

发票是会计核算的原始依据。于国家,它是保障税收的基石;于企业,它是公司做账的依据;于个人,它是报销的凭证。
临近年底,为了赶在截止日期前完成封账,各大公司的财务部门开始加急投入人力、时间成本将发票录入系统,工作压力大,运营成本昂贵。
以增值税发票为例,财务人员通常需要肉眼核对长达十几位的发票代码、纳税人识别号等,并手动录入关键数据。这样沉重的负担无疑会导致发票出错风险激增,也拖累公司整体财务管理效率!
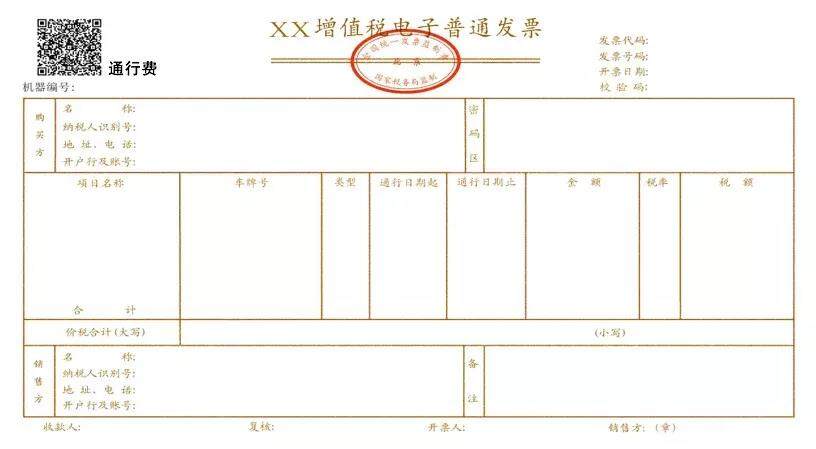
增值税电子普通发票格式
票据 OCR 为何难以落地?
OCR,全称光学字符识别(Optical Character Recognition),是计算机视觉的一个分支,主要包含文本检测和文本识别两大关键技术:前者用于定位图像中的文字,后者负责将定位到的文字图像转化为可编辑的文本。
发展至今,OCR 的应用已经十分广泛,市场上的 OCR 产品也比比皆是,但它们的在现实场景下的识别效果却良莠不齐。这是因为作为一种基于图像的文字识别技术,OCR 的识别效果不仅取决于算法,输入图像的质量也严重影响着其最终准确率。
对于算法:目前业界针对文本检测和文本识别已经提出了很多优秀的“轮子”。但检测模型只能完成文字定位,识别模型只能完成文字转录,为了形成一套完整的 OCR 流程,企业需要对各类已有“轮子”进行定制化组合。考虑到 AI 模型的开发难度,这就为企业增加了引进 AI 技术专家的成本。
对于图像质量:通用的 OCR 方法在高质量扫描图像上都能取得较好的效果,但在实际应用中,财务部门上传的票据大多存在分辨率低、光照不均匀、背景杂乱、拍摄角度随意、版式复杂多样等问题,这些都可能影响最终的识别结果。
同时,OCR 服务在许多场景下是系统中连接着后续业务逻辑的子模块。为方便后续业务的进行,系统不仅要知道图像上包含哪些文字,更需要结构化文本内容,这也增加了 OCR 的技术难度。以增值税发票的识别为例,OCR 服务的最终返回结果类似如下的形式:
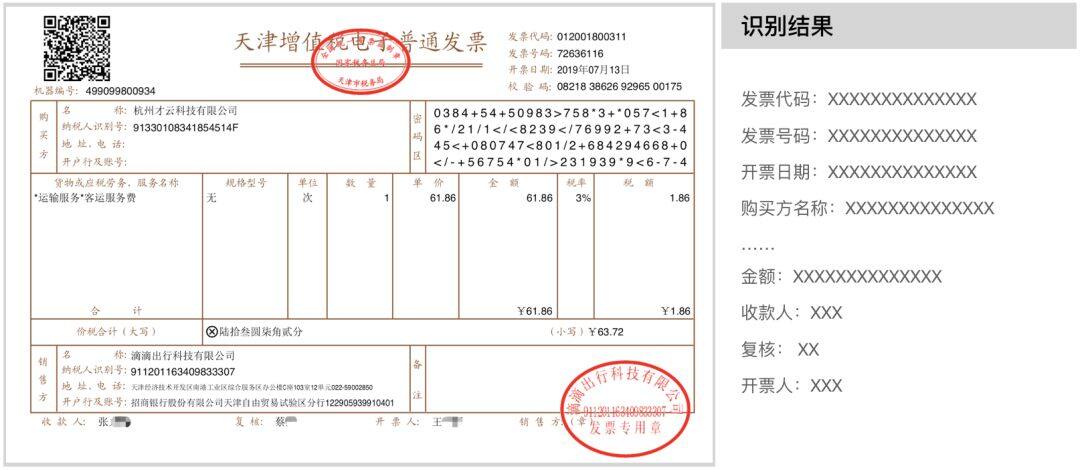
因此,从实际落地的角度看,当下有很多 OCR 产品只是炫技之作,它们忽视了企业的现实情况,无法从平台级别实现一套通用的票据结构化识别流程,方便非 AI 专家构建定制化 OCR 解决方案,提升 AI 产品在企业系统中的长期价值。
才云票据结构化识别通用 Pipeline
针对上一节提出的问题,才云算法团队(Cabernet 团队)经多方调研和尝试,总结出了企业对通用票据 OCR 落地应用的三项主要需求:
构建通用的票据结构化识别流程,方便非 AI 专家灵活、合理利用“轮子”;
拥有多角度检测和识别的能力,在图像质量不理想的情况下仍能保持高准确率;
结构化不同票据的票面信息,为每一种票据做定制化处理。
结合在五百强企业财务部门的应用实践,才云 Cabernet 团队针对当下所有具有明确版式的票据,设计了一套通用的结构化识别流程(Pipeline),整个 Pipeline 包含票据提取、票据标准化、文本检测及结构化和文本识别四大模块。
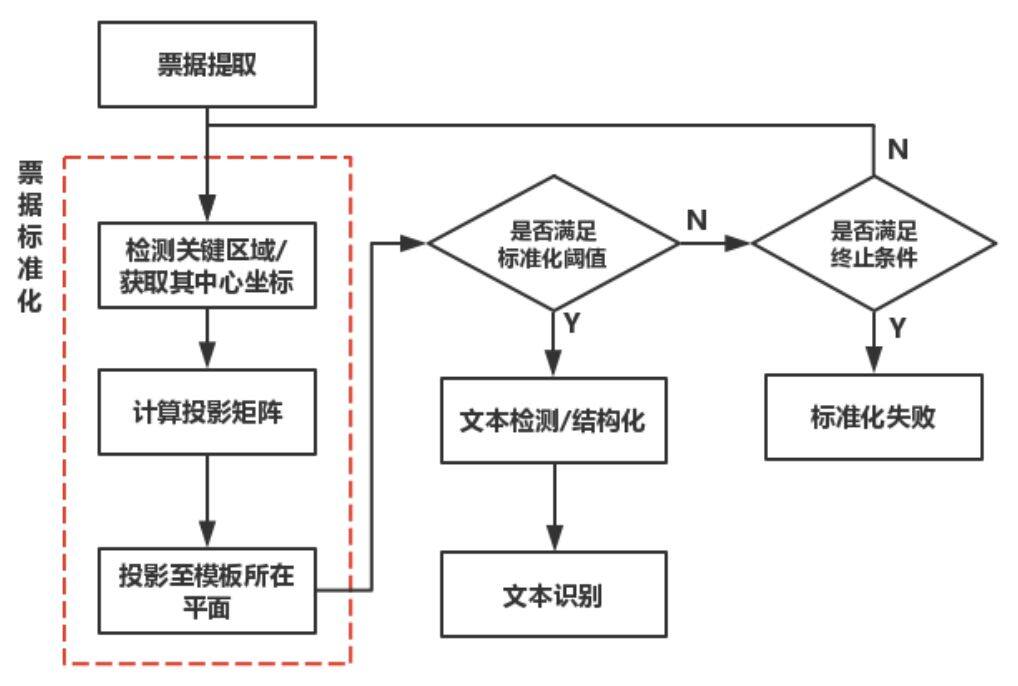
才云票据结构化识别通用 Pipeline
票据提取
首先,票据提取模块的输入是用户上传的图像。由于报销人可能会同时提交不同类型的多种票据,其中甚至夹杂公司不支持报销的纸质材料,Pipeline 的第一个环节需要完成感兴趣票据的自动分类和裁切(未支持的票据种类视为不感兴趣),如下图所示:
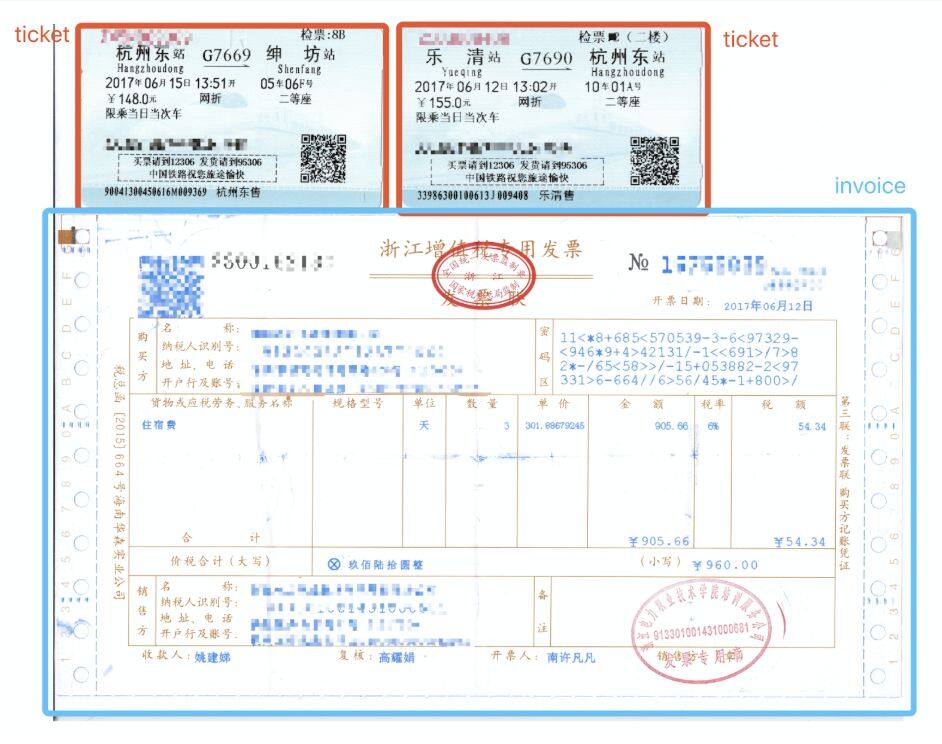
票据提取结果示例图(不同类型的票据用边界框颜色不同)
票据标准化
在企业中,票据图像的采集一般由人工通过扫描仪、高拍仪、手机等设备完成,采集角度不固定,导致无法使用标准模板上的先验信息,影响结构化识别的准确率。
该问题虽然可以通过规范用户的采集方式缓解,但出于对提高用户体验、加快信息采集效率的考量,才云 Cabernet 团队最终选择在 Pipeline 中实现票据标准化。
标准化是通过空间映射将输入图像转换成标准模板。方法是在输入图像和标准票据模板上寻找特征点对计算映射矩阵 H,通过 H 将输入票据投影到模板平面。这包含两个问题:
问题一:在标准模板上的特征点选择标准——选取的点应尽量均匀分布在图像四周,可以最大程度地保证投影之后图像信息的完整性;
问题二:在输入图像上找到标准模板上特征点的映射——在模板图像上定义关键区域,训练检测(实例分割)模型预测输入图像的关键区域,以输入图像和模板上的区域中心作为特征点对。
*注:关于问题二,此处推荐使用 Mask R-CNN 完成区域检测并以 Mask 中心为特征点,避免常用检测算法的矩形框中心在拍摄角度随意的情况下无法准确描述特征点的位置。
以火车票为例,我们可以定义如下的关键区域:起始站、车次号、到达站、时间/价格信息、座位信息、身份证、二维码。图中绿色的点代表该区域的中心点:

关键区域模板示意图
标准化前(左)和标准化后(右)
文本检测及结构化
这一环节的主要任务是检测、定位各类信息在票据上的位置,方便后续文字识别。
对于标准化后的票据,票面上的文本已基本被调整至水平方向,因此无论是传统文字检测方法还是深度学习文本检测模型,它们都能在票据上完成文本定位。
*注:由于传统方法易受图像质量的影响,抗噪能力不强,这里还是推荐使用场景适应性更好的深度学习方法。
以火车票为例:

文本检测结果(右)和关键字段模板示意图(左)
结构化检测结果(不同颜色的框代表属于不同字段)
文本识别
至此,整个 Pipeline 中最难的两个部分“标准化”和“结构化检测”都已经完成,相当于用户已经知道当前输入的票据上的感兴趣字段所在的位置,剩下的只需把关键字段位置对应的图像转换成文本内容即可。
文本识别可以将整个关键字段切割成单字逐个识别,也可以直接识别整条文本行,下图是才云 Cabernet 团队基于文本识别模型,对整条关键字段进行识别的效果。

结构化识别结果示意图
未来展望
本文提出的票据结构化通用 Pipeline 是一套针对常规票据从输入到最终结构化输出的最佳实践,包含票据分类、自动裁切、版面标准化、结构化检测与识别等多项 OCR 不可或缺的步骤及实现方法。
为帮助更多企业自主开发票据识别 OCR 系统,才云 AI 中台 Caicloud Clever 即将上线票据结构化识别通用 Pipeline,利用平台级 AI 开发能力及在国内诸多大型企业积累的丰富落地经验,帮助用户灵活、自由地定制各环节模型,轻松实现票据种类的扩展,并快速在生产环境中落地。
为进一步服务用户,才云 Cabernet 团队下一步的工作将围绕两个方向展开:
设计通用 OCR 模型框架:通过规范化 OCR 模型的输入输出,统一训练、推理的流程和接口,实现在 Pipeline 中的即插即用;
开展对自动数据增强(Data Augmentation)的研究:在数据有限的情况下,低成本、更稳健地提升 OCR 的性能。
本文转载自才云 Caicloud 公众号。
原文链接:https://mp.weixin.qq.com/s/6XcH_jfULfGZQCDdehQzfg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论