
背景
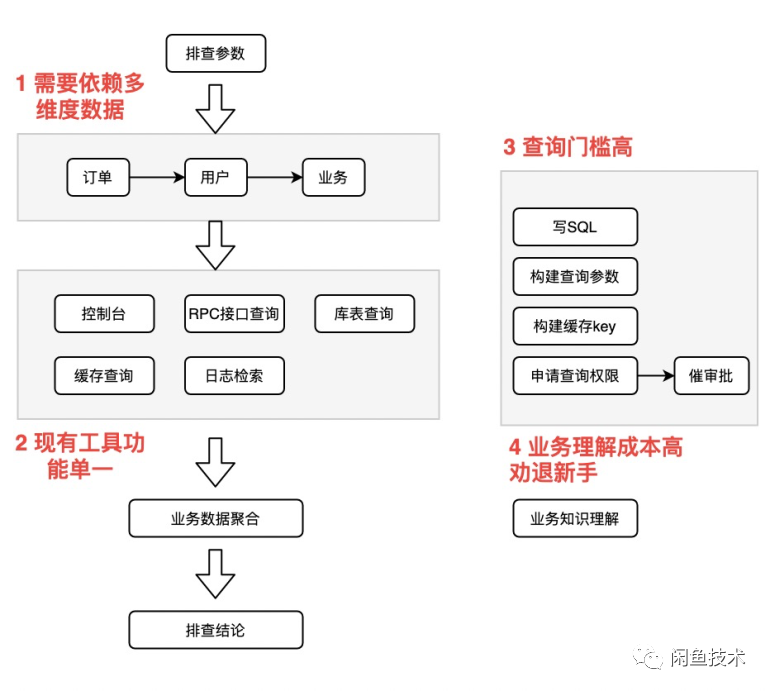
在日常的开发中,我们会收到来自用户,合作伙伴,客服,运营,产品和测试的各种各样的问题反馈,问题咨询,单点问题排查等,这些问题在经过若干人转交后,大部分最终会由开发同学处理。
而开发同学解决这些问题也相当痛苦:反复沟通获取必要的查询参数,从多个平台得到业务数据,如果没有相关的平台工具,那么还会通过构建 SQL, rpc 服务入参,缓存 key 等查询获取所需要的业务参数,最后根据你多年对业务的理解,从这些数据中找到答案。
我们可以将以上归纳为两个影响我们日常问题排查效率的因素:问题流转多;排查链路长。
本文将介绍一种提高日常业务问题排查效率的通用方案,并已在闲鱼应用落地,取得了不错的效果。
该方案具备以下特点:
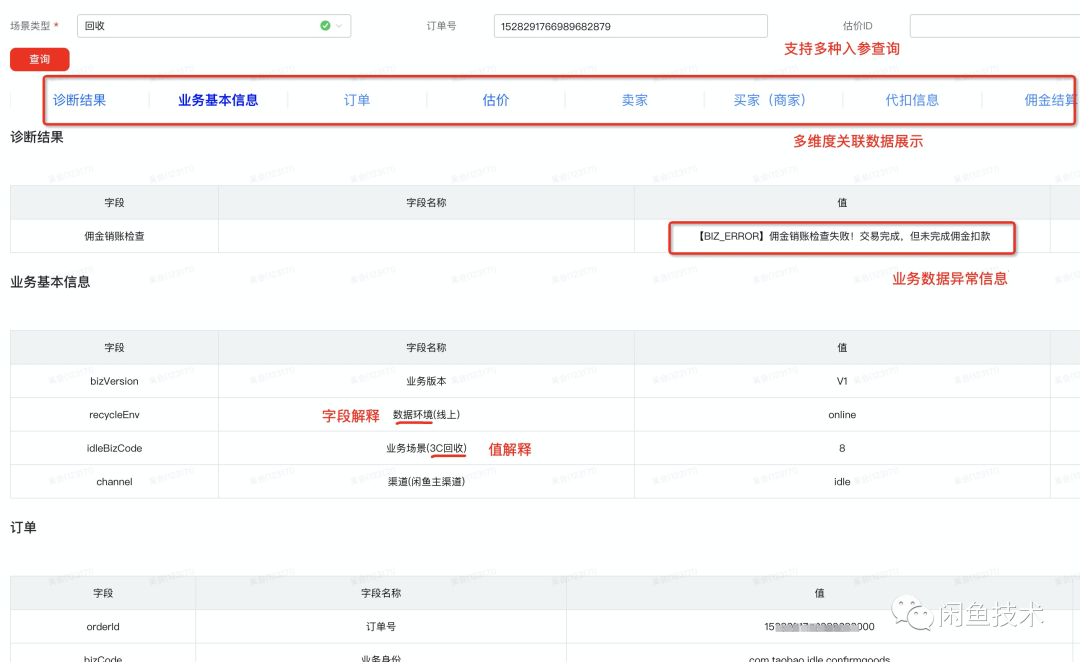
一键获取所有关联业务数据:输入不同维度的入参,获取一致的数据结果;
业务数据易于理解,人人可用:可对业务数据属性进行解释,以方便非技术人员自助查询;
业务数据可诊断:如果数据出现异常,能够给出异常的数据信息。
业务数据全景与诊断
整体思路
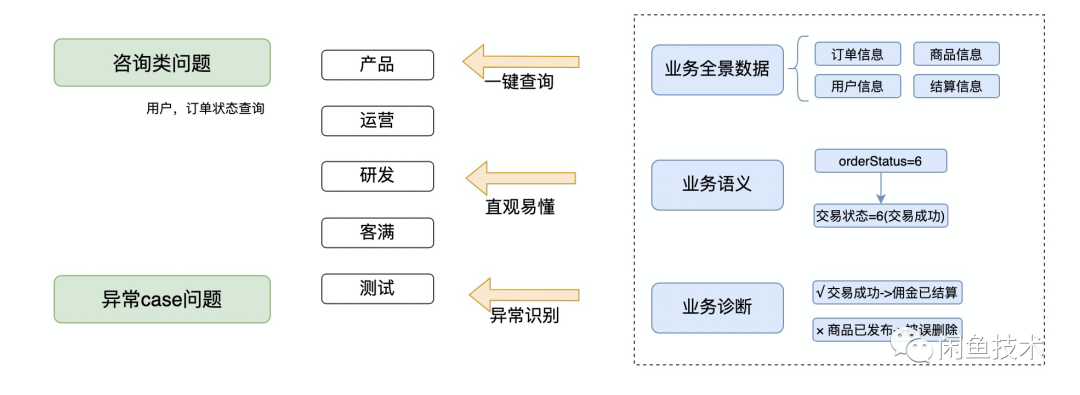
我们将问题分成 2 类
异常 case 问题:业务数据存在异常(数据缺失,状态不一致等)
业务数据查询:数据正常,需要咨询相关数据(单据状态,权益核销情况等)
通过对问题的归纳和排查过程的抽象,我们的思路就比较清晰了:
1.提供一种通用的数据聚合查询方式,能够依赖调用各个系统服务获取所有关联数据
2.对业务数据进行语义解释和补充
3.抽象业务规则集,判断数据是否存在异常
此外,系统还要 具备高扩展性和接入成本低,使其他业务快速接入使用。
整体架构如下:
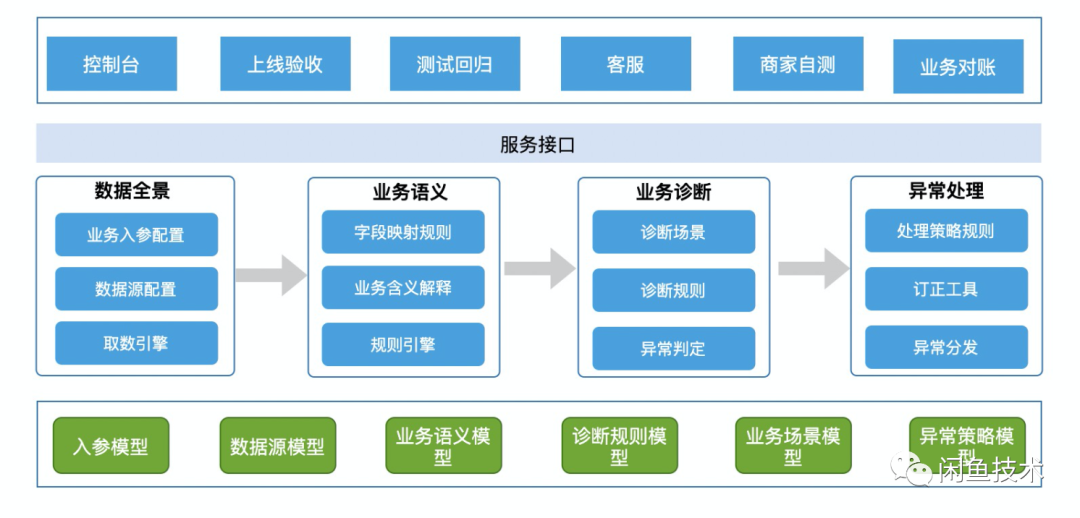
下面分别介绍如何实现数据全景,业务语义解释,以及业务数据诊断。
数据全景
这一部分是整个系统的基础,后续的所有的能力都是基于聚合查询的数据实现的。聚合查询会调用多个系统的接口,而对于每个业务的服务依赖都不同且只能由负责该业务的开发同学完成(因为其他人并不知道取哪些数据),如果查询成本过高则不利于业务方的接入和使用,通用性也大打折扣。这里我们选择 GraphQL 作为数据聚合查询服务。
关于 GraphQL 的介绍:https://graphql.cn/
闲鱼此前有过关于 GraphQL 的一些实践。通过编写 graphql 语句一次性获取所有的数据,前端根据数据直接渲染,实现快速搭建页面。通过将业务逻辑前置,服务端只需要专注于建设稳定的域服务,使我们开发过程中免除了前后端的数据格式约定和接口联调,提高了研发效率。很多情况下,GraphQL 也可以作为 FaaS 的一种解决方案。
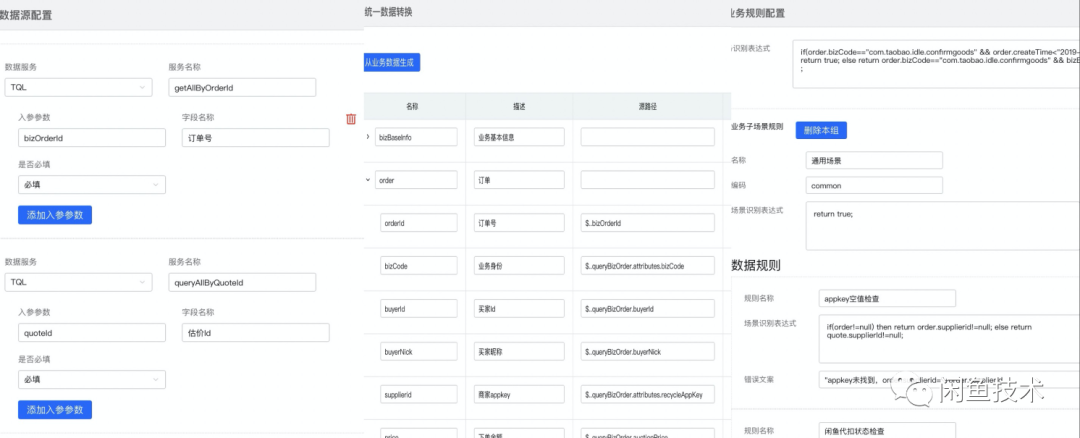
我们以闲鱼回收业务为例,该业务全链路涉及到 交易,资金,芝麻信用,蚂蚁能量,佣金结算,和估价数据,其 graphql 语句简单描述为:

如上图,我们输入订单号 bizOrderId, 通过 GraphQL 执行器分别依赖调用了多个系统的 订单服务 queryBizOrder,估价服务 HSF_quoteService,代扣服务 HSF_agreementpayBillQuery, spu 查询服务 HSF_spuQuery,结算查询服务 settleBillQuery, 并且通过 Tair(分布式缓存,类似 redis)查询了用户的业务状态,经过 6 个系统最终得到聚合数据:
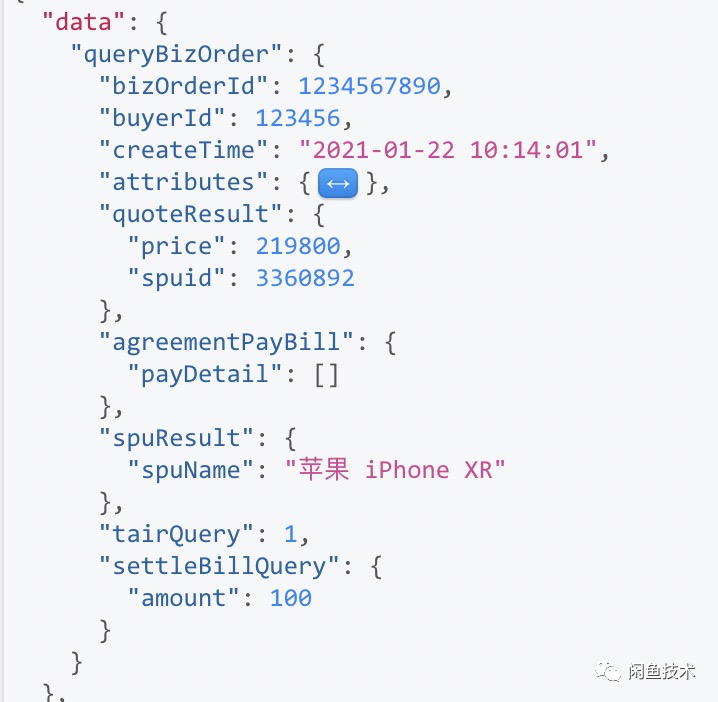
使用 GraphQL 实现业务数据的聚合查询,业务使用成本大大降低,一般无需侵入系统即可获取所有数据。
业务语义转换
数据转换是将 GraphQL 的查询数据转变为可被理解的业务数据, 包括属性字段的中文解释,以及对属性值的含义解释,以便于可视化输出和降低非技术同学理解成本,这里需要解决 3 个问题:
数据重分组
从上面的例子我们看到,“用户信用订单笔数”是来自于 redis 这样中间件的非特定域服务的数据, 但从业务逻辑的划分上,这个数据应当属于”用户“域,因此,为了表达更加直观,我们将其归为用户属性
输入数据的不确定性
在很多情况下,反馈者提供的查询入参并不总是一个维度的参数,如交易链路中,用户提供的可能是 订单 id/退款单 Id/资金单 Id/权益 Id 等,这些数据实际上都能一一对应, 如果只能通过订单号查询,那有时候就需要进行至少一次反查才能得到订单 Id 后再使用工具。要实现”一键直达“,我们就要支持多维参数输入,比如上面的例子,还可以通过估价 Id 来获取聚合数据:
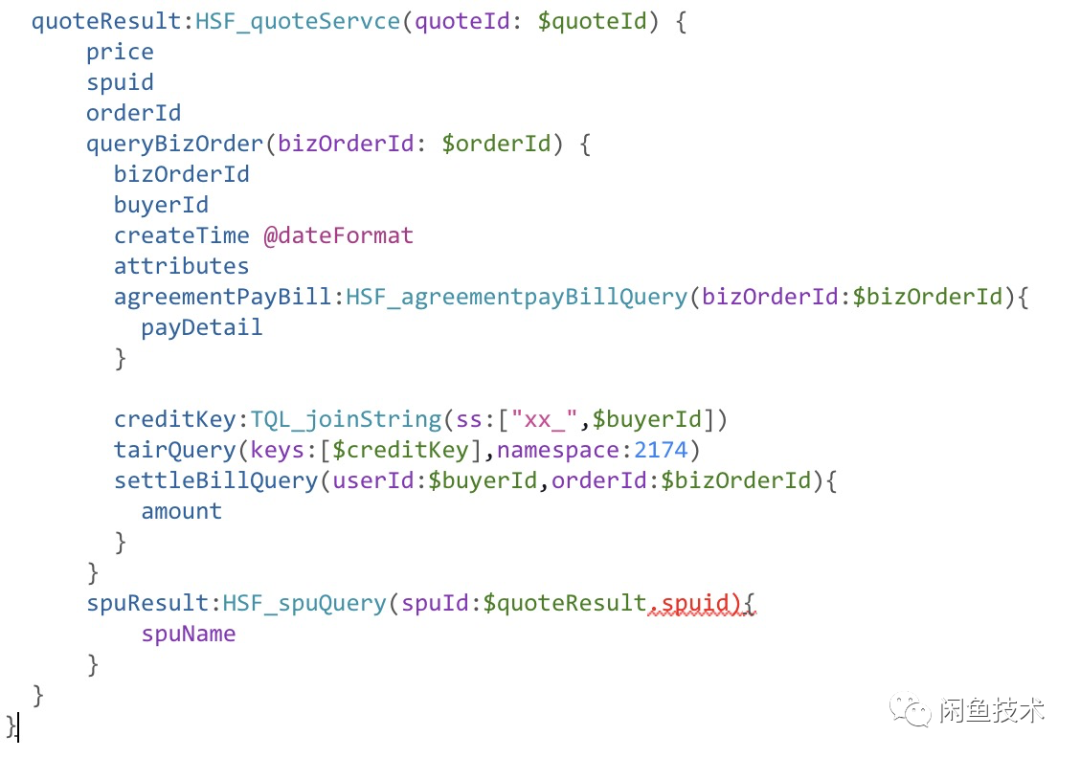
可以看到这两个 ql 返回的数据结构是不同的,但其有效的业务数据都是相同的,我们将这种数据称为异构数据。
异构数据统一
不同的输入参数导致我们需要使用不同的 GraphQL 语句来表达,并得到了不同结构的返回结果,这不利于业务字段的解释和数据规则检查 。因此需要将多个异构数据合并为一个确定的数据结构,作为页面统一展示,和后续进行数据诊断的输入参数。
我们使用 JSONPath 将其转化为统一的数据结构并对数据进行重新分组:

除了 JSONPath,我们还实现了一些其他情况下的二次值转换:
状态值转换:通常用于翻译可枚举的状态值,如交易状态=6 解释为 交易状态=6(交易成功);
虚拟属性值对:类似于宏,如定义 "是否是高价订单" = eval(order.price>2000), 计算表达式的值,以补充一个原本不存在的属性字段。
现在,我们已经得到一个可以查询业务全景数据的工具了。你可以使用它作为业务数据的查询控制台。
有了统一的业务数据,下一步就是实现业务数据的诊断能力。
业务诊断
判断数据是否异常,从开发角度看就是这样的逻辑集合:
if(实际值!=期望值){ print 异常结果}这里的[期望值] 是一个数据集,即表示为:
当 数据中出现 A 数据时,数据还应当有结果[B1,B2,B3]。
我们将业务逻辑细化,形成一个业务数据规则表达模型:
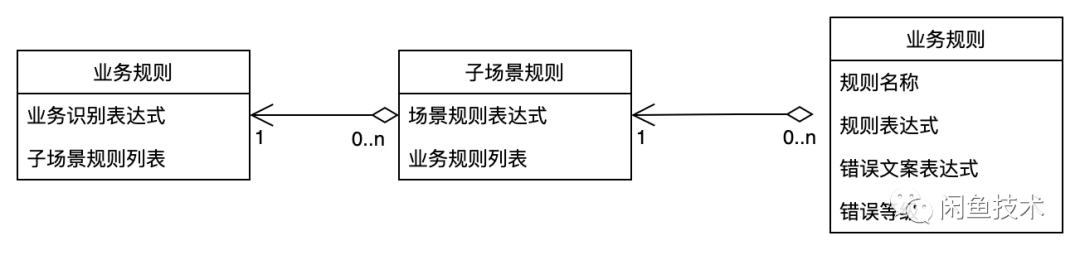
这些规则可以从业务 TC 用例得出,进行可视化后还能帮助新人学习业务逻辑。
我们选择 QLExpress 来表达并执行这个规则
QLExpress(https://github.com/taobao/qlexpress)是阿里开源的一种动态脚本引擎,功能强大,兼容 java 的大部分语法,可以使用关键字别名替换:
如果(order.isCreditOrder == "1") 则 return order.idleCreditPayAmount > 0;否则 return true;执行上面的规则代码
//defaultContext 是数据转换后的数据,作为qlexpress的上下文 Object executeResult = QLExpressUtil.execute(ruleExpress, defaultContext, errorList, false, false); //将执行结果转换,空结果默认成功, 如果结果为失败,则再执行一次formater获得错误文案 QLExpResult qlExpResult = buildQlExpResult(context, executeResult, formater); if (!qlExpResult.getSuccess()) { errors.add(DiagnosisError .of(ErrorLevel.BIZ_ERROR.name(), ruleName, String.valueOf(qlExpResult.getData()))); }依次将所有的规则全部执行完后,将结果与业务结果合并展示,就得到一个带有诊断结果的业务全景数据:

整体执行过程
最后,总结一下整个执行过程:
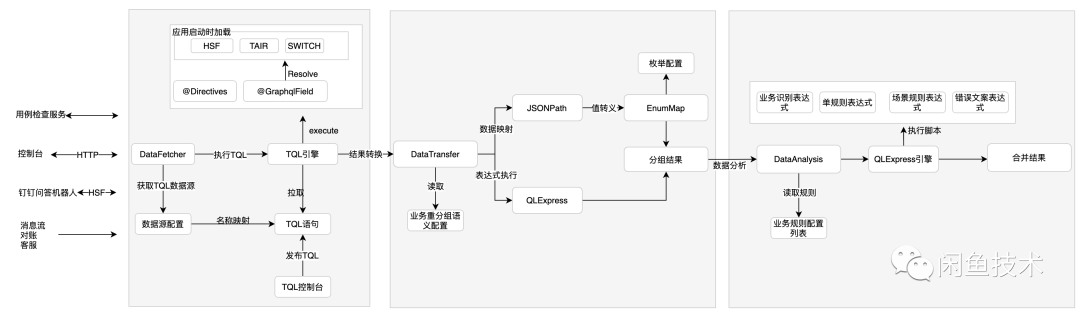
以上就是我们实现日常业务数据全景排查与诊断的核心能力,通过提供一些页面配置化接口,即可使多业务快速接入。
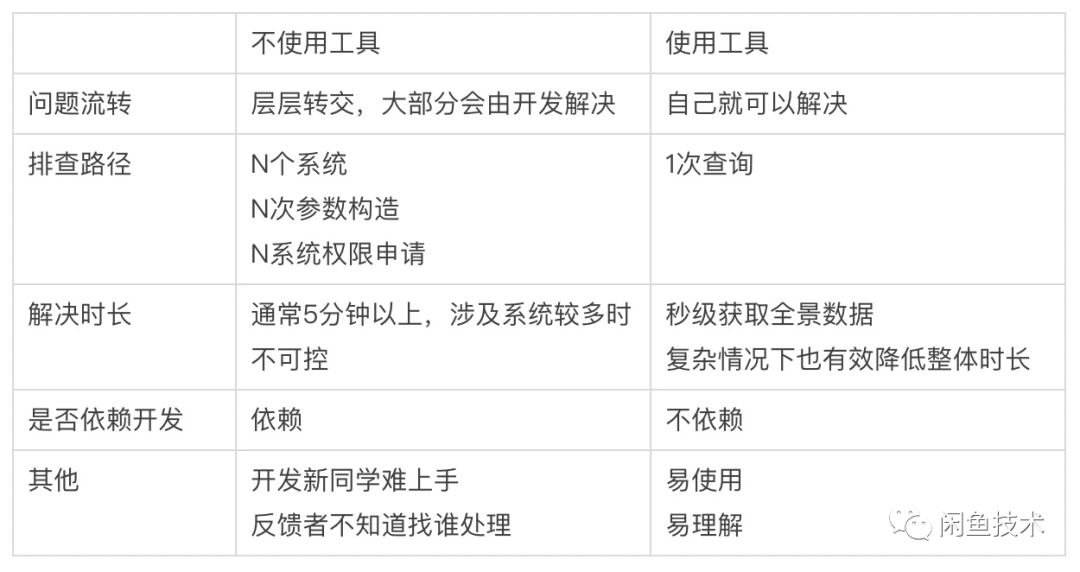
应用效果对比
最后,我们从几个维度对比下该工具的排查效率:
能力延伸
除此以外,我们还进行了更多能力的延伸,以更高效地支持日常业务运维。
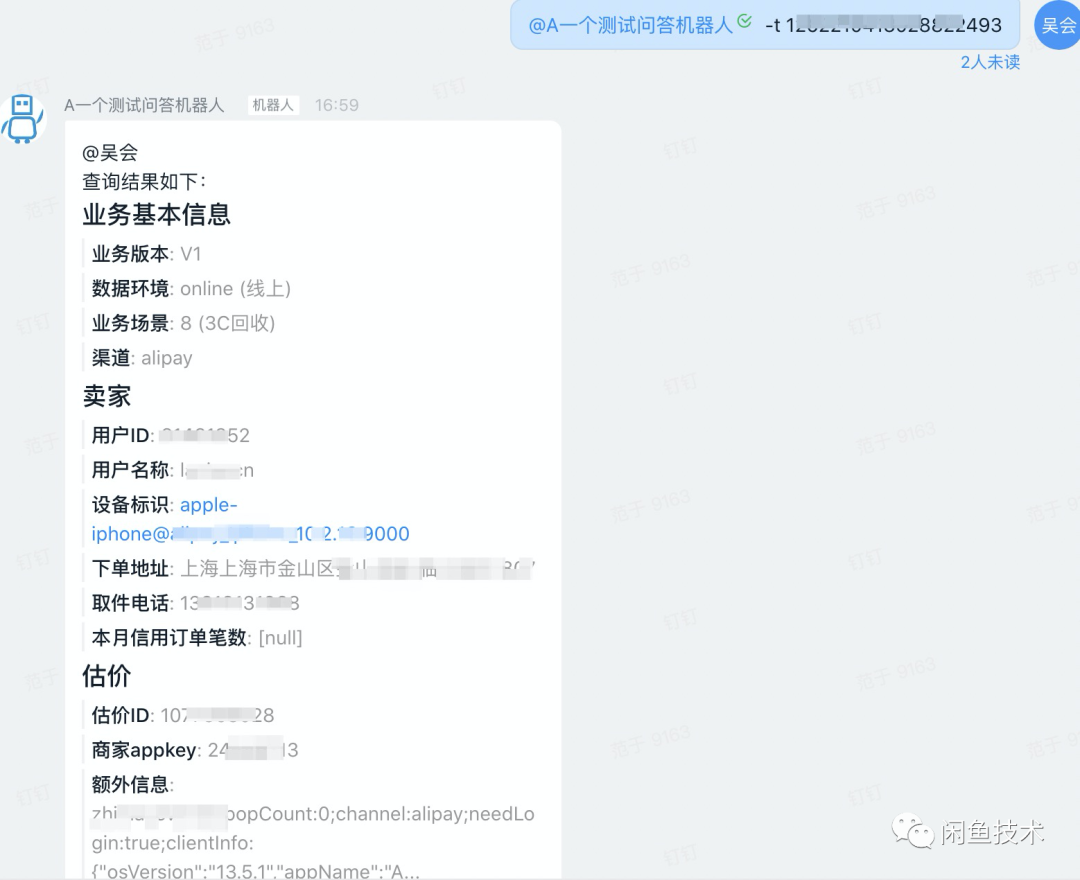
接入钉钉答疑机器人
你可以在度假,休息,电脑不在身边等不方便的情况下使用手机完成这一切,更高效更快速,避免了可能会收到的分手警告~
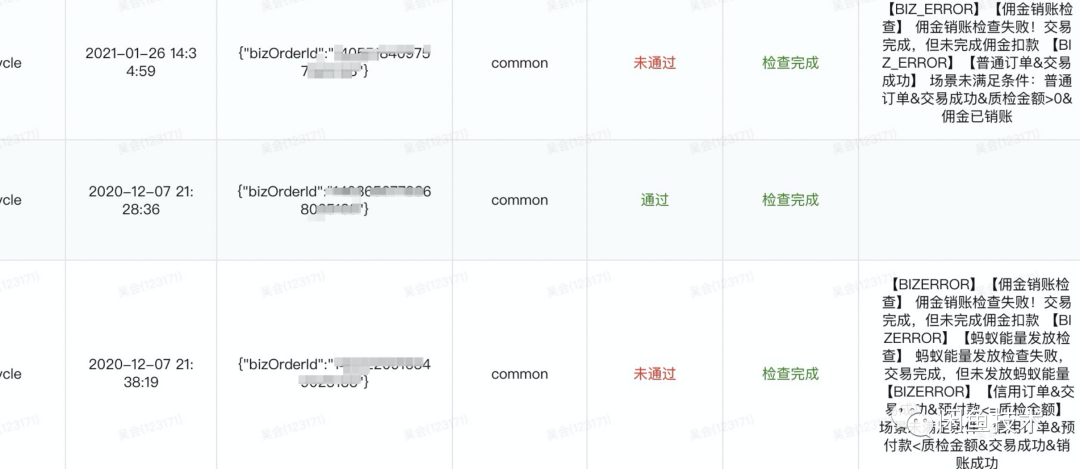
用例的自动化检查
如果业务系统会与外部(合作伙伴)系统交互,将无法通过内部的回放工具来保障外部服务是否正常,我们可以基于诊断能力从数据层面验证是否存在异常:
总结
通过对日常问题的分析归纳,排查流程的抽象,我们总结出了一个能够提高日常单点问题的排查效率的通用方案,使其能够服务于产品,运营,客服,研发,测试人员,业务可扩展且低成本接入,显著降低了问题的排查成本。方案的实现主要包括:
使用 GraphQL 实现业务数据的聚合查询;
使用 JSONPath 解决不同维度的异构数据和业务数据的重分组,并进行业务语义解释;
使用 QLExpress 表达和执行业务数据规则,完成数据的诊断。
当然,目前还存在很多种情况无法做到一键排查,未来,我们还会向着实现“问题到我为止”的目标持续优化:
结合日志检索工具,用户行为回放工具提供更多维度的一键直达;
对异常数据的处理,包括数据订正,审批,指引;
为客服,答疑等场景提供排查手段,引入敏感数据分级,防止数据泄露;
接入业务消息进行对账 &监控预警。
本文转载自:闲鱼技术(ID:XYtech_Alibaba)
原文链接:如何实现日常业务问题的一键排查?




