

近年来人工智能的浪潮越来越汹涌,以神经网络、集成模型为代表的机器学习模型在数据挖掘领域中发挥着不可替代的作用。在追求模型高精度的道路上,工业界和学术界也十分关注模型的可解释性,期待从复杂模型中得到更直观的理解。可解释机器学习作为索信达 AI 创新中心的重要研究方向之一,包括了内在可解释模型和事后可解释方法。我们希望可以通过一系列文章来介绍解释不同模型的方法,并分享与实际场景相结合的业务与技术心得。
1.Shapley Value
在当今的金融、医疗等数据挖掘的应用领域中,模型的可解释性和精度是同等的重要。众所周知,精度较高的模型,如集成模型,深度学习模型等,内部结构复杂多变,不能直观理解。SHAP,作为一种经典的事后解释框架,可以对每一个样本中的每一个特征变量,计算出其重要性值,达到解释的效果。该值在 SHAP 中被专门称为 Shapley Value。因此 Shapley Value 是 SHAP 方法的核心所在,理解好该值背后的含义将大大有助于我们理解 SHAP 的思想。
1.1 Shapley value 起源
Shapley value 最早由加州大学洛杉矶分校(UCLA)的教授 Lloyd Shapley 提出, 主要是用来解决合作博弈论中的分配均衡问题。Lloyd Shapley 是 2012 年的诺贝尔经济学奖获得者,也是博弈论领域的无冕之王。
我们已有的数据集中会包含很多特征变量,从博弈论的角度,可以把每一个特征变量当成一个玩家。用该数据集去训练模型得到的预测结果, 可以看成众多玩家合作完成一个项目的收益。Shapley value, 通过考虑各个玩家做出的贡献,来公平地分配合作的收益。
1.2 Shapley value 计算
可以通过一个小例子来看如何计算 Shapley Value。
假设:合作项目 Proj=<Players, v>
Players={1,2,…n}, 每个玩家在这个项目中所做的贡献量的特征方程是 v。
定义 Proj=500 行代码,由 3 个程序员完成,这就对应 3 个玩家:1,2,3。
每个玩家可以独立完成的代码:, ,
如果合作:,, , 。
具体的合作过程有 6 种情况:
玩家 1 邀请玩家 2, 玩家 2 接着邀请玩家 3;
玩家 1 邀请玩家 3, 玩家 3 接着邀请玩家 2;
玩家 2 邀请玩家 1, 玩家 1 接着邀请玩家 3;
玩家 2 邀请玩家 3, 玩家 3 接着邀请玩家 1;
玩家 3 邀请玩家 1, 玩家 1 接着邀请玩家 2;
玩家 3 邀请玩家 2, 玩家 2 接着邀请玩家 1;
用图来表示:
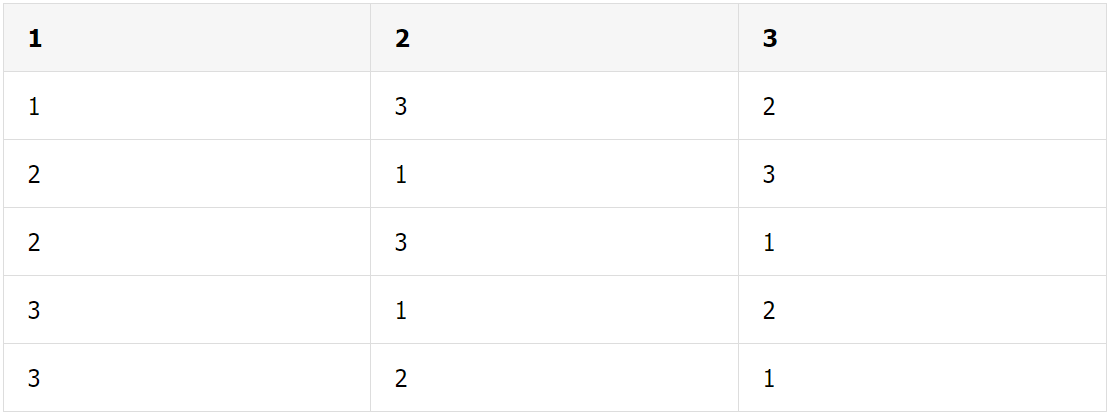
如果我们要合理分配,是否公平主要看边际贡献。
先定义第 i 个玩家加入组织 S 的边际贡献
挑选第一种情况为例:
玩家 1 边际贡献:
玩家 2 边际贡献:
玩家 3 边际贡献:
按照上面的计算过程,依次计算剩下的 5 种情况。同时考虑到这 6 种情况是等概率出现的。完整结果如下图:
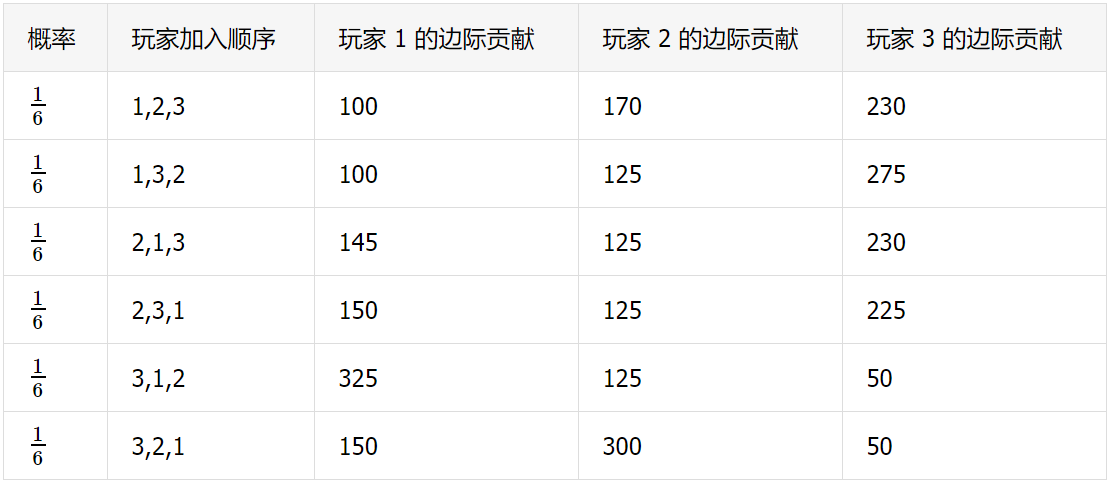
计算第 i 个玩家的 Shapley Value, 主要是由上图的边际贡献得到。

所以按照比例来分配奖金:
玩家 1 分配的奖金为总奖金的 32.3%
玩家 2 分配的奖金为总奖金的 32.3%
玩家 3 分配的奖金为总奖金的 35.3%
2. SHAP 原理
SHAP 全称是 SHapley Additive exPlanation, 属于模型事后解释的方法,可以对复杂机器学习模型进行解释。虽然来源于博弈论,但只是以该思想作为载体。在进行局部解释时,SHAP 的核心是计算其中每个特征变量的 Shapley Value。
SHapley:代表对每个样本中的每一个特征变量,都计算出它的 Shapley Value。
Additive:代表对每一个样本而言,特征变量对应的 shapley value 是可加的。
exPlanation:代表对单个样本的解释,即每个特征变量是如何影响模型的预测值。
当我们进行模型的 SHAP 事后解释时,我们需要明确标记。已知数据集(设有 M 个特征变量,n 个样本),原始模型 f,以及原始模型 f 在数据集上的所有预测值。g 是 SHAP 中用来解释 f 的模型。
先用 f 对数据集进行预测,得到模型预测值的平均值。单个样本表示为,为在原始模型下的预测值。 是事后解释模型的预测值,满足。其中代表第 i 个特征变量的 Shapley Value,是 SHAP 中的核心要计算的值,需要满足唯一性。同时上述模型 g 需要满足如下的性质:
性质 1:局部保真性 (local accuracy)
即两个模型得到的预测值相等。当输入单个样本到模型 g 中时,得到的预测值与原始模型得到的预测值相等。
性质 2:缺失性(missingness)
如果在单个样本中存在缺失值,即某一特征变量下没有取值,对模型 g 没有影响,其 Shapley Value 为 0。
性质 3:连续性(consistency)
当复杂模型 f 从随机森林变为 XGBoost,如果一个特征变量对模型预测值的贡献增多,其 Shapley value 也会随之增加。
在上述 3 个限制条件下,可以理论证明求出唯一的,即对应的模型 g 也是独一无二的。具体证明可参考 Shapley’s paper (1953).。
N={1,2…M}代表数据集中特征变量下标,1 代表第一个特征变量,以此类推,i 是第 i 个特征变量,M 是特征变量的总个数。S 是集合{1,2…i-1,i,…M}的子集,有种可能。是 S 中的元素的总个数。代表当样本中只有中的特征变量值时,模型的预测值。代表当样本中只有中的特征变量值时,模型的预测值。二者相减,可当成第 i 个特征变量在子集 S 下的边际贡献。前面的权重(kernel): 是根据排列组合的公式得到, 代表有相同元素个数的 S 存在的概率。
3. SHAP 分类
就是众所周知的第 i 个特征变量的 Shapley Value。SHAP 的核心是计算这个理论的 Shapely Value,如果直接计算,由于特征子集的多种可能,上述计算方式的时间复杂度是指数级的。因此围绕着如何计算 Shapley Value,我们根据对 Shapley Value 计算的两种近似方法将 SHAP 分为两大类。
3.1 Model-agnostic 近似
Kernel SHAP
该方法借用 LIME 方法(详情请见可解释机器学系列文章第二篇)来估计出解释模型 g 中的,属于 model-agnostic 的方法。Linear LIME 是指使用线性模型来近似原始复杂模型 f。从模型的构成来看,Linear LIME 拟合的回归模型与 SHAP 模型一脉相承,满足特征的可加性。
设定好 LIME 中的正则化参数,加权的核函数以及损失函数进行设定。设定模型复杂度设为 0,加权核函数,损失函数。x 是要解释的样本,z 是抽取的样本点,M 是 x 的维度,是 z 的维度。
利用 LIME 来估计出模型 g 中每个变量对应的系数,也就是 SHAP 中的,得到关于权重的唯一解,在这里称为 Shapley kernel。
3.2 Model-specific 近似
如果我们已知复杂模型的种类,比如树集成模型,深度学习模型等,那么可以用更快更高效的方法来计算对应每个样本中的每个特征变量的 shapley value。对于不同的模型,计算 Shapley Value 也是不同的。TreeSHAP 是专门针对树模型的 SHAP 方法,下面会重点介绍。
TreeSHAP
树集成模型中包括很多性能优良的黑箱模型,比如随机森林、XGBoost、LightGBM 和 CatBoost,都属于非线性模型。Scott M. Lundberg,Su-In Lee 等提出了 TreeSHAP 来对树模型进行局部解释。相对于 model-agnostic 的局部解释方法,TreeSHAP 不需要抽样,而是通过对树模型中的节点来计算 Shapley Value,具体算法可以参考论文 2。
TreeSHAP 有如下优点:
1. 计算时间减少
如果直接用 Shapley Value 的公式来计算,时间复杂度是指数级的,但是 TreeSHAP 将中计算 Shapley Value 的算法进行优化,时间复杂度变为线性,因此可以大大缩短运行时间。
2. 将局部解释拓展到抓取交互效应
对于每一个样本, 局部解释会对其中的每一个特征变量计算对应的值。直观来看,这种解释不能让我们直接地看到交互作用。为解决这个问题,TreeSHAP 提供了计算 SHAP interaction value(参考论文 2)的方法来看模型内部的交互作用。
3. 基于众多局部解释来进行全局解释
对于整个数据集,可以运用 Shapley Value 来高效准确地获得局部解释性,即对每个样本的解释,可以帮助我们得到特征变量的全局解释。对于某一个特征变量,TreeSHAP 可以计算出所有样本中对应该变量的 Shapley Value, 将它们的平均值作为该特征的重要性值,从而得到全局解释。
4.SHAP 解释
介绍完如何计算 Shapley Value 之后,要开始解读是 Shapley Value 如何影响原始模型 f 的预测值。假设数据集中有 4 个特征变量,用原始模型 f 预测之后,我们以模型预测值的平均值作为其期望,即。以单个样本为例,它在原始模型中的预测值为, 我们计算出 4 个对应的 Shapley Value 后开始解释。
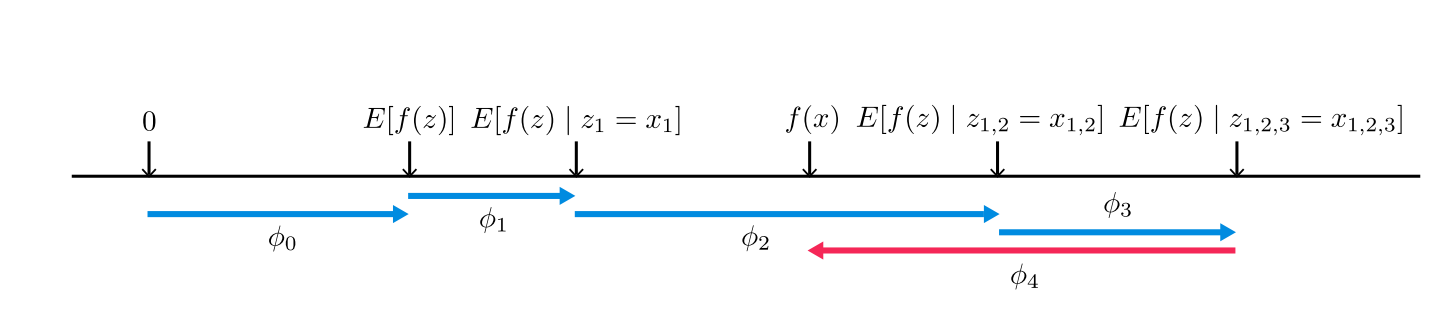
对于整个数据集而言,是固定的,是模型预测的平均值,可为正也可为负。上图解释了这个样本预测值与平均预测值之间存在差异的原因 。蓝色的箭头代表 Shapley Value 的值为正,意味着该特征变量对原始模型的预测值有一个正向的影响。红色的箭头代表 Shapley Value 的值为负,意味着该特征变量对原始模型的预测值有一个负向的影响。从图中可以看出,, 所以特征变量对有正向的作用,且的作用最强。的存在则对构成了负向的作用。最终在这 4 个特征变量的力的作用下,将该样本的原始模型预测值从平均值达到了。
5. 代码展示
SHAP 可以用来解释很多模型。接下来在台湾银行数据集上用 Tree SHAP 来解释复杂树模型 XGBoost。
Tree Explainer 是专门解释树模型的解释器。用 XGBoost 训练 Tree Explainer。选用任意一个样本来进行解释,计算出它的 Shapley Value,画出 force plot。对于整个数据集,计算每一个样本的 Shapley Value,求平均值可得到 SHAP 的全局解释,画出 summary plot。
下图是 Tree SHAP 对任意一个样本画出的 force plot,由于 Treeshap 是对对数几率(log odd ratio)进行解释,所以出现负数。具有负向影响的变量变为 PAY_AMT1 和 LIMIT_BAL 等,具有正向影响的特征变量加入 PAY_AMT6,PAY_0。其他变量的 Shapley Value 由于值太小就不一一列举。

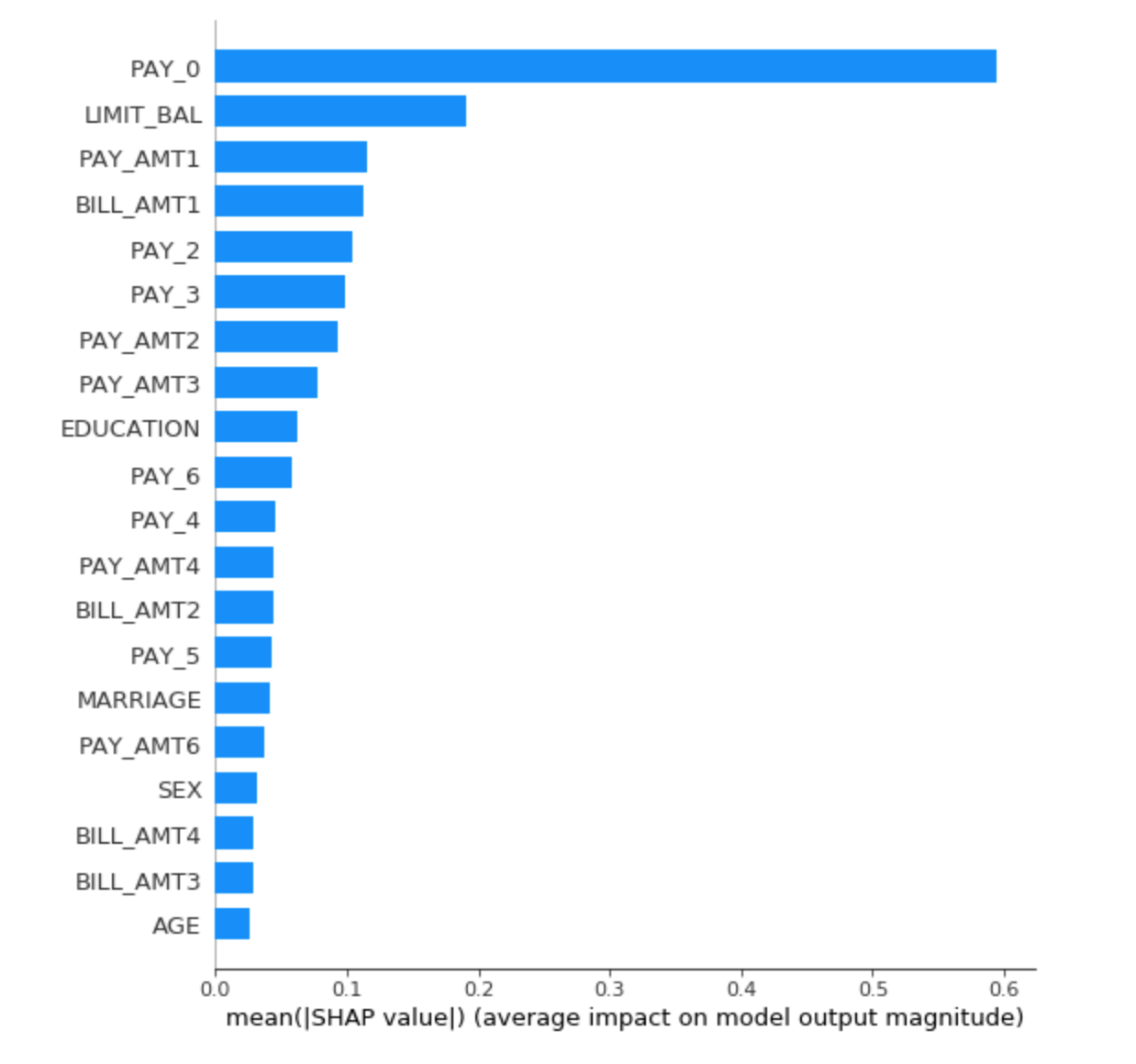
在 summary plot 中 PAY_0 该特征最重要,其次是 LIMIT_BAL,PAY_AMT1。
6.结语
本文先引入博弈论中的经典问题:如何公平分配每个玩家对项目的收益,来介绍每个玩家的 Shapley Value。通过类比的思想,将数据集中的特征变量当做玩家,模型的预测值当做项目的收益。对于单个样本而言,每个特征变量计算出来的 Shapley Value,可以将其理解为该特征如何影响原始模型的预测值。接下来围绕着如何计算 Shapley Value 提出 SHAP 的两种分类,一种是 Kernel SHAP,对应 model-agnostic 方法。剩下的分类是对特定模型的,其中着重介绍了 TreeSHAP。然后对计算出的 Shapley Value 应用博弈论的方法来进行局部解释,全局解释则是基于众多样本的局部解释而得到。最后用台湾银行信用卡数据集实践了 TreeSHAP,并介绍几种重要的图,包括 force plot、summary plot。
7.参考资料
LIME: Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why should i trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016.
Scott M. Lundberg, Su-in Lee. From local explanations to global understanding with explainable AI for trees.2020.
Scott M. Lundberg, Su-in Lee. A Unifified Approach to Interpreting Model Predictions, 2016.
原文链接:
https://mp.weixin.qq.com/s/dZ_CoYdVZexn3aaZ6BqNYw

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论