
在谈论数据库架构和数据库优化的时候,我们经常会听到“分库分表”、“分片”、“Sharding”…这样的关键词。让人感到高兴的是,这些朋友所服务的公司业务量正在(或者即将面临)高速增长,技术方面也面临着一些挑战。让人感到担忧的是,他们系统真的就需要“分库分表”了吗?“分库分表”有那么容易实践吗?为此,笔者整理了分库分表中可能遇到的一些问题,并结合以往经验介绍了对应的解决思路和建议。
垂直分表
垂直分表在日常开发和设计中比较常见,通俗的说法叫做“大表拆小表”,拆分是基于关系型数据库中的“列”(字段)进行的。通常情况,某个表中的字段比较多,可以新建立一张“扩展表”,将不经常使用或者长度较大的字段拆分出去放到“扩展表”中,如下图所示:
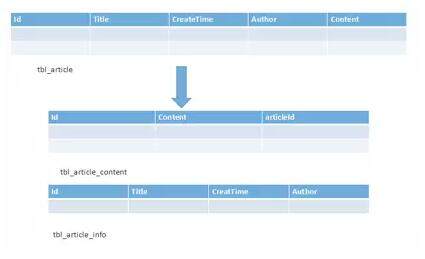
小结
在字段很多的情况下,拆分开确实更便于开发和维护(笔者曾见过某个遗留系统中,一个大表中包含 100 多列的)。某种意义上也能避免“跨页”的问题(MySQL、MSSQL 底层都是通过“数据页”来存储的,“跨页”问题可能会造成额外的性能开销,这里不展开,感兴趣的朋友可以自行查阅相关资料进行研究)。
拆分字段的操作建议在数据库设计阶段就做好。如果是在发展过程中拆分,则需要改写以前的查询语句,会额外带来一定的成本和风险,建议谨慎。
垂直分库
垂直分库在“微服务”盛行的今天已经非常普及了。基本的思路就是按照业务模块来划分出不同的数据库,而不是像早期一样将所有的数据表都放到同一个数据库中。如下图:
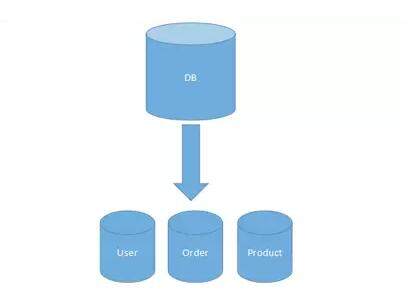
小结
系统层面的“服务化”拆分操作,能够解决业务系统层面的耦合和性能瓶颈,有利于系统的扩展维护。而数据库层面的拆分,道理也是相通的。与服务的“治理”和“降级”机制类似,我们也能对不同业务类型的数据进行“分级”管理、维护、监控、扩展等。
众所周知,数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于 Web 和应用服务器来讲,是比较难实现“横向扩展”的。数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破 IO、连接数及单机硬件资源的瓶颈,是大型分布式系统中优化数据库架构的重要手段。
然后,很多人并没有从根本上搞清楚为什么要拆分,也没有掌握拆分的原则和技巧,只是一味的模仿大厂的做法。导致拆分后遇到很多问题(例如:跨库 join,分布式事务等)。
水平分表
水平分表也称为横向分表,比较容易理解,就是将表中不同的数据行按照一定规律分布到不同的数据库表中(这些表保存在同一个数据库中),这样来降低单表数据量,优化查询性能。最常见的方式就是通过主键或者时间等字段进行 Hash 和取模后拆分。如下图所示:
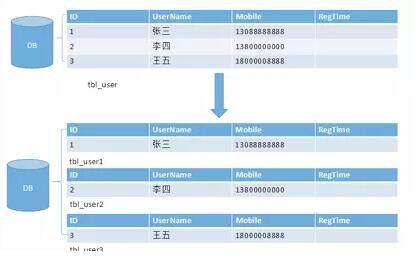
小结
水平分表,能够降低单表的数据量,一定程度上可以缓解查询性能瓶颈。但本质上这些表还保存在同一个库中,所以库级别还是会有 IO 瓶颈。所以,一般不建议采用这种做法。
水平分库分表
水平分库分表与上面讲到的水平分表的思想相同,唯一不同的就是将这些拆分出来的表保存在不同的数据中。这也是很多大型互联网公司所选择的做法。如下图:
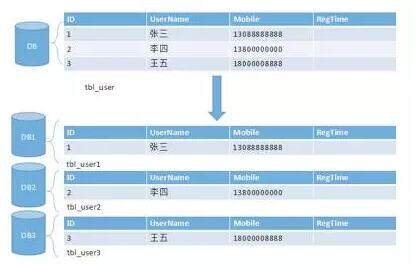
某种意义上来讲,有些系统中使用的“冷热数据分离”(将一些使用较少的历史数据迁移到其他的数据库中。而在业务功能上,通常默认只提供热点数据的查询),也是类似的实践。在高并发和海量数据的场景下,分库分表能够有效缓解单机和单库的性能瓶颈和压力,突破 IO、连接数、硬件资源的瓶颈。当然,投入的硬件成本也会更高。同时,这也会带来一些复杂的技术问题和挑战(例如:跨分片的复杂查询,跨分片事务等)
分库分表的难点
垂直分库带来的问题和解决思路:
跨库 join 的问题
在拆分之前,系统中很多列表和详情页所需的数据是可以通过 sql join 来完成的。而拆分后,数据库可能是分布式在不同实例和不同的主机上,join 将变得非常麻烦。而且基于架构规范,性能,安全性等方面考虑,一般是禁止跨库 join 的。那该怎么办呢?首先要考虑下垂直分库的设计问题,如果可以调整,那就优先调整。如果无法调整的情况,下面笔者将结合以往的实际经验,总结几种常见的解决思路,并分析其适用场景。
跨库 Join 的几种解决思路
全局表
所谓全局表,就是有可能系统中所有模块都可能会依赖到的一些表。比较类似我们理解的“数据字典”。为了避免跨库 join 查询,我们可以将这类表在其他每个数据库中均保存一份。同时,这类数据通常也很少发生修改(甚至几乎不会),所以也不用太担心“一致性”问题。
字段冗余
这是一种典型的反范式设计,在互联网行业中比较常见,通常是为了性能来避免 join 查询。
举个电商业务中很简单的场景:
“订单表”中保存“卖家 Id”的同时,将卖家的“Name”字段也冗余,这样查询订单详情的时候就不需要再去查询“卖家用户表”。
字段冗余能带来便利,是一种“空间换时间”的体现。但其适用场景也比较有限,比较适合依赖字段较少的情况。最复杂的还是数据一致性问题,这点很难保证,可以借助数据库中的触发器或者在业务代码层面去保证。当然,也需要结合实际业务场景来看一致性的要求。就像上面例子,如果卖家修改了 Name 之后,是否需要在订单信息中同步更新呢?
数据同步
定时 A 库中的 tab_a 表和 B 库中 tbl_b 有关联,可以定时将指定的表做同步。当然,同步本来会对数据库带来一定的影响,需要性能影响和数据时效性中取得一个平衡。这样来避免复杂的跨库查询。笔者曾经在项目中是通过 ETL 工具来实施的。
系统层组装
在系统层面,通过调用不同模块的组件或者服务,获取到数据并进行字段拼装。说起来很容易,但实践起来可真没有这么简单,尤其是数据库设计上存在问题但又无法轻易调整的时候。
具体情况通常会比较复杂。下面笔者结合以往实际经验,并通过伪代码方式来描述。
简单的列表查询的情况
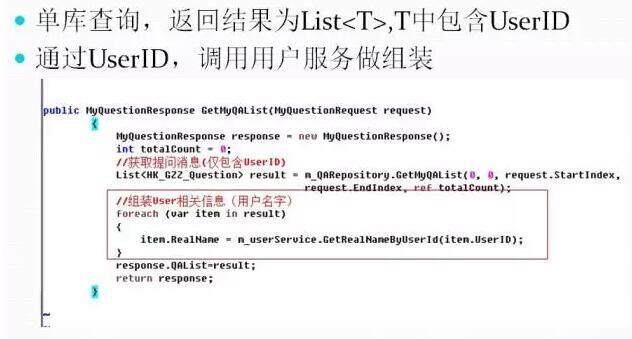
伪代码很容易理解,先获取“我的提问列表”数据,然后再根据列表中的 UserId 去循环调用依赖的用户服务获取到用户的 RealName,拼装结果并返回。
有经验的读者一眼就能看出上诉伪代码存在效率问题。循环调用服务,可能会有循环 RPC,循环查询数据库…不推荐使用。再看看改进后的:

这种实现方式,看起来要优雅一点,其实就是把循环调用改成一次调用。当然,用户服务的数据库查询中很可能是 In 查询,效率方面比上一种方式更高。(坊间流传 In 查询会全表扫描,存在性能问题,传闻不可全信。其实查询优化器都是基本成本估算的,经过测试,在 In 语句中条件字段有索引的时候,条件较少的情况是会走索引的。这里不细展开说明,感兴趣的朋友请自行测试)。
小结
简单字段组装的情况下,我们只需要先获取“主表”数据,然后再根据关联关系,调用其他模块的组件或服务来获取依赖的其他字段(如例中依赖的用户信息),最后将数据进行组装。
通常,我们都会通过缓存来避免频繁 RPC 通信和数据库查询的开销。
列表查询带条件过滤的情况
在上述例子中,都是简单的字段组装,而不存在条件过滤。看拆分前的 SQL:
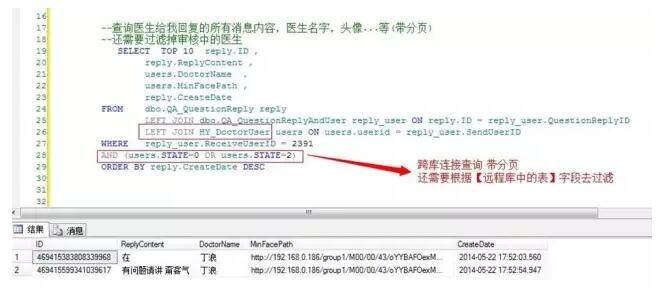
这种连接查询并且还带条件过滤的情况,想在代码层面组装数据其实是非常复杂的(尤其是左表和右表都带条件过滤的情况会更复杂),不能像之前例子中那样简单的进行组装了。试想一下,如果像上面那样简单的进行组装,造成的结果就是返回的数据不完整,不准确。
有如下几种解决思路:
- 查出所有的问答数据,然后调用用户服务进行拼装数据,再根据过滤字段 state 字段进行过滤,最后进行排序和分页并返回。
这种方式能够保证数据的准确性和完整性,但是性能影响非常大,不建议使用。
2. 查询出 state 字段符合 / 不符合的 UserId,在查询问答数据的时候使用 in/not in 进行过滤,排序,分页等。过滤出有效的问答数据后,再调用用户服务获取数据进行组装。
这种方式明显更优雅点。笔者之前在某个项目的特殊场景中就是采用过这种方式实现。
跨库事务(分布式事务)的问题
按业务拆分数据库之后,不可避免的就是“分布式事务”的问题。以往在代码中通过 spring 注解简单配置就能实现事务的,现在则需要花很大的成本去保证一致性。这里不展开介绍,
感兴趣的读者可以自行参考《分布式事务一致性解决方案》,链接地址:
http://www.infoq.com/cn/articles/solution-of-distributed-system-transaction-consistency
垂直分库总结和实践建议
本篇中主要描述了几种常见的拆分方式,并着重介绍了垂直分库带来的一些问题和解决思路。读者朋友可能还有些问题和疑惑。
1. 我们目前的数据库是否需要进行垂直分库?
根据系统架构和公司实际情况来,如果你们的系统还是个简单的单体应用,并且没有什么访问量和数据量,那就别着急折腾“垂直分库”了,否则没有任何收益,也很难有好结果。
切记,“过度设计”和“过早优化”是很多架构师和技术人员常犯的毛病。
2. 垂直拆分有没有原则或者技巧?
没有什么黄金法则和标准答案。一般是参考系统的业务模块拆分来进行数据库的拆分。比如“用户服务”,对应的可能就是“用户数据库”。但是也不一定严格一一对应。有些情况下,数据库拆分的粒度可能会比系统拆分的粒度更粗。笔者也确实见过有些系统中的某些表原本应该放 A 库中的,却放在了 B 库中。有些库和表原本是可以合并的,却单独保存着。还有些表,看起来放在 A 库中也 OK,放在 B 库中也合理。
如何设计和权衡,这个就看实际情况和架构师 / 开发人员的水平了。
3. 上面举例的都太简单了,我们的后台报表系统中 join 的表都有 n 个了, 分库后该怎么查?
有很多朋友跟我提过类似的问题。其实互联网的业务系统中,本来就应该尽量避免 join 的,如果有多个 join 的,要么是设计不合理,要么是技术选型有误。请自行科普下 OLAP 和 OLTP,报表类的系统在传统 BI 时代都是通过 OLAP 数据仓库去实现的(现在则更多是借助离线分析、流式计算等手段实现),而不该向上面描述的那样直接在业务库中执行大量 join 和统计。
由于篇幅关系,下篇中我们再继续细聊“水平分库分表”相关的话题。
作者介绍
丁浪,技术架构师。关注高并发、高可用的架构设计,对系统服务化、分库分表、性能调优等方面有深入研究和丰富实践经验。热衷于技术研究和分享。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论