计算机世界中有一些非常基础、重要、应用广泛而又特别容易让人困惑的主题,比如字符编码、字节序 (即大小端表示) 浮点数实现、日期时间处理以及正则表达式等等,而正则表达式是其中的典型代表。然而正则表达式作为那种没用过的话,不觉得对自己有什么影响,一旦用过并且用熟练了,就再也回不去了的神器,要熟练掌握并能灵活运用,实非易事。
那到底应该怎样才能最高性价比地掌握正则表达式这个神器呢?这正是我写这个系列文章的目的。
首先,应从编程语言发展史和编程范式的角度,理解正则表达式是一个字符匹配领域的领域特定语言 (DSL),具有高度简洁、高度抽象的特点。
另外,学习过程中,不能不求甚解,应充分了解正则引擎的基本原理;应充分辨析多个多义元字符,以免混淆,比如 -、+、?、^,尤其是元字符?;深入理解转义,掌握其规律;不要期望短期内迅速掌握,正确的学习方法是:先简单了解一些基本的规则与元字符,不用刻意去强行记忆,而是应在实践中多运用,边学、边深入、边熟练。
还有就是除了看入门教程、经典著作之外,可以关注本系列文章。本系列文章出自于我自己在学习正则表达式的过程中所经历过的真切体会和真实痛点。虽然会涉及到正则引擎内部的相关匹配原理与匹配机制的解释,但出于更偏向实践运用的目的,不会花费过多的笔墨在 DFA、NFA 等过于深入的正则表达式幕后技术细节的讲解上。
下面为本系列的前一篇文章:
前文大致上对本系列文章的成文原因,以及正则表达式的学习难点、正则表达式的概念、正则表达式的简史、正则表达式的流派进行了简要介绍。接下来本文简要介绍一下正则表达式的基础知识。
一、正则表达式构成
1. 正则表达式中的语法元素,从是否具有特殊含义的角度进行分类,可分为下列两大类、共五种语法元素:
1)不具有特殊含义的语法元素
- 字面字符 (文本字符):不具有特殊含义的单个字符,代表字符自身 (即字符字面值);
- 普通转义序列:由转义前导符\后跟元字符所组成的字符序列,将具有特殊含义的元字符,转义为 (即转换为) 不具有特殊含义的字符本身 (即字符字面值);
2)具有特殊含义的语法元素
- 元字符:具有特殊含义的单个字符,包括:\、(、)、[、]、{、}、.、-、*、+、?、|、^、$;
- 元转义序列:由转义前导符\后跟单个字符或多个字符组成,具有特殊含义,包括:\0octal-num、\num、\a、\A、\b、\b{}、\B、\B{}、\cX、\C、\d、\D、\e、\E、\f、\F、\g{}、\gnum、\G、\h、\H、\k{}、\k<>、\k’’、\K、\l、\L、\n、\N、\N{}、\o{octal-num}、\pP、\p{}、\PP、\P{}、\Q、\r、\R、\s、\S、\t、\u、\U、\v、\V、\w、\W、\xhex-num、\x{hex-num}、\X、\z、\Z 等;
- 特殊构造 (特殊结构):由多个元字符和 / 或普通字符组成,具有特殊含义,包括:字符组 [xyz] 或 [^xyz]、捕获分组 (sub-regex)、命名捕获分组 (?sub-regex)、非捕获分组 (?:sub-regex)、预查分组 (即环视分组)(?=sub-regex) 或 (?!sub-regex) 或 (?<=sub-regex) 或 (?sub-regex)、嵌入条件分组 (?(condition)true_sub-regex|false_sub-regex)、内联修饰选项与取消内联修饰选项分组 (?modifier-modifier)、注释分组 (?#comment)、分支复位分组 (?|sub-regex)、表达式引用分组 (?R) 或 (?num)、平衡分组 (?<-name>sub-regex) 等。
2. 从匹配的是位置还是字符的角度来分类,可分为如下四大类:
1)匹配字符的语法元素
-
字面字符 (文本字符):代表字符自身 (即字符字面值);
-
普通转义序列:将具有特殊含义的元字符,转义为 (即转换为) 不具有特殊含义的字符本身 (即字符字面值);
-
元字符:.;
-
下面这些元转义序列:**** 固定字符:\a、\b(字符组内部)、\e、\f、\n、\r、\t、\v(非 Perl 系);
字符组简记:\d、\D、\h、\H、\N{}、\p{}与\pP、\P{}与\PP、\s、\S、\v(仅 Perl 系)、\V、\w、\W
进制转义字符:\octal-num(Perl 系中也可写作\o{octal-num})、\xhex-num(Perl 系中也可写作\x{hex-num})、\uhex-num(非 Perl 系,Ruby1.9+ 等个别语言中还可写作\u{hex-num});
控制字符:\cX 系列;
其他:\C、\N、\R、\X。
2)匹配位置的语法元素
-
下面这些元字符:^、$
-
下面这些元转义序列:**** 锚点:\A、\z、\Z、\b(字符组外部)、\b{}、\B、\B{}、\G;
其他:\<、\>。
-
预查分组:(?=sub-regex)、(?!sub-regex)、(?<=sub-regex)、(?
3)既可能匹配字符,也可能匹配位置的语法元素
- 由下限次数为 0 的量词所限定的子表达式,下限次数为 0 的量词包括:?、*、{0,}、{0,m}、{,m}(逗号“,”前面为空的这种写法仅部分正则引擎支持,不推荐这种写法);
- 下面这些元转义序列:**** 引用:\num、\g{num}、\gnum、\k{name}、\k、\k’name’(如果引用的是文本,则匹配字符,如果引用的是位置或空字符串,则匹配的是位置);
- 特殊构造 (特殊结构):捕获分组 (sub-regex)、命名捕获分组 (?sub-regex)、非捕获分组 (?:sub-regex)、固化分组 (即原子分组)(?>sub-regex)、嵌入条件分组 (?(condition)true_sub-regex|false_sub-regex) 等,当这些分组中的 sub-regex 为空时,匹配的是位置;不为空时,若 sub-regex 匹配字符,则这些分组匹配的是字符,否则匹配的是位置。
4)既不匹配字符,也不匹配位置的语法元素
除上述语法元素之外的其他语法元素,这包括:\K、内联修饰选项与取消内联修饰选项分组 (?modifier-modifier)、注释分组 (?#comment) 等。
3. 注意,语法元素有时也会称之为子表达式;当然,子表达式的概念要比语法元素更为丰富,涵盖面更广。因此,需根据上下文予以准确理解。
二、字符串构成
1. 从正则表达式的角度来看,字符串通常由位置和字符所共同构成,但空字符串仅由单个位置构成 (该位置既是空字符串的起始位置,也是空字符串的结束位置,可同时匹配表示字符串起始位置的元字符 ^ 和表示字符串结束位置的元字符 $)。
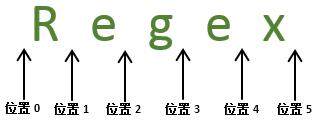
对于字符串“Regex”而言,是由五个字符以及六个位置构成的,理解这一点对于正则表达式的匹配原理的理解很重要。
2. 字符串中的位置,其实也是组成该字符串的字符的索引,因此,位置 0 就是用来索引 (即定位) 字符 R 的索引 0。字符串“Regex”始于索引 0(即位置 0) 处,止于索引 5(即位置 5) 处。
当正则引擎在字符串中查找匹配时,可以认为在字符串中有一个匹配定位指针,该指针可以在字符串中的各个位置之间移动(一般是从左到右依次移动,但回溯时也会从右向左移动;另外,.Net 中还支持从右向左匹配)。
3. 查找匹配过程中,下一次匹配的起始位置与前一次匹配的结束位置往往是相同的:
正则式:/regex/
字符串:regexregex
找到第一个子字符串"regex",开始于位置 0 结束于位置 5
找到第二个子字符串"regex",开始于位置 5 结束于位置 10
三、匹配过程与匹配定位指针、匹配控制权
1. 匹配过程从字符串的角度来看的话,必然总是从字符串中的一个位置开始匹配的,可能是从字符串的起始位置匹配,也可能是从字符串中间的某两个字符之间的位置开始匹配,甚至可能是从字符串的结束位置开始匹配(.Net 中支持从右向左匹配)。当然,绝大部分情况下,均是从字符串的起始位置开始匹配的。
当在某个位置尝试匹配失败,正则引擎将移动字符串中的匹配定位指针到字符串中的下一个位置开始继续尝试匹配。这样逐个位置尝试,直到获得匹配,或者一直到字符串结尾仍未获得匹配则报告匹配失败。
2. 匹配过程从正则表达式的角度来看的话,必然总是从正则表达式的起始位置从左至右逐个语法元素开始尝试匹配的 (但多选分支结构中的情况稍微复杂些:传统型 NFA 正则引擎由于遵循“最左先到先得原则”,一旦其中某个分支获得了匹配,将不会继续尝试匹配剩下的分支;而 DFA 和 POSIX NFA 正则引擎由于遵循“最左最长原则”,必须选择各个分支中所获得的最长匹配,因此会逐个分支尝试匹配)。
正则表达式中的某个语法元素一旦在字符串中获得了匹配 (若该语法元素后面有量词限定的话,需满足其重复次数,且有可能存在回溯,详见后文解释),则表示该语法元素成功获得了匹配,于是匹配控制权转移到下一个语法元素,重复该过程。
原则上,匹配控制权一旦从某个语法元素转移出去,则该语法元素不能再次重新获得。不过,懒惰量词形成的回溯例外 (懒惰量词所限定的语法元素一旦获得了该量词的下限次匹配之后,会先将匹配控制权转移给紧随其后的语法元素,若紧随其后的语法元素无法匹配,则会将匹配控制权返回给该语法元素)。(如果暂时看不明白没关系,后文都会有详细解释)。
若正则表达式中的某个必须匹配的语法元素 (而由下限次数为 0 的量词所限定的语法元素则为可选匹配) 一旦在字符串中无法获得匹配,则该正则表达式匹配失败。
四、占有字符 (消费字符与消耗字符) 匹配和不占有字符 (零宽度) 匹配
1. 正则表达式匹配过程中,若其中的某个语法元素匹配到的是字符,而非位置,并且在字符串中移动了匹配定位指针,此时可分为两种情况:
- 所匹配的字符被保存到了最终的匹配结果中 (即返回了所匹配到的字符),那么就认为该子表达式消费了这些字符;
- 所匹配的字符未被保存到最终的匹配结果中 (即没返回所匹配到的字符),那么就认为该子表达式消耗了这些字符(比如位于元转义序列\K 之前的子表达式)。
无论是消费了字符,还是消耗了字符,均属于占有了字符。
如果该子表达式匹配的仅仅是位置,或者虽然匹配了字符,但最终并不实际移动字符串中的匹配定位指针(比如预查分组),那么就认为这个语法元素是不占有字符的,即属于零宽度的。
占有字符还是不占有字符,最终以是否实际移动了字符串中的匹配定位指针为准。
2. 占有字符是互斥的,不占有字符是非互斥的。
所谓互斥指的是一个字符,只能由一个语法元素匹配,一旦被某个语法元素匹配后占有了,则不能为其他语法元素所匹配占有;所谓非互斥指的是一个位置,可以同时由多个不占有字符 (即零宽度) 的语法元素匹配。
五、八大原则简介
1. 受《精通正则表达式》一书中“最左原则”、“最长原则”以及衍生的“最左最长原则”的启发,在此基础上我进一步推广扩展,总结为八大原则。其中包括六大基本原则与两大衍生原则,先简要介绍如下 (后文结合语法元素会有详细解释):
六大基本原则:
- 最左原则:在一个字符串中,若一个正则表达式可能有多个匹配结果时,其中最靠近字符串左边的起始位置的那个匹配结果总是会优先于其他的匹配结果被返回;
- 最长原则 (即长度优先原则):如果在字符串中的某个位置存在多个可能的匹配,将返回最长文本 (即最多字符) 的那个匹配;
- 先到先得原则 (即顺序优先原则):在同一个位置上,如果有多个长度不同的匹配结果,将返回最先获得匹配的结果,或前后两个由贪婪量词或懒惰量词所限定的子表达式发生匹配冲突时,后者仅获得其下限次数的匹配,而前者将获得超过其上限次数的尽可能多的匹配;
- 逐位置依次尝试匹配原则:匹配总是从字符串的起始位置 (即位置 0) 开始,从左到右地逐个位置尝试匹配整个正则表达式;
- 整体匹配优先原则:整个正则表达式获得匹配的优先级要高于贪婪量词所限定的子表达式;
- 占有匹配优先原则:整个正则表达式获得匹配的优先级要低于占有量词所限定的子表达式。
两大衍生原则:
- 最左最长原则:非全局模式下,如果在字符串中的多个位置中的每个位置均有多个可能的匹配文本,DFA 和 POSIX NFA 引擎会优先选择最靠左边位置的所有可能的匹配文本当中最长的文本;
- 最左先到先得原则:非全局模式下,如果在字符串中的多个位置中的每个位置均有多个可能的匹配文本,传统型 NFA 引擎会优先选择最靠左边位置的所有可能的匹配文本当中最先获得匹配的文本。
2. 这些原则看似平淡无奇,但正如“两点间直线距离最短”这样显而易见的几何学公理,却是支撑起整个宏伟的欧几里得几何学的基石一样,这八大原则也是正则引擎匹配机制的基础,理解它们是理解正则引擎匹配行为的关键。
参考资料
一)文档
Perl:
- Perl regular expressions (perlre)(英文)
- Perl Regular Expressions Reference (perlreref)(英文)
- Perl Regular Expression Backslash Sequences and Escapes (perlrebackslash)(英文)
- Perl Regular Expression Character Classes (perlrecharclass)(英文)
- regular-expressions.info: Perl’s Rich Support for Regular Expressions(英文)
PHP:
- PCRE(preg) 正则表达式语法介绍 (中文)
- regular-expressions.info: PHP Provides Three Sets of Regular Expression Functions(英文)
PCRE2:
.Net(C#、VB):
- 正则表达式语言快速参考 (中文)
- regular-expressions.info: Using Regular Expressions with The Microsoft .NET Framework(英文)
Java:
- Regular Expressions Tutorials(正则表达式教程)(英文)
- Package java.util.regex(英文)
- regular-expressions.info: Using Regular Expressions in Java(英文)
JavaScript:
- MDN:正则表达式简介 (中文)
- MDN:RegExp 对象说明 (中文)
- EMCAScript:RegExp (Regular Expression) Objects(英文)
- regular-expressions.info: Using Regular Expressions with JavaScript(英文)
Python2.7:
Python3.4:
- Regular expression operations(英文)
- Regular expression HOWTO(英文)
- regular-expressions.info: Python’s re Module(英文)
Vim:
GNU Grep:
GNU Sed:
GNU awk:
二)书籍
- 《精通正则表达式》英文版及中文版 作者:Jeffrey E·F·Friedl 译者:余晟 电子工业出版社 2012-07
- 《正则指引》作者:余晟 电子工业出版社 2012-05
- 《正则表达式必知必会》作者:Ben Forta 译者:杨涛 人民邮电出版社 2015-01
- 《冒号课堂:编程范式与 OOP 思想》作者:郑晖 电子工业出版社 2009-10
三)其他
本系列文章还参考了网上的大量资料,除了少部分资料由于未作大量修改 (但基本上也有少量修改,因为网上文章随意性较大,很多明显的笔误或前后矛盾之处,如若不改反而让人迷糊) 而标明了原作者和出处之外,其余由于基本上已按自己的理解作了大量改写,因此没有再一一予以说明,在此对原文作者表示歉意并感谢。
另外,文中图片小部分来自网络,大部分为本人制作,也不再一一说明,在此对原图作者表示歉意并感谢。




