

人生病了要去看医生,程序生病了看的就是运维工程师了。医生给病人看病要做很多检查,然后拿着结果单子分析病因。运维工程师分析系统故障也会查看采集的监控指标,然后判断根因是什么。
查看指标这事儿,说起来也不难。只要画出指标的趋势图(指标值随时间变化的曲线),有经验的工程师很容易就能看出有没有毛病,进而推断故障的原因。不过呢,都说脱离开剂量说食物的毒性是耍流氓,查看指标这事也差不多。如果只有几条指标需要查看,做个仪表盘就能一目了然,可是如果有成千上万的指标呢?人家查抄大老虎的时候点钞机都烧坏了好几台,如果人工查看这么多指标,脑子的下场估计也好不到哪儿去。所以说还是得靠“机器人”。
等等,“机器人”怎么能知道什么指标有毛病,什么指标没毛病呢?就算能知道,把有毛病的指标挑出来工程师凭啥就能知道根因呢?所以,我们的“机器人医生”必须能够识别出指标的异常,然后还需要能把识别出的异常整理成工程师容易理解的报告才行。
传统的办法
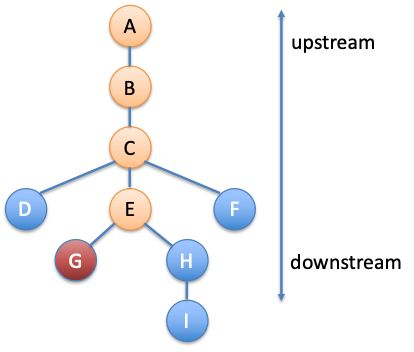
图 1 模块调用关系图
人工诊断故障的时候,工程师往往是根据脑子里的模块调用关系图(图 1)来排查系统。很多时候,故障都是因为在最上游的前端模块(图 1 中的 A)上看到了很多失败的请求发现的。这时,工程师就会沿着 A 往下查。因为 A 调用了 B 模块,所以需要查看 B 的指标,如果有指标异常那么就怀疑是 B 导致了故障。然后再检查 B 的直接下游模块 C,以此类推。在这个过程中,怀疑通过模块的调用关系不断往下传递,直到传不下去为止。在图 1 的例子中怀疑最后就停在了倒霉蛋 G 的头上,谁让它没有下游模块呢。
总的来说,这就是模块间把责任想办法往下游推的过程。当然,真实的场景要更加复杂一些。并不是只要下游有异常就可以推的,还需要考察异常的程度。比如,如果倒霉蛋 G 的异常程度比 E 的异常程度小很多,根因就更有可能在 E 里面。
找到了根因模块再去分析根因就容易多了,所以寻找根因模块是故障诊断中很重要的步骤。
上面的过程可以很直接地变成一个工具:
做一个页面展示模块调用关系图
工程师为每个指标配置黄金指标,以及黄金指标的阈值
在模块图中标出黄金指标有异常的模块以及它们到达前端模块的可能路径
这个工具通过配置黄金指标及阈值的方式解决了指标以及如何判断异常的问题,然后再通过模块调用关系图的方式呈现异常判断的结果,解决了异常判断和结果整理这两个核心问题。
不过,传统的办法在实际使用中还是会碰到很多问题:
1.活的系统一定是不断演化的,模块的调用关系也随之发生改变。为了保证工具里面的关系图不会过时,就需要不断从真实系统同步。干过系统梳理这种活的工程师都知道,这可不容易。如果整个系统使用统一的 RPC 中间件在模块中通讯,那就可以通过分析 RPC trace log 的方式挖掘出调用关系图来,不过“历史代码”通常会趴在路中间拦着你。
2.每个黄金指标通常只能覆盖一部分的故障类型,新的故障一出现,就需要增加黄金指标。这样一来配置工作——尤其是阈值的配置——就会不断出现。另外,指标多了,就很容易出现“全国山河一片红”的情况。大多数的模块都被标出来的时候,工具也就没啥用了。
3.大型的系统为了保证性能和可用性,常常需要在好几个机房中部署镜像系统。因为大多数的故障只发生在一个机房的系统中,所以工程师不但需要知道根因模块是谁,还需要知道在哪个机房。这样一来,每个机房都得有一个调用关系图,工程师得一个一个地看。
理想的效果
传统的方法作出来的诊断工具最多也就是半自动的,应用起来也受到很多的限制,所以我们就想做一个真正全自动、智能化的工具。
首先,我们希望新工具不要过于依赖于黄金指标,这样指标的配置工作就能减少。但是,这反过来说明全自动的工具必须能够扫描所有模块上的所有指标,这样才能做到没有遗漏。所以,异常判断不能再通过人工设置阈值的方式来进行,而必须是基本上无监督的(Unsupervised)。另外,不同指标的语意有很大差异,异常判断的算法也必须足够灵活,以适应不同指标的特点。
其次,我们希望工具不要太过依赖于调用关系图,这意味着我们需要寻找一种新的方式来整理和呈现结果。其实,调用关系图并不是必须的。在使用传统诊断方法时,我们就发现一部分工程师经常脱离调用关系图,直接按照黄金指标的异常程度从大到小检查模块。这是因为这部分工程师负责的系统黄金指标代表性强、容易理解,更重要的是不同模块黄金指标的异常程度可以比较。
所以说,我们完全可以做一个诊断工具来产出根因模块的推荐报告,报告的内容必须易于理解,推荐的顺序也必须足够准确。
实例指标的自动排查分析
我们以实例指标为例,介绍如何实现一个指标排查工具,达成理想的效果。排查工具的总体流程如图 2 所示。
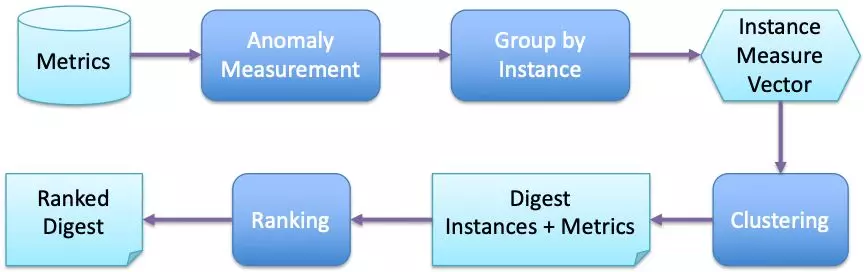
图 2 实例指标自动排查的总体流程
在第一步,所有被收集来的指标都会通过异常检测算法赋予它们一个异常分数。比较两个指标的异常分数就能够知道它们的异常程度谁大谁小了。这一步的核心是要寻找一个方法能够量化地衡量每个指标的异常,而且这个量化衡量出来的分数还可以在不同实例的不同指标之间比较。
第二步,我们把异常分数按照它们所属的实例分组,每组形成一个向量(vector)。这时,每个实例都会对应一个向量,向量中的每个元素就是一个指标的异常分数。然后,模式(pattern)差不多的向量就可以通过聚类(clustering)算法聚成若干个摘要(digest)。这样一来,工程师们就容易理解分析的结果了。
第三步,我们可以根据摘要中包含的实例以及指标的异常分数排序(ranking),形成推荐报告。
总结
本文介绍了一种在服务发生故障时自动排查监控指标的工具,第一步利用了概率统计的方式估算每个指标的异常分数,第二步用聚类的方式把异常模式相近的实例聚集在一起形成摘要,第三步用 ranking 的方式向工程师推荐最有可能是根因的摘要。
由于运维场景的特点是数据量大,但是标定很少,生成标定的代价高昂而且容易出错,接下来我们会详细介绍如何利用概率统计、非监督学习和监督学习的方法来解决这个问题,敬请期待吧~
作者介绍:
运筹,百度资深数据架构师,负责百度智能运维算法和策略的研究工作,致力于用算法和数据的力量解决运维问题。
本文转载自公众号 AIOps 智能运维(ID:AI_Ops)。
原文链接:
https://mp.weixin.qq.com/s/_qNXA_XDhgwpEYjrJFjz1g

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论