

2. 阿里 DUPN
Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks
多任务学习的优势:可共享一部分网络结构,比如多个任务共享一份 embedding 参数。学习的用户、商品向量表示可方便迁移到其它任务中。本文提出了一种多任务模型 DUPN:
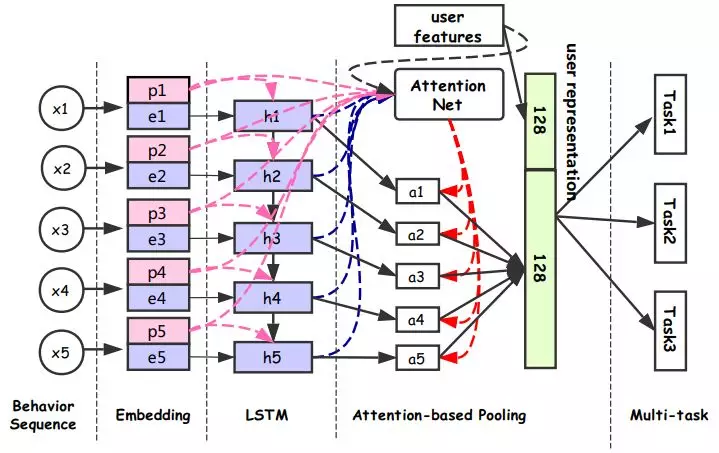
模型分为行为序列层、Embedding 层、LSTM 层、Attention 层、下游多任务层。
❶ 行为序列层:输入用户的行为序列 x = {x1,x2,…,xN},其中每个行为都有两部分组成,分别是 item 和 property 项。Item 包括商品 id 和一些 side-information 比如店铺 id、brand 等 ( 好多场景下都要带 side-information,这样更容易学习出商品的 embedding 表示 )。Property 项表示此次行为的属性,比如场景 ( 搜索、推荐等场景 ) 时间、类型 ( 点击、购买、加购等 )。
❷ Embedding 层:主要多 item 和 property 的特征做处理。
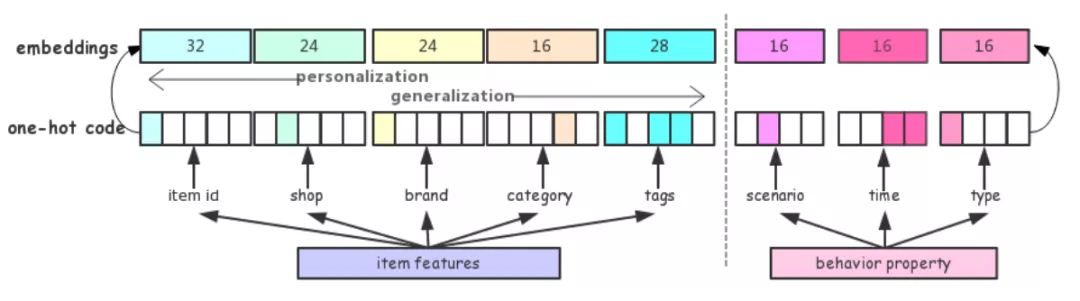
❸ LSTM 层:得到每一个行为的 Embedding 表示之后,首先通过一个 LSTM 层,把序列信息考虑进来。
❹ Attention 层:区分不同用户行为的重要程度,经过 attention 层得到 128 维向量,拼接上 128 维的用户向量,最终得到一个 256 维向量作为用户的表达。
❺ 下游多任务层:CTR、L2R ( Learning to Rank )、用户达人偏好 FIFP、用户购买力度量 PPP 等。
另外,文中也提到了两点多任务模型的使用技巧:
❶ 天级更新模型:随着时间和用户兴趣的变化,ID 特征的 Embedding 需要不断更新,但每次都全量训练模型的话,需要耗费很长的时间。通常的做法是每天使用前一天的数据做增量学习,这样一方面能使训练时间大幅下降;另一方面可以让模型更贴近近期数据。
❷ 模型拆分:由于 CTR 任务是 point-wise 的,如果有 1w 个物品的话,需要计算 1w 次结果,如果每次都调用整个模型的话,其耗费是十分巨大的。其实 user Reprentation 只需要计算一次就好。因此我们会将模型进行一个拆解,使得红色部分只计算一次,而蓝色部分可以反复调用红色部分的结果进行多次计算。
美团 “猜你喜欢” 深度学习排序模型
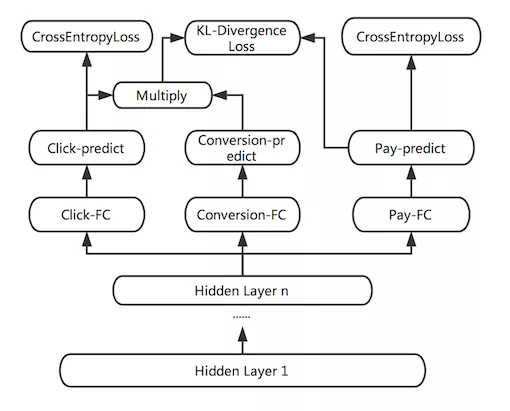
根据业务目标,将点击率和下单率拆分出来,形成两个独立的训练目标,分别建立各自的 Loss Function,作为对模型训练的监督和指导。DNN 网络的前几层作为共享层,点击任务和下单任务共享其表达,并在 BP 阶段根据两个任务算出的梯度共同进行参数更新。网络在最后一个全连接层进行拆分,单独学习对应 Loss 的参数,从而更好地专注于拟合各自 Label 的分布。
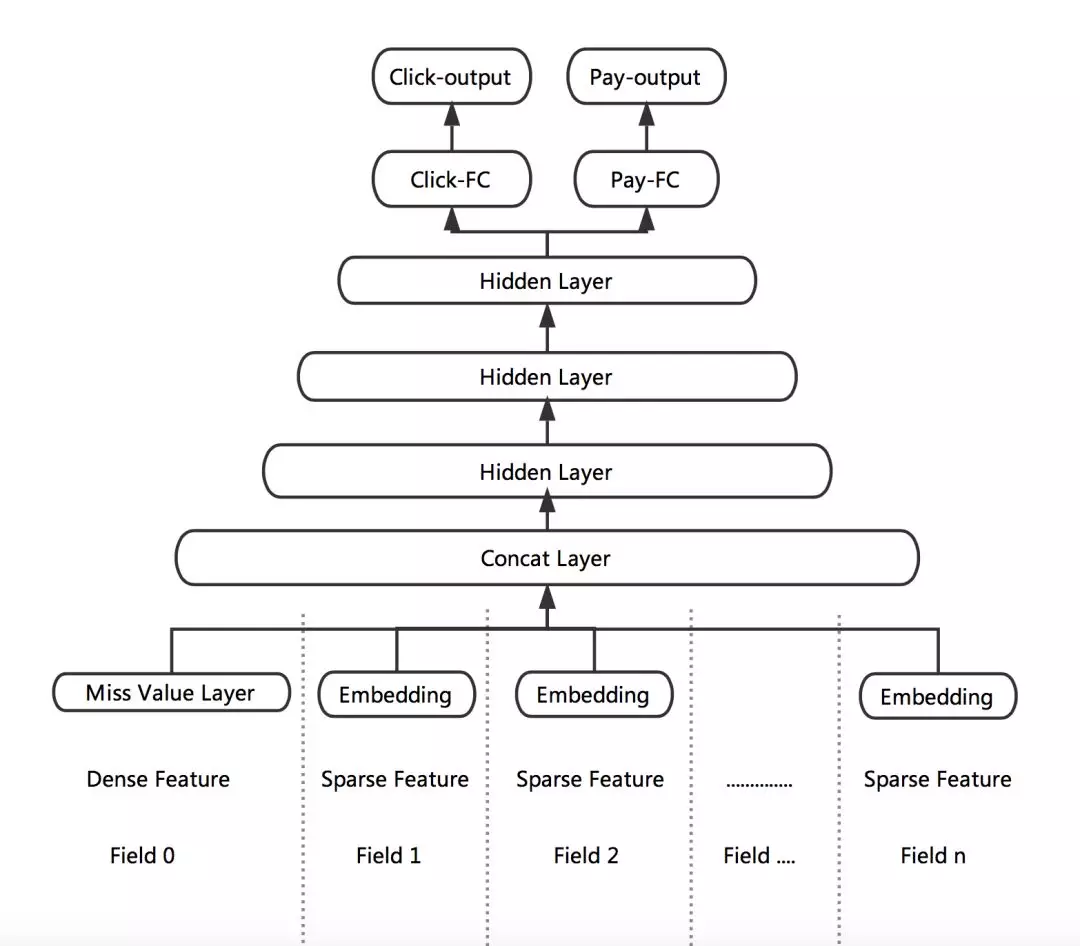
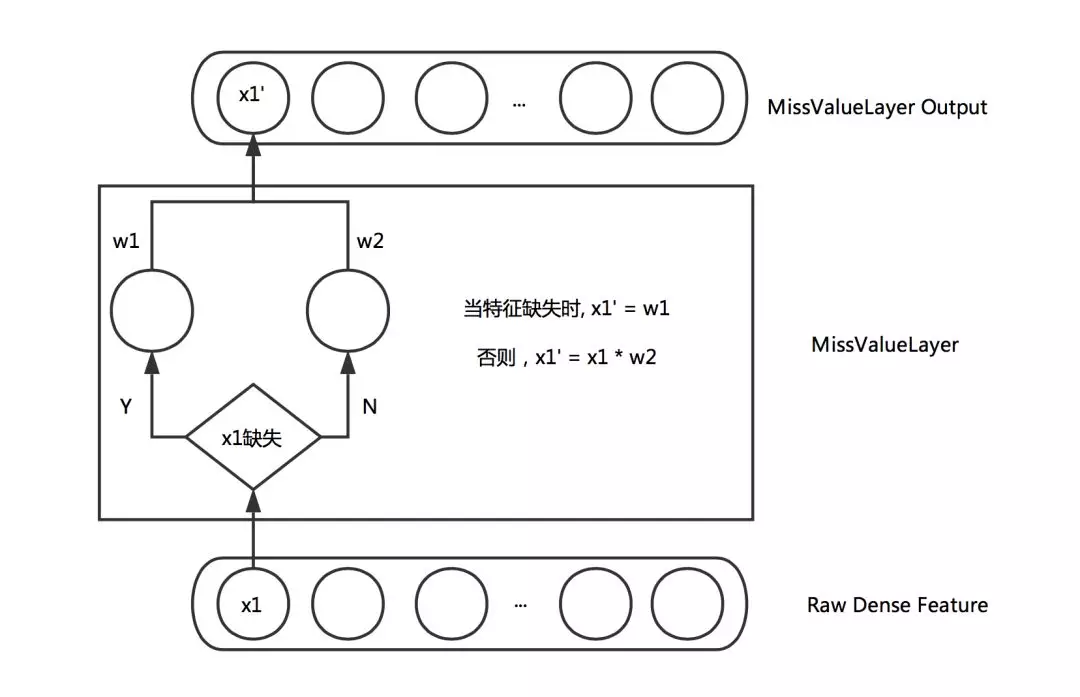
这里有两个技巧可借鉴下:
❶ Missing Value Layer:缺失的特征可根据对应特征的分布去自适应的学习出一个合理的取值。
❷ KL-divergence Bound:通过物理意义将有关系的 Label 关联起来,比如 p(点击) * p(转化) = p(下单)。加入一个 KL 散度的 Bound,使得预测出来的 p(点击) * p(转化) 更接近于 p(下单)。但由于 KL 散度是非对称的,即 KL(p||q) != KL(q||p),因此真正使用的时候,优化的是 KL(p||q) + KL(q||p)。
Google MMoE
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
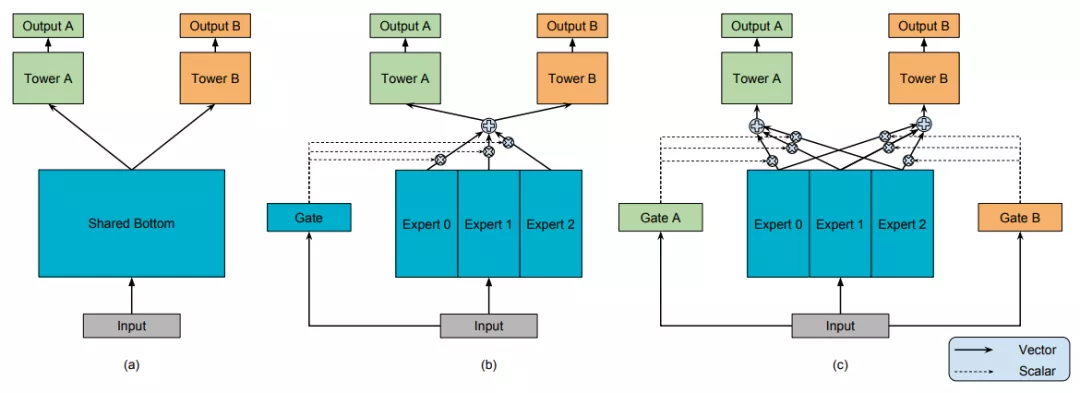
模型 (a) 最为常见,两个任务直接共享模型的 bottom 部分,只在最后处理时做区分,图 (a) 中使用了 Tower A 和 Tower B,然后分别接损失函数。
模型 (b) 是常见的多任务学习模型。将 input 分别输入给三个 Expert,但三个 Expert 并不共享参数。同时将 input 输出给 Gate,Gate 输出每个 Expert 被选择的概率,然后将三个 Expert 的输出加权求和,输出给 Tower。有点 attention 的感觉
模型 © 是作者新提出的方法,对于不同的任务,模型的权重选择是不同的,所以作者为每个任务都配备一个 Gate 模型。对于不同的任务,特定的 Gate k 的输出表示不同的 Expert 被选择的概率,将多个 Expert 加权求和,得到 fk(x) ,并输出给特定的 Tower 模型,用于最终的输出。
其中 g(x) 表示 gate 门的输出,为多层感知机模型,简单的线性变换加 softmax 层。
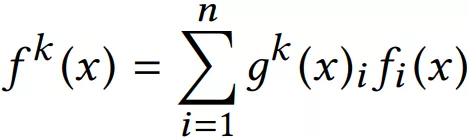
本文转载自 DataFunTalk 公众号。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论