

近日,数据挖掘顶会 ACM KDD 2023 在美国长滩开幕。在大模型开放日上,Open AI、Meta、智谱 AI、Google DeepMind、Microsoft、Intel 等公司研究学者展开深度交流。微软首席科学家 & 技术院士 Jaime Teevan、OpenAI ChatGPT 团队成员 Jason Wei、智谱 AI CEO 张鹏、谷歌 DeepMind 首席科学家/研究主管 Denny Zhou,以及 Meta FAIR 研究工程师 Vedanuj Goswami 就大模型赋能未来工作、语言模型推理能力、Llama 2、GLM-130B 和 ChatGLM、大模型范式与挑战等主题进行了分享。
OpenAI Jason Wei:大语言模型的复兴
Jason Wei 是 OpenAI ChatGPT 研发团队成员之一。此前他在谷歌大脑团队担任高级研究科学家,期间致力于推广思维链提示,共同领导了指令调优前期工作,并撰写关于大语言模型涌现的工作。
Jason 在分享中提到,大语言模型的三个主要特征,分别是缩放法则、涌现能力和推理能力,并探讨了这些特征如何影响自己的 AI 研究领域。

Jason 还介绍了他和其他人在 LLM 推理能力上所做的研究工作:
第一,思维链(Chain-of-Thought)。如果你用一个想法来提示 LLM,它给出的回复质量就会飞跃。
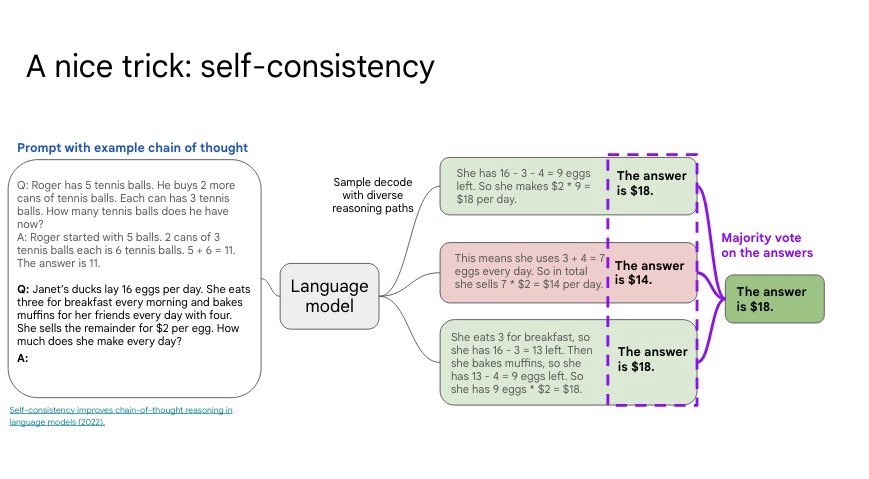
第二,自我一致性(Self-Consistency)。对多次生成进行采样调查,然后选择最常见的答案。自我一致性改善了语言模型中的思维链推理。
第三,从最少到最多的提示(Least-to-Most Prompting),这要求 LLM 将问题分解成不同的任务,并从易到难进行排序。
智谱 AI 张鹏 :从 GLM-130B 到 ChatGLM
作为智谱 AI(Zhipu AI)的 CEO,张鹏带领团队成功开发了 1300 亿参数的双语(中英文)大语言模型 GLM-130B。自 2022 年 8 月起,该模型已开源,在准确性和鲁棒性方面可媲美 GPT-3 davinci。
2023 年 3 月 14 日,基于 GLM-130B,智谱 AI 正式发布了 ChatGLM,一款类 ChatGPT 的对话机器人产品。此外,其开源、紧凑的版本 ChatGLM-6B 与 ChatGLM2-6B 全球下载量超过 5,000,000 次,连续 28 天位居 Hugging Face Trending 榜首,并在 GitHub 上获得超过 4.4 万颗星标。
最近,智谱 AI 还把 ChatGLM 升级到 ChatGLM2,推出了多个参数尺寸,大幅提升了能力,基于 ChatGLM2-6B 的代码生成模型,智谱 AI 还更新了代码生成工具 CodeGeeX2。
张鹏介绍了智谱 AI 自研的 GLM 框架,GLM 的预训练框架是一种自回归填空的方法,集成了 GPT 和 BERT 这两种预训练框架的优势,既能够实现单项注意力的计算,做序列的生成,也可以做到双向注意力的计算,做回归的模型。
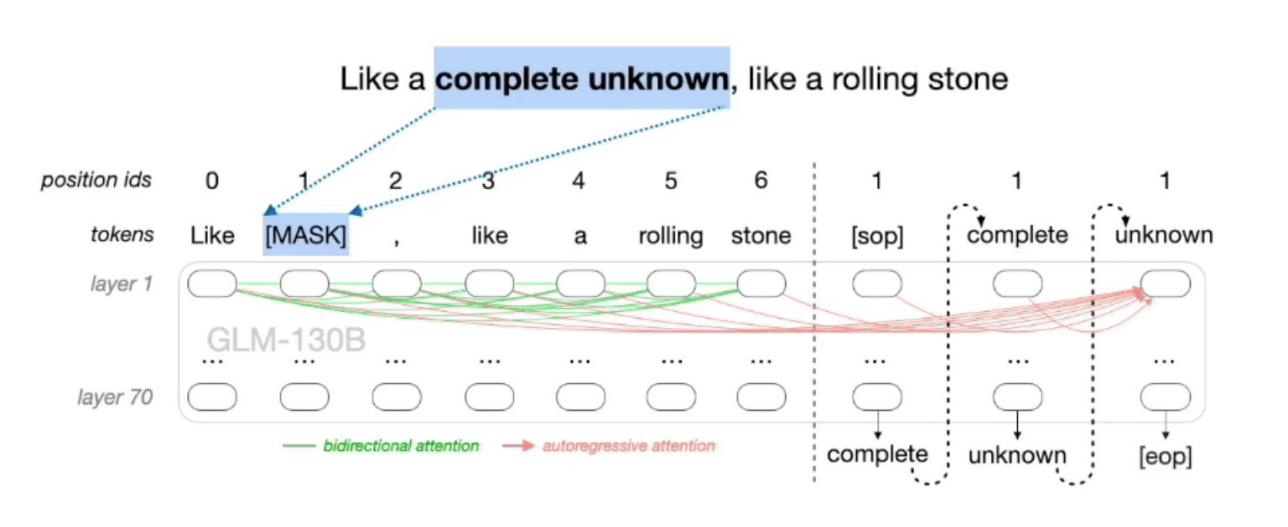
在 GLM 基础上,2022 年 8 月,智谱推出拥有 1300 亿参数的中英双语稠密模型 GLM-130B。得益于新的模型架构,GLM 在许多具有百万参数甚至更少训练步骤的基准测试中,能够在自然语言理解方面实现比 BERT 和 T5 更好的性能。训练一个 1000 亿规模的大型语言模型并非易事,智谱团队解决了许多工程问题和算法上的挑战,包括频繁且随机的硬件故障、训练稳定性等问题,相关细节都发表在 ICLR 2023 的论文中。
微软 Jaime Teevan:LLM 如何塑造未来的工作
Jaime 是微软首席科学家和技术院士,负责公司核心产品中的驱动技术创新。她提倡人们应找到更聪明的方式来充分利用好时间,领导微软的未来工作倡议,探索 AI 和混合办公等如何改变人们完成事情的方式。此前她曾担任微软 CEO 萨提亚·纳德拉的技术顾问,并领导了微软研究院的生产力团队。
此外,Jaime 是 ACM Fellow 以及 ACM SIGIR and SIGCHI Academies 的会员。她还曾荣获 TR35、BECA 和 Karen Sparck Jones 奖。她本科毕业于耶鲁大学,并获得了 MIT 人工智能博士学位。她也是华盛顿大学的客座教授。
Jaime 认为,伴随 LLM 的崛起,未来的工作方式正在发生迅速变化,知识越来越多地蕴含在对话而非文档中。Jaime 探讨了 LLM 如何通过生成符合人们语境和意图的自然语言建议和反馈,以提高人们的工作效率和创造力。要有效地做到这一点,LLM 需要能够利用各种来源的相关内容作为其响应的基础。人们还需要学习新的对话模式,以充分发挥大模型的价值,因为在人际交往中行之有效的模式对 LLM 来说可能并不是最佳的。
此外,Jaime 讨论了提示工程在生产环境中的重要性,并强调能够识别和推荐对话模板的价值。通过对这些研究课题的深入研究,推荐系统界有机会创造一个全新的、更美好的工作未来。
谷歌 DeepMind Denny Zhou:教语言模型学推理
Denny Zhou 是 Google DeepMind 的首席科学家/研究主管,他是推理团队的创立者和现任负责人。主要研究兴趣在于构建和教导大语言模型实现类人的推理能力。他领导的团队已经开发了思维链提示、自洽性解码、最少到最多提示、指令调优(FLAN2)、LLM 自我调试等大语言模型的各种涌现属性。Denny Zhou 曾获得 2022 年谷歌研究技术影响力奖(Google Research Tech Impact Award)。
Denny Zhou 认为,过去数十年,机器学习社区已经开发了大量用来增强学习效率的数据驱动方法,比如半监督学习、元学习、主动学习、迁移学习等。然而,所有这些方法已被证明对于现实世界的 NLP 任务并不是特别有效,由此暴露了机器学习的一大缺陷 ——缺乏推理。人们往往可以从很少的示例中学习,这就归功于推理能力而不是依赖数据统计。
Denny Zhou 表示,谷歌 DeepMind 引领的 LLM 推理工作开发的方法极大缩小了人类智能与机器学习之间的差距,在仅要求很少的注释示例且不需要训练的情况下也能实现新的 SOTA。这些工作,谷歌 CEO 桑达尔·皮查伊在 2021 年的 Google I/O 大会上进行过重点展示。
Meta FAIR Vedanuj Goswami:Llama 2 开放基础和微调聊天模型
上个月,最强的开源大模型 Llama 2 惊艳发布,一夜之间改变了大模型竞争格局。发布之后, Llama 2 模型迅速成为了社区最广泛使用和下载的开源模型之一。Vedanuj 曾经参与训练 Llama 2 系列模型,目前在 Meta AI 的 LLM 研究团队担任研究工程师,重点研究 LLM 预训练和缩放技巧。
Vedanuj 还曾是「No Language Left Behind」(不落下任何语言)和「Universal Speech Translation for Unwritten Languages」(非书面语的通用语音翻译)等翻译项目的研究负责人,并在 FAIR 从事过多模态研究,领导 FLAVA 和 MMF 等著名项目。
Vedanuj 表示,7 月 18 日刚刚发布的 Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体,因为开源且可以直接商用化,吸引了整个业界的关注。
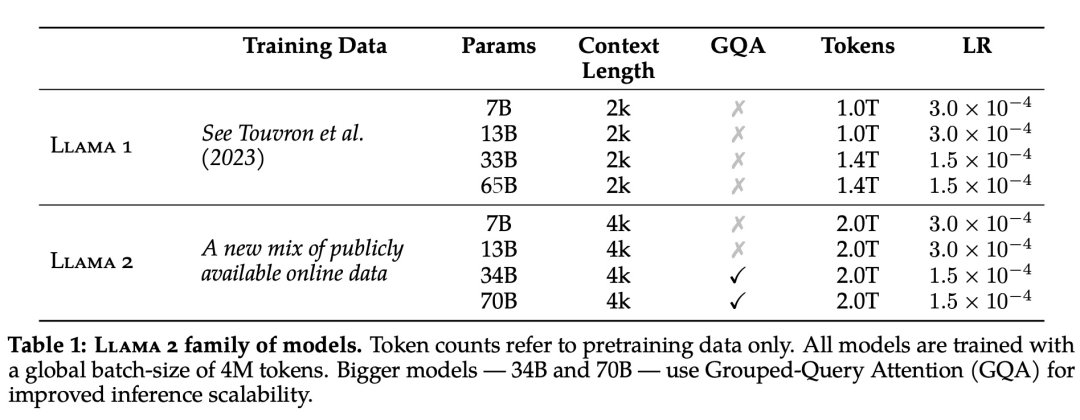
在预训练层面,Llama 2 模型系列以 Llama 1 论文中描述的预训练方法为基础,使用了优化的自回归 transformer,并做了一些改变以提升性能。相比于 Llama 1,Llama 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制。具体来说,Llama 2 预训练模型是在 2 万亿的 token 上训练的,精调 Chat 模型是在 100 万人类标记数据上训练的。
在训练硬件方面,Meta 在其研究超级集群(Research Super Cluster, RSC)以及内部生产集群上对模型进行了预训练。两个集群均使用了 NVIDIA A100。在 Meta 的评估中,多项测评结果显示,Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
当然,对于今天的大模型来说,「安全」是一个重要性不亚于「性能」的指标。在 Llama 2 的研发过程中,Meta 使用了三个常用基准评估其安全性:
真实性,指语言模型是否会产生错误信息,采用 TruthfulQA 基准;
毒性,指语言模型是否会产生「有毒」、粗鲁、有害的内容,采用 ToxiGen 基准;
偏见,指语言模型是否会产生存在偏见的内容,采用 BOLD 基准。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论