

一般来讲,用 PyTorch 处理自然语言比较繁琐。于是,国外一位开发者 Yasufumi TANIGUCHI 开发了 LineFlow,为了尽可能减轻编码的痛苦,并保证完成同样的任务。Yasufumi TANIGUCHI 表示,LineFlow 要比 PyTorch 简洁数倍,让我们来看看 LineFlow 究竟能简洁到什么地步?
对自然语言处理任务来说,你可能需要在预处理中对文本进行词法分析或构建词汇表。因为这个过程非常痛苦,所以我创建了LineFlow ,尽可能让整个过程干净整洁。真正的代码看起来是什么样子?请看下面的图,预处理包括词法分析、词汇表构建和索引。
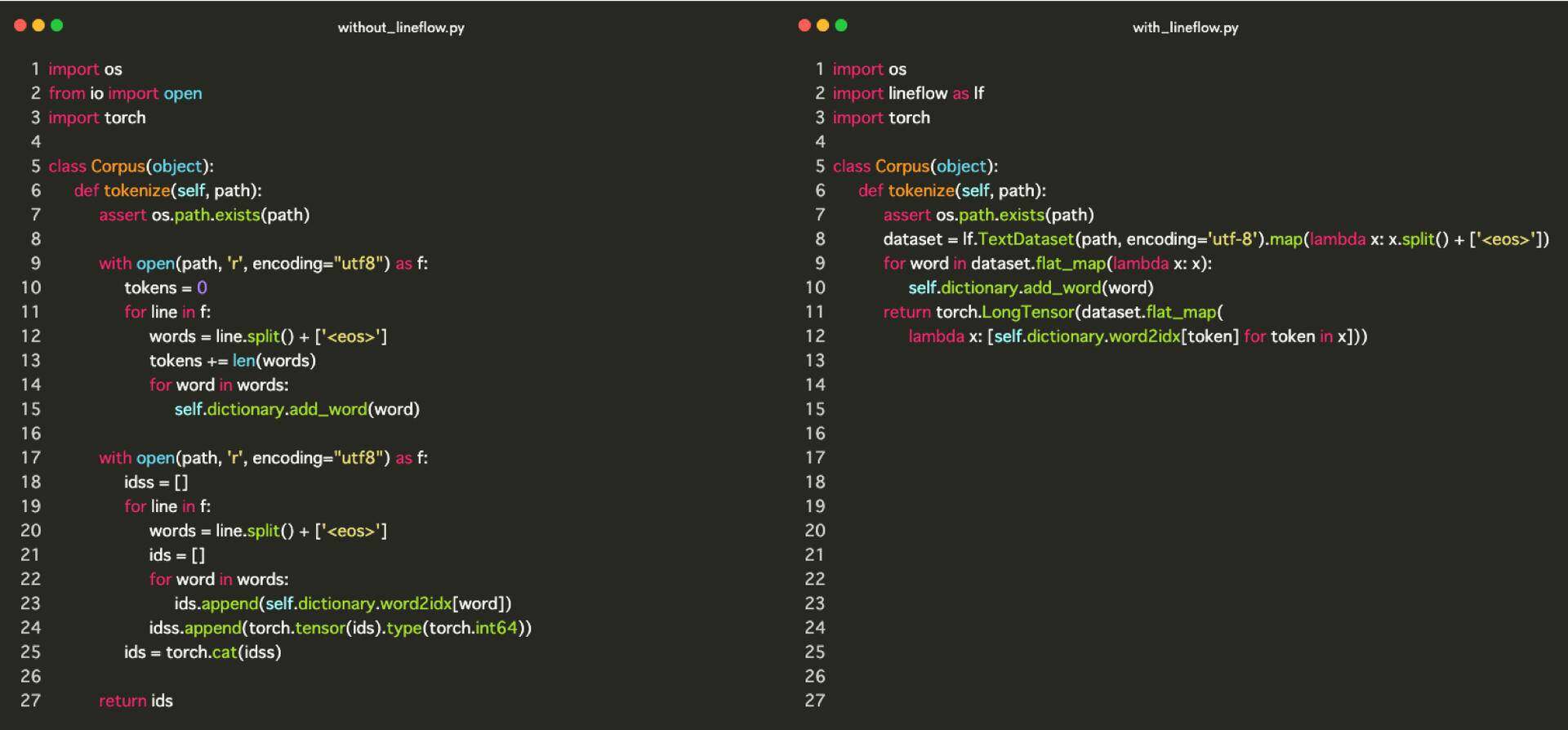
左边部分是来自 PyTorch 官方示例仓库的示例代码,它对文本数据进行常见的预处理。右边部分是用 LineFolw 编写的,实现了完全相同的处理。看完对比之后,你应该明白 LineFlow 是如何减轻痛苦的。要查看完整的代码,可以访问此链接。
在本文中,我将详细解释上图右边部分的代码,并讲解 LineFlow 的用法。
加载文本数据
文本数据的加载,是通过上面代码中的第 8 行完成的,我稍后会详细解释这个 map。lf.TextDataset 将文本文件的路径作为参数并进行加载。
lf.TextDataset 要求的数据格式是每行对应一个数据。如果文本数据满足此条件,则可以加载任何类型的文本数据。


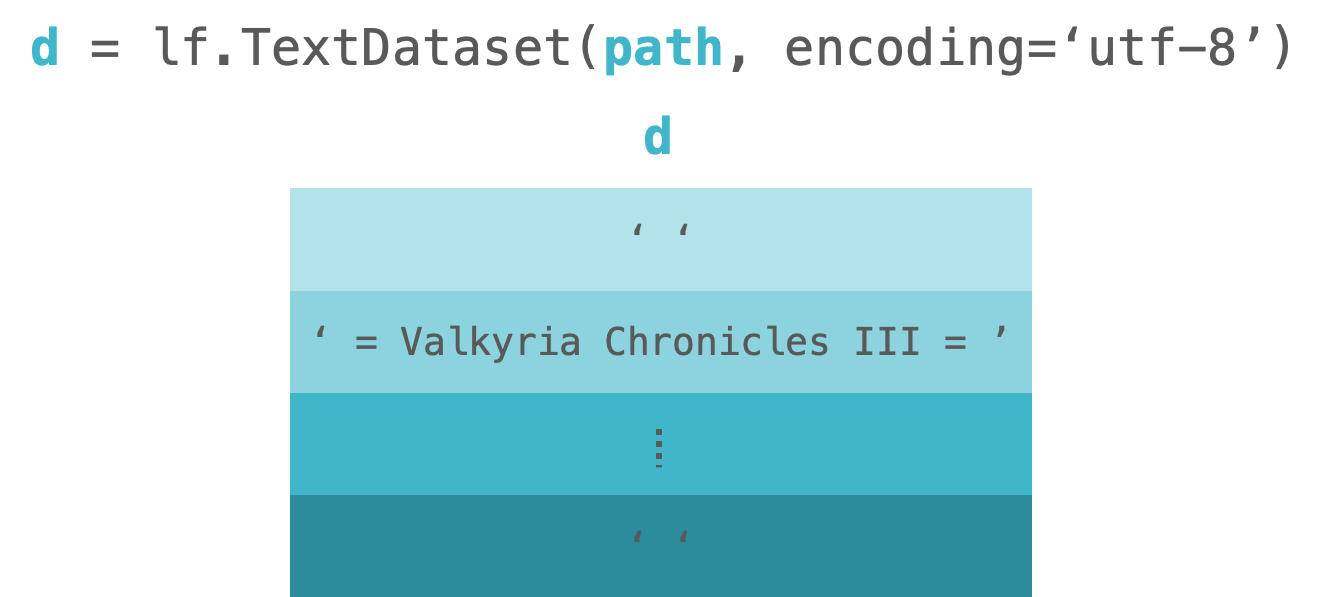
加载之后,它将文本数据转换为列表。列表中的项对应于文本数据中的行。 请看下图,这是 lf.TextDataset 的直观图像。图中的 d 代表代码中的 dataset。
LineFlow 已经提供了一些公开可用的数据集。所以你可以马上使用它。要查看提供的数据集,请访问此链接。
2. 标记化
文本标记化也是通过第 8 行完成的。map将作为参数传递的处理应用到文本数据的每一行。
请看下图。这是 lf.TextDataset.map 的直观图像。图中的 d 代表代码中的 dataset。
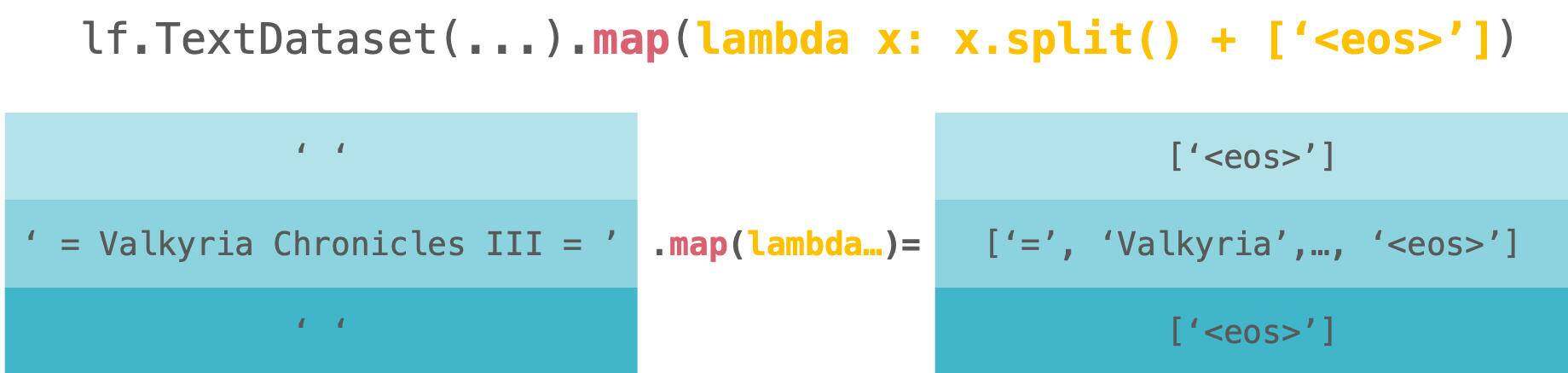
让我们深入了解下面的实际处理过程。
我们将文本数据中的每一行按空格拆分为标记,然后将 <eos>添加到这些标记的末尾。我们遵循 WikiText 官方页面上的处理方式。
此时,我们使用 str.split 进行标记化。我们可以使用其他的标记化方法,如 spaCy、StanfordNLP、Bling Fire 等。例如,如果你想使用 Bling Fire,我们将得到以下代码。
另外,只要我们的处理将每行文本数据作为参数,就可以执行任何我们想要的处理。例如,我们可以计算标记的数量。在下面的代码中,标记的数量是在第二个元素中定义的。
当我们想要制作用于注意力机制或长短期记忆网络的掩码时,这种处理就很有用。
3. 索引
索引是由第 9 行到第 12 行完成的。这些行如下图所示。在这个代码块中,我们构建了词汇表和索引。让我们按顺序来查看这些内容。
首先我们将看到构建词汇表的代码块。在下面的代码块中,我们构建了词汇表。 flat_map 将作为参数传递的处理应用于数据中的每一行,然后对其进行扁平化。因此,我们将在 dataset.flat_map(lambda x: x) 之后获取单个标记。
请看下图。这是 dataset.flat_map(lambda x: x) 的直观图像。图中的 d 代表代码中的 'dataset`。

flat_map 有点令人困惑,但它等同于下面的代码。
在使用 flat_map 提取每个标记之后,我们将标记传递给 self.dictionary.add_word 来构建词汇表。我将不会解释它是如何工作的,因为这与本文无关。但如果你对它的内部实现感兴趣的话,请查看此链接。
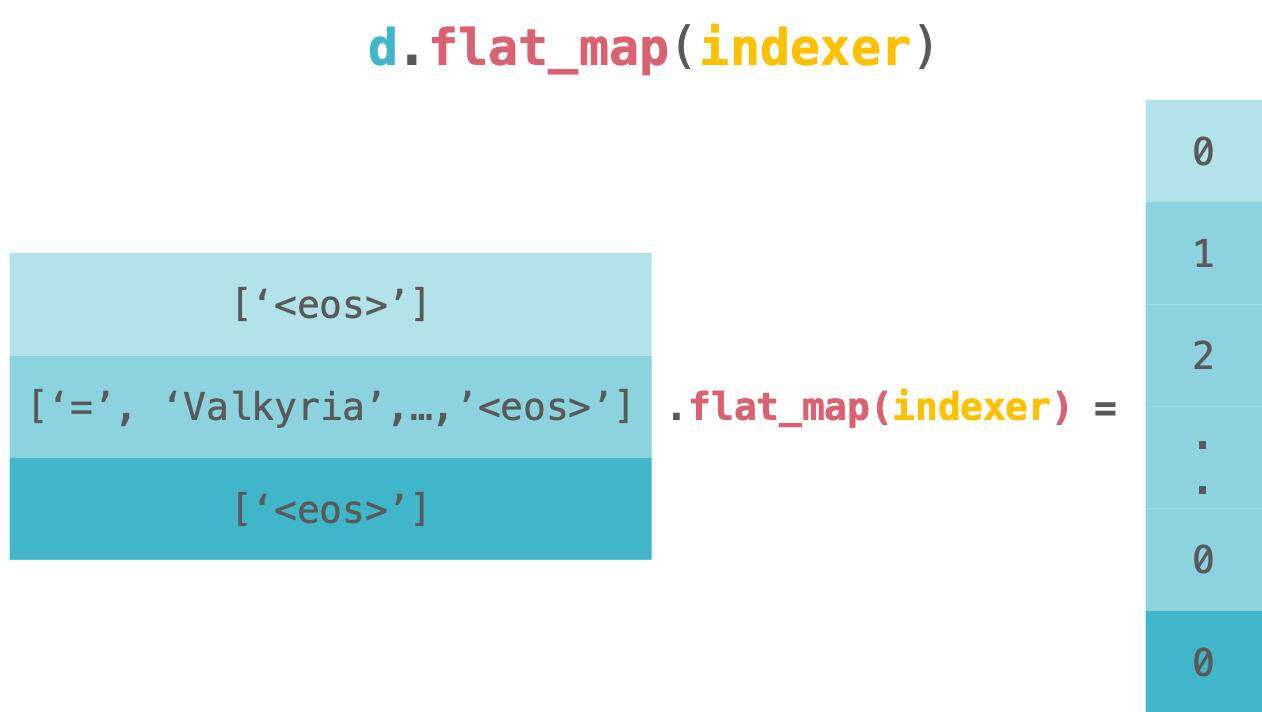
接下来,我们将看到索引的代码块。索引是由一下的代码块来完成的。我们还使用 flat_map 来索引每个标记并使其扁平化。这是因为 PyTorch 的示例需要扁平化标记的张量,所以我们就这么做了。
请看下图。这是 dataset.flat_map(indexer) 的直观图像。图中的 d 代表代码中的 dataset。
此代码等同于以下代码。
最后,我们用 torch.LongTensor 将它包起来,把它变成张量。至此就完成了文本数据的加载。
现在我们可以阅读完整的代码了,如下所示:
这就是全部的解释。LineFlow 通过对文本数据进行向量化来完成较少的循环和嵌套代码。我们可以使用 Python 的 map 来完成同样的工作。但是,LineFlow 为我们提供了可读的、干净的代码,因为它像管道(Fluent Interface)一样构建了处理过程。
如果你喜欢 LineFlow,并想了解更多信息,请访问 LineFlow 在 GitHub 的仓库。
作者介绍:
Yasufumi TANIGUCHI,软件工程师,对自然语言处理有着浓厚的兴趣。本文最初发表于 Medium 博客,经原作者 Yasufumi TANIGUCHI 授权,InfoQ 中文站翻译并分享。
原文链接:
https://towardsdatascience.com/lineflow-introduction-1caf7851125e

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论