
一、简介
1.1 摘要
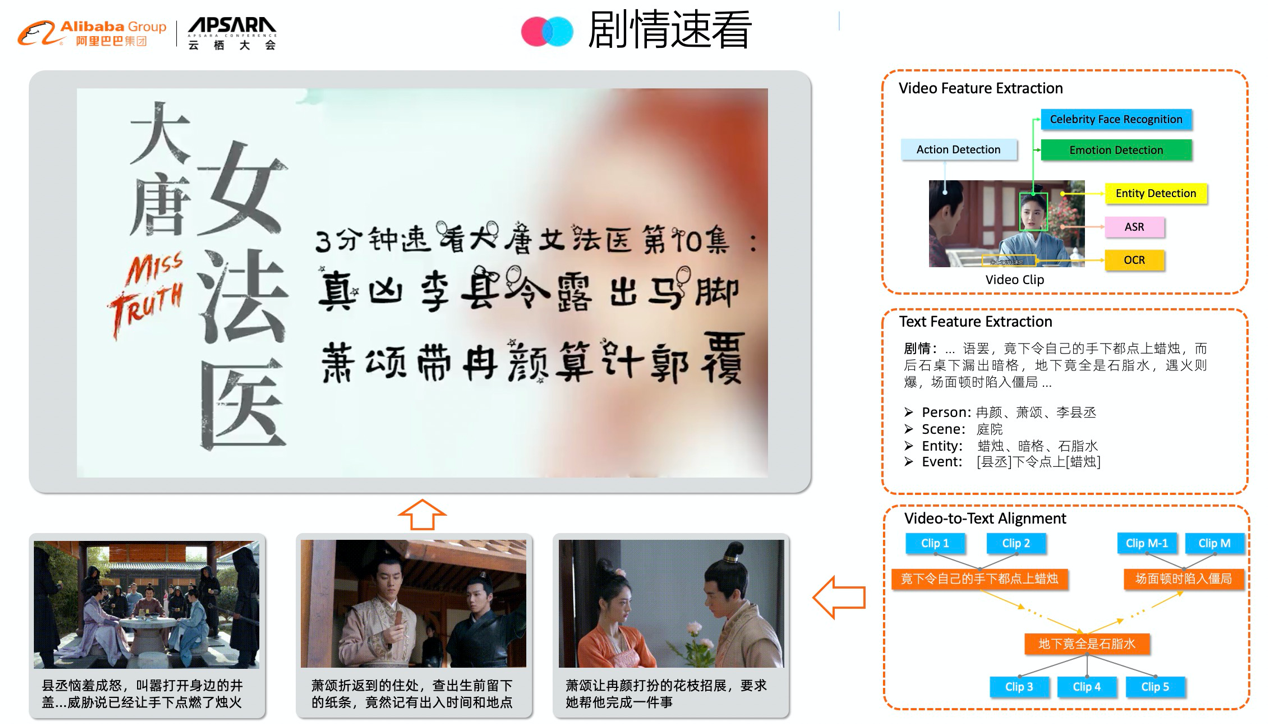
随着用户的时间碎片化程度加剧,视频“由长变短”成为一种趋势,信息流场景下的短视频消费需求日益增长,优酷每年为用户提供大量优质视频资源,具备天然的“由长变短”优势,并通过算法研究在速看短视频的自动化生产方面取得突破。
1.2 相关研究
学术界中将该问题命名为 text video alignment:给定 video 的剧本,基于 video shot 和 sentence 的相似度,做两个 sequence 的对齐。 涉及两个任务,第一个任务是计算文本与视频片段的相似性,第二个任务是 text sequence 与 video sequence 的对齐。
video text alignment 与 video text grounding 的区别是其对视频片段边界不敏感,不要求回归边界,只做 shot 与 text 相似度的度量。而与 video text retrieval 的的相同之处是需要计算 video clip 和 text 的特征及相似度,不同之处是 text video alignment 有时序信息,且时序是顺序的,不存在乱序。text video alignment 的相似比对只在指定的 video 当中,不存在跨 video 的检索。
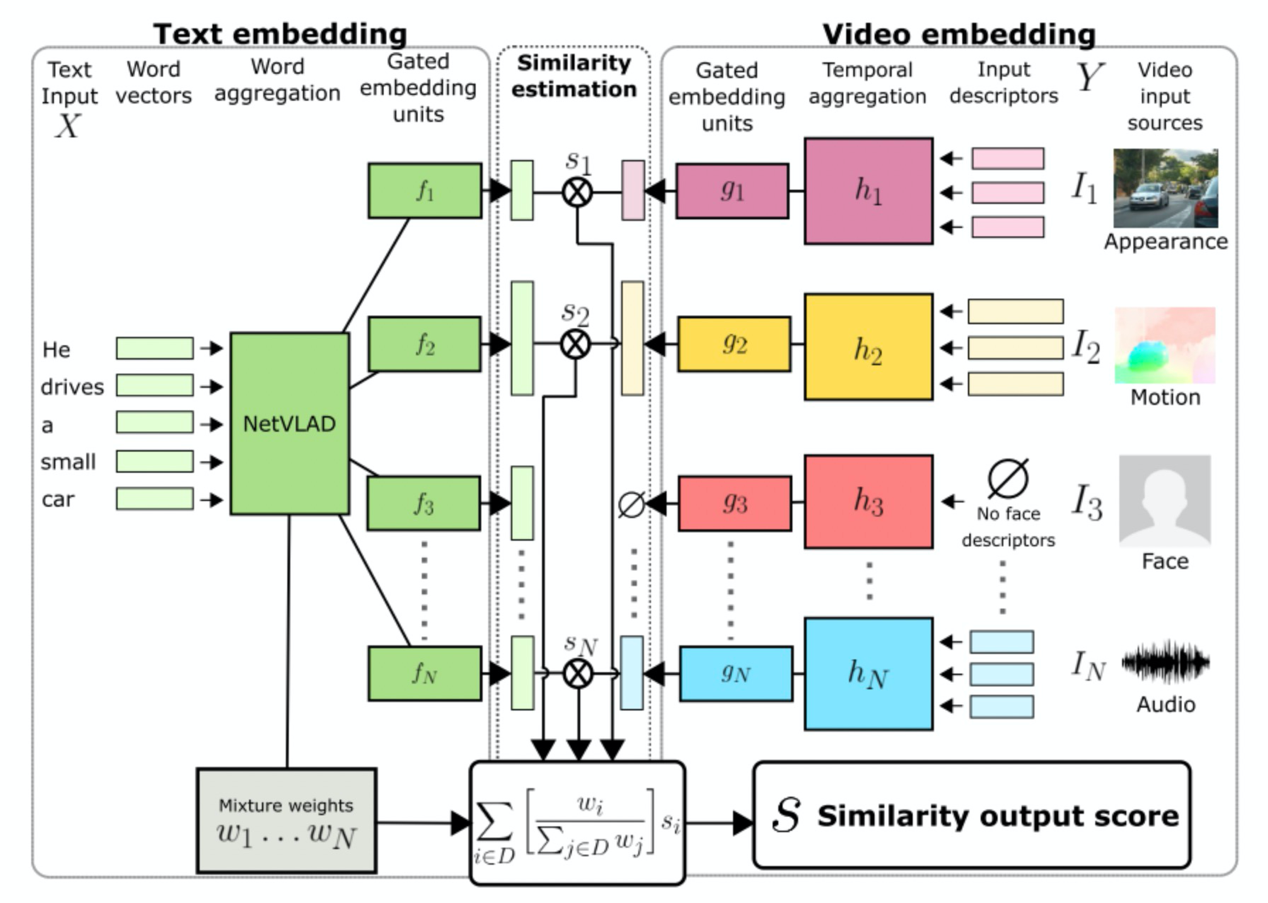
视频中通常会包含多种不同模态的信息,例如光流、人脸、声音等,之前的方法仅考虑了某一模态的特征。文章[1]提出了一个相似度计算框架将所有模态特征纳入视频-文本的相似度计算中,并且可以灵活扩展到更多的模态,也可以处理某一模态特征缺失的情况。
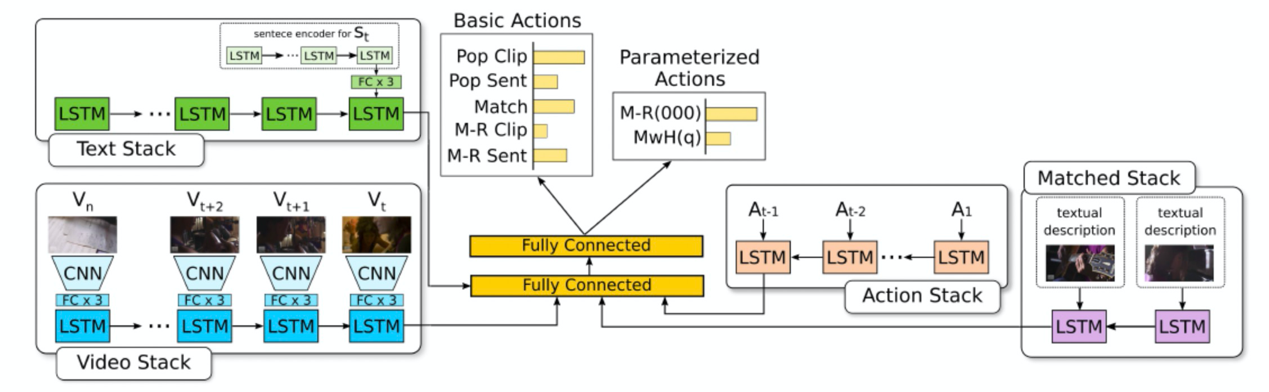
文章[2]将视频和文本的跨模态匹配过程抽象为对视频序列栈和文本序列栈的操作过程。利用 LSTM 对视频序列和文本序列进行建模,构成视频序列栈和文本序列栈,通过循环预测不同的栈顶操作来实现序列匹配。可以满足不同类型的匹配要求。
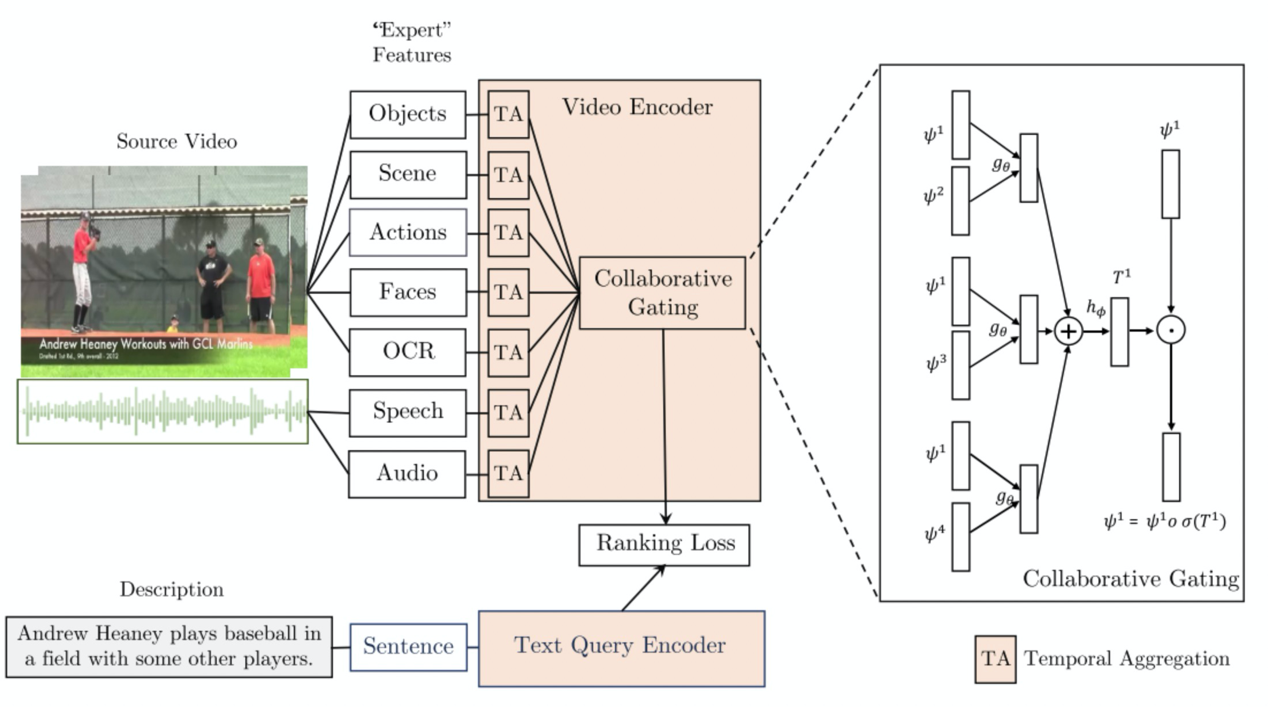
文章[3]将文章[1]中的相似度计算框架应用在视频文本检索领域。在原有结构基础上增加了信息过滤模块,增加了不同模态之间的信息融合通道,能够更好地融合不同模态的特征。
文章[4]将图神经网络应用在了视频文本检索领域。分别在文本和视频模态提取不同层级的特征,并使用图神经网络进行模态内的特征融合,最后进行相似度计算。相较于其他方法,图结构的表示方式能够更加合理的组织信息,提升模型性能。
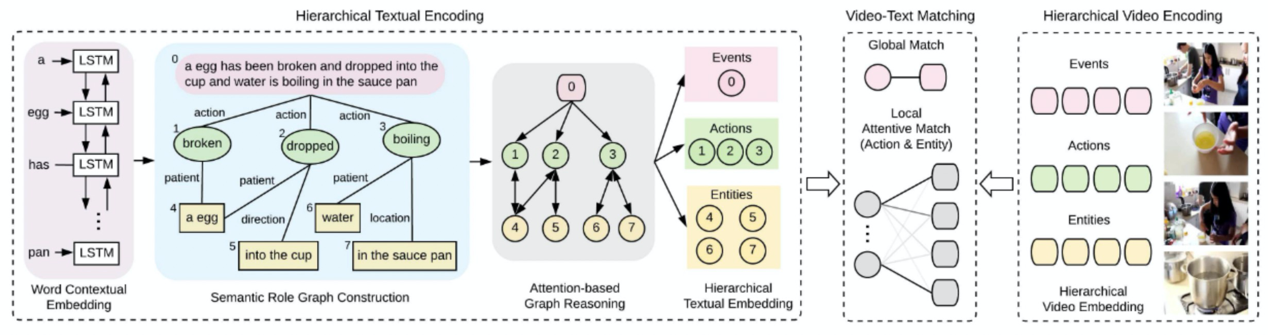
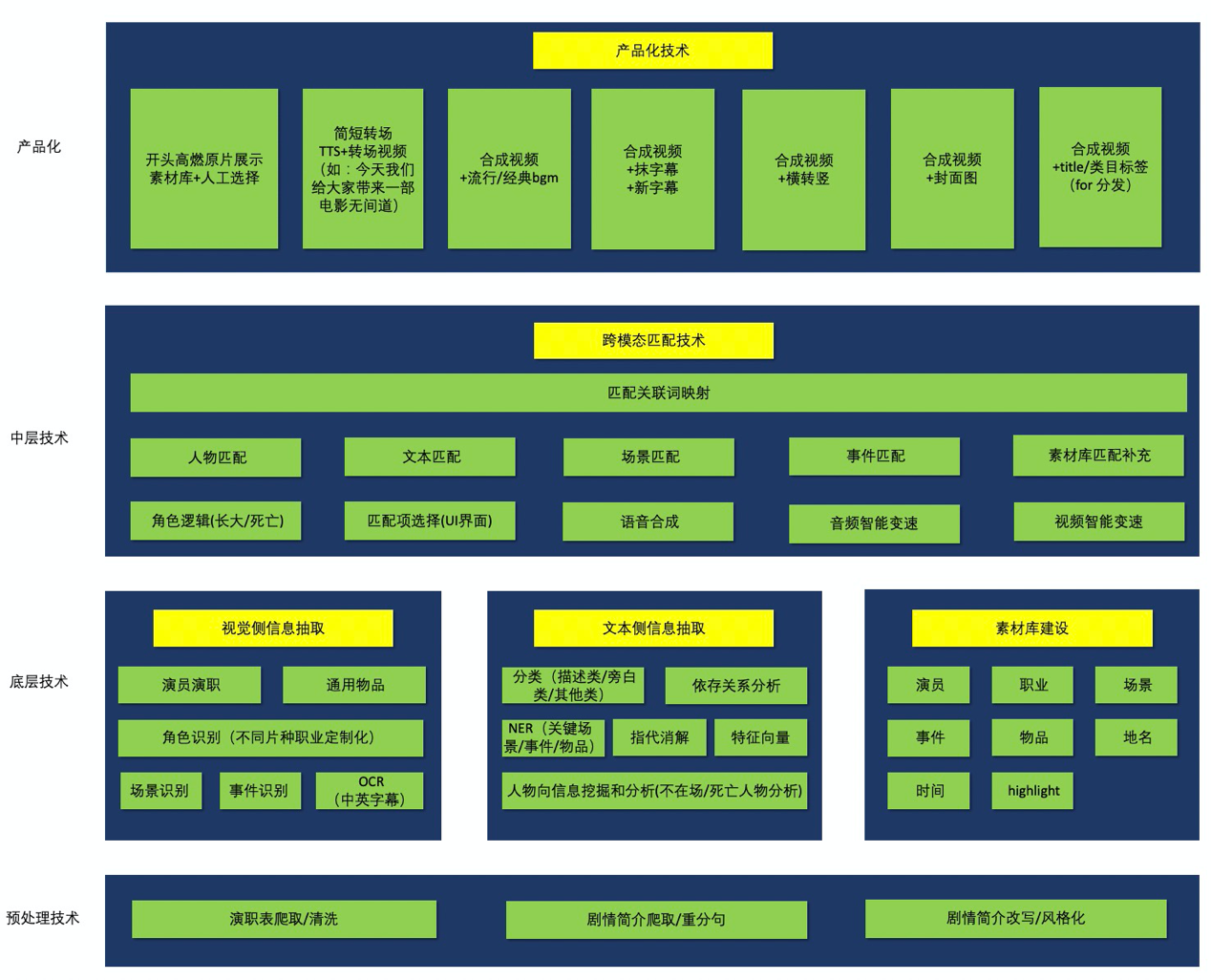
二、算法描述
2.1 算法框架概览
2.2 特征设计
2.2.1 视频特征
视频侧特征提取需要首先进行视频结构化(通过对视频中的图像信息进行智能分析,提取出关键信息,并进行文本的语义描述)。

2.2.2 文本特征
文本侧信息的提取包括了几个部分:文本分类、命名实体识别(Named Entity Recognition)、指代消解和依存关系分析。这些技术模块在一起组成完整的文本处理链路,提取出文本的关键特征之后供多模态匹配使用。
文本分类为匹配算法的权重提供重要依据,匹配算法将按照句子的分类结果采用合适的匹配策略。例如对于描述性的文本采用人物、场景、行为的嵌入向量匹配;对于对白的文本采用 ocr 文本匹配。
命名实体识别可以提取出文本中的命名实体,例如人物、行为、场景等关键信息,这些结构化数据可以通过相似度算法与视频的嵌入向量计算语义距离,从而为基于嵌入向量和标签的匹配算法提供重要的打分函数。采用 Bert[1]模型来进行文本分类和命名实体识别的任务,具体来讲,使用在其他的较大的中文语料库上预训练的模型,然后在自己标注的数据集上进行调优。
指代消解和依存关系分析为消除文本特征中的歧义和冗余项提供了工具。剧情文本中的句子存在很多代词指代的情形,无法用 NER 直接推理出关键的人物。例如,陈永仁听说韩琛新进了一批毒品,于是他赶快把这个消息传递给了黄志诚。第二个子句中的他,如果没有指代消解的能力,就无法准确提出。
句子的依存关系分析则在此基础之上提炼出句子中最关键的信息部分,舍弃干扰项,大大提升提取特征的质量。剧情文本当中通常会有不少定语和状语,这对于 text2video 的任务其实帮助很小,而且他们会扰乱句子主体的提取。这个时候,我们使用句子的依存关系分析,提取出最关键的主语、谓语(行为)和宾语,作为句子的主干成分,从而用作匹配的特征。
2.3 跨模态匹配
跨模态匹配解决如何对齐文本中的句子与视频片段的问题。这是一个非常困难的系统性问题。为了解决这个问题,我们设计了一个多层级的匹配算法,主要分为两个语义级别的匹配:嵌入向量级别和标签级别。
针对嵌入向量级别,我们会针对文本和视频分别训练一个语义嵌入向量提取模型,然后对每一个句子和视频的片段计算一个相应的语义嵌入向量,再用一个神经网络来学习这两个向量之间的匹配关系。这部分的数据我们采用人工标注了一部分。
嵌入向量级别可以解决广义上的语义匹配问题,然而有一些简单的逻辑可以低成本地使用标签级别的匹配算法快速、精准地完成。例如,文本中和视频中出现了对应的人物,那么我们可以使用对应的人物标签来过滤到非匹配的片段。针对这个问题,我们设计了一些有效的相似度分数评估函数,用来计算标签之间的语义距离,从而为搜索匹配进行打分排序。
2.4 文本匹配
对于文本的匹配有两种不同的需求:分别是短句级别的短文本匹配和句子级别的匹配,在此采用词向量的方式来计算文本的相似度。在公开的中文语料库(800 万中文词)上训练了词向量模型,用来计算短语的词向量。
对于短语级别的文本匹配,直接根据词向量模型所计算的词向量作为匹配的依据。对于句子级别的文本匹配,对句子中的词语单独计算词向量,然后进行加权平均作为整个句子的词向量。
有了短语和句子的词向量之后,还需要根据词向量计算文本的距离。所使用的基准方法非常简洁:在计算句子中短语的词嵌入的平均值之后计算两个句子的词嵌入的余弦相似性。这个方法虽然简洁但是在大部分场景下表现都符合预期。针对比较困难的场景,使用词移距离,计算其中一文本中的单词在语义空间中移动到另一文本单词所需要的最短距离。
三、效果展示
四、参考文献及备注
[1] Learning a Text-Video Embedding from Incomplete and Heterogeneous Data
[2] A Neural Multi-sequence Alignment TeCHnique (NeuMATCH)
[3] Use What You Have: Video Retrieval Using Representations From Collaborative Experts
[4] Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning
备注:TTS 语音合成技术由阿里巴巴达摩院语音实验室提供




