当前令牌(数据缓存的索引)的位置存于 tokenBuffer 。第三,检查下一个字符,并根据字符是什么(它是什么样令牌)来执行 switch-case 结构。最后,保存当前令牌的令牌长度。
这的确是分析一个数据缓冲区的完整过程。请注意,一旦一个字符串索引开始被发现,该分析器调用 parseStringToken()方法,通过扫描的数据,直到字符串令牌结尾。这比试图处理 parseToken() 方法内所有逻辑执行更快,也更容易实现。
JsonTokenizer 内方法的其余部分只是辅助 parseToken() 方法,或者移动数据位置(索引)到下一个令牌(当前令牌的第一个位置),诸如此类。
JsonParser.parseObject() 方法
JsonParser 类主要的方法是 parseObject()方法,它主要处理从 JsonTokenizer 得到令牌的类型,并试图根据上述类型的输入数据找到 JSON 对象中。
如下是 parseObject() 方法:
private void parseObject(JsonTokenizer tokenizer) { assertHasMoreTokens(tokenizer); tokenizer.parseToken(); assertThisTokenType(tokenizer.tokenType(), TokenTypes.JSON_CURLY_BRACKET_LEFT); setElementData(tokenizer, ElementTypes.JSON_OBJECT_START); tokenizer.nextToken(); tokenizer.parseToken(); byte tokenType = tokenizer.tokenType(); while (tokenType != TokenTypes.JSON_CURLY_BRACKET_RIGHT) { assertThisTokenType(tokenType, TokenTypes.JSON_STRING_TOKEN); setElementData(tokenizer, ElementTypes.JSON_PROPERTY_NAME); tokenizer.nextToken(); tokenizer.parseToken(); tokenType = tokenizer.tokenType(); assertThisTokenType(tokenType, TokenTypes.JSON_COLON); tokenizer.nextToken(); tokenizer.parseToken(); tokenType = tokenizer.tokenType(); switch (tokenType) { case TokenTypes.JSON_STRING_TOKEN: { setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_STRING); } break; case TokenTypes.JSON_STRING_ENC_TOKEN: { setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_STRING_ENC); } break; case TokenTypes.JSON_NUMBER_TOKEN: { setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_NUMBER); } break; case TokenTypes.JSON_BOOLEAN_TOKEN: { setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_BOOLEAN); } break; case TokenTypes.JSON_NULL_TOKEN: { setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_NULL); } break; case TokenTypes.JSON_CURLY_BRACKET_LEFT: { parseObject(tokenizer); } break; case TokenTypes.JSON_SQUARE_BRACKET_LEFT: { parseArray(tokenizer); } break; } tokenizer.nextToken(); tokenizer.parseToken(); tokenType = tokenizer.tokenType(); if (tokenType == TokenTypes.JSON_COMMA) { tokenizer.nextToken(); //skip , tokens if found here. tokenizer.parseToken(); tokenType = tokenizer.tokenType(); } } setElementData(tokenizer, ElementTypes.JSON_OBJECT_END); } }
parseObject()方法希望看到一个左花括号({),后跟一个字符串标记,一个冒号和另一个字符串令牌或数组的开头([])或另一个 JSON 对象。当 JsonParser 从 JsonTokenizer 获取这些令牌时,它存储开始,长度和这些令牌在自己 elementBuffer 中的语义。然后,数据处理代码可以浏览这个 elementBuffer 后,从输入数据中提取任何需要的数据。
看过 JsonTokenizer 和 JsonParser 类的核心部分后能让我们理解分析和解析的工作方式。为了充分理解代码是如何运作的,你可以看看完整的 JsonTokenizer 和 JsonParser 实现。他们每个都不到 200 行,所以它们应该是易于理解的。
JsonNavigator 组件
JsonNavigator 是一个元素访问组件。它可以帮助我们访问 JsonParser 和 JsonParser2 创建的元素索引。两个组件产生的索引是相同的,所以来自两个组件的任何一个索引都可以。如下是代码示例:
JsonNavigator jsonNavigator = new JsonNavigator(dataBuffer, elementBuffer);
一旦 JsonNavigator 创建,您可以使用它的导航方法,next(),previous() 等等。你可以使用 asString(),asInt() 和 asLong() 来提取数据。你可以使用 isEqualUnencoded(String) 来比较在数据缓冲器中元素的常量字符串。
使用 JsonNavigator 类看起来非常类似于使用 GSON 流化 API。可以比较一下 AllBenchmarks 类的 gsonStreamBuildObject(Reader)方法,和 JsonObjectBuilder 类 parseJsonObject(JsonNavigator)方法。
他们看起来很相似,不是么? 只是,parseJsonObject() 方法能够使用 JsonNavigator 的一些优化(在本文后面讨论),像数组中基本元素计数,以及对 JSON 字段名称更快的字符串比较。
基准化分析
VTD-XML 对 StAX,SAX 和 DOM 解析器等 XML 解析器做了的广泛的基准化比较测试。在核心性能上,VTD-XML 赢得了他们。
为了对索引叠加解析器的性能建立一些信任依据,我已经参考 GSON 实现了我的 JSON 解析器。本文的第一个版本只测算了解析一个 JSON 文件的速度与通过 GSON 反射构造对象。基于读者的意见,我现在已经扩大了基准,基于四种不同的模式来测算 GSON:
1、访问 JSON 文件所有元素,但不做任何数据处理。
2、访问 JSON 文件所有元素,并建立一个 JSONObject。
3、解析 JSON 文件,并构建了一个 Map 对象。
4、解析 JSON 文件,并使用反射它建立一个 JSONObject。
请记住,GSON 是一个高质量的产品,经过了很好的测试,也具有良好的错误报告等。只有我的 JSON 解析器是在概念验证级别。基准测试只是用来获得性能上的差异指标。他们不是最终的数据。也请阅读下文的基准讨论。
如下是一些基准结构化组织的细节:
· 为了平衡 JIT,尽量减小一次性开销,诸如此类。JSON 输入完成 1000 万次的小文件解析,100 万次中等文件和大文件。
· 基准化测试分别重复三个不同类型的文件, 看看解析器如何做小的,中等和大文件。上述文件类型大小分别为 58 字节,783 字节和 1854 字节。这意味着先迭代 1000 万次的一个小文件,进行测算。然后是中等文件,最后在大文件。上述文件存于 GitHub 库的数据目录中。
· 在解析和测算前,文件完全装载进内存中。这样解析耗时不包含装载时间。
· 1000 万次迭代(或 100 万次迭代)测算都是在自己的进程中进行。这意味着,每个文件在单独的进程进行解析。一个过程运行一次。每个文件都测算 3 次。解析文件 1000 万次的过程启动和停止 3 次。流程是顺序进行的,而不是并行。
如下是毫秒级的执行时间数据:
基准
小 1
小 2
小 3
中 1
中 2
中 3
大 1
大 2
大 3
JsonParser2
8.143
7.862
8.236
11.092
10.967
11.169
28.517
28.049
28.111
JsonParser2 + Builder
13.431
13.416
13.416
17.799
18.377
18.439
41.636
41.839
43.025
JsonParser
13.634
13.759
14.102
19.703
19.032
20.438
43.742
41.762
42.541
JsonParser + Builder
19.890
19.173
19.609
29.531
26.582
28.003
56.847
60.731
58.235
Gson Stream
44.788
45.006
44.679
33.727
34.008
33.821
69.545
69.111
68.578
Gson Stream + Builder
45.490
45.334
45.302
36.972
38.001
37.253
74.865
76.565
77.517
Gson Map
66.004
65.676
64.788
42.900
42.778
42.214
83.932
84.911
86.156
Gson Reflection
76.300
76.473
77.174
69.825
67.750
68.734
135.177
137.483
134.337
如下是比较基准所处理事情的说明:
描述
JsonParser2
使用 JsonParser2 解析文件和定位索引。
JsonParser2 + Builder
使用 JsonParser2 解析文件和在解析文件上构建 JsonObject。
JsonParser
使用 JsonParser 解析文件和定位索引。
JsonParser + Builder
使用 JsonParser 解析文件和在解析文件上构建 JsonObject。
Gson Stream
使用 Gson streaming API 解析文件和迭代访问所有令牌。
Gson Stream + Builder
解析文件和构建 JsonObject。
Gson Map
解析文件和构建 Map。
Gson Reflection
使用反射解析文件和构建 JsonObject。
如你所见,索引叠加实现(JsonParser 和 JsonParser2)比 Gson 更快。下面我们将讨论一下产生上述结果的原因的推测。
性能分析
GSON Streaming API 并非更快的主要原因是当遍历时所有数据都从流中抽取,即使不需要这些数据。每一个令牌变成一个 string,int,double 等,存在消耗。这也是为什么用 Gson streaming API 解析 JSON 文件和构建 JsonOject 和访问元素本身是一样快。 唯一增加的显式时间是 JsonObject 内部的 JsonObject 和数组的实例化。
数据获取不能解释这一切,尽管,使用 JsonParser2 构建一个 JSONObject 比使用 Gson streaming API 构建 JSONObject 几乎快两倍。如下说明了一些我看到的索引叠加解析器比流式解析器的性能优势:
首先,如果你看一下小的和大的文件的测试数据,每一次解析式 GSON 都存在一次性开销。 JsonParser2+ JsonParser 和 GSON 基准测试间的性能差异在小的文件上更明显。可能原因是 theCharArrayReader 创建,或类似的事情。也可能是 GSON 内部的某项处理。
第二,索引叠加解析器可以允许你控制你想抽取的数据量。这个让你更细粒度的控制解析器的性能。
第三, 若一个字符串令牌含有需要手动从 UTF-8 转换为 UTF-16 的转义字符(如“\”\ t\ N \ R“),JsonParser 和 JsonParser2 在分析时能够识别。如果一个字符串令牌不包含转义字符,JsonNavigator 可以用一个比它们更快的字符串创建机制。
第四,JsonNavigator 能够让数据缓冲区中的数据的字符串比较更快。 当你需要检查字段名是否等于常量名时,非常方便。使用 Gson’s streaming API,你将需将字段名抽取为一个 String 对象,并比较常量字符串和 String 对象。JsonNavigator 可以直接比较常量字符串和数据缓冲区中的字符,而无需先创建一个 String 对象。这可以节省一个 String 对象的实例化,并从数据缓冲区中的数据复制到一个 String 对象的时间,它是仅用于比较(如检查 JSON 字段名称是否等于“key”或“name”或其它)。JsonNavigator 使用方式如下所示:
if(jsonNavigator.isEqualUnencoded("fieldName")) { }
第五,JsonNavigator 可以在其索引向前遍历,计数包含原始值(字符串,数字,布尔值,空值等,但不包含对象或嵌套数组)数组中的元素数量。当你不知道数组包含有多少个元素,我们通常抽取元素并把它们放到一个 List 中。一旦你遇到数组结束的标记,将 List 转成数组。这意味着构建了非必要的 List 对象。此外,即使该数组包含原始值,如整数或布尔值,所有抽取的数据也必须要插入到 List 对象。抽取数值插入 List 时进行了不必要的对象创建(至少是不必要的自动装箱)。再次,创建基础值数组时,所有的对象都必须再次转换成原始类型,然后插入到数组中。如下所示是 Gson streaming API 工作代码:
List<Integer> elements = new ArrayList<Integer>(); reader.beginArray(); while (reader.hasNext()) { elements.add(reader.nextInt()); } reader.endArray(); int[] ints = new int[elements.size()]; for (int i = 0; i < ints.length; i++) { ints[i] = elements.get(i); }
当知道数组包含的元素数时,我们可以立即创建最终的 Java 数组,然后将原始值直接放入数组。在插入数值到数组时,这节省了 List 实例化和构建,原始值自动装箱和对象转换到原始值的时间。如下所示是使用 JsonNavigator 功能相同的代码:
int[] ints = new int[jsonNavigator.countPrimitiveArrayElements()]; for (int i = 0, n = ints.length; i < n; i++) { ints[i] = jsonNavigator.asInt(); jsonNavigator.next(); }
即使刚刚从 JSON 数组构建 List 对象,知道元素的个数可以让你从一开始就能正确的实例化一个 ArrayList 对象。这样,你就避免了在达到预设阈值时需动态调整 ArrayList 大小的麻烦。如下是示例代码:
List<String> strings = new ArrayList<String>(jsonNavigator.countPrimitiveArrayElements()); jsonNavigator.next(); // skip over array start. while (ElementTypes.JSON_ARRAY_END != jsonNavigator.type()) { strings.add(jsonNavigator.asString()); jsonNavigator.next(); } jsonNavigator.next(); //skip over array end.
第六,当需访问原始数据缓冲区时,可以在很多地方用 ropes 代替 String 对象。一个rope是一个含有 char 数组引用的一个字符串令牌,有起始位置和长度。可以进行字符串比较,就像一个字符串复制rope等。某些操作可能用rope要比字符串对象快。因为不复制原始数据,它们还占用更少的内存。
第七,如果需要做很多来回的数据访问,您可以创建更高级的索引。 VTD-XML 中的索引包含元素的缩进层次,以及同一层的下一个元素(下一个同级)的引用,带有更高缩进层的第一个元素(初始元素),等等。这些都是增加到线性解析器元素索引顶部的整型索引。这种额外的索引可以让已解析数据的遍历速度更快。
性能和错误报告
若看看 JsonParser 和 JsonParser2 代码,你将看到更快的 JsonParser2 比 JsonParser 更糟糕的错误报告。当分析和解析阶段一分为二时,良好的数据验证和错误报告更易于实现。
通常情况下,这种差异将触发争论,在解析器的实现进行取舍时,优先考虑性能还是错误报告。然而,在索引叠加解析器中,这一讨论是没有必要的。
因为原始数据始终以其完整的形式存在于内存中,你可以同时具有快和慢的解析器解析相同的数据。您可以快速启动快的解析器,若解析失败,您可以使用较慢的解析器来检测其中输入数据中的错误位置。当快的解析器失败时,只要将原始数据交给较慢的解析器。基于这种方式,你可以获得两个解析的优点。
基准分析
基于数据(GSON)创建的对象树与仅标识在数据中找到的数据索引进行比较,而没有讨论比较的标的,这是不公平的比较。
在应用程序内部解析文件通常需要如下步骤:

首先是数据从硬盘或者网络上装载。接着,解码数据,例如从 UTF-8 到 UTF-16。第三步,解析数据。第四步,处理数据。
为了只测量原始的解析器速度, 我预装载待解析的文件到内存。 该基准测试的代码没有以任何方式处理数据。尽管该基准化测试只是测试基础的解析速度,在运行的应用程序中,性能差异并没有转化成性能显著提高。如下是原因:
流式解析器总是能在所有数据装载进内存前开始解析数据。我的 JSON 解析器现在实现版本不能这样做。这意味着即使它在基础解析基准上更快,在现实运行的应用程序中,我的解析器必须等待数据装载,这将减慢整体的处理速度。如下图说明:

为了加速整体解析速度,你很可能修改我的解析器为数据装载时即可以解析数据。但是很可能会减慢基本解析性能。但整体速度仍可能更快。
此外,通过在执行的基准测试之前数据预加载到内存中,我也跳过数据解码步骤。数据从 UTF-8 转码为 UTF-16 是也存在消耗。在现实应用程序中,你不可以跳过这一步。每个待解析的文件来必须要解码。这是所有解析器都要支持的一点。流式解析器可以在读数据时进行解码。索引叠加分析器也可以在读取数据到缓冲区时进行解码。
VTD-XML 和 Jackson (另一个 JSON 解析器) 使用另一种技术。它们不会解码所有的原始数据。相反,它们直接在原始数据上进行分析,消费各种数据格式,如(ASCII,UTF-8 等)。这可以节省昂贵的解码步骤,解码要使用相当复杂分析器。
一般来说,要想知道那个解析器在你的应用程序更快,需要基于你真实需要解析的数据的基准上进行全量测试。
索引叠加解析器一般讨论
我听到的一个反对索引叠加分析器的论点是,要能够指向原始数据,而不是将其抽取到一个对象树,解析时保持所有数据在内存中是必要的。在处理大文件时,这将导致内存消耗暴增。
一般来说,流式分析器(如 SAX 或 StAX)在解析大文件时将整个文件存入内存。然而,只有文件中的数据可以以更小的块进行解析和处理,每个块都是独立进行处理的,这种说法才是对的。例如,一个大的 XML 文件包含一列元素,其中每一个元素都可以单独被解析和处理(如日志记录列表)。如果数据能以独立的块进行解析,你可以实现一个工作良好的索引叠加解析器。
如果文件不能以独立块进行解析,你仍然需要提取必要的信息到一些结构,这些结构可以为处理后面块的代码进行访问。尽管使用流式解析器可以做到这一点,你也可以使用索引叠加解析器进行处理。
从输入数据中创建对象树的解析器通常会消耗比原数据大小的对象树更多的内存。对象实例相关联的内存开销,加上需要保持对象之间的引用的额外数据,这是主要原因。
此外,因为所有的数据都需要同时在内存中,你需要解析前分配一个数据缓冲区,大到足以容纳所有的数据。但是,当你开始解析它们时,你并不知道文件大小,如何办呢?
假如你有一个网页应用程序(如 Web 服务,或者服务端应用),用户使用它上传文件。你不可能知道文件大小,所以开始解析前无法分配合适的缓存给它。基于安全考虑,你应该总是设置一个最大允许文件大小。否则,用户可以通过上传超大文件让你的应用崩溃。或者,他们可能甚至写一个程序,伪装成上传文件的浏览器,并让该程序不停地向服务器发送数据。您可以分配一个缓冲区适合所允许的最大文件大小。这样,你的缓冲区不会因有效文件耗光。如果它耗光了空间,那说明你的用户已经上传了过大的文件。
关于作者
 Jakob Jenkov**** 是一个企业家,作家和软件开发者,生活在西班牙的巴塞罗那。Jakob 在 1997 年学习了 Java,从 1999 年工作以来就一直使用 Java。他目前专注于跨领域(软件,流程,企业等)的效率改善。他拥有哥本哈根信息技术大学的信息技术专业硕士学位。你可以在他的个人网站上获取更多关于他工作的信息。
Jakob Jenkov**** 是一个企业家,作家和软件开发者,生活在西班牙的巴塞罗那。Jakob 在 1997 年学习了 Java,从 1999 年工作以来就一直使用 Java。他目前专注于跨领域(软件,流程,企业等)的效率改善。他拥有哥本哈根信息技术大学的信息技术专业硕士学位。你可以在他的个人网站上获取更多关于他工作的信息。
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论