
“小明,小明,性能报告麻烦给一下”
“小明,小明,你这数据有问题啊,跟我测的不一致,重新再测试”
“小明,小明,我们搞了个体验优化,帮忙跑一下数据吧”
上述故事纯属虚构,如有雷同,纯属巧合。
引言
如文章开头的故事所言,在闲鱼 APP 发版期间,也会遇到性能报告生成不及时、性能数据不准确的问题。先一起来看个图回顾一下闲鱼最初的性能测试流程。
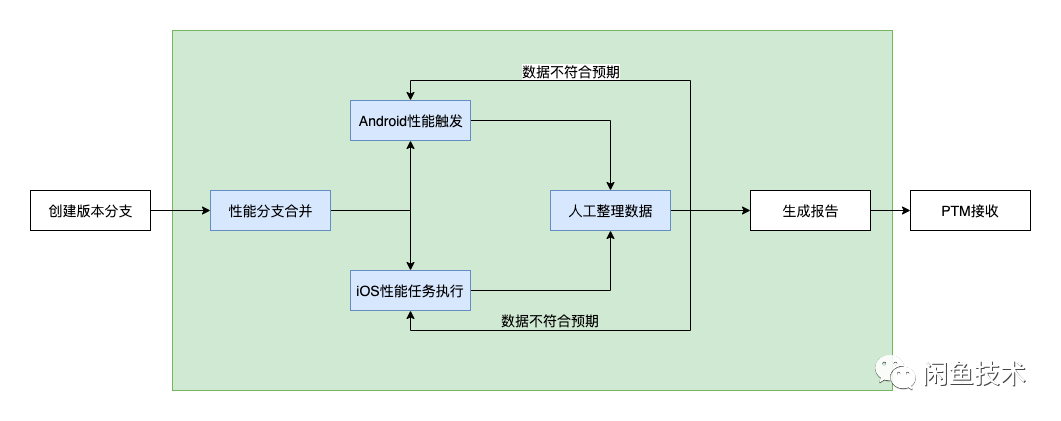
从上图中我们可以发现闲鱼之前的性能测试流程自动化覆盖率特别低,基本上所有环节都需要人力介入,十分耗时耗力,主要问题如下:
人工成本高 闲鱼发版时需要回归多个主干场景的性能信息,投入人力成本至少 1 人日,适配同学偶尔苦不堪言。
手动操作误差大,频繁返工 参与跟版的同学是轮岗制,他们的操作习惯不同、打开页面不同会导致数据存在误差,偶尔需要返工,最多一次需要反复测试四五次。
提测无性能卡点 人工测试时性能卡点都是放到了发版的阶段,往往会耗费过多精力去排查什么引起的,我们把性能卡点前置就可以避免
数据没有沉淀 在自动化之前,性能数据都是用一个 Excel 来统计,然后生成报告,整个数据都没有沉淀,我们也没有抓手去判断到底是哪里产生了问题。
研发自测难 开发同学经常会做个体验优化,这个时候想验证一下,每次都在等资源,然后适配同学做这种枯燥的事情又很枯燥、很无奈。
基于以上原因,我们开始着手设计开发闲鱼端性能测试平台,通过流程化、规范化、自动化来提升测试效率,释放人力去做更多有意义的事情,本文主要介绍了闲鱼性能自动化测试平台的解决方案以及落地过程中踩过的坑。
解决方案
其实我们主要想解决的问题有 3 个:人力成本、误差问题、数据沉淀,对于底层基础能力,SLM 和 TMQ 已经足够完善,我们不需要重复造轮子,所以主要集中测试流程、脚本以及数据沉淀,底层实现直接使用集团现有能力。
系统设计
在整个系统设计中,我们秉承着极简主义,绝不重复造轮的理由,整个系统底层上直接使用 SLM、TMQ 现有能力进行性能数据收集,同时报表数据使用 deepinsight 生成。在脚本管理方面,通过 Git 仓库来进行管理,每个分支代表某个版本的性能测试脚本,这样我们可以同时回溯多个版本的性能。
在任务触发方法,我们在闲鱼质量平台中开发了性能测试模块,用于性能测试脚本、任务的管理,用户不需要关注底层的平台实现,只需要在闲鱼质量平台上提供包地址以及可选参数,即可触发任务,而这些任务可能是在 TMQ 运行,也可能是在 SLM 运行。另外我们和整个打包构建流程打通,当有 release 包构建成功时,能够自动触发性能任务进行数据收集,减少人力介入。
任务完成后,通过数据回流,可直接在平台上进行数据查看,同时对于版本数据,能够直接进行归档,归档后,数据通过 odps 同步到 deepinsight 实现报表的自动化和生成。
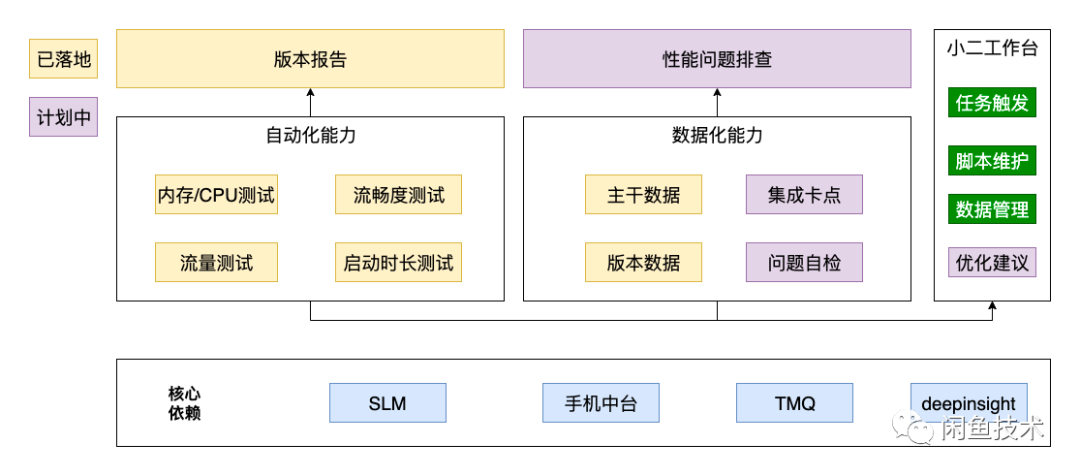
我们的测试目标不应该是为了出数据而出数据,而是能够给出开发排查建议,具体定位到性能是受哪块业务、哪个合并的影响,这也是我们规划中的内容,后续会在该方面持续发力,利用历史数据沉淀进行问题自检、排查建议。
具体测试流程
如图 3 所示,整个测试流程分为三个阶段:任务触发、自动化执行、PTM/PM 数据确认以及问题排查。对于研发同学而已,他们做完性能优化之后,可以直接在平台触发任务进行性能测试,不需要等待质量同学和适配同学介入就能够自己快速验证效果。
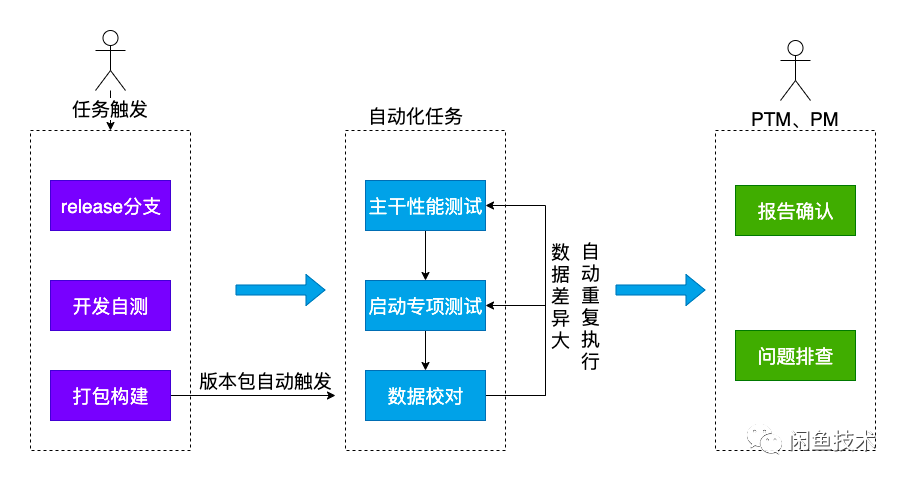
在发版流程中,我们将性能测试左移到每个 release 包构建完成后,只要 release 渠道包构建完成,系统会自动触发性能测试任务,一旦回归完成,我们就能够立刻获得该版本的性能数据。这个过程减少了人力介入,能够避免人为因素带来的版本节奏推迟。
在手工测试时,经常会出现数据不准确导致返工反复测试,中间的沟通其实浪费了很多的时间和人力成本,所以我们在平台中加入了自动重试机制,当某个版本的数据计算完成后,会自动与历史版本数据进行对比,如果对比结果数据差异过大,系统会自动在不同的机器上重跑最近两个版本的数据并进行比较,将数据验证前移。由于平台做了一轮数据比对和校验,所以在 PTM/PM 数据确认以及问题排查阶段一般情况下不需要再投入额外的精力,除非 APP 性能确实出现了问题。
踩过的坑与雷
让整个流程跑起来很简单,但是在实际使用中有不少坑,所以整个系统上线后依然做了不少调整。以下是我们遇到的问题以及解决方案,希望对大家的性能测试工作有所帮助。
机器温度对性能的影响 由于机房的机器整天都在执行任务,再加上一直充电,就会导致设备温度升高,升高之后 CPU 会进行降频,这时候 FPS、CPU 都不准确。为了解决这个问题,我们在每次任务执行前,先把设备占用,停止执行任务 10 分钟,让设备的温度降低,这样能够减小温度带来的误差。
FPS 受到网络加载的影响 在 Feeds 测试时,不同页面网络的加载会导致滑动的幅度有差异,这个时候每次在测量 FPS 时都会有波动,虽然求取平均值能够减少误差,但是并不准确。于是我们在测量时,将整个性能测试分为两个阶段:CPU\Memory\流量收集阶段,即上滑时收集内存、内存、和流量信息,下滑时收集 FPS,因为在下滑时,数据都已经加载完毕,我们就可以规避网络带来的误差。
设备对性能的影响 设备的影响,不同的设备条件不同,在测量时 CPU、FPS 均有误差,为了解决这个问题,我们已经开始自建闲鱼自建的设备库,对于版本性能测试,使用专门的设备进行测试。
总结与展望
总结
经过一阶段的实践,目前该能力已经应用在闲鱼发版流程中(6890-6940),总体效果如下:
人力成本降低 版本性能测试从 1 人日->1h 以内,同时数据有争议时,能够同步自动化快速进行验证,不需要考虑适配成本,这样可以投入更多的人力做更需要人力的地方。
高效稳定 相比于之前,目前的测试数据更加稳定,除了极个别场景需要特别回顾以外,大多数场景都能够准确测试,基本上在跟进的几个版本中没有出现重复跑数据的情况。在两次发版过程中出现 2 次性能数据差异过大,经排查都是代码变更问题导致。
数据沉淀 目前我们的数据沉淀能够帮助我们在后续进行更深层次的性能分析。
展望
测试左移 我们希望把脚本通用化,开发只需要点点点、选选选就能够指定需要测试的场景性能,而不需要维护脚本。
接入持续集成,提测卡点 在 release 包打出之后,我们的性能自动化平台就能够自动触发,对其性能进行测试,发版时报告自动发送。
深入化 当前的测试流程提供了问题发现能力,但在问题定位能力上还有所欠缺。后续我们会持续深入探索如何通过数据沉淀、分析来主动抛出指标异常可能是由于哪个模块、甚至是哪个代码块导致,这样不但能够减少开发排查的成本,也能增加数据的可信性。
本文转载自:闲鱼技术(ID:XYtech_Alibaba)
原文链接:闲鱼性能测试那些事儿




