
2016 年年末,Microsoft发布了Azure SQL 数据库内存技术通用版。该内存处理技术仅能在Azure Premium 数据库层使用,它提升了联机事务处理(OLTP)以及混合事务分析处理场景中聚集列存储索引和非聚集列存储索引的性能。
Azure SQL 数据库与 SQL Server 数据库使用了同样的内存技术。之前,Microsoft 首先分别在 SQL Server 2012 和 SQL Server 2014 的列存储索引及联机事务处理中引入了内存能力。
Microsoft 声称通过内存技术联机事务处理的性能最高可以提升 30%,分析工作负载最高可以快 100x ,非常适合于寻找以下内存用例的组织:
得益于内存技术所带来的更加有效的查询和事务处理,组织不需要修改服务层就能获得一定的伸缩空间;除此之外,内存技术还能帮助组织降低成本。通常情况下,组织不需要升级数据库的定价层就能实现性能提升。在某些情况下,甚至降低定价层依然可以实现性能提升。
Microsoft 认为在 Azure SQL 数据库中使用内存技术有以下好处:
- 内存联机事务处理可提升吞吐量并降低事务处理的延迟。
- 聚集列存储索引可减少存储占用(高达 10 倍)并提升报告和分析查询的性能。将其与数据集市中的事实数据表结合使用,可在数据库中容纳更多数据并提升性能。将其与操作数据库中的历史数据结合使用,可存档并查询高达 10 倍的额外数据。
- 用于混合事务分析处理 (HTAP) 的非聚集列存储索引可以让用户直接查询操作数据库以获取实时的业务见解,无需运行昂贵的抽取、转换、加载(ETL)过程,无需等待数据仓库填充。通过非聚集列存储索引可以对联机事务处理数据库执行快速地分析查询,同时减少对运行负载的影响。
- 用户还可以将内存联机事务处理和列存储索引结合到一起使用。可以使用具有列存储索引的内存优化表,以便于快速地对相同数据执行事务处理并运行分析查询。
在最近的一个Data Exposed 演讲中,来自于Microsoft 的高级技术布道者Scott Klein 和高级项目经理Jos de Bruijn 展示了一个使用Azure SQL 数据库内存处理的范例。他们构建了一个可以模拟物联网设备遥测输入的应用程序。在该示例中,他们模拟了一个100 万电表同时向数据库发送用电信息的场景,示例开始的时候Azure SQL 数据库并没有启用内存对象,结果CPU 和Log IO 承受了非常大的压力,CPU 占用率徘徊在89% 左右,Log IO 占用率达到了86%。在启用了内存对象优化之后,CPU 占用率降到了10.47%,Log IO 占用率降到了34%。
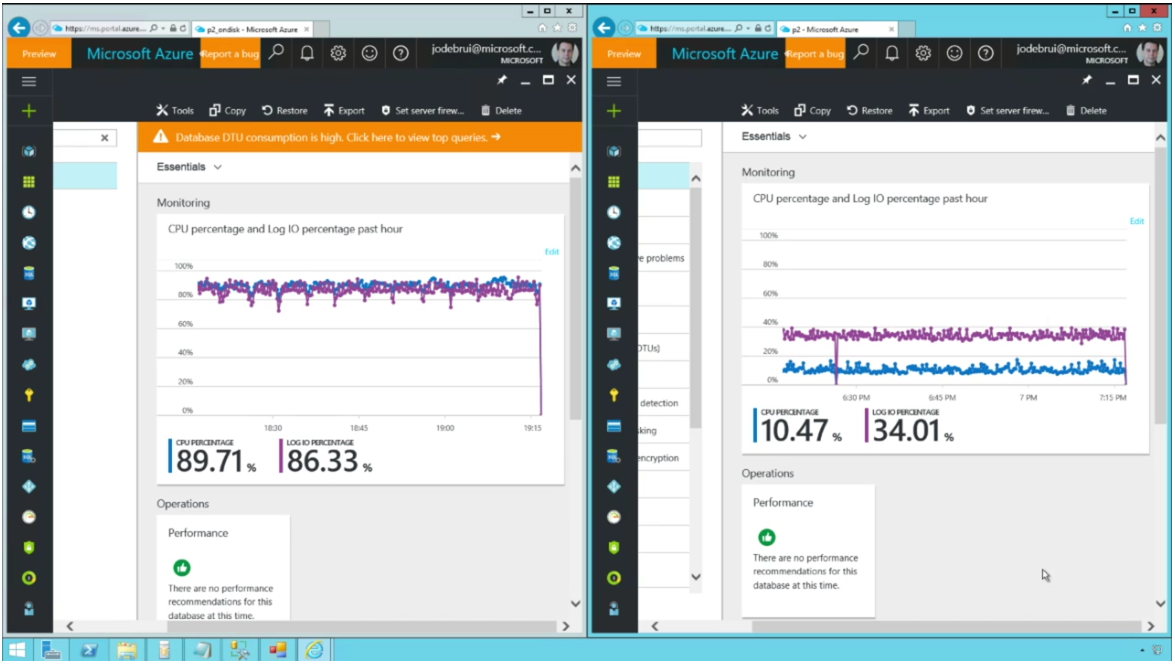
图片源: (屏幕截图) https://channel9.msdn.com/Shows/Data-Exposed/In-Memory-OTLP-in-Azure-SQL-DB
在遇到性能压力的时候,开发者可能会想提升 Azure SQL 数据库的吞吐量单位(DTU)。现在,面对性能挑战的时候,人们的答案可能是优化而不是扩展。Quorum Business Solutions 公司的解决方案架构师 Mark Freydl 解释道:
我们针对石油和天然气的物联网平台全年必须保持 7*24 小时运行,因此性能可扩展是非常关键的。Azure SQL 数据库为少数关键操作所提供的内存联机事务处理表和本地编译的存储过程可立即将总体 DTU 消耗降低 70%。
除了物联网遥测示例之外,Microsoft 还提到了一些其他的可使用内存处理的场景,包括金融交易、游戏、ASP.NET 会话管理、Tempdb 替代以及避免无效的抽取转换加载操作。

图片源: (屏幕截图) https://channel9.msdn.com/Shows/Data-Exposed/In-Memory-OTLP-in-Azure-SQL-DB
查看英文原文: Improving Azure SQL Database Performance Using In-Memory Technologies

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论