
作者 | 蚂蚁链 LETUS 技术负责人 田世坤
写在前面
文字产生以前,结绳记事是人类用来存储知识和信息的主要方式。此后,从竹简、纸张的发明,到工业时代的磁盘存储,再到信息时代的数据库,存储方式不断革新,“存力”不断提高。
11 月 3 日,在 2022 云栖大会上,蚂蚁链历经 4 年技术攻关与测试验证的区块链存储引擎 LETUS(Log-structured Efficient Trusted Universal Storage)正式发布。
这一款面向区块链可信数据存储的技术产品,不仅用来解决当前蚂蚁链及区块链产业的规模化发展问题,也面向 Web3 时代提供“可信存力”支撑。
我们认为,随着大量的数据和数字资产在数字化世界里流转,可信数据的“存力”将如同电力网络的承载力一样重要。
本文希望通过对 LETUS 的深入技术解读,回答读者们普遍关心的关键问题:LETUS 是什么?主要解决哪些问题?为什么坚持用“可验证结构”?为什么要自研?以及未来要走向何处?
背景是什么?
从 2009 年序号为 0 的创世块诞生至今已过去十多年,“中本聪”依然神秘,但区块链技术的发展却因为公链、token、开源的推动,没有丝毫神秘感。
经过几代技术演进,在比特币的 UTXO 模型基础上诞生了应用更为广泛、支持可编程智能合约的区块链技术:通过密码学、共识算法、虚拟机、可信存储等技术,多个参与方执行相同的“指令”,来完成同一个业务逻辑,如账户转账,或者合约调用,维护不可篡改和不可伪造的业务数据。
简单讲,可将这类账本数据库,看作一个去中心化防作恶、防篡改的复制状态机,所执行的是智能合约描述的业务逻辑,而状态机通过日志 (区块数据)产生新的状态(状态数据):
区块数据:包括交易、回执、世界状态 Root Hash 等信息,和数据库系统中的日志类似,但是块之间由 Hash 锚定防篡改,并且不会删除。(区块数据记录的是区块链上发生的每一笔交易,如:Alice 向 Bob 转账 xx)
状态数据:记录账户、资产、业务合约数据等状态信息,和数据库系统中表数据类似,需要实现可验证可追溯。(状态数据记录的是区块链上每个账户或智能合约的当前状态,如:Bob 账户剩余 xx)
链上数据的特点可以总结为以下三个:
持续增长:从创世块开始,账本数据随交易持续增长,保留周期长;
多版本:交易修改状态数据产生新版本,系统提供历史版本查询和验证功能;
可验证:交易和账户状态通过 Merkle 根哈希(Merkle Root Hash)锚定在区块头,通过 SPV(simple payment verification,简单支付证明)提供存在性证明;
区块链应用通过可验证数据结构(Authenticated Data Structure,如 Merkle tree)实现可验证和可追溯。我们认为,Web3“存力”一个非常重要的要素是可验证,而今天我们看到的区块链存储瓶颈大多来源于可验证结构 ADS(如 Merkle tree)的低效存取和查询,这正是蚂蚁链 LETUS 重点攻克的难题。
我们要什么?
随着时间推移和链上交易的增加,对存储容量的要求也不断增长,随之而来的是区块数据存储成本的大幅提升;与此同时,链上状态数据规模也持续增加,可验证数据结构持续膨胀,导致交易性能随账户规模提升和历史状态数据增加而持续下降。
2019 年,蚂蚁链上线了一个供应链金融业务,大家特别兴奋。但是,这种兴奋并没有维持多久,随着程序跑的时间越来越长,问题慢慢暴露出来。
供应链金融是面向 ToB 的,不像 ToC 端随时都有数据,可能会在某个时刻(比如每天晚上)有一笔状态数据非常大的交易进来,跑了一个星期后发现性能越来越慢。
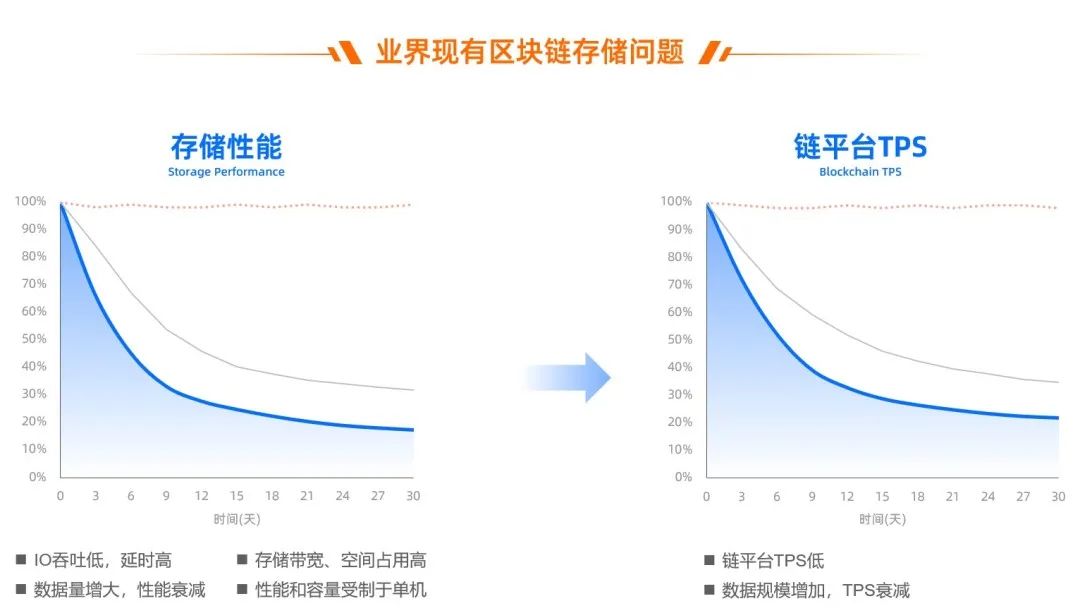
链平台 TPS 的衰减和存储直接相关,而与共识、虚拟机都无关,随着业务合约持续写入数据,存储性能大幅衰减。
如果要在技术上长时间支持亿级账户规模、每天能稳定支撑亿级交易量,存储的规模和性能问题必须要攻克。
期间,团队也曾试过各种技术方法对他进行优化,得到一些缓解。但多次尝试之后发现,随着数量增加而出现的性能衰减,是一个绕不开的瓶颈,需要从本质上解决。
我们需要从问题表象分析背后的原因。
区块链应用通过可验证数据结构实现可验证和可追溯,但是可验证数据结构会带来读写放大(问题 1)和数据局部性(问题 2)。
而存储系统为了实现数据管理,需要对数据分页 / 分层、排序,如 KV 数据库基于 LSM-tree 将数据分层有序存储,而 MySQL 之类的数据库将数据分页,也会基于 B-tree 数据结构来排序索引。
业界现有的实现方式,大多采用基于 LSM 架构的通用 Key-Value 数据库,在数据库之上运行一个独立 Merkle 树来实现可验证,如:
以太坊:MPT(Merkle Patricia Tree)+LevelDB
Diem:JMT(Jellyfish Merkle Tree)+RocksDB
背后的核心矛盾为:
Merkle 树每次状态数据修改,即使只改一个 KV,也需要从叶子节点到根节点,每一层节点都重新编码后,写到 KV 数据库,例如上图中 Alice 给 Bob 转账,需要写入 Merkle 树的 2 个叶子节点和 3 个中间节点,最坏情况需要写入数十个中间节点;
Merkle 树的节点的 key 完全随机 (如对内容算 hash,再以 hash 为 key),数据局部性(data locality)非常不友好,如 RocksDB 里为了让 Level 内 sst 文件有序,即使没有垃圾依然需要层层进行数据压实(compaction),从而消耗了大部分的磁盘读写带宽;
数据规模越大,Merkle 树本身的层数越多,需要额外写入的 key-value 越多,DB 里的数据量越多,后台数据管理的代价越大(如 compaction 流量),消耗大量的磁盘和 CPU 资源。
除此之外,吞吐、延时等存储性能(问题 3)、持续增长下的存储成本(问题 4)、单机存储下的规模瓶颈(问题 5)也都是需要解决的问题。
面临什么挑战?
在过去几年的快速发展中,区块链的业务场景对交易吞吐量和响应时间要求越来越高,很多技术也被推动迭代发展,如 PBFT、HoneyBadger、MyTumbler 等高性能共识算法,BTN 等网络基础设施,JIT 加持的 WASM 虚拟机、以及高效的并行执行技术。
但比较而言,存储的性能对区块链平台整体性能影响非常大。对面向 2C 场景的数字藏品类业务(如鲸探,需支持秒杀),交易 TPS 与延时要求极为苛刻;而对需要在链上保存大量数据的存证类业务,大容量存储带来的成本又十分可观。
要支撑业务的长期可持续发展,我们归纳出区块链存储面临的核心挑战:
规模:业务账户规模可达数 10 亿,状态数据和历史版本规模分别需要支撑到十亿、千亿级;
性能:转账交易需求可达十万级 TPS、百毫秒级延时,要求性能不能受制于单机瓶颈,数据规模持续增长下性能不衰减;
成本:随着交易增长,存储容量持续增加,存储空间占用、节点间带宽占用居高不下。业务持续增长要求低成本存储。
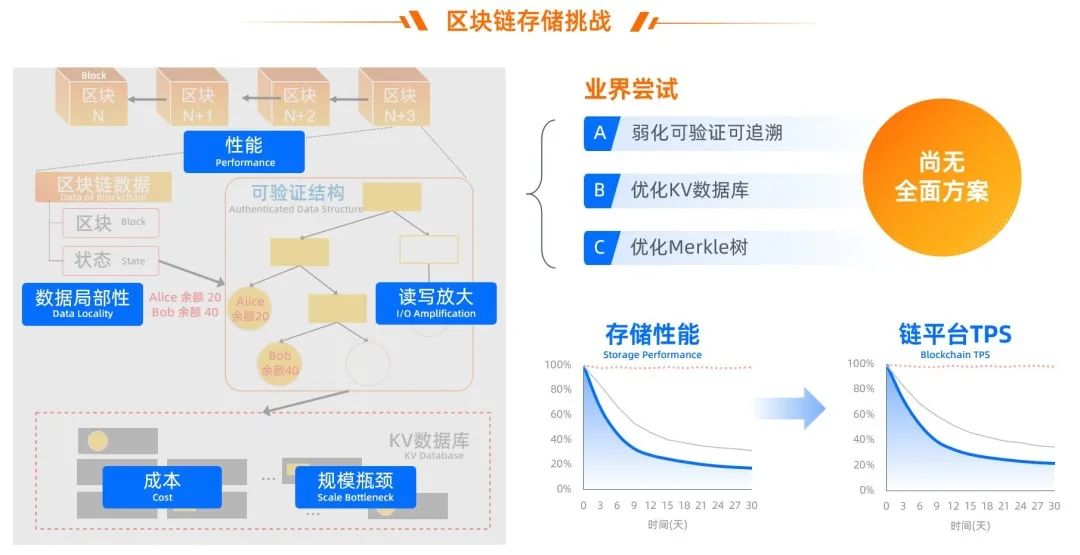
这些问题在行业内很普遍。业界技术路线主要分三条:
路线 A:弱化可验证可追溯,如 HyperLedger Fabric 1.0 开始不支持可验证和多版本,保存读写集、只持久化最新版本状态数据;
路线 B:优化 KV 数据库存储,如实现键值分离、hash 索引的 KV 数据库等 (BadgerDB、ParityDB),接入通用分布式数据库 (MySQL) 等;
路线 C:优化 Merkle 树,交易 ID 作为版本、树结构稀疏化,如 Diem JMT。
根据公开信息,目前区块链产品中主流的 MPT + LevelDB、JMT + RocksDB、MySQL 等存储架构,没有能全部解决上述 5 个问题的方案,难以在支持多版本和可验证的同时,满足 10 亿级账户规模下的高性能、易扩展、低成本的业务要求。
我们做到了什么?
我们自研了一套区块链存储引擎 LETUS(Log-structured Efficient Trusted Universal Storage),保证完整的可验证、多版本能力,既满足区块数据不可篡改、可追溯、可验证等要求,也提供对合约数据友好访问、存储规模可分片扩展,高性能低成本等特性。同时也满足通用性,统一管理区块数据、状态数据。

4 年前不敢想象的能力现在具备了(以下数据为统一环境下的测试结果)
大规模:通过存储集群扩展支持十亿账户规模,TPS 超过 12 万,交易平均时延低于 150ms;
高性能:存储层 IO 吞吐相比以太坊 MPT + LevelDB 等架构提升 10~20 倍,IO 延迟降低 90% 以上。链平台在 7x24 高压力压测中,端到端 TPS 不随数据量增加而衰减;
低成本:相比 MPT + LevelDB 架构,磁盘带宽减少 95%、空间占用减少 60%;相比于 Diem JMT + RocksDB 架构,磁盘带宽减少约 60%、空间占用降低约 40%;
进一步降成本方案,供用户选用:
a. 针对区块数据容量与成本持续增长,提供智能控温分层存储能力,并应用于存证等业务降低约 70% 存储成本,同时也降低运维成本。
b. 针对状态数据的历史版本容量与成本持续增长,提供范围扫描的批量裁剪能力,实现历史版本状态数据的裁剪和后台空间回收,在十亿账户规模时,使用链原生存储可以减少近 90% 状态存储空间。
但这背后是一个技术架构的跨越,从下图左边的可验证数据结构 +KV 数据库架构,升级为现在的 LETUS 存储引擎,架构更简洁,系统更高效。
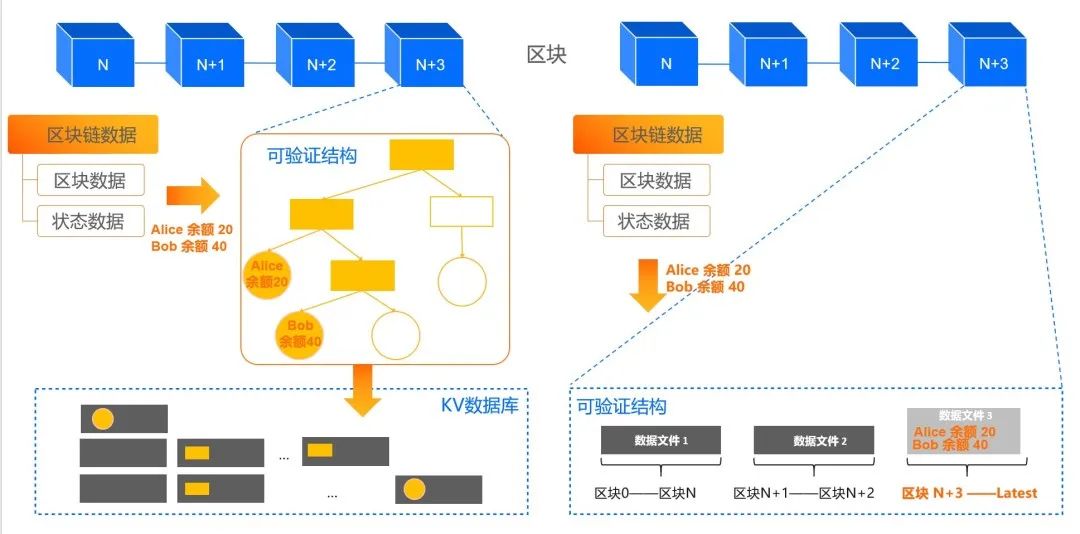
如 Alice 给 Bob 转账,只需要写增量数据,不需要写入 7 个 Merkle 树节点,数据局部性更友好,如 Alice 和 Bob 的账户数据,按区块号有序,不再 hash 随机。
怎么做到的?
图片回顾这四年,主要经历的三个大的阶段。
阶段一:开源思路优化
第一年里,为了满足业务急迫诉求,我们需要在有限时间内,实现亿级账户规模和交易 TPS。先从已有系统入手,深度优化了状态树,基于开源 MPT 到自研 FDMT,同时调优 RocksDB 数据库、增加并发、提升介质性能。
一系列优化措施缓解了问题,但依然无法根本解决,例如数据规模增加后,写放大依然有几十倍,数据在底层存储里依然随机分布。
阶段二:自研存储引擎
为了能彻底解决上述所有问题,我们不得不重新思考存储引擎的设计。
核心设计
针对读写放大(问题 1)、数据局部性(问题 2)和性能(问题 3),我们结合区块链特征,如可验证数据结构的读写行为、链上数据的多版本诉求、只追加和不可篡改等,重新设计存储引擎的架构分层、关键组件、索引数据结构:
根据区块链特征,我们根据可验证数据结构的读写行为、链上数据的多版本诉求,重新设计存储引擎的架构分层、关键组件、索引数据结构:
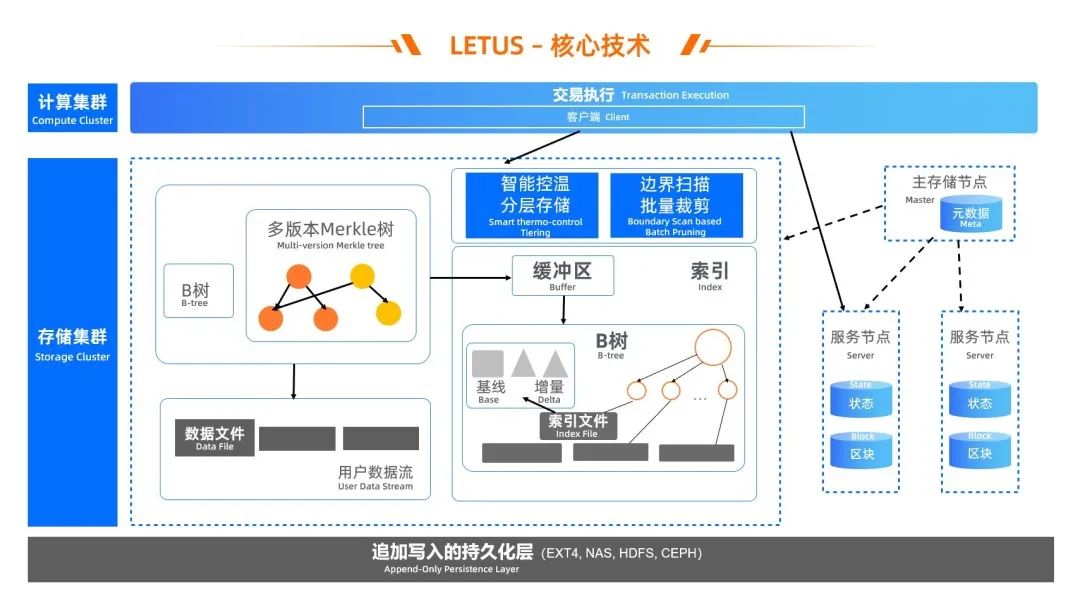
将可验证特性下推到存储引擎内部,由内置的 Version-based(区块号)多版本 Merkle 树提供可验证可追溯,并且直接操作文件,从而缩短 IO 路径;
将可验证特性下推到存储引擎内部,由内置的 Version-based(区块号)多版本 Merkle 树提供可验证可追溯,并且直接操作文件,从而缩短 IO 路径;
多版本 Merkle 树的 Node 聚合为 page,提升磁盘友好性,page 存储采用 Delta-encoding 思想避免 in-place 更新(结合 Bw-tree 思路),状态数据修改时主要保存增量,定期保存基线,从而减少写放大,也减少了空间占用;
为 page 存储实现 Version-based 的存储与检索,索引 page 都按区块号有序写入、在索引文件里有序总局,核心数据结构为 B 树变种,从而实现有序数据 locality;
利用区块链场景数据的追加写、Immutable 特点,架构上采用 Log-Structured 思想,通过日志文件来组织数据;
数据与索引分离,数据按区块号有序写入数据文件,通过异步 IO、协程并发等提升系统并发度,索引多模,区块 & 状态通用,除 Merkle 树支持状态数据,实现有序 B 树支持区块数据;
当前最新版本 Merkle 树优先在内存里缓存或者全部缓存,链上合约执行时,如果存在则直接读取,不需要访问 page 来重放,从而加速合约执行。
基于些核心设计,实现了成本降低的同时性能提升,链平台交易 TPS、延时等性能指标不会随着数据规模的提升而衰减。
降成本
虽然存储资源占用大幅降低后,但是链上数据依然面临持续增长带来的高成本问题(问题 4)。
基于 LETUS 架构的后台数据治理框架,我们能很方便的扩展实现数据迁移 / 压缩 / 垃圾回收等治理策略,基于这些策略,为用户提供进一步降成本能力,并针对自己的业务特点来选择使用:
(1)智能控温分层存储:存储介质按照性能、成本分层,通过智能控温调度数据在不同介质的分布量,将冷数据后台自动迁移到廉价介质(如 NAS),降低存储整体成本,并实现容量扩展,不受单盘空间限制。
(2)范围扫描的批量裁剪:对于历史版本 Merkle 树和状态对象,基于版本有序性与内置 Merkle 树,让用户可以指定目标区块号范围裁剪,通过 Page 边界扫描,批量索引与数据裁剪、垃圾回收实现存储空间释放,进一步降低状态数据成本。
规模扩展
针对问题 5,LETUS 采用分布式存储架构,实现单个共识参与方计算和存储分离,计算层和存储层可分别部署独立集群,通过高性能网络通讯框架进行数据读写访问。
为了对海量状态数据进行灵活的数据分片,并且保证各个区块链的参与方 hash 计算的一致性,将数据切片为 256 个最小存储单元(msu),并将一个或者多个 msu 构成一个状态数据分片(partition),将所有数据分片调度到多个物理机器。从而实现规模弹性扩展,解决了单机存储的容量瓶颈和带宽瓶颈。
阶段三:生产落地
为了全面落地铺开的同时让业务平稳运行,能够开着飞机换引擎,在这几年的研发过程里,我们充分准备、循序渐进的分阶段落地:

2021 年 5 月,基于 LETUS 存储引擎的区块数据冷热分层,在版权存证业务灰度上线,存储成本降低 71%,解决容量瓶颈并降低运维成本。
2021 年 8 月,基于 LETUS 存储引擎的状态数据,在数字藏品平台“鲸探”双写灰度上线,并成功支撑秒杀场景;
2022 年 2-6 月,LETUS 引擎的历史状态数据裁剪、存储服务架构升级等生产 ready,在数字藏品和版权存证等业务全面落地,并从灰度双写切为单写;LETUS 单写意味着对硬件资源要求大幅下降,我们将“鲸探”生产环境的云资源全面降配,降配后链平台性能水位提升 200%,同时存储成本下降 75%。
总结与展望
蚂蚁一直坚持“成熟一个开放一个”的技术战略。同样的,LETUS 不只为蚂蚁链定制,也同样给其他联盟链、公链提供高性能、低成本的支持。
蚂蚁链坚持技术自研,确保在共识协议、智能合约、网络传输、存储引擎、跨链技术、区块链隐私计算等领域处于全球领先水平。我们始终认为,坚持技术自主研发是建立长期可持续竞争力的关键。
在“可信存力”这条赛道上,我们也需要为进一步的技术壁垒提前布局,如合约结构化查询语言,为链上合约实现结构化 + 可验证的查询能力, 提升开发者体验;Fast-Sync 与节点多形态,提升组网效率和节点成本灵活性;以及 Web3 等潜在的技术生态。
技术创新永远在路上。接下来,继续沿着硬核技术方向突破,啃一些硬骨头,持续为整个价值互联网提供可靠的、可持续的存力。




