
Selenium 团队最近发布了 Selenium 2 (又名 Selenium WebDriver)。主要新功能是集成了 WebDriver——曾经是 Selenium 1(又名 Selenium RC)的竞争对手。Selenium RC 在浏览器中运行 JavaScript 应用,而 WebDriver 通过原生浏览器支持或者浏览器扩展直接控制浏览器:
WebDriver 针对各个浏览器而开发,取代了嵌入到被测 Web 应用中的 JavaScript。与浏览器的紧密集成支持创建更高级的测试,避免了 JavaScript 安全模型导致的限制。除了来自浏览器厂商的支持,WebDriver 还利用操作系统级的调用模拟用户输入。WebDriver 支持 Firefox ( FirefoxDriver )、IE ( InternetExplorerDriver )、Opera ( OperaDriver ) 和 Chrome ( ChromeDriver )。对 Safari 的支持由于技术限制在本版本中未包含,但是可以使用 SeleneseCommandExecutor 模拟。它还支持 Android ( AndroidDriver ) 和 iPhone ( IPhoneDriver ) 的移动应用测试。它还包括一个基于 HtmlUnit 的无界面实现,称为 HtmlUnitDriver 。WebDriver API 可以通过 Python、Ruby、Java 和 C#访问,支持开发人员使用他们偏爱的编程语言来创建测试。
WebDriver 的创建者Simon Stewart 早在 2009 年八月的一份邮件中解释了项目合并的原因。
为何把两个项目合并?部分原因是 WebDriver 解决了 Selenium 存在的缺点(比如,能够绕过 JS 沙箱。我们有出色的 API),部分原因是 Selenium 解决了 WebDriver 存在的问题(例如支持广泛的浏览器),部分原因是因为 Selenium 的主要贡献者和我都觉得合并项目是为用户 提供最优秀框架的最佳途径。
在两个项目合并中出现了哪些架构方面的问题?学到了哪些经验和教训?Simon Stewart 在《开源应用架构》中做了详细的描述,本文是Selenium WebDriver 架构系列文章的第二篇,对复杂性设计的优劣做了深入实际的分析。
处理复杂性
软件是模块构造起来的。这些模块很复杂,作为API 的设计人员,我们可以选择如何处理这种复杂性。极端情况下,我们可能会传播这种复杂性,这意味着API 的每一位用户都需要牵涉其中。另一个极端情况是承担尽可能多的复杂性并将其隔离在某个地方。这个地方对于许多想一探究竟的API 用户来说黑暗而恐怖。折中方案则是API 的用户,如果无须深入了解实现细节,那么只需面对当前所遇到的复杂性即可。
WebDriver 的开发人员更倾向于发现并在少数地方隔离这些复杂性,而不是传播它。这么做的原因之一是为了用户。看看我们的 bug 列表就会知道,他们特别善于发现问题和缺陷,但是因为许多用户不是开发人员,复杂的 API 不会受欢迎。我们试图让 API 正确地引导大家。例如,考虑下面来自早期 Selenium API 的方法,每一个都用于设置输入元素的值:
- type
- typeKeys
- typeKeysNative
- keydown
- keypress
- keyup
- keydownNative
- keypressNative
- keyupNative
- attachFile
下面是 WebDriver API 中的等价方法:
- sendKeys
如前所述,这凸显了 RC 和 WebDriver 之间的主要思想差异——WebDriver 在努力模拟用户,而 RC 在较低层次提供的 API让用户难以或者无法使用。typeKeys 和 typeKeysNative 之间的区别在于前者总是使用合成事件(synthetic event),而后者则尝试利用 AWT Robot 输入键值。令人失望的是,AWT Robot 发送按键事件给具有焦点的任意窗口,也就是说可能不是浏览器。相比之下,WebDriver 的原生事件,直接把事件发送给窗口处理函数,避免了浏览器窗口必须具有焦点的要求。
WebDriver 设计
团队将 WebDriver 的 API 定位为“基于对象的”。接口被明确定义并努力坚持只包含一个角色或者责任,而不是将每一个可能的 HTML 标记模块化为单独的类,我们只有一个 WebElement 接口。通过这种方式,开发人员使用支持自动补全的 IDE 即可被提示下一步工作。其结果类似于下面的代码片段(Java 语言):
WebDriver driver = new FirefoxDriver();
driver.
此时,包含 13 个方法的短列表显示出来,用户选择其中一个:
driver.findElement(
)
大多数 IDE 现在显示预期参数的类型提示,在这个例子中是“By”。By 包含许多预定义的静态工厂方法。我们的用户可以快速地完成刚才的代码:
driver.findElement(By.id(“some_id”));
基于角色的接口
考虑一下简化的 Shop 类。每天,它需要进货,并与 Stockist 合作发布新的货单。每月,它需要付工资和税。为了描述清楚,我们假设它通过使用 Accountant 完成这些事情。一种建模结果如下所示:
public interface Shop {
void addStock(StockItem item, int quantity);
Money getSalesTotal(Date startDate, Date endDate);
}
我们有两种选择来定义 Shop、Accountant 和 Stockist 之间的接口的边界。图 1 显示了一种理论上的选择。
这意味着 Accountant 和 Stockist 将把 Shop 作为各自方法的参数。缺点是,Accountant 不可能真的想要处理货架,而让 Stockist 了解 Shop 添加的大量价签也不合适。因此,更好的一种思路如图 2 所示。
我们将需要两个 Shop 必须实现的接口,但是这些接口清晰的定义了 Shop 为 Accountant 和 Stockist 承担的角色。它们都是介于角色的接口:
public interface HasBalance {
Money getSalesTotal(Date startDate, Date endDate);
} public interface Stockable {void addStock(StockItem item, int quantity);
} public interface Shop extends HasBalance, Stockable {}
我发现 UnsupportedOperationExceptions 等让人非常不适,但是我们需要某些东西以支持对部分用户暴漏部分功能而不会影响 API 的其他部分。为此,WebDriver 广泛使用了基于角色的接口。例如,有一个 JavascriptExecutor 接口提供了在当前页面环境中执行任意 Javascript 语句块的功能。WebDriver 实例对该接口的成功映射可以提示你利用该方法完成自己的工作。
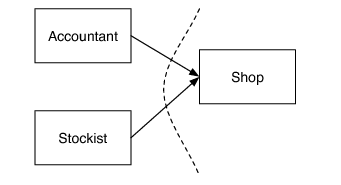
图 1:Accountant 和 Stockist 依赖 Shop
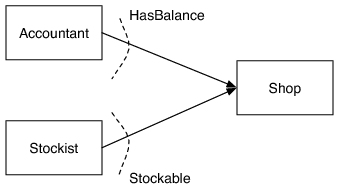
图 2:Shop 实现了 HasBalance 和 Stockable
处理组合爆炸
考虑到 WebDriver支持广泛的浏览器和语言,我们首先想到稍有不慎,就会面临维护成本的大量攀升。假设 X 种浏览器和 Y 种语言,我们很容易就会掉进 X×Y 种实现中。
减少 WebDriver 支持的编程语言种类是降低成本的途径之一,但是我们基于两种原因不想这样做。首先,从一种语言切换到另一种时人们会承受认知负荷,因此对用户来说如果测试框架(WebDriver)能够允许他们采用在日常开发中使用的编程语言来编写测试,那么这是巨大的优势。其次,在单一项目中混合多种语言可能会让团队感觉不舒服,而且公司的编码规范和需求通常要求技术单一纯正性(虽然我们愉快的看到,第二点理由随着时间推移越来越淡化),因此,减少支持语言的种类不是可选项。
减少支持浏览器的数量也不是一种选择——想想看,当我们决定在 WebDriver 中淘汰对 Firefox 2 的支持时,就遇到了强烈的抗议,而事实上当我们作出这个决定时,Firefox 2 只占了浏览器市场份额不到 1%。
我们唯一的选择是努力使所有浏览器对语言绑定的外观相同:它们应该提供统一的接口,可以轻松地通过各种语言解决。更重要的是,我们希望语言绑定本身尽可能的易于编写,这意味着需要尽可能的使它们保持简洁。我们在底层 driver 中放入了尽可能多的逻辑来支持这种设计:我们无法放入 dirver 的每一块功能都意味着需要通过我们支持的每一种语言实现,而这代表了一大块工作量。
这里举一个例子,IE driver 成功地把定位和启动 IE 的功能放入了主要驱动逻辑中。虽然这会导致在 dirver 中编写惊人数量的代码,但是用于创建新实例的语言绑定只需对 driver 的单一方法调用。相比之下,Firefox 无法做这种改动。在 Java 语言中,这意味着我们有三个主要的类来处理配置和启动 Firefox,大约 1300 行代码。这些类在每一种支持 FirefoxDriver 的语言绑定中都是重复的,无须依赖 Java 服务器。这会有大量的多余代码需要维护。
WebDriver 设计中的缺陷
通过这种方式发布功能的缺陷在于除非有人知道某个特定的接口存在,否则他们可能不会意识到 WebDriver 支持这种功能,在 API 的可发掘性上存在缺憾。当然在 WebDriver 刚发布的时候,我们会投入大量时间来指导人们找到合适的接口。现在我们已经花费大量精力来编写文档,随着 API 获得广泛应用,用户会越来越容易的找到所需的文档。
我认为 API 有一个地方设计的非常差。我们有一个接口称为 RenderedWebElement,其中包含一些奇怪的方法来查询元素的渲染状态(isDisplayed、getSize 和 getLocation),执行操作(hover 和拖拽方法),而且还提供方法获取特定 CSS 属性的值。创建它的原因是 HtmlUnit 驱动没有提供所需的信息,但是 Firefox 和 IE 驱动提供了。它最初只有一部分方法,后来我经过苦苦思索又增加了其他方法。这个接口目前众所周知,艰难的选择在于是否保持 API 的丑陋之处,或者删除它。我更倾向于不要遭遇“破窗”理论,因此,在 Selenium 2.0 发布之前修补它非常重要。结果就是,在你读到这些文字时,RenderedWebElement 可能已经消失了。
从实现者的观点来看,紧密绑定浏览器也是一种设计缺陷,虽然无法避免。支持新浏览器时需要投入巨大的努力,经常需要数次尝试才能找到正确方法。具体的例子就是,Chrome 驱动经过了四次完全重写,IE 驱动也有三种关键重写。紧密绑定浏览器的优点在于它提供了更多控制权。
布局和 Javascript
浏览器自动化工具基本上由三部分构成:
- 与 DOM 交互的方法
- 执行 Javascript 的机制
- 一些模拟用户输入的办法
本节重点介绍第一部分:提供与 DOM 交互的机制。浏览器的办法是通过 Javascript,所以看起来与 DOM 交互的理想语言也是它。虽然这种选择似乎显而易见,但是在考虑 Javascript 时需要平衡一些有趣的挑战和需求。
像多数大型项目一样,Selenium 使用了分层的库结构。底层是 Google 的 Closure 库,提供原语和模块化机制来协助源文件保持精简。在此之上,有一个实用工具库,提供的函数包括简单的任务,如获取某个属性值、判断某个元素是否对用户可见,还包括更加复杂的操作,如通过合成事件模拟用户点击。在项目中,这些被视为提供最小单元的浏览器自动化,因此称之为浏览器自动化原子(Browser Automation Atom)。最后,还有适配层来组合这些原子单元以满足 WebDriver 和 Core 的 API 协议。
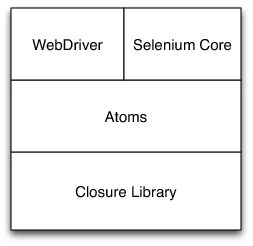
图 3:Selenium Javascript 库的层次结构
选择 Closure 库基于几种原因。主要理由是 Closure 编译器理解库使用的模块化技术。Closure 编译器的目标是输出 Javascript。“编译”可以简单到按照依赖顺序查找输入文件、串联并漂亮的打印出来,也可能复杂到进行精细的改动和删除死代码。另一种不可否认的优势是团队中采用 Javascript 编程的几位成员对 Closure 库非常熟悉。
当需要与 DOM 交互时,“原子”库的代码会被用于项目中的各个角落。对于 RC 和那些大部分由 Javascript 编写而成的 driver 来说,这些库被直接使用,通常编译为单个巨大的脚本。对于采用 Java 编写的 driver,来自 WebDriver 适配层的各个函数在编译的时候会启用完整优化,生成的 Javascript 在 JAR 中作为资源包含进来。对于采用 C 语言编写的 driver,如 iPhone IE 驱动,不仅各个函数被通过完整优化来编译,而且生成的输出文件被转换成定义在头文件中的常量,通过 driver 的正常 Javascript 执行机制来执行。虽然这看起来有些奇怪,但是这种做法使 Javascript 放在底层驱动中,无须在各处暴露原始的代码。
因为原子库应用广泛,所以在不同浏览器之间确保一致的行为是可行的,因为库采用 Javascript 编写,而且无需提升权限来执行开发周期,所以方便、快捷。Closure 库可以动态加载依赖,因此 Selenium 开发人员只需编写测试并在浏览器中加载,修改代码并在需要时点击刷新按钮。一旦测试在浏览器中通过,很容易在另一个浏览器中加载并确保通过。因为 Closure 库在抽象屏蔽浏览器之间的差异方面做得很好,这就足够在持续构建中在每一种支持的浏览器中运行测试集以衡量是否通过。
最初 Core 和 WebDriver 存在许多相同的代码——通过略微不同的方式执行相同的功能。当我们开始关注原子库时,这些代码被重新梳理,我们努力找出最合适的功能。毕竟,两个项目都被广泛应用,它们的代码非常健壮,因此把一切都丢掉从零开始不仅浪费而且愚蠢。通过对每个原子库的分析,我们找出了可以使用的部分。例如,Firefox driver 的 getAttribute 方法从大约 50 行缩减到几行,包括空白行在内:
FirefoxDriver.prototype.getElementAttribute =
function(respond, parameters) {
var element = Utils.getElementAt(parameters.id, respond.session.getDocument());
var attributeName = parameters.name;
respond.value = webdriver.element.getAttribute(element, attributeName);
respond.send();
};
倒数第二行中,respond.value 的赋值调用了原子级的 WebDriver 库。
原子库是本项目若干架构思想的实际演示。当然,它们满足了 API 的实现应该倾向于 Javascript 的需求。更出色的是,用一个库在代码库中分享,以前一个缺陷需要在多种实现中验证和修复,现在只需在一个地方修改即可,这种做法降低了变化的成本,同时提高了稳定性和有效性。原子库也使项目的“巴士”因素更优化。因为通常的 Javascript 单元测试可以用于验证缺陷是否修复,所以参与到开源项目中的障碍要比之前需要了解每一个 driver 如何实现的时候更低。
使用原子库还有另外一个好处。模拟现有 RC 实现但由 WebDriver 支持的分层对团队尝试以可控的方式迁移到更新的 WebDriver API 是一种重要的工具。因为 Selenium Core 是原子化的,所以单独编译每一个函数是可行的,使得编写这种模拟层易于实现而且更准确。
当然,这种做法也存在缺点。最重要的是,把 Javascript 编译成 C 常量是一种非常奇怪的事情,它总是阻碍那些想参与 C 语言编程的项目贡献者。而且很少有开发人员能够了解所有浏览器并致力于每一种浏览器上运行所有测试——很可能有人会不小心在某处引入回归问题,我们需要花时间找到问题,如果持续构建很多的话则更需精力。
因为原子库规范了浏览器之间的返回值,所以可能存在意想不到的返回值。例如,考虑如下 HTML:
checked 属性值依赖于使用的浏览器。原子库规范了该值和 HTML 5 标准中定义的其他 Boolean 属性为“true”或者“false”。当该原子量被引入代码库后,我们发现有许多地方大家都做了依赖于浏览器的假设(觉得返回值应该是什么样的)。虽然这些值现在都一致了,但是我们花了很长时间来向社区解释发生了哪些变化以及这样做的原因。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论