

最近我分配到了一个非常有趣的任务:在前端显示 1GB 文件和 200 万行数据,并实现过滤,在这篇文章中,我将分享我是如何完成这个任务的。
背景
我曾经创建了一个简单的 React 应用程序。这个应用程序从服务器加载一些数据,并呈现在几个表格中。在成功演示了 React 应用程序后,客户授权我访问生产数据。然后,有趣的事情发生了。当我将应用程序从开发 API 连接到生产环境并重新加载页面时,看到了类似“显示此网页时出现问题”的错误。经过调试,我发现生产服务器的 JSON 文件大小约为 500MB(而不是从开发服务器的 2 到 5 MB)。
最新的需求是:
1.JSON 文件最大可达到 1 GB。
2.后端不会进行分页——只能接受这个事实。
首先,我尝试了 react virtualized,一个 React 组件,可以通过虚拟渲染有效地渲染大型列表。
但几天后又出现了新的需求:
3.“标准的浏览器搜索(Ctrl/Cmd + F)功能无法正常工作,必须修复这个问题!”
虚拟列表背后的主要思想是只渲染可见的内容。因此,如果用户在搜索框中输入一些东西,那么浏览器只会搜索虚拟列表的可见部分。
下图演示了浏览器是如何搜索虚拟列表的。请注意,滚动后出现的记录(虚拟列表进行了重新渲染)没有高亮显示,尽管包含了要搜索的值“@”。
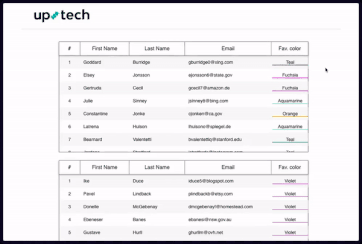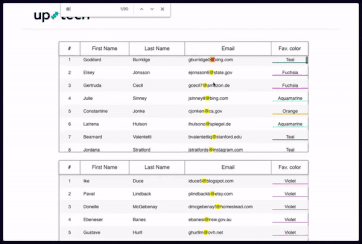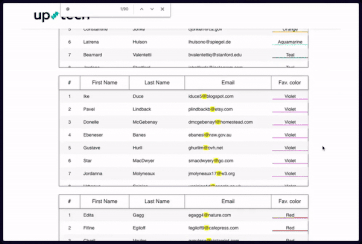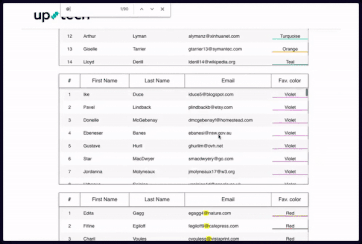
搜索框
我决定创建一个具有类似默认浏览器搜索功能的自定义搜索框,但可以搜索所有的 200 万条记录。
对大量数据进行过滤操作会导致“堆内存不足”。截至 2018 年 4 月,我没有找到任何提供内置搜索/过滤功能的 React 虚拟列表实现。
经过几个小时的谷歌搜索和在 Stack Overflow 网站上提问之后,我想到了 Web Worker,并使用了Simple Web Worker库。这个方法的主要思想是将一个大数组拆分成更小的部分,并使用 Web Worker 异步处理每个部分。
找到最佳的块长度是很有必要的。块的长度越短搜索速度就越慢,但长度越长,在低配置设备上出现“堆内存不足”的可能性就越大。在我的例子中,根据实验结果,3000 是最佳长度。
华丽制胜
下图演示了自定义搜索框。在发生滚动后,高亮显示不会消失,用户可以通过箭头按键在行和表之间导航。是的,过滤数据确实需要一些时间,但它可以处理比之前更多的信息。为简单起见,数组只包含了 9000 个项,但可以随意添加,不过过滤时间也会随之增加(过滤 200 万行可能需要 5-7 分钟)。
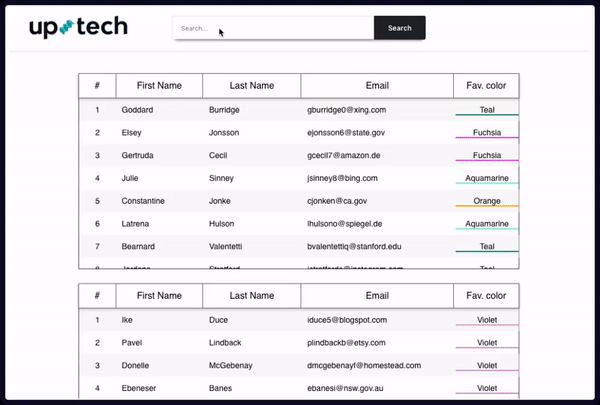
这种方法帮助我解决了几个问题:
过滤大量数据而不会导致浏览器崩溃。在我的例子中,文件的最大大小约为1GB,最多有约200万行数据。
创建一个搜索框,提供与原生浏览器搜索类似的UX,可以搜索所有200万行数据。
你可以在这里找到应用程序的源代码:
https://github.com/uptechteam/react-filter-demo
演示:https://uptechteam.github.io/react-filter-demo/
解决方案简短描述
这个 React 应用程序包含 3 个组件:
App.js——应用程序的主要组件;
SearchBox.js——实现搜索框功能的组件,使用箭头按键导航搜索结果;
TablesViews.js——渲染结果表格的组件,它演示了如何在表格之间实现SearchBox导航。
英文原文:
更多内容,请关注前端之巅。


暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论