

前言
很多人学习和使用 envoy 时,很容易混淆一些概念,比如把异常点驱逐和微服务熔断混为一谈,分不清最大驱逐比与恐慌阈值的区别等。本文将基于 envoy 官方文档(v1.10.0),详细介绍异常点检测的类型、驱逐算法以及相关概念的解析,并且最后对易混淆的几个概念进行辨析。

简介
异常点检测(Outlier detection)和驱逐(Ejection)是用来动态确定上游集群中是否有表现不同于其他主机的实例,并将它们从健康负载均衡集中移除的过程。性能可能会沿着不同的轴变化,如连续失败,一时的成功率,短时间内的延迟等。异常值检测是一种被动的健康检查形式。Envoy 还支持主动健康检查。被动和主动健康检查功能可以一起或独立使用,它们共同构成整个上游健康检查解决方案的基础。
驱逐算法
根据异常值检测的类型,驱逐要么以直线方式运行(例如在连续返回 5xx 的情况下),要么以指定的间隔运行(例如在周期性成功率的情况下)。驱逐算法的工作原理如下:
主机被确定为异常点。
如果没有主机被驱逐,Envoy 会立即驱逐主机。否则,它会检查以确保驱逐主机的数量低于允许的阈值(通过 outlier_detection.max_ejection_percent 设置指定)。如果驱逐的主机数量超过阈值,则主机不会被驱逐。
主机被驱逐的状态会保持一小段时间(以毫秒为单位)。被驱逐意味着该主机被标记为不健康,并且在负载均衡期间不会被使用,除非负载均衡器处于恐慌状态。被驱逐的时间等于 outlier_detection.base_ejection_time_ms 的值乘以该主机被驱逐的次数。这意味着,如果该主机连续失败,它被驱逐的时间将越来越长。
驱逐时间满足后,被驱逐主机将自动恢复服务。通常情况下,异常值检测与主动健康检查(active health checking)一起使用,以获得全面的健康检查解决方案。
检测类型
Envoy 支持以下异常点检测类型:
连续返回 5xx
如果上游主机返回一些连续的 5xx,它将被驱逐。注意,在本例中,5xx 表示实际的 5xx 响应码,或者导致 HTTP 路由器代表上游返回该响应码的事件(重置、连接失败等)。驱逐所需的连续 5xx 的数量由 outlier_detection.continutive_5xx 值控制。
连续网关失败
如果上游主机返回一些连续的"网关错误”(502、503 或 504 状态码),它将被驱逐。注意,这包括可能导致 HTTP 路由器代表上游返回其中一个状态码的事件(重置、连接失败等)。驱逐所需的连续网关故障数量由 outlier_detection.consecutive_gateway_failure 值所决定的。
成功率
基于成功率的异常点驱逐聚合了集群中每个主机的成功率数据。然后在给定的时间间隔内,基于统计的异常点检测数据对主机进行驱逐。如果主机的请求量汇总时间间隔小于 outlier_detection.success_rate_request_volume 值,该异常点驱逐将不会被计算。另外,如果一个间隔中具有最小所需请求卷的主机数量小于 outlier_detection.success_rate_minimum_hosts 值,检测将不能进行。
驱逐事件日志
异常点驱逐事件的日志可以由 Envoy 选择性地生成。这在日常操作中非常有用,因为全局统计信息不能提供关于哪些主机被驱逐以及出于什么原因被驱逐的足够信息。日志被结构化为基于 protobuf 的 OutlierDetectionEvent messages 转存文件。驱逐事件日志是在集群管理器 outlier detection configuration 中配置的。
相关概念
主动健康检查
主动健康检查可以在每个上游集群的基础上进行配置。主动运行健康检查和 EDS 类型服务发现会同时进行。但是,即使使用其他服务发现类型,也有其他需要进行主动健康检查的情况。Envoy 支持三种不同类型的健康检查(HTTP, L3/L4, Redis)及各种设置(检查时间间隔、主机不健康标记为故障、主机健康时标记为成功等)。
在同时使用主动健康检查和被动健康检查(异常点检测)时,通常使用较长的健康检查间隔来避免大量的主动健康检查流量。在这种情况下,当使用/healthcheck/fail 管理端点时,能够快速耗尽上游主机仍然是有用的,router filter 会在 x-envoy-immediate-health-check-fail header 里面响应来支持它的实现。如果 header 由上游主机设置标记,Envoy 将立即将主机标记为主动健康检查失败。注意,只有在主机集群的主动健康检查已配置时才会发生这种情况。如果 Envoy 已经通过/healthcheck/fail 管理端点标记为失败,健康检查过滤器将自动设置这个 header。
恐慌阈值
在负载均衡期间,Envoy 通常只会考虑上游集群中健康的主机。但是,如果集群中健康主机的百分比变得过低,envoy 将忽视所有主机中的健康状况和均衡。这被称为 恐慌阈值(panic threshold) 。缺省恐慌阈值是 50%。这可以通过运行时配置或者集群配置进行配置。恐慌阈值用于避免在负载增加时主机故障导致整个集群中级联故障的情况。注意:恐慌阈值不同于驱逐算法第 2 点提到的最大驱逐百分比(outlier_detection.max_ejection_percent)。
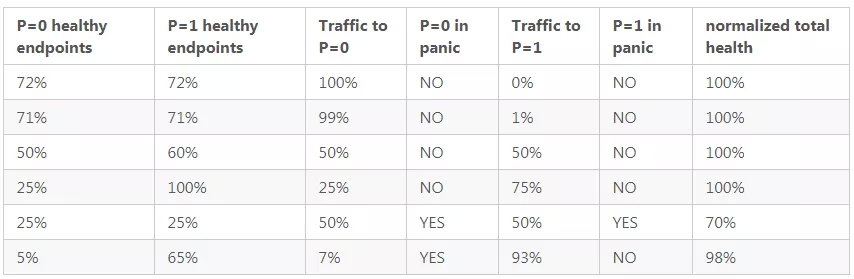
另外,恐慌阈值与优先级协同工作。如果某个优先级的可用主机数量下降,Envoy 将尝试将一些流量转移到较低的优先级。如果它成功地在较低的优先级找到足够的可用主机,Envoy 将不顾恐慌阈值。在数学术语中,如果所有优先级的规范化(normalized)总可用性为 100%,Envoy 将忽略恐慌阈值,并继续根据这里描述的算法在优先级之间分配流量负载。然而,当规范化总可用性下降到 100%以下时,Envoy 假定在所有优先级上都没有足够的可用主机。它将继续跨优先级分配流量负载,但是如果给定优先级的可用性低于 panic 阈值,则流量将负载均衡到该优先级的所有主机,而不管它们的可用性如何。
总结
结合以上介绍来看,异常点检测是一种被动的健康检查,区别于主动健康检查,它不是向主机发送心跳或者通过长链接探活来判定实例的健康,而是通过对该主机发起的请求的返回值做分析,基于不同的检测类型以及不同的驱逐算法,对目标主机做驱逐或者恢复。
而微服务中的熔断主要是一种系统保护策略,它的基本功能是在检测到故障后切断链路,通过直接返回错误或者 fallback 值,来直接提高系统可用性,防止该故障程序出现问题蔓延至整个网络造成雪崩效果。笔者以为,envoy 中的异常点检测可以理解为"实例级别"的熔断,并且没有半开放状态。关于该实例级别的熔断与公称断路器的区别的详细介绍,可以参考微服务断路器模式实现:Istio vs Hystrix。
并且,envoy 异常点检测中的maxEjectionPercent属性的作用会保持一部分的实例池,即使其中部分实例不可用。其目的是为了避免在负载增加时主机故障导致整个集群中级联故障雪崩,这一点和恐慌阈值的作用相似。但是’maxEjectionPercent’与’panic threshold’的作用域却完全不同。达到恐慌阈值后,流量将负载均衡到该优先级的所有主机,所有主机包括被异常点检测标记为不健康的实例和健康的实例,并且如果如果驱逐达到了‘maxEjectionPercent’设定值,那么这组健康的实例中还可能包含不可用的实例。
最后 Envoy 自身还实现了网络级别的分布式断路器,这才是 istio/envoy 提供的"正统"断路器。作为一个分布式短路器,它的特点是在网络级别强制实现断路,而不必为每个应用程序单独配置或者编程,实现零侵入。Envoy 支持的分布式断路包括:集群最大连接数、集群最大挂起请求数、集群最大请求数、集群最大活动重试次数等。
总而言之,不管是 envoy 的异常点检测还是网络级别的分布式断路器,作为一种 sidecar 代理,采用的是黑盒方式的实现,并且对应用程序零侵入。但是如果你的系统需要对某个应用程序做到方法级别的精确熔断,设置各种超时重试等参数,设置不同的 fallback 返回值,抑或是调用其它的服务做降级处理等等,则需要侵入式的断路器(可参考 Resilience4J 与 Hystrix)。
本文转载自公众号 ServiceMesher(ID:ServiceMesher)。
原文链接:
https://mp.weixin.qq.com/s/3t32qC0FNGrENi67VPpPaQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论