

1.1 业务背景
本次优化的背景来源于公有云 AOM 日志服务。日志服务底层采用 Lucene 进行索引,对每个用户建立索引文件夹,方便对每个用户的日志进行管理。AOM 日志服务的对象为面向所有用户,有着用户数量多、流量大、流量分布不均匀等情况。虽然可以通过增加服务节点将大量用户分配到不同节点上,但是如果能够提升单个节点的处理速度极限处理速度可以有效的提高节点资源利用率。
1.2 建立模型
考虑公有云多用户查询,结合 Lucene 索引存储的特性,提出以下三个模型:
单用户单线程索引模型
线程池索引模型
多线程 Multi 组合索引模型
1.3 单用户单线程索引模型
由于不同用户需要建立不同的索引文件夹,可以对每个用户单独建立线程进行索引,该模式下索引管理方便,也是最简单直接的方案。
为模拟不同数量用户下索引速度的变化,使用固定整体流量的方式进行测试。用户数量*用户流量=总体流量,总体流量固定不变为 40MB/s,随着用户数量增加,用户的流量对应减少。
1.3.1 测试结果
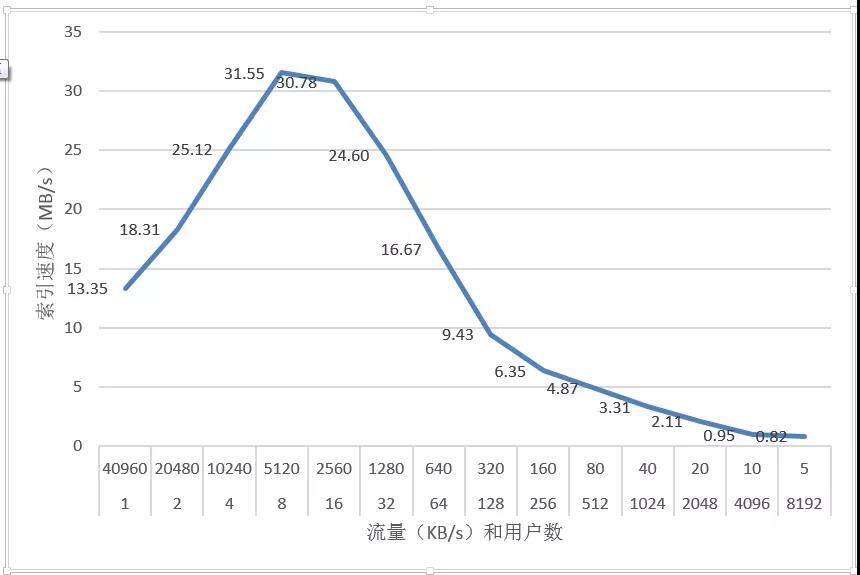
测试结果表明,单用户单线程索引模型下,随着用户数量的增加,整体索引写入速度呈现先增大后减小的趋势。用户数量大于 1024 以后,整体的索引速度降低到 3MB/s,已经不能满足一个节点的正常索引写入要求了。
1.3.2 结果分析
用户数量较少情况下,索引速度随着用户数量显著升高
每个用户使用一个线程进行索引,而单线程只能跑在每次只能运行在单个 CPU 上,不能充分利用测试环境下的多核 CPU。而随着用户数量的增多,索引的线程增加,多个线程在不同 CPU 下同时索引,整体的索引速度有明显的上升。
用户数量继续增加,索引速度降低
在用户持续增加的情况下,线程数也相应的增加。CPU 在多个线程来回切换,大量的时间浪费在线程的上下文切换过程中,从而导致索引写入速度降低,使得其整体索引速度降低到非常低的水平。
1.3.3 问题定位
针对上文测试的结果,现有代码框架下,整体的日志索引写入速度对用户数量有很大关联。其根本原因是对每个用户创建一个线程,造成在大量用户写入的情况下,存在大量的线程,程序大量的时间都用在了线程的上下文的切换上。
1.4 线程池索引模型
对于用户随着用户数量增多而线程数增加的问题,首先想到的是使用线程池,用户处理日志的逻辑添加到线程池队列,线程池的线程对队列的任务进行处理。这样可以固定线程数最大为线程池的最大线程数量。
1.4.1 测试结果
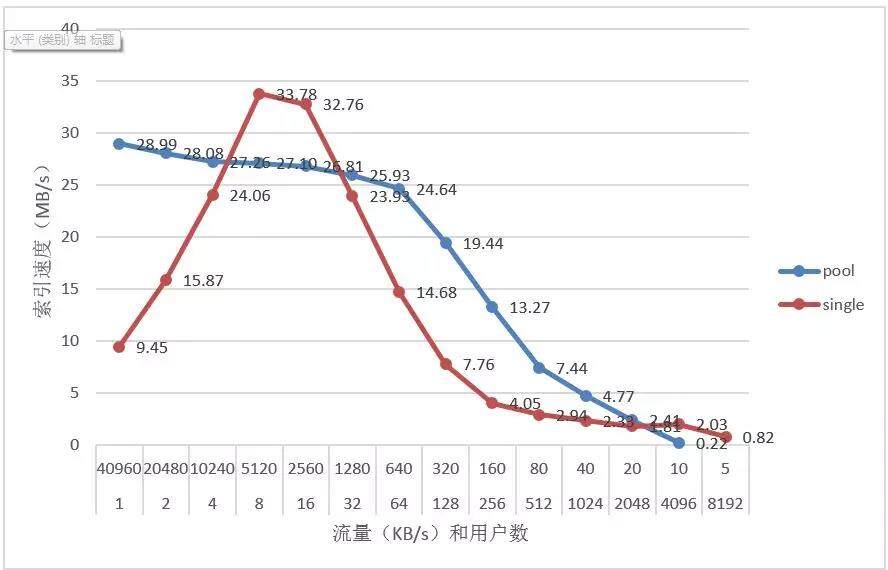
其中 pool 代表线程池索引模型、single 代表单线程索引模型
1.4.2 结果分析
线程池在小用户量情况下,其索引速度相对较稳定
随着用户数量的增加,线程池模型的索引速度也会显著的降低
1.4.3 问题定位和分析
对于随着用户数量增加索引速度下降的问题,多线程只会启动固定线程数,用户数量的增加对其索引速度不会有很大的影响,按理其索引速度不会有很大的影响。
为了找到这个问题的原因,提出了很多种可能性,如是否是用户流量太高、索引缓存设置太低、刷新时间太短等。但经过测试,这些可能性都被排除了,线程池模型索引速度在用户数大于 500 以后就会出现明显的很低情况。
最后,通过研究 Lucene 的多线程索引模型,找到了可能导致这种现象的原因。
首先,Lucene 索引都是通过 IndexWriter 对象完成的,每个用户都包含一个 IndexWriter 对象,对应了用户的索引文件夹。也就是说,有多少个用户,就有多少个索引文件夹。在大量用户同时写入数据时候,需要频繁的在多个文件夹下切换,频繁的更换写入的文件夹,也即进行随机写入,所以索引的速度会降低。
其次,而 IndexWriter 是线程安全的对象,其能够支持多线程访问,实现多线程同时访问的原理如下。
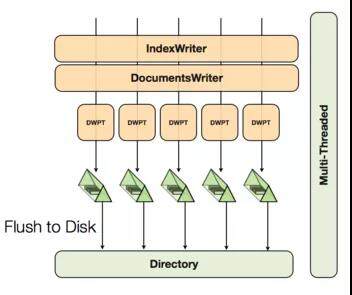
Lucene 为了支持多线程,会对每个访问 IndexWriter 的线程缓存一个 DWPT(Document Writer Per Thread)对象,不同线程对相同 IndexWriter 使用的是不同的 DWPT 对象。每个 DWPT 对象能够独立的完成对数据进行索引,对一个索引来说,多线程索引能够显著的提升其索引速度。这个从之前单个用户在线程池模型其索引速度明显大于单用户单线程索引速度快也能看出。
正是 Lucene 对多线程的这个优化造成线程池模型的问题:由于多线程访问 IndexWriter 会缓存多个 DWPT 对象,每个 DWPT 对象其对应的就是一个小的索引文件,在多线程写入时会频繁的在每个 DWPT 上进行切换,也就是在多个文件上进行频繁写入切换。例如:如果线程池中有 20 个线程,在对某个用户写入索引的时候,会生成 20 个文件进行同时写入。可以预见,当用户数量增加时,同时写入的文件数量等于用户数线程数。当用户为 512 个是,同时写入文件的数量为 51220=10240 个文件。高频率的随机写入请求的,整体的索引数据会有明显的下降。
1.5 多线程 Multi 组合索引模型
找到了线程池模型下大量用户索引速度慢的问题是由于多个线程同时对每个用户进行索引造成的,就需要为每个用户配置单独的线程进行索引,但是这样就和之前的单线程模型一样,会有大量线程频繁切换的问题了。要解决这个问题有如下两个关键点:
索引的线程数不能过多,避免频繁的线程上下文切换。
每个用户需要在固定线程下进行索引,避免同一个索引下生成多个小索引文件
为此提出了多线程 Multi 组合索引模型,其结合了线程池模型和单线程模型的优势,有效的解决了上述问题。
1.5.1 模型原理
1、建立多个只有单线程的线程池模型,每个线程池只有一个线程工作,且对每个线程池进行编号。
2、以用户 id 进行 hash,得到的结果对线程池总数进行求余,得到的数即为该用户所在的线程编号。将该用户的索引任务提交到对应编号的线程池中,实现单个用户只对应一个线程进行索引处理。
3、新建一个多线程数(数量为 4-20)的线程池,并对所有用户流量进行监控,将用户流量大于一个固定阈值(如:1MB/s)的用户索引统一交由该线程池进行处理。增加大流量用户索引速度。
Multi 模型总共具有两种线程池,第一种为单线程线程池,只有单个线程进行处理任务,用户的索引任务将会固定到某个单线程池中。第二种为普通的多线程线程池,其包含多个线程同时处理任务,主要面向的是对大流量用户,并发索引,增加索引能力。这么做的前提是某个节点大用户数量不会很多,以每个用户 5M/s 的流量下,10 个用户总体流量就达到 50M/s,已经远远超过一个节点的总体速度了,采用多线程并发同时索引能够极大的增加索引能力的同时索引的文件最大也就 50 个,是完全能够接受的。
1.5.2 Multi 模型测试结果
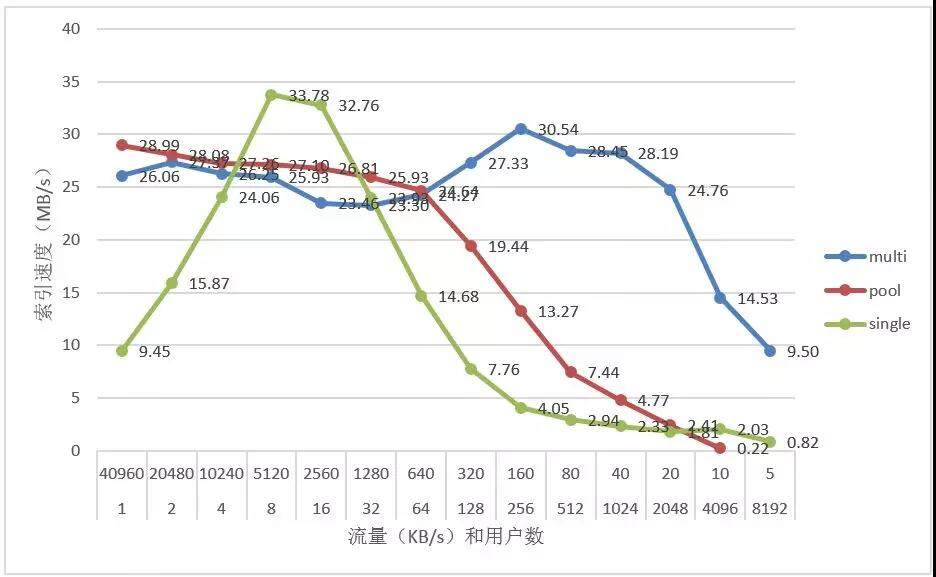
1.5.3 结果分析
通过对比三种模型 single 单用户单线程模型、pool 线程池模型、multi 多线程组合模型的结果可以发现,Multi 模型在用户数量小于 2000 的情况下都能保持一个相当高的总体索引写入速度。在用户数量大于 2000,由于此时同时索引的文件数量过多,过多的对磁盘进行随机读写,造成磁盘的写入速度降低,索引速度有所下降。
1.6 多应用场景测试
上述的测试场景比较单一,所有用户的流量相同,用户数量增大,每个用户平均流量降低。而现网可能出现很多其他场景,为了进一步说明 Single、Pool、Multi 模型的差别,对比 Multi 模型的优势,创建了多种用户流量测试场景和参数,具体测试场景说明如下:
pool 线程数速度测试
单用户大流量
多用户小流量(10M/s)
固定大用户多小用户流量测试(24M/s)
multi 测试
1.6.1 测试参数说明
为了完成上述测试,编写了一个测试脚本,其中包含了各种运行参数设置,方便实现各种测试场景下。
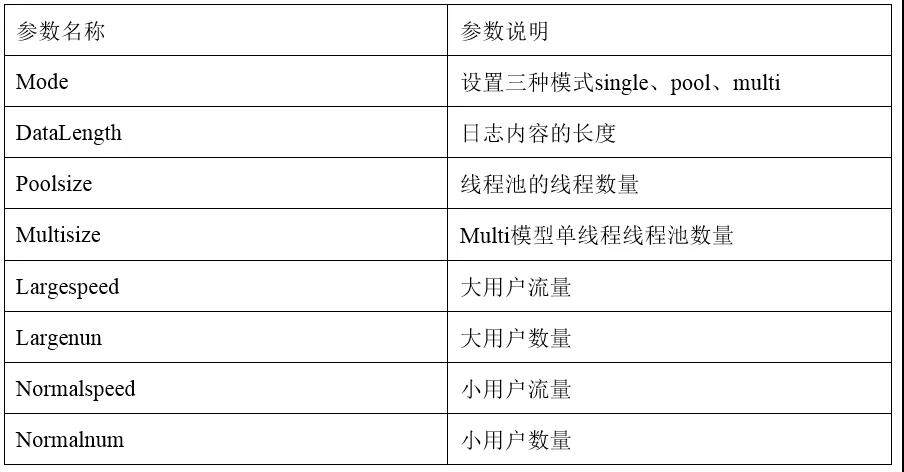
1.6.2 pool 线程数速度测试
测试目的:测试不同线程数量对单个单用户索引速度的影响
结果分析:对于单个用户,并发索引的线程数量的增加,其索引速度有所增加,线程数达到 8 以后,其整体索引速度趋于稳定。
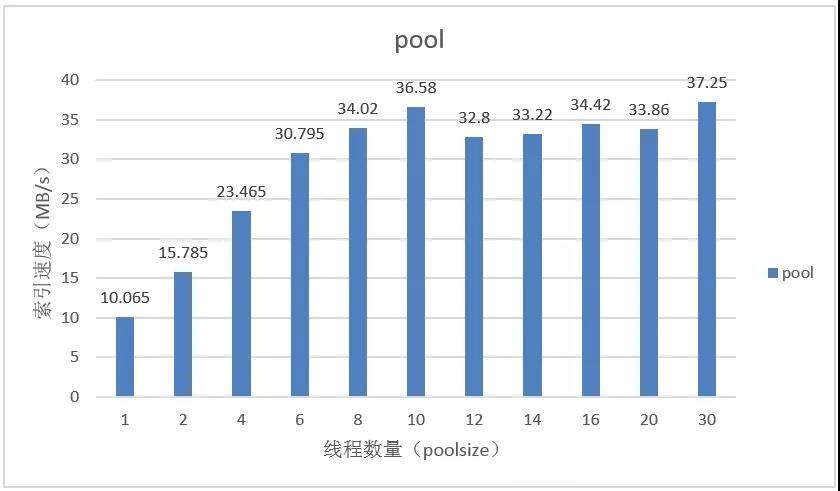
1.6.3 单用户大流量
测试目的:测试单个用户其流量增加三种模型的整体索引速度的变化
结果分析:对于单个用户,随着其流量的增加,single 模型索引速度维持不变,multi 和 pool 模型都能够显著增加。说明 pool 和 multi 模型其对大用户的最大索引速度都能够达到 30MB/s 的较高水平。
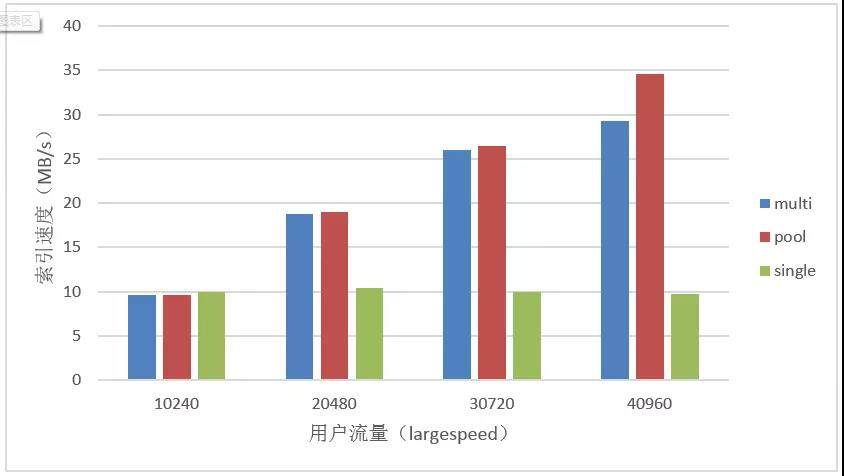
1.6.4 多用户小流量(10M/s)
测试目的:在多个用户,每个用户的流量较小的情况下,三种模型的索引速度对比。
结果分析:Multi 模型能够很好的处理多个小用户的场景,其整体索引速度能够维持稳定不变,而 pool 和 single 模型都对大量用户比较敏感,用户数大于 500,索引速度会有明显的下降。
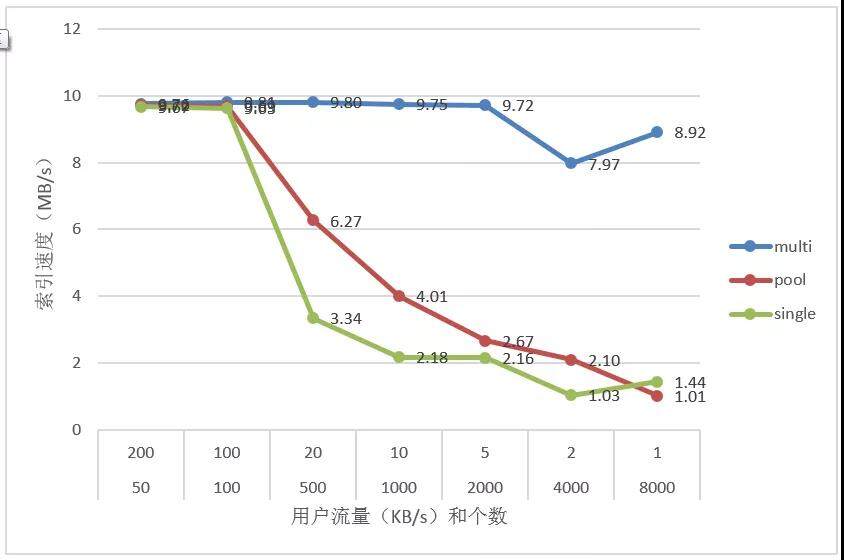
1.6.5 固定大用户多小用户流量测试(24M/s)
测试目的:测试在有几个大流量用户的情况下,小用户的数量对整体索引速度的影响。
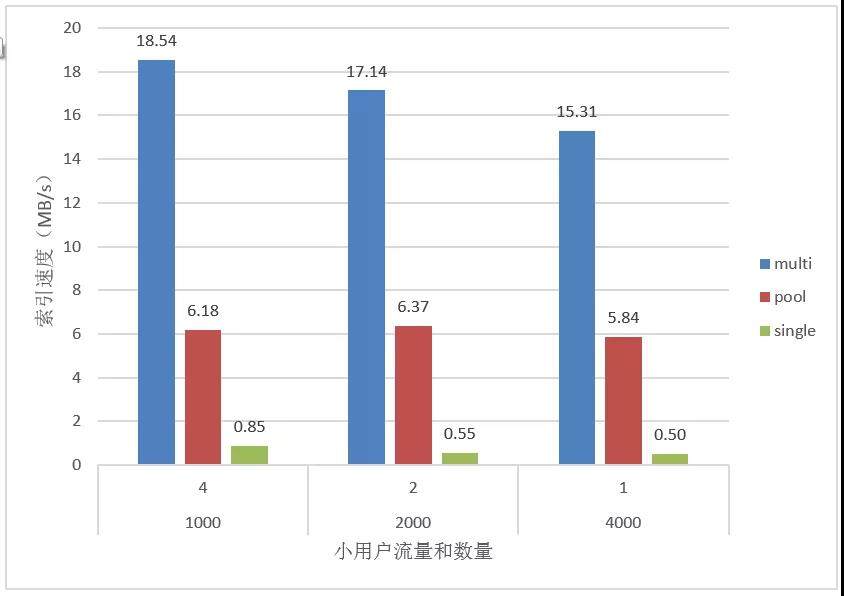
其中,大用户数量为 4,大用户流量为 5M/s
1.6.6 multi 模型测试
测试目的:测试 multi 模型在各种参数情况下其索引速度的变化
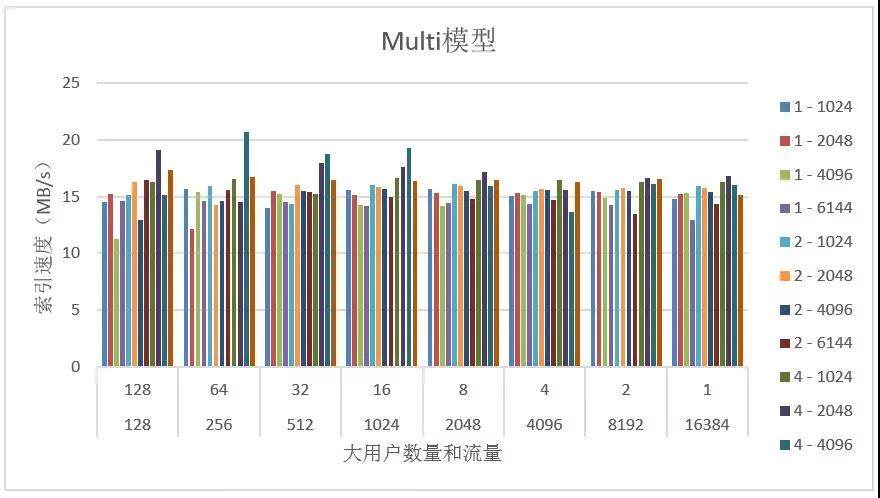
其中图例 1-1024 表示总体小用户数量为 1024 个,每个小用户流量为 1KB/s。
结果分析:从测试结果可以看出,Multi 模型在不同小用户数量和流量,不同大用户数量和流量下具有较稳定的索引速度。
1.7 结论
根据上述各种场景的测试,可以得到 Multi 模型对比 Single 和 Pool 模型都有显著的优势,其能够稳定的维持较高的索引速度,在一定范围内,用户数量的增加,对其索引速度的影响最小。
1.8 Multi 模型进一步改进
Multi 的组合模型相对于单线程和线程池在大量用户情况下有着较大的索引速度的提升,但是还有很多地方可以进一步优化:
1、 线程数量的优化,线程数量的大小直接影响着索引的速度,既不能太多也不能太少,需要根据实际的运行环境调节出一个最优的线程数量。
2、 用户分配策略,现在是根据用户的 id 进行 hash 分配到不同的线程进行索引,会造成不同线程处理的整体流量不均匀状况,不能充分利用每个线程的处理能力。需要研究一种更好的用户分配策略。
本文的测试还有很多不足之处,还有很多可以优化的地方,测试的方案也比较简单,只是为以后的进一步优化提供指导,接下来还需要进一步优化方案。
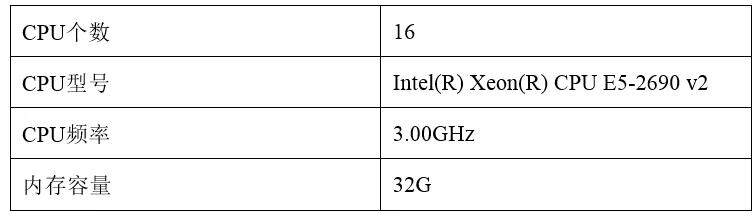
1.9 测试环境参考
本次测试的环境为申请的 AOM-技术项目环境,测试节点的信息如下:
1.9.1 测试数据的获取
本次测试使用本地的日志文件作为日志数据进行索引。同时为了尽可能符合真实的日志内容,本次测试从华为公有云获取到的 AOM 服务自身产生的日志数据,该日志文件的大小为 20G。
本文转载自华为云产品与解决方案公众号。
原文链接:https://mp.weixin.qq.com/s/19C74VlkknN0uHq6-NRowg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论