

本文最初发布于 Ben Northrop 的个人博客,经原作者授权由 InfoQ 中文站翻译并分享。
重写带有一种欺骗性的诱惑,其逻辑看上去是这样:
这个系统已经应用于生产环境,我们很显然知道它是如何工作的,因此只要将其移植到一个更好的平台,一旦我们完成这项工作,事情就会变得更简单。
我们在本文将批判这种基于直觉的认识。你会看到,重写绝非易事。尽管我们不受新应用程序部分挑战的影响,但我们也会碰到前所未有的全新挑战。为了成功地完成重写,我们必须应对这些挑战,因此提前了解有什么挑战很有必要。
在冒险重写之前,让我们讲述一个快速的起源故事,看看我们是怎么走到这一步的?
开始
这一切都始于绿地开发( Greenfield Development )阶段。在这个阶段,我们萌生一个想法,开始构建一款功能强大的应用程序。经过数周或几个月的不懈努力,我们最终向市场发布了一款产品。当然,这个“市场”既可能是真正的付费用户,也可能是一组内部业务用户等等。
如果应用程序很受欢迎,在一段时间内,它会处于增强( Enhancement )阶段,添加新功能,解决缺陷。这是个平衡阶段,每个人都是快乐的。最终, 技术债务会不断累积,我们开始发现,我们努力工作的回报在递减——在过去,一周的开发足以添加一个完整的新功能,但现在,可能都不够改变按钮的颜色。
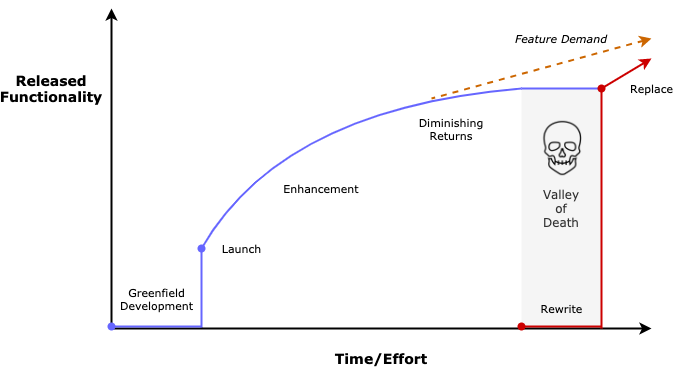
这时,我们可能就会产生疑问:投入时间和金钱去做一件注定失败的事,这样做是否值得。此外,自应用程序首次发布以来,可能出现了一些令人兴奋的新技术,我们可能对如何利用这些技术让应用程序更具弹性、更易使用和更高效等有一些宏伟愿景。所以,我们开始制定一个重写计划。其思想是将现有系统的开发短时间冻结,然后将资源转移到替代系统上。我们会先打基础(使用更现代的模式、工具、语言等等),然后将现有的功能迁移过去。用户只需要安然度过“暂停”(即不获得任何新的更新),但是当重写的系统就位时,工作效率应该是以前的两倍(或者更多!) 。
虽然这个“直接迁移(lift and shift)”计划看起来直截了当,但它掩盖了一些关键风险——技术、组织和心理方面的因素都会使这个重写阶段极不稳定。此外,这个阶段拖得越久,我们成功(即交付替换品)的机会就越低。因此,让我们看看其中隐含的一些危险。
风险一:双倍的工作量
在这段旅程中,我们常常面对的第一个风险是重写基本上是双倍的工作量。
当然,在技术上,我们希望自己可以暂停以往的开发,只专注于在新平台上编写代码,但现实(准确地说是业务)很难遵守这一原则。
或许是为了赢得(或留住)一个重要客户,业务人员要求我们现在就在已有系统中添加一些新特性。或者第三方系统改变了其 API,而我们需要重构,或者出现了 sev-1 缺陷,或者新的政府法规发布。
关键是, 生产系统几乎不可能长时间处于静止状态 ,甚至在重写期间也是如此。对旧系统进行维护是不可避免的,而这意味着并行开发。
这样,第一个问题是并行开发违反了我们作为开发人员最神圣的原则: 不要重复自己。对遗留系统的任何更改都需要移植到新系统中。例如,如果我们在旧栈中添加特性 X,我们必须在新栈中再次添加 X(但这次是用新的语言或框架编写的)。这种重复工作也适用于 X 的测试、项目管理、构建和部署。本质上,无论对遗留系统进行更改需要花费多少时间或资源,在重写阶段,成本很容易翻倍。
而且,根据重写工作的进度,更改(如功能、缺陷修复等等)可能发生在源代码中尚未重写的部分,所以团队必须记住,到那里的时候要把重写的时间线后推。或者在相反情况下,更改发生在应用程序中已经重写的部分,因此,团队必须返回并更新刚刚迁移过的代码(然后重新测试等等)。
无论哪一种方式,重写过程中的并行开发都可能让人觉得,团队在地面上构建替代品的同时还要保证飞机的正常飞行。为了乘客的安全,那架飞机必须留在空中,但如果我们花太多的精力去维护它,我们就永远无法让新飞机起飞。当然,负责这两驾“飞机”的团队通常是同一个,这就引出了下一个问题。
风险二:团队分裂
假设需要做一些必要的工作来支持现有系统,那么问题是:谁对此负责?通常,团队会采用两种方法来管理并行工作。一种选择是,让更多的初级开发人员留在维护模式中,从而解放高级开发人员来开发新系统。这是有道理的,因为完成重写通常需要更高层次的技术“无畏派”——掌握各种新技术并整合应用、配置环境、建立模式和约定等等,这些都是棘手的任务,可能会让新晋开发人员深陷泥潭。
因此,团队可能会决定进行这种类型的分裂,初级开发人员维护,高级开发人员继续前进。但这可能只是短时间有效, 不用多久,高级开发人员还是会被拉回来帮助解决需要全员参与的关键问题或讨论一些变化的影响。多年来,他们对旧系统的了解,以及他们与业务利益相关者、运维人员和其他人的关系,让他们不可替代。他们不得不参与其中。即使这种“抽离”每周只占用几个小时,但上下文切换仍然会阻碍工作效率。当开发人员在旧系统和新系统之间来回切换时,重写的时间线就会被推后。
为避免这种情况,团队可以采取另一种方法:组建一个新团队,这样更容易专注于重写。这个“重写团队”的开发人员与现有系统的联系可以忽略不计(也许他们是顾问、新雇员等等),因此他们能更好地将自己隔离开来,并在新工作中保持高效。
问题解决了?没有。第一个问题是根据定义,这些开发人员不太熟悉代码库,不具备领域知识,不知道事物是如何运转的,也不知道为什么要这样运转。当然,他们有原始代码作为文档,但这就像通过查看源代码来学习编程语言一样。这都是事实,不是讲故事。因此,这个新团队要么会在理解现有系统的错综复杂之处时步履维艰,要么会为了继续前进而做出错误的假设,要么最终不得不拉拢原来的团队。这些都不是富有成效的结果。
此外,这种“组建新团队”的方法也会疏远那些留下来负责支持遗留系统的资深开发人员,使他们感到好像自己因为忠诚度和经验受到了惩罚。新团队使用现代化的技术开始全新工作,而他们还在毫无生气的做着维护。这一点也不酷。因此,不出所料,这样很快就会导致开发人员不满,稍后是人才流失。我们需要设计一个团队结构,既能支持旧系统,又能正确高效地构建新系统,让每个人都满意。但即使你让合适的人上了合适的车,还是会有意外发生。
风险三:意外之事
现在,即使重写的团队配备了经验丰富的开发人员(即那些帮助编写遗留系统或至少有一些经验的开发人员),在将现有的源代码迁移到新平台时,总还是会有意外。对于此类意外事件,Donald Rumsfeld 提出了比较中肯的见解:
有报道说 ,我们总是对没有发生的事情感兴趣,因为据我们所知 ,有已知的已知 ; 有些事情我们知道我们已经知道。我们也知道有已知的未知;也就是说,我们知道有些事情是我们不知道的。但也有未知的未知——那些我们不知道自己不知道的。纵观我们国家和其他自由国家的历史,后一类往往是最困难的一类。
通常,当开始重写过程时,我们会设法估计需要付出多少努力。从这里开始,我们会编目前两类工作。当然,有一些代码库我们有直接的经验,因此,我们可以更快(更准确)地做出估计。这些是已知的已知。但是,系统中也有一些地方,我们知道自己没有直接的经验,所以我们增加了一些缓冲。
比如,Joe 编写了注册流程,但是他去年辞职,所以迁移可能需要更长的时间。
这些就是已知的未知。我们按计划继续进行,评估这两种类型的工作,并为已知的未知留出额外时间,直到就整个时间线达成一致。
然而,直到我们深入研究并开始迁移代码时,我们才偶然发现第三种也是最有害的工作类别,即未知的未知。它可能是我们从来不知道其存在的 1000 行令人费解的业务逻辑,或者是我们不知道何人使用的一组报告,又或者是一些我们不知道的将整个系统集成在一起的“胶带”。不管是什么,我们最初的重写计划都从来没有考虑到它,但我们此时已经走出太远,无法回头。
结果是,我们要分析这个(以前)未知的未知,看看“它到底做了什么?”,然后进行处理(“我们需要把它迁移过来,还是可以抛在一边?”)。这些额外的分析、讨论和努力只会推迟最初计划好的时间,降低业务发起人和客户的耐心。
虽然其中一些未知的未知可以被消化吸收,但太多的话可能会使整个重写工作陷入危的境地。通过更好的计划和分解(稍后详细讨论),可以尽量减少这种未知的未知,但是要完全避免还是很困难的。不管怎样,我们还会给自己造成另一种危险。
风险四:第二系统效应
通常,我们长期忍受现有系统的缺陷,以至于当有机会重新来过时,我们忍不住想让一切变得更好,或者更完美。
几十年前, Fred Brooks将这种趋势称为第二系统效应( Second System Effect)。在《 人月神话》中,Brooks 谈到了系统架构师,根据他的观察:
在设计第一个项目时,他会不断地修饰和润色功能。这些功能会被存起来,用于“下一个”项目。早晚有一天,第一个项目结束了,架构师对这类系统充满信心,他相信自己已精通这一级别的系统,并时刻准备着开发第二个系统。
第二个系统是架构师们所设计的最危险的系统。当他着手第三个或第四个系统时,先前的经验会相互验证,他们就可以判断出此类系统的通用特性,而系统之间的差异会帮助他识别出经验中不具普遍性的部分。
这种影响可以通过几种方式表现出来。首先,我们倾向于把重写看作是一个消除我们在过去的系统中所积累的全部技术债务的机会。我们希望分解 God 类,修复不一致的变量命名,改写和重组数据结构等等。基本上,我们认为这是解决遗留代码中所有小问题的机会,因为将债务移植到新代码库中感觉不太合适。
此外,我们还很容易产生这样的想法,不仅将重写看作是对架构中有缺陷或缺少支持的的某些部分进行现代化的机会,而且还将其看作是一跃跨到技术最前沿的工具 。也许 UI 仍然是陈旧的 AngularJS,并不能为移动 Web 用户提供很好的渲染,所以移植到一个更现代的 Web 框架似乎是合理的。但是,当完成这项工作后,我们又将后端分解为微服务,并使用 Go 编写它们!从本质上说,重写就像一项法案——它可能只是一项减少枪支暴力的简单法案,但当它通过并成为法律时,西弗吉尼亚州已经有了五座新桥梁,俄勒冈州的农民也得到了种植大豆的补贴。
第二系统效应不仅存在于开发者中间。通常,业务涉众也会采取同样的策略,但是有他们自己的优先级。“我们还不如把这个用户渴望已久的功能在重写时添加,因为无论如何我们都会修改代码。”就像技术上的改进和润色一样,范围变得越来越大,重写的发布日期也被推得越来越晚。
最后,初始系统的开发口号是“快速上线运行!”,而重写时变成了“我们以后再也没有机会做 X、Y 和 Z 了!”
风险五:重蹈覆辙
人们常说,将军在和平时期会为最后一场战争做准备。他们会回顾和反思过去作战计划中的缺陷和错误,并发誓绝不让这些错误再次发生。然,后下一场战争就来了,和上次完全不同。他们的准备是徒劳的。重写也会发生同样的情况。我们非常清楚自己在第一个系统上的失误,所以当设计第二个系统时,我们首先要确保自己不会重蹈覆辙。但人们很容易忽略,事情已经发生了变化。在我们重写的时候,那些过去的错误可能不是问题,所以没有必要去预防它们。与此同时,在重写中使用的现代化技术引入了一整套我们还无法预见到的新问题。
在从事咨询工作的早期,我帮助一个客户建立了一个大型网络应用程序,服务于几千名内部用户。这个应用程序是成功的,换言之,我们在预算范围内按时交付了功能,但是,我们不知不觉把“马”套在了错误的马车上。那是单页应用出现的早期,所以我们使用了一个名为 Google Web Toolkit 的刚起步的框架,在当时,它非常酷。遗憾的是,在这个应用发布一年左右之后,谷歌从 GWT 转向了更好的技术(Angular),让所有人(包括这个客户)都困在了这种基本上不受支持的技术上。这种糟糕的情况,我们是很难预测和预防的。
几年后,我有机会与一些仍然在那里的开发者重新取得联系,他们告诉我,他们别无选择,只能重写这个应用程序。但当我问他们选了哪些技术时,我感到很惊讶。他们不想再被单页面应用技术或一个昙花一现的框架所伤害,于是他们选择了一项非常非常成熟且有十年之久的服务器端页面渲染技术,尽管此时,单页框架已经非常可靠,每个人都在使用,而他们那有着丰富用户交互的应用程序本可以从那个模型受益。换句话说,他们重写的核心驱动力是避免第一个系统的错误,但在这个过程中,他们错过了现代 Web 框架的许多优势。他们在打最后一场战争。
风险六:全有或全无
重写的最后一个大风险是可以避免的,但通常还是无法避免。虽然我们现在认可了迭代开发的智慧和最小可行产品的概念,但通过重写,很难找到一种方法来一次性交付所有的东西。例如,如果客户一直在使用一个拥有 100 个功能的遗留系统,如果我们希望他们(愉快地)转换,我们交付的新系统怎么能够少于 100 个功能呢?基本上,重写的系统需要能够完成旧系统所做的一切,因此,在我们回到迭代开发之前,我们似乎必须首先部署整个替代系统。这不仅取决于现有系统的大小,可能需要付出相当的努力。
此外,这种“全有或全无”的需求与业务人员持续不断的需求相结合,会给团队带来难以置信的压力。如果团队在重写全部完成之前不能交付任何东西,那么他们就不能显示任何有形的价值,直到替代产品推出。在某种意义上,业务被重写工作俘虏了,他们要保持耐心,相信他们的开发团队可以完成这项工作。这并非易事。如果客户特别要求,或者团队经常遇到意想不到的延迟和问题(例如,未知的未知等),将重写的发布日期推后,业务可能就会觉得必须施加压力(这会迫使团队走捷径),或者干脆放弃。
总结
最后,希望你已经了解了重写阶段可能存在的风险。虽然绿地开发阶段肯定也有它的风险,但重写也不是在公园里散步。即使最有能力的团队,也很容易被并行开发、团队组织、特性和技术镀金以及“大爆炸式”部署的挑战拖垮。因此,我们必须对大规模重写有充分的理解。在 下一章我们将看到,令人惊讶的是,情况并非总是如此。
原文链接:
http://www.bennorthrop.com/rewrite-or-refactor-book/chapter-2-the-risks-of-rewrites.php

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论