SQL:2003 是 SQL 标准的第四个修订版, 该版本引入了若干新特性,其中便包括窗口函数(SQL Window Function)。在 Oracle 数据库中窗口函数被称作『分析函数』(Analytics Functions), 其他主流数据库产品也都有各自的实现。MySQL 于版本 8.0.2(2017 年 7 月发布)开始支持一部分窗口函数语法,TiDB 则于版本3.0 1 (2019 年 6 月发布) 实现了与 MySQL 兼容的语法支持。
本文尝试在 TiDB 3.0 上运行一些包含窗口函数调用语法的 SQL,实地体验一下 TiDB 对窗口函数的支持。
准备环境
准备TiDB 3.0环境。若手边有一套TiDB 3.0环境,则足以运行本文后面列出的所有SQL。建议在非生产环境执行这些SQL,以免影响到线上业务。如果手边没有合适的TiDB 3.0环境,建议在个人电脑上以Docker形式运行Standalone模式的TiDB Server。这里 1列出了具体的做法。
开启TiDB窗口函数支持。全局变量tidb_enable_window_function须设置为1。在我使用的测试环境里,把TiDB从版本v2.1.x升级到3.0.1之后,该变量虽然默认被置为了1,但仍然无法识别窗口函数语法。 须再次手动设定一下方才生效。具体细节可参考这里.
tidb> set global tidb_enable_window_function = 1;Query OK, 0 rows affected (0.01 sec)
tidb> show variables like '%window%';+| Variable_name | Value |+| tidb_enable_window_function | 1 |+1 row in set (0.01 sec)
复制代码
tidb>show create table sample_db.emp \G*************************** 1. row *************************** Table: EMPCreate Table: CREATE TABLE `EMP` ( `EMPNO` int(11) NOT NULL, `ENAME` varchar(10) DEFAULT NULL, `JOB` varchar(9) DEFAULT NULL, `MGR` int(11) DEFAULT NULL, `HIREDATE` date DEFAULT NULL, `SAL` int(11) DEFAULT NULL, `COMM` int(11) DEFAULT NULL, `DEPTNO` int(11) DEFAULT NULL, PRIMARY KEY (`EMPNO`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin1 row in set (0.00 sec)
tidb>select * from sample_db.emp;+-------+--------+-----------+------+------------+------+------+--------+| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |+-------+--------+-----------+------+------------+------+------+--------+| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800 | NULL | 20 || 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600 | 300 | 30 || 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250 | 500 | 30 || 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975 | NULL | 20 || 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250 | 1400 | 30 || 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850 | NULL | 30 || 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450 | NULL | 10 || 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000 | NULL | 20 || 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000 | NULL | 10 || 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500 | 0 | 30 || 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100 | NULL | 20 || 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950 | NULL | 30 || 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000 | NULL | 20 || 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300 | NULL | 10 |+-------+--------+-----------+------+------------+------+------+--------+14 rows in set (0.00 sec)
复制代码
上面几项就绪,则不妨试着执行下述 SQL 验证一下环境:
tidb>select -> ENAME, -> DEPTNO, -> count(*) over(partition by DEPTNO) as dept_cnt -> from EMP -> order by DEPTNO -> ; +--------+--------+----------+ | ENAME | DEPTNO | dept_cnt | +--------+--------+----------+ | CLARK | 10 | 3 | | KING | 10 | 3 | | MILLER | 10 | 3 | | FORD | 20 | 5 | | ADAMS | 20 | 5 | | JONES | 20 | 5 | | SCOTT | 20 | 5 | | SMITH | 20 | 5 | | MARTIN | 30 | 6 | | TURNER | 30 | 6 | | WARD | 30 | 6 | | JAMES | 30 | 6 | | ALLEN | 30 | 6 | | BLAKE | 30 | 6 | +--------+--------+----------+ 14 rows in set (0.00 sec)
复制代码
如果在你的环境里也能成功执行,并输出相同结果,则证明环境搭建成功。
SQL 分组操作
什么是『SQL 分组操作』(SQL Grouping)?一言以蔽之,凡是使用了 GROUP BY 的 SELECT 语句都在执行 SQL 分组操作。那么,它和窗口函数有什么关系呢?分组是窗口函数的基础。我们也可以这么说,『窗口函数是更为高级的 SQL 分组操作』。
下面我们来执行一个有分组操作的 SQL,列出 EMP 表中员工人数超过 3 人的部门:
tidb>select DEPTNO, count(*) -> from EMP -> group by DEPTNO -> having count(*) > 3 -> order by count(*) desc; +--------+----------+ | DEPTNO | count(*) | +--------+----------+ | 30 | 6 | | 20 | 5 | +--------+----------+ 2 rows in set (0.00 sec)
复制代码
上述 SQL 按照部门编号(DEPTNO)把 EMP 表的数据记录分成了三组(使用 GROUP BY 分组,结果如下所示),分别计算每个分组包含多少行记录(调用聚合函数 COUNT(*)),最后筛选出记录行数超过 3 的分组(使用 HAVING 关键字)。
tidb>select * from EMP order by DEPTNO; +-------+--------+-----------+------+------------+------+------+--------+ | EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO | +-------+--------+-----------+------+------------+------+------+--------+ | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450 | NULL | 10 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000 | NULL | 10 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300 | NULL | 10 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000 | NULL | 20 | | 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100 | NULL | 20 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975 | NULL | 20 | | 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000 | NULL | 20 | | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250 | 1400 | 30 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500 | 0 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250 | 500 | 30 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950 | NULL | 30 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600 | 300 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850 | NULL | 30 | +-------+--------+-----------+------+------------+------+------+--------+ 14 rows in set (0.00 sec)
复制代码
SQL 分组操作有几个要点:
聚合函数(Aggregate Function,也可以叫GROUP BY Function):通常而言,分组是为了执行聚合函数,而聚合函数一定会把某个分组作为运算对象。除了上面使用到的COUNT,常见的聚合函数还有AVG(求均值),SUM(求和) 和 MAX(求最大值)等。TiDB支持的聚合函数列表在这里 1.
大多数聚合函数都会忽略掉NULL,唯独COUNT(*)例外。COUNT(_)会直接计数相应分组的记录行数, 而不在意某个字段值是否为NULL。如下述SQL所示,COUNT(_)的计算结果是14,COUNT(COMM)的结果则为4。这是因为EMP表中有10行记录COMM值都是NULL。与此类似,AVG(COMM)的计算结果是COMM字段不为NULL的4行记录的平均值:(1400 + 0 + 500 + 300) / 4 = 550。请注意,这里的除数是4,不是EMP表总行数14。
tidb>select count(*), count(COMM), avg(COMM) from EMP;+----------+-------------+-----------+| count(*) | count(COMM) | avg(COMM) |+----------+-------------+-----------+| 14 | 4 | 550.0000 |+----------+-------------+-----------+1 row in set (0.01 sec)
复制代码
tidb>select count(*) -> from EMP -> where JOB = 'CLERK';+----------+| count(*) |+----------+| 4 |+----------+1 row in set (0.00 sec)
复制代码
tidb>select DEPTNO -> from EMP -> where JOB = 'CLERK' -> group by DEPTNO -> order by DEPTNO;+--------+| DEPTNO |+--------+| 10 || 20 || 30 |+--------+3 rows in set (0.00 sec)
tidb>select distinct DEPTNO -> from EMP -> where JOB = 'CLERK' -> order by DEPTNO;+--------+| DEPTNO |+--------+| 10 || 20 || 30 |+--------+3 rows in set (0.00 sec)
复制代码
建议开启SQL模式选项ONLY_FULL_GROUP_BY 1。开启了ONLY_FULL_GROUP_BY之后,在含有GROUP BY的SELECT语句里, SELECT后面不能出现非聚合列。如下所示,sql_mode变量里不含ONLY_FULL_GROUP_BY选项时,TiDB允许一条不规范的GROUP BY语句成功执行(须注意, 此时查询结果里的JOB值可能与你的预期不符);加入了ONLY_FULL_GROUP_BY选项后,则TiDB会直接报错。
tidb>show variables like '%sql_mode%';+---------------+--------------------------------------------+| Variable_name | Value |+---------------+--------------------------------------------+| sql_mode | STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION |+---------------+--------------------------------------------+1 row in set (0.00 sec)
tidb>select DEPTNO, JOB, count(*) -> from EMP -> group by DEPTNO;+--------+----------+----------+| DEPTNO | JOB | count(*) |+--------+----------+----------+| 10 | MANAGER | 3 || 30 | SALESMAN | 6 || 20 | CLERK | 5 |+--------+----------+----------+3 rows in set (0.00 sec)
tidb>set sql_mode = 'STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,ONLY_FULL_GROUP_BY';Query OK, 0 rows affected (0.00 sec)
tidb>select DEPTNO, JOB, count(*) -> from EMP -> group by DEPTNO;ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'JOB' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
复制代码
窗口函数入门
现在,不妨再回头看一遍『准备环境』一节我们执行过的那个 SQL,请注意这一行:
count(*) over(partition by DEPTNO) as dept_cnt
复制代码
我们关于窗口函数基本语法的介绍就从这一行代码展开。
OVER 关键字
当 COUNT 函数后面跟着 OVER 关键字,行为就发生变化了:TiDB 会把它当做窗口函数,而不是聚合函数。我们熟悉的那些聚合函数几乎都可以后接 OVER 关键字,从而摇身一变成为窗口函数。
TiDB 还提供了一些非聚合窗口函数(Non-aggregate Window Function),比如ROW_NUMBER、RANK、LAG和LEAD。可以在这里 1找到 TiDB 支持的非聚合窗口函数列表。这里,我们来看一个非聚合窗口函数的例子。下列 SQL 调用ROW_NUMBER函数为员工自动编号:左数第一列是整个公司范围内的流水号,第二列则是部门内的流水号。这个 SQL 表明,ROW_NUMBER 会根据不同的数据窗口生成不同的流水号。
tidb>select -> ROW_NUMBER() over() as '#', -> ROW_NUMBER() over(partition by DEPTNO) as '##', -> ENAME, -> DEPTNO -> from EMP -> order by DEPTNO; +------+------+--------+--------+ | # | +------+------+--------+--------+ | 1 | 1 | CLARK | 10 | | 2 | 2 | KING | 10 | | 3 | 3 | MILLER | 10 | | 4 | 1 | FORD | 20 | | 5 | 2 | ADAMS | 20 | | 6 | 3 | JONES | 20 | | 7 | 4 | SCOTT | 20 | | 8 | 5 | SMITH | 20 | | 9 | 1 | MARTIN | 30 | | 10 | 2 | TURNER | 30 | | 11 | 3 | WARD | 30 | | 12 | 4 | JAMES | 30 | | 13 | 5 | ALLEN | 30 | | 14 | 6 | BLAKE | 30 | +------+------+--------+--------+ 14 rows in set (0.00 sec)
复制代码
何时执行?
基本上,窗口函数代码的执行会被放在一个 SELECT 语句执行过程的最后面,但会早于 ORDER BY 和 LIMIT 等决定最终结果集展示的部分。因此,在一个 SELECT 语句里,原始数据集经过 FROM、JOIN、WHERE 和 GROUP BY 过滤后才会传递给窗口函数做进一步的计算处理。
我们来看下面这个例子。相较于前一个 SQL,下述 SQL 增加了过滤条件DEPTNO = 10。这导致部门编号等于 20 和 30 的记录行被提前过滤掉了,因此最后只有三行记录被查出来,而前一个 SQL 的查询结果则含有 14 行结果。两相对比,不难看出 TiDB 会先执行 WHERE 条件,后执行窗口函数。
tidb>select -> ROW_NUMBER() over() as '#', -> ROW_NUMBER() over(partition by DEPTNO) as '##', -> ENAME, -> DEPTNO -> from EMP -> where DEPTNO = 10 -> order by DEPTNO; +------+------+--------+--------+ | # | ## | ENAME | DEPTNO | +------+------+--------+--------+ | 1 | 1 | CLARK | 10 | | 2 | 2 | KING | 10 | | 3 | 3 | MILLER | 10 | +------+------+--------+--------+ 3 rows in set (0.00 sec)
复制代码
最后不妨这样来总结一下:对于下面 SQL,通常的执行顺序会是FROM → JOIN → WHERE → GROUP BY → 窗口函数调用处理 → ORDER BY → LIMIT,窗口函数调用通常会被作为最后的部分来处理。
select ..., win_func() over(...), ... from t1 join t2 on ... where ... group by ... order by ... limit ...
复制代码
PARTITION BY 子句
PARTITION BY 子句本质上等同于 GROUP BY,它做的事情其实就是『分组』。在讲述窗口函数用法的书籍和文档中,『分组』和『分区』可以视为同义词;一个分组(分区)也可以被称作一个『窗口』,而操作这个『窗口』的函数就被称作『窗口函数』。『窗口函数』是 SQL 标准里规定的叫法,Oracle 中叫分析函数,DB2 则称之为 OLAP 函数。
上述count(*) over(partition by DEPTNO)的语义是先按照 DEPTNO 字段把记录集分组,然后计算每一组的记录行数。当然,OVER 后面的括号里也可以空着什么都不填:count(*) over(),这时整个记录集会被当做一个『大分组』来对待。
在一个 SQL 语句里,PARTITION BY 子句可以出现多次,并且每次用于分组的字段也可以不同。这样就做到了 GROUP BY 无法达成的事情:在一个 SELECT 语句里,以多种维度把数据分组并做不同的聚合计算处理; 并且,SELECT 后面可以出现任意列,不仅限于那些用于分组的列。
我们来看下面这个 SQL,它先按照 DEPTNO 字段分组,计算每个员工所在部门的人员总数;接着按照 JOB 字段再次分组,计算每个员工的职位(JOB)在整个公司内出现的次数。
tidb>select ENAME, -> DEPTNO, -> count(*) over(partition by DEPTNO) as dept_cnt, -> JOB, -> count(*) over(partition by JOB) as job_cnt -> from EMP -> order by DEPTNO, ENAME;+--------+--------+----------+-----------+---------+| ENAME | DEPTNO | dept_cnt | JOB | job_cnt |+--------+--------+----------+-----------+---------+| CLARK | 10 | 3 | MANAGER | 3 || KING | 10 | 3 | PRESIDENT | 1 || MILLER | 10 | 3 | CLERK | 4 || ADAMS | 20 | 5 | CLERK | 4 || FORD | 20 | 5 | ANALYST | 2 || JONES | 20 | 5 | MANAGER | 3 || SCOTT | 20 | 5 | ANALYST | 2 || SMITH | 20 | 5 | CLERK | 4 || ALLEN | 30 | 6 | SALESMAN | 4 || BLAKE | 30 | 6 | MANAGER | 3 || JAMES | 30 | 6 | CLERK | 4 || MARTIN | 30 | 6 | SALESMAN | 4 || TURNER | 30 | 6 | SALESMAN | 4 || WARD | 30 | 6 | SALESMAN | 4 |+--------+--------+----------+-----------+---------+14 rows in set (0.00 sec)
复制代码
两个 PARTITION BY 子句,两次维度不同的分组操作,他们相互独立,互不影响。想一想,如果不用窗口函数,我们该如何做到这一点呢? 我能想到两种替代方案:
tidb>select ENAME, -> DEPTNO, -> (select count(*) from EMP t1 where t1.DEPTNO = t.DEPTNO) as dept_cnt, -> JOB, -> (select count(*) from EMP t2 where t2.JOB = t.JOB) as job_cnt -> from EMP t -> order by DEPTNO, ENAME;+--------+--------+----------+-----------+---------+| ENAME | DEPTNO | dept_cnt | JOB | job_cnt |+--------+--------+----------+-----------+---------+| CLARK | 10 | 3 | MANAGER | 3 || KING | 10 | 3 | PRESIDENT | 1 || MILLER | 10 | 3 | CLERK | 4 || ADAMS | 20 | 5 | CLERK | 4 || FORD | 20 | 5 | ANALYST | 2 || JONES | 20 | 5 | MANAGER | 3 || SCOTT | 20 | 5 | ANALYST | 2 || SMITH | 20 | 5 | CLERK | 4 || ALLEN | 30 | 6 | SALESMAN | 4 || BLAKE | 30 | 6 | MANAGER | 3 || JAMES | 30 | 6 | CLERK | 4 || MARTIN | 30 | 6 | SALESMAN | 4 || TURNER | 30 | 6 | SALESMAN | 4 || WARD | 30 | 6 | SALESMAN | 4 |+--------+--------+----------+-----------+---------+14 rows in set (0.00 sec)
复制代码
tidb>select t.ENAME, -> t.DEPTNO, -> t1.dept_cnt, -> t.JOB, -> t2.job_cnt -> from EMP t -> left join (select DEPTNO, count(*) as dept_cnt from EMP group by DEPTNO) t1 on t1.DEPTNO = t.DEPTNO -> left join (select JOB, count(*) as job_cnt from EMP group by JOB) t2 on t2.JOB = t.JOB -> order by t.DEPTNO, t.ENAME;+--------+--------+----------+-----------+---------+| ENAME | DEPTNO | dept_cnt | JOB | job_cnt |+--------+--------+----------+-----------+---------+| CLARK | 10 | 3 | MANAGER | 3 || KING | 10 | 3 | PRESIDENT | 1 || MILLER | 10 | 3 | CLERK | 4 || ADAMS | 20 | 5 | CLERK | 4 || FORD | 20 | 5 | ANALYST | 2 || JONES | 20 | 5 | MANAGER | 3 || SCOTT | 20 | 5 | ANALYST | 2 || SMITH | 20 | 5 | CLERK | 4 || ALLEN | 30 | 6 | SALESMAN | 4 || BLAKE | 30 | 6 | MANAGER | 3 || JAMES | 30 | 6 | CLERK | 4 || MARTIN | 30 | 6 | SALESMAN | 4 || TURNER | 30 | 6 | SALESMAN | 4 || WARD | 30 | 6 | SALESMAN | 4 |+--------+--------+----------+-----------+---------+14 rows in set (0.01 sec)
复制代码
PARTITION BY 子句对于 NULL 的处理方式,和 GROUP BY 有异曲同工之处。我们来看下面这个例子:
tidb>select ENAME, -> COMM, -> coalesce(COMM, -1) as comm_value, -> count(*) over(partition by COMM) as cnt1, -> count(COMM) over(partition by COMM) as cnt2 -> from EMP; +--------+------+------------+------+------+ | ENAME | COMM | comm_value | cnt1 | cnt2 | +--------+------+------------+------+------+ | KING | NULL | -1 | 10 | 0 | | FORD | NULL | -1 | 10 | 0 | | JAMES | NULL | -1 | 10 | 0 | | JONES | NULL | -1 | 10 | 0 | | ADAMS | NULL | -1 | 10 | 0 | | BLAKE | NULL | -1 | 10 | 0 | | CLARK | NULL | -1 | 10 | 0 | | SCOTT | NULL | -1 | 10 | 0 | | SMITH | NULL | -1 | 10 | 0 | | MILLER | NULL | -1 | 10 | 0 | | TURNER | 0 | 0 | 1 | 1 | | ALLEN | 300 | 300 | 1 | 1 | | WARD | 500 | 500 | 1 | 1 | | MARTIN | 1400 | 1400 | 1 | 1 | +--------+------+------------+------+------+ 14 rows in set (0.00 sec)
复制代码
count(*) over(partition by COMM) as cnt1仍然针对 COUNT(*)做了特殊化处理,把符合COMM IS NULL条件的记录行都划归进一组,因此结果集的前十行cnt1 = 10。
count(COMM) over(partition by COMM) as cnt2 则视 NULL 为无物,前十行cnt2都是 0。
NULL 是易燃易爆品,每一个使用 SQL 编程的程序员都应该警惕这个坑,务必小心在意,徐徐绕行;每一个 DBA 在做 SQL 审核的时候都要时刻提着一把锤子,把一根名为NOT NULL的铁钉尽可能钉在每个字段定义的后面。
现在, 不妨回头再看一遍『SQL分组操作』一节着重提过的几个要点,是不是对『窗口函数是更为高级的 SQL 分组操作』这句话多了点一手体验?其实,窗口函数可以做到更多。
ORDER BY 和 Frame 子句
在 OVER 子句里可以嵌入 ORDER BY,从而实现一种『滚动累加』(Running Total)效果。我们先来看一个 SQL:
tidb>select DEPTNO, -> ENAME, -> HIREDATE, -> SAL, -> sum(SAL) over(order by HIREDATE) as running_total -> from EMP -> where DEPTNO = 10 -> ; +--------+--------+------------+------+---------------+ | DEPTNO | ENAME | HIREDATE | SAL | running_total | +--------+--------+------------+------+---------------+ | 10 | CLARK | 1981-06-09 | 2450 | 2450 | | 10 | KING | 1981-11-17 | 5000 | 7450 | | 10 | MILLER | 1982-01-23 | 1300 | 8750 | +--------+--------+------------+------+---------------+ 3 rows in set (0.00 sec)
复制代码
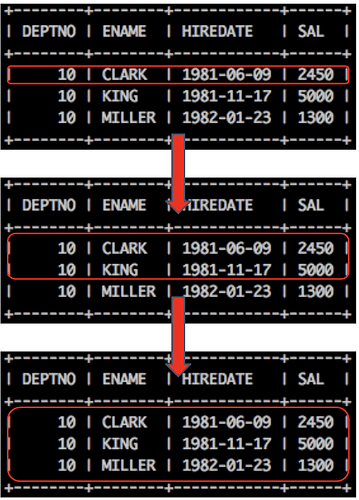
猜一下上述结果集里 running_total 列究竟是怎么算出来的?其实是这么来的:
结合下图来看会更容易理解一些:
我们可以描述一下sum(SAL) over(order by HIREDATE) as running_total的处理过程:先按照 HIREDATE 字段排序,然后针对每一行数据算出来『从第一行到当前行 SAL 的加和』。换句话说,每一行计算结果的产生过程都是这样的:先确定一个『滑动的数据窗口』,第一次仅包含第一行数据,第二次包含前两行,第三次则是前三行;然后针对该数据窗口计算 SUM(SAL)。
一句简单的order by HIREDATE就代表了这么复杂的操作,是不是也太晦涩难懂了?这和 SQL 直来直去的语言风格严重不符啊?你说得对!其实order by HIREDATE只是一种省略形式,完整写法是这样的:
tidb>select DEPTNO, -> ENAME, -> HIREDATE, -> SAL, -> sum(SAL) over(ORDER BY HIREDATE -> RANGE BETWEEN UNBOUNDED PRECEDING -> AND CURRENT ROW) as running_total -> from EMP -> where DEPTNO = 10; +--------+--------+------------+------+---------------+ | DEPTNO | ENAME | HIREDATE | SAL | running_total | +--------+--------+------------+------+---------------+ | 10 | CLARK | 1981-06-09 | 2450 | 2450 | | 10 | KING | 1981-11-17 | 5000 | 7450 | | 10 | MILLER | 1982-01-23 | 1300 | 8750 | +--------+--------+------------+------+---------------+ 3 rows in set (0.00 sec)
复制代码
注意观察加粗的部分:
ORDER BY HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
复制代码
跟随在 OVER 关键字后面的ORDER BY配合RANGE BETWEEN语法(或者另一种ROW BETWEEN语法)被称作 Frame子句 1。它的作用是在窗口函数执行过程中临时确定一个滑动的数据窗口,并在此窗口之上施行运算(使用聚合窗口函数或者非聚合窗口函数)。简单来讲,Frame 子句会决定两件事:
在滑动的数据窗口形成之前,决定数据如何排序。ORDER BY HIREDATE即是把数据按照HIREDATE字段升序排列(默认排序方式为ASC)。
在每一次运算过程中,确定当前数据窗口的起止边界。RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW的意思是『从最上面的一行到当前行(包括当前行)』。TiDB提供了一些表达式和关键字 1帮助我们灵活指定窗口范围:
UNBOUNDED PRECEDING:最上面一行
UNBOUNDED FOLLOWING:最下面一行
CURRENT ROW:当前行
<em>n</em> PRECEDING:当前行往上数<em>n</em>行
<em>n</em> FOLLOWING:当前行往下数<em>n</em>行
下面这个例子展示了上述语法:
tidb>select DEPTNO, -> ENAME, -> SAL, -> sum(SAL) over(partition by DEPTNO) as total1, -> sum(SAL) over() as total2, -> sum(SAL) over(order by HIREDATE -> range between unbounded preceding -> and current row) as running_total1, -> sum(SAL) over(order by HIREDATE -> rows between 1 preceding -> and current row) as running_total2, -> sum(SAL) over(order by HIREDATE -> range between current row -> and unbounded following) as running_total3, -> sum(SAL) over(order by HIREDATE -> rows between current row -> and 1 following) as running_total4 -> from EMP -> where DEPTNO = 10;+--------+--------+------+--------+--------+----------------+----------------+----------------+----------------+| DEPTNO | ENAME | SAL | total1 | total2 | running_total1 | running_total2 | running_total3 | running_total4 |+--------+--------+------+--------+--------+----------------+----------------+----------------+----------------+| 10 | CLARK | 2450 | 8750 | 8750 | 2450 | 2450 | 8750 | 7450 || 10 | KING | 5000 | 8750 | 8750 | 7450 | 7450 | 6300 | 6300 || 10 | MILLER | 1300 | 8750 | 8750 | 8750 | 6300 | 1300 | 1300 |+--------+--------+------+--------+--------+----------------+----------------+----------------+----------------+3 rows in set (0.01 sec)
复制代码
命名窗口
命名窗口(Named Window)其实是一种语法糖,用于简化窗口函数代码的写法。我们先来看一个例子:
tidb>SELECT -> ENAME, -> DEPTNO, -> row_number() over (partition by DEPTNO) AS 'row_number', -> rank() over (partition by DEPTNO) AS 'rank', -> dense_rank() over (partition by DEPTNO) AS 'dense_rank' -> FROM EMP; +--------+--------+------------+------+------------+ | ENAME | DEPTNO | row_number | rank | dense_rank | +--------+--------+------------+------+------------+ | CLARK | 10 | 1 | 1 | 1 | | KING | 10 | 2 | 1 | 1 | | MILLER | 10 | 3 | 1 | 1 | | FORD | 20 | 1 | 1 | 1 | | ADAMS | 20 | 2 | 1 | 1 | | JONES | 20 | 3 | 1 | 1 | | SCOTT | 20 | 4 | 1 | 1 | | SMITH | 20 | 5 | 1 | 1 | | MARTIN | 30 | 1 | 1 | 1 | | TURNER | 30 | 2 | 1 | 1 | | WARD | 30 | 3 | 1 | 1 | | JAMES | 30 | 4 | 1 | 1 | | ALLEN | 30 | 5 | 1 | 1 | | BLAKE | 30 | 6 | 1 | 1 | +--------+--------+------------+------+------------+ 14 rows in set (0.00 sec)
复制代码
上述 SQL 中出现了三处partition by DEPTNO,略显冗长。我们可以这样来改写:
tidb>SELECT -> ENAME, -> DEPTNO, -> row_number() over w as 'row_number', -> rank() over w as 'rank', -> dense_rank() over w as 'dense_rank' -> FROM EMP -> window w as (partition by DEPTNO); +--------+--------+------------+------+------------+ | ENAME | DEPTNO | row_number | rank | dense_rank | +--------+--------+------------+------+------------+ | CLARK | 10 | 1 | 1 | 1 | | KING | 10 | 2 | 1 | 1 | | MILLER | 10 | 3 | 1 | 1 | | FORD | 20 | 1 | 1 | 1 | | ADAMS | 20 | 2 | 1 | 1 | | JONES | 20 | 3 | 1 | 1 | | SCOTT | 20 | 4 | 1 | 1 | | SMITH | 20 | 5 | 1 | 1 | | MARTIN | 30 | 1 | 1 | 1 | | TURNER | 30 | 2 | 1 | 1 | | WARD | 30 | 3 | 1 | 1 | | JAMES | 30 | 4 | 1 | 1 | | ALLEN | 30 | 5 | 1 | 1 | | BLAKE | 30 | 6 | 1 | 1 | +--------+--------+------------+------+------------+ 14 rows in set (0.00 sec)
复制代码
总结
我们在 TiDB 3.0 上运行了一些窗口函数 SQL,主要涉及如下语法元素:
窗口函数, 包括聚合窗口函数(如COUNT和SUM)和非聚合窗口函数(如ROW_NUMBER和RANK)
OVER子句
PARTITION BY子句
ORDER BY子句和Frame子句,包括RANGE BETWEEN和ROWS BETWEEN语法
命名窗口
TiDB 3.0 实现了和 MySQL 8.0 相兼容的窗口函数语法,这有助于程序员写出更加现代化的 SQL 代码(相比于 SQL92 标准)。有了窗口函数,我们有望在不包含子查询的单一 SELECT 语句里轻松实现多维度分组操作,在返回结果中也能做到同时呈现明细列和聚合计算结果列。这些都是传统 GROUP BY 语法无法胜任的。除此之外,在执行代价和性能层面,窗口函数相较于传统做法无疑有着更大的优势。
囿于篇幅,本文没有对具体的窗口函数用法做更多展开。例如,RANK、LEAD和LAST_VALUE等非聚合窗口函数其实有着更加细微有趣且变化繁多的使用技巧,从事报表和数据分析任务的程序员若能熟练掌握则可事半功倍。
致谢
本文多处 SQL 代码示例出自《SQL 经典实例》一书的附录 A 『窗口函数简介』,行文思路也多有借鉴。该书的附录 A 用了二十多页篇幅对窗口函数的基本概念和用法做了言简意赅的介绍。从个人经验而言,这篇附录大概算得上关于窗口函数最为精炼的入门材料了。读者若有兴趣,不妨移步该书官方主页 3下载附录 A 的内容。感谢图灵社免费开放了该章节的下载。
作者介绍:
刘春辉,Sea Group DBA,TiDB User Group (TUG) 大使。
本文转载自 AskTUG。
原文链接:
https://asktug.com/t/tidb-3-0/348











评论