
JSON 是⼀种轻量级的数据交换格式,强⼤⽽简单,是流⾏的最主要的数据交换之⼀。Marshal 这⼀术语是指是将语⾔的内存对象,解析为 JSON 格式的字符串。本⽂主要分析在 Golang 语⾔原⽣包内,是如何实现将结构体解析为 JSON 字符串,分析代码基于 go 1.14.2 。
前置知识
语言类型
Marshal ⽬标是,将 Golang 的对象转换成符合 json 标准的字符串。 对象由结构体实例化⽣成,Golang 语⾔使⽤type 和 struct 关键词来定义结构体。结构体是复合类型,由其域成员嵌套组成树状结构。成员也会可能有 map 、array 、 struct 等复合类型。
stu := Student{ Name: "张三", Age: 18, High: true, sex: "男"} 可以被解析为:
'{"name":"张三", "age":18, "high":"true", "set":"男"}'从序列化的⻆度考虑,我们将 Golang 内部数据类型分为两类,基本类型和复合类型:

复合类型,需要⼀系列复杂递归流程⾄基本类型,才能⽣成字节序列。⽽简单的类型,可以直接⽣成字节序列。每种类型都有对应⼀种编码函数,取 Bool 类型举例,其编码函数为 boolEncoder,如下,只是简单的写⼊ buffer ⾥ “true/false”。其余除 String 内各种转义处理会略麻烦,其余都相对简单,不做具体分析。
func boolEncoder(e *encodeState, v reflect.Value, opts encOpts) { if opts.quoted { e.WriteByte('"') } if v.Bool() { e.WriteString("true") } else { e.WriteString("false") } if opts.quoted { e.WriteByte('"') }}反射
Golang 结构体序列化 JSON 的过程,利⽤了语⾔内置的反射的特性来实现不同数据类型的通⽤逻辑,所以我们要先对其⽤到的反射有⼀定的认知。
编程语⾔⾥,每个对象可以有两个不同维度的属性,即类型和值,如 Golang 的 object 有 Type 和 Value。 Type 表示类型,每个⾃定义定义的结构体,是⼀种不同的类型,如结构体的组成不同,就是不同类型,⽽Value 装载具体对象的值。可以理解为,Value 装载了具体的字节块,⽽ Type 对象装载了该字节块的模式, 字节块没有边 界,要按 Type 来格式化为对象。
Value 和 Type 在程序执⾏中,也是具象化的具体结构体对象,存储了具体的值,其内部采⽤冗余字段的⽅式来对不同类型提供⽀持。除了 Value 和 Type,还有个更⾼维度的属性 Kind,Kind 应当被理解为 Type 更⾼⼀层的抽象, Type 类⽐为⼩汽⻋、公交⻋、救护⻋等,Kind 则表示机动⻋。Golang 总共定义了 27 种不同的 Kind,其值为 uint 类型的枚举值 。
reflect 包提供了较为完善的机制来⽀持使⽤反射的特性,如 Type 和 Value 都提供了 Kind()⽅法⽤来获取其属于的 Kind 常量。reflect.Value 可以装载任意类型的值,反射函数 reflect.ValueOf 接受任意的 interface{} 类型, 并返回⼀个装载着其动态值的 reflect.Value。通过使⽤ Value 提供的 v.Elem()来获取 interface()或者 pointer 的 Value 值。使⽤反射,默认使⽤者(Json 序列化包)清楚其原始类型,否则会直接 panic,如对⾮ Array、Chan、Map、Ptr、or Slice 类型调⽤ Elem()。
type Type interface { // Key returns a map type's key type. // It panics if the type's Kind is not Map. Key() Type // Elem returns a type's element type. // It panics if the type's Kind is not Array, Chan, Map, Ptr,or Slice. Elem() Type}// Elem returns the value that the interface v contains// or that the pointer v points to.// It panics if v's Kind is not Interface or Ptr.// It returns the zero Value if v is nil.func (v Value) Elem() Value { // ....}对⽤户⾃定义的不同结构体⽽⾔,其 reflect.Type 不⼀样。reflect.Type 之间的相互⽐较,会循环递归保证内部所有域确保⼀致。⽤户⾃定义的结构体和内置类型同样凑效。
reflect/type.go:2731if comparable { typ.equal = func(p, q unsafe.Pointer) bool { for _, ft := range typ.fields { pi := add(p, ft.offset(), "&x.field safe") qi := add(q, ft.offset(), "&x.field safe") if !ft.typ.equal(pi, qi) { return false } } return true }}上述反射知识,有助于我们深⼊理解源码,此处先抛出 2 个相关问题:
上⽂提到的每种类型都有对应⼀种编码函数 encoderFunc,究竟是对不同的 Kind,还是对应不同的 Type?
下⽂会讲到序列化的缓存中间结果,那么缓存是针对不同的 Kind 还是针对不同的 Type 来缓存?
解析流程
Json Marshal 的流程,有两条主线,⼀条是利⽤Golang 反射原理,使⽤递归的解析结构体内所有的字段,⽣成字节序列,有两处递归;另外⼀条主线是,尽可能的缓存可复⽤的中间状态结果,以提⾼性能,有三处缓存。
从 序列化的⼊⼝ marshal 出发,我们看到,其中 valueEncoder 内部会调⽤预处理过程 typeEncoder,valueEncoder 将会调⽤ newTypeEncoder,⽣成每种类型对应的 encoderFunc。然后对每种类型调⽤的相对应的 encoderFunc 执⾏具体序列。
func (e *encodeState) reflectValue(v reflect.Value, opts encOpts){valueEncoder(v)(e, v, opts)}参考下⾯代码,可以看到 switch t.Kind() 返回语⾔数据类型的,是对每种 Kind 有对应⼀种编码函数 encoderFunc,那上⽂的问题⼀是否可以回答了?理由是:encoderFunc 可以统⼀在 Kind 层,是因为每种 Kind 的处理逻辑是相同的,况且,因为 struct 是⽤户可以⾃定义的,所以具体的 Type 是⽆穷的,也不可能将执⾏逻辑为每种 Type 定义⼀种。
其实不然,虽然每种 Kind 的处理逻辑是相同的,但是每种 Type 所对应的值是不⼀样的,如代码中 newStructEncoder(t) 返回的是具体的 structEncoder 的⽅法,和该 struct 对应的 Type 的具体值有关联。 所以,上⽂的问题⼀的回答应该是对每⼀种 Type,⽣成基于 Type 的编码⽅法 se.encode(…)。
func newTypeEncoder(t reflect.Type, allowAddr bool) encoderFunc { // ⾸先,对实现了 Marshaler 或者 TextMarshaler的,且可以寻址的,直接返回⾃定义的 encoder // 然后,对各种类型进⾏encode,复合类型继续调⽤typeEncoder递归处理 switch t.Kind() { case reflect.Bool: return boolEncoder case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32,reflect.Int64: return intEncoder # 等等各种类型 case reflect.Struct: return newStructEncoder(t) case reflect.Slice: return newSliceEncoder(t) case reflect.Ptr: return newPtrEncoder(t) default: return unsupportedTypeEncoder } //... ...}注:此处笔者对源码⾥多处命名表示质疑,如 valueEncoder 的⽬的是输出每种 Kind 的 encoderFunc,⽤ valueEncoder 命名会让读代码者产⽣⼀定困惑。还有调⽤链路 中,typeEncoder 的命名,它只是⽐ newTypeEncoder 多了⼀层缓存,typeEncoder 更合适的应该是 cachedTypeEncoder,newTypeEncoder 应该恢复为 typeEncoder。 这样也会与源码中的 cachedTypeFields 保持⼀致。
主线⼀:两处递归
从源码看到,Marshal 流程,包含两处递归:
递归遍历结构体树状结构,对内部结点⽣成其对应类型编码器 encodeFunc,或者开发者⾃定义的编码器(TextMarshaler、Marshaler),递归的结束条件是最终递归⾄基本类型,⽣成基本类型编码器。
启动类型编码器调⽤,依赖类型编码器函数内部递归,从根节点依次调⽤整棵树的序列化函数。递归的结束条件是递归⾄基本类型编码器,⽣成字符编码。
递归是为了处理复杂类型, 如类型编码器调⽤过程中,复合类型 Ptr(指针) 、Slice、(切⽚)、Array、Map 处理过程类似。Ptr 编码器函数 通过 t.Elem() 递归调⽤typeEncoder;Array/Slice 编码器函数通过 t.Elem() 递归调⽤ typeEncoder;Map 稍微复杂,不但通过 t.Elem() 递归调⽤ typeEncoder,其额外的操作是的对其 Key 进⾏处理,通过判断其 Key 类型,操作如下:
Key 为 string 类型,直接存储为 JSON 字符序列的 Key 值。
Key 为 ⾮string 类型,且实现了 TextMarshaler,按 TextMarshaler 的实现处理,最终将⾮string 的 key 转换为 string 类型,直接存储为 JSON 字符序列的 Key 值。
其他类型,输出不⽀持错误。因为常规的 JSON Key 也是 string 类型。下⽂代码,是 struct 的类型编码器递归调⽤过程,它⾸先遍历所有的成员,并通过 f.encoder 来调⽤每个成员的编码函数,如果成员是复合类型,则会⼀层层深⼊调⽤,是⼀个较为完整的⼴度优先遍历:
func (se structEncoder) encode(e *encodeState, v reflect.Value,opts encOpts) { next := byte('{')FieldLoop: for i := range se.fields.list { f := &se.fields.list[i] fv := v for _, i := range f.index { ...... fv = fv.Field(i) } e.WriteByte(next) next = ',' ...... opts.quoted = f.quoted // 递归调⽤ f.encoder(e, fv, opts) } if next == '{' { e.WriteString("{}") } else { e.WriteByte('}') }}递归调⽤,最终会形成树状调⽤结构体,对如下 Student 的结构体对应的对象,其最 终的递归树状图如下:
type Student struct { Name string `json:"name"` Age int CurrentClass *Class Classes []Class Friends map[string]Student}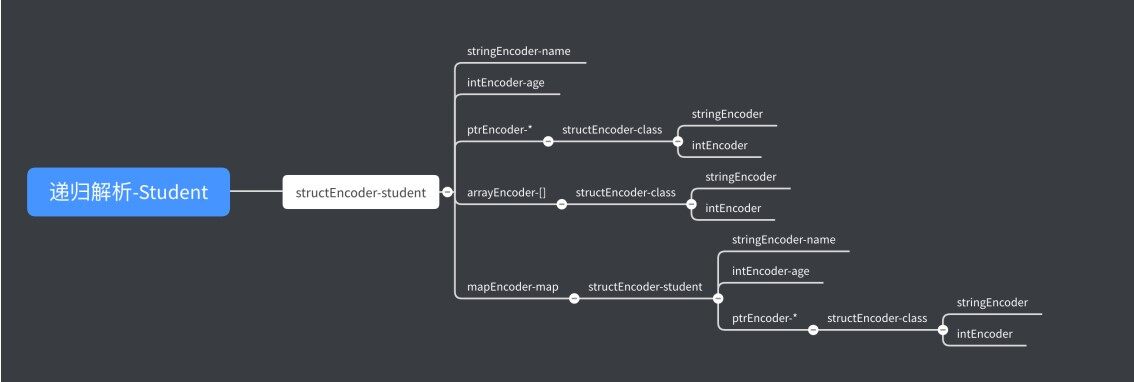
主线二:三处缓存
序列化的过程中,使⽤了三处全局缓存,来提⾼性能。其中 ⼀个 sync.poll 缓存了临 时对象,两个 sync.map 分别缓存了解析的中间过程编码函数,和结构体的分析及预 处理值。 注意这⾥是程序进程全局缓存,可以在进程内通⽤于序列化任意对象,这是因为 ⼀个进程中,Type 是唯⼀的,其⽤于序列化的属性是稳定不变的,可以全局通⽤。
sync.poll 存储 encodeState
sync.poll 是 Golang 官⽅提供⽤来缓存分配的内存的对象,以降低分配和 GC 压⼒。 序 列化中,encodeState 的⾸要作⽤是存储字符编码,其内部包含了 bytes.Buffer,由于 在 json.Marshal 在 IO 密集的业务程序中,通常会被⼤量的调⽤,如果不断的释放⽣成 新的 bytes.Buffer,会降低性能。 官⽅包的源码可以看到, encodeState 结构体被放 进 sync.poll 内(var encodeStatePool ),来保存和复⽤临时对象,减少内存分配, 降低 GC 压力。
// An encodeState encodes JSON into a bytes.Buffer.type encodeState struct { bytes.Buffer // accumulated output scratch [64]byte // ⽤来避免层级递归层级过深,遇到层级过深的 时候,会主动失败。 ptrLevel uint ptrSeen map[interface{}]struct{}}sync.poll 内部的 bytes.Buffer 提供可扩容的字节缓冲区,其实质是对切⽚的封装,结 构中包含⼀个 64 字节的⼩切⽚,避免⼩内存分配,并可以依据使⽤情况⾃动扩充。⽽ 且,其空切⽚ buf[:0] 在该场合下⾮常有⽤,是直接在原内存上进⾏操作,⾮常⾼效, 每次开始序列化之处,会将 Reset()。
func (b *Buffer) Reset() { b.buf = b.buf[:0] b.off = 0 b.lastRead = opInvalid}解析初始,从 encodeStatePool 内获取”旧内存”,并进⾏ Reset
func newEncodeState() *encodeState { if v := encodeStatePool.Get(); v != nil { e := v.(*encodeState) e.Reset() ... e.ptrLevel = 0 return e } return &encodeState{ptrSeen: make(map[interface{}]struct{})}}sync.map 存储 encoderFunc
var encoderCache sync.Map // map[reflect.Type]encoderFunc在序列化过程中利⽤了反射的特性来处理不同类型的通⽤逻辑。在递归过程中,产⽣的不同的类型所对应的 encoderFunc, 都会被存储在全局的 sync.map 内。通过对中间过程产⽣的 encoderFunc 缓存,减少每次⽣成的开销。
如上⽂阐述中提到,Golang 通过反射,将对象两个维度的属性提取,即 reflect.Type、reflect.Value。在树状递归过程中,使⽤reflect.Value 来进⾏传递。使⽤reflect.Type 来作为 key 来缓存不同的 encoderFunc。此处回答下上⽂提出的问题⼆:存储只以 Type 为维度,举个例⼦,根据上⽂ reflect.Type 描述可知道,含有不同数据成员的 struct 是对应不同的 Type,如果 structA 内部有嵌套其他 structB。structA、structB 会被独⽴的两个 key 被存储起来,查找 structA 时候,可以直接获取其对应的 encoderFunc。
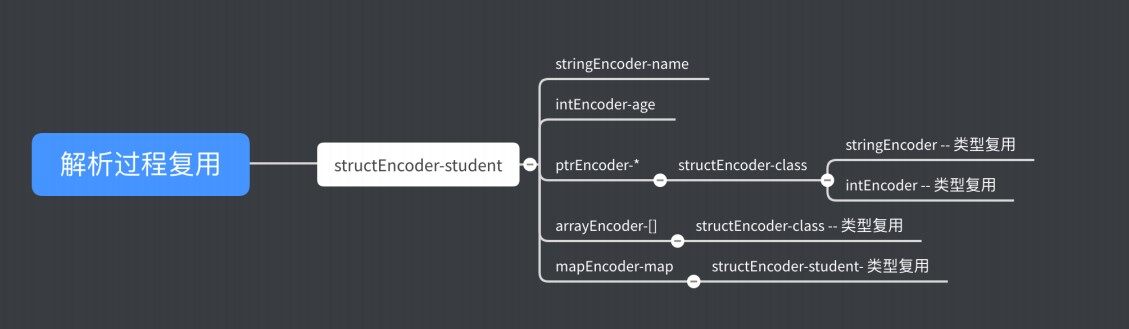
在序列化 student 对象后,进⾏ school 对象的序列化,由于包含 student 类型,全局 复⽤示例如下:
type School struct { Name string `json:"name"` Students []Student}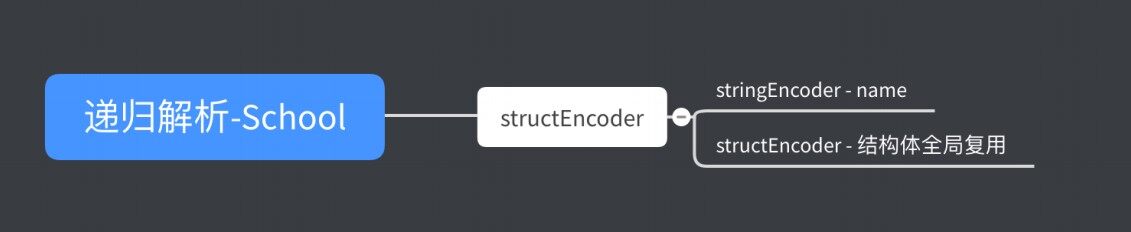
sync.map 存储 struct 对应的 filed list
var fieldCache sync.Map // map[reflect.Type]structFields程序执⾏过程中,结构体内部分成员属性是必然保持稳定,在序列化过程中可以被加 以利⽤来提⾼性能,如:
某个域,是否需要被序列化;
每个域的对应 encoderFunc;
序列化成 Json 时候的 key 值,如 student 内 name 域将被预处理为 “name”: 。
是否是嵌套其他 struct 等特性。
fieldCache 正是缓存 Json 序列化过程中所需的结构体内部分成员属性⽽产⽣的。 它 也是 sync.Map 类型,其作⽤是为了缓存⼀些预处理的结果,在最终递归⽣成 json 字 符串时候使⽤。
序列化过程中,所需的稳定的结构体属性的如下 structFields 和 field 所示。我们 可以看到,有 nameBytes、nameNonEsc 等对应序列化过程中固定的属性或者值,都 可以被缓存下来,如 student ⾥的 Age 域,会被预处理为 ’”age”:‘,对每次序列化⽽⾔,都稳定不变。
type structFields struct { list []field nameIndex map[string]int}// A field represents a single field found in a struct.type field struct { name string nameBytes []byte // []byte(name) equalFold func(s, t []byte) bool // bytes.EqualFold orequivalent nameNonEsc string // `"` + name + `":` nameEscHTML string // `"` + HTMLEscape(name) + `":` tag bool index []int typ reflect.Type omitEmpty bool quoted bool encoder encoderFunc}为了性能考虑,序列化过程,缓存起来 struct ⾥每个 filed 对应的值,避免重复处理。同样为了提⾼速度,对结构体以上稳定属性进⾏预处理,且存储下来。⽽且,json 解析过程中,会存在结构体 array/map 等⼤量重复使⽤同⼀结构体的情况,该措施可以有效提⾼性能。
结构体的处理⽐较复杂,其中 typeFields 不仅仅只是列出 field 的事情要多,⽽且还做了⼀定的预处理,如对每个字段⽣成其 name 值,并存储:
对结构体内的域,进⾏⼴度优先遍历,识别出所有需要解析的字段。
去除所有 omitempty 且值为零值的字段,或者 tag 内有 ”-“ 字段。
遍历 json tag,对每个字段⽣成其 name 值,如这样的字符串 "name:"
如果 bool int float 对应的 tag 是 string ,则进⾏处理,标识需要添加 "
对匿名结构体、或者相同 tag 的结构体进⾏处理
下⾯结合源码,对其⼴度优先递归遍历 fields 的过程摘出进⾏分析。基本思想:原始 结构体定义为顶点 v,访问它的所有 field1, field1,..., fieldn,然后再依次访问 field1, field1 field2,…, fieldn 的域,直到所有与 v 有相通路径的所有顶点都被访问完为⽌。为 了避免结构体的引⽤关系可能会形成有向图状结构,遍历过程中使⽤了 visited 避免嵌 套进⾏。具体代码参⻅ typeFields 函数,先结构体内结构体的所有域,压⼊fields 内。然后对每个 filed 递归调⽤typeEncoder,获取所有的 encoderFunc。
func typeFields(t reflect.Type) structFields { // Anonymous fields to explore at the current level and thenext. current := []field{} next := []field{{typ: t}} // Types already visited at an earlier level. visited := map[reflect.Type]bool{} // Fields found. var fields []field for _, f := range current { if visited[f.typ] { continue } visited[f.typ] = true // Scan f.typ for fields to include. for i := 0; i < f.typ.NumField(); i++ { sf := f.typ.Field(i) // Record found field and index sequence. ⽣成 field field.nameNonEsc = `"` + field.name + `":` fields = append(fields, field) continue } } for i := range fields { f := &fields[i] f.encoder = typeEncoder(typeByIndex(t, f.index)) } return structFields{fields, nameIndex}}总结
本⽂剖析了 json 序列化的源码,并对⼀些关键细节进⾏分析。Json 序列化的源码使 ⽤反射来处理各种不同类型之间的通⽤逻辑,并通过递归来简化代码逻辑。
Json 序列化的源码同样也展示了在有⾼性能要求的代码的过程中,缓存的重要 性,需要尽可能多的缓存中间结果。这些细节,对于我们写⼀些基础的组件,有⼀定 的借鉴意义。




