
现如今企业的数据查询需求在不断增多,在共享同一集群时,往往需要同时面对多个业务线或多种分析负载的并发查询。在有限的资源条件下,查询任务间的资源抢占将导致性能下降甚至集群不稳定,因此负载管理的重要性不言而喻。
从业务场景出发,用户负载管理的需求主要来自以下几方面:
多个业务部门或租户可能共享同一套集群时,为避免不同租户间的负载相互影响,需保证每个租户的资源使用独立性和性能稳定性。
不同业务对查询任务的响应度和优先级有着不同要求,对于关键业务或高优先级任务,如实时数据分析、在线交易等,需要确保这些任务能够获得足够的资源并优先执行,避免因资源竞争对查询性能产生影响。
用户不仅关心资源的分配和管理,还注重成本控制和资源利用率。负载管理方案需在满足隔离要求的同时,实现用户对低使用成本和高资源利用率的诉求。
在早期版本中,Apache Doris 推出了基于资源标签(Resource Tag)的隔离方案,包括集群内节点级别的资源组划分以及针对单个查询的资源限制,实现了不同用户间的资源物理隔离。而为给用户提供更完善的负载管理方案,Apache Doris 自 2.0 版本起,推出了基于 Workload Group 的管理方案,实现了 CPU 资源的软限,为用户提供较高的资源利用率。在新发布的 2.1 版本基于 Linux 内核提供的 CGroup 技术,进一步地实现了对 CPU 资源的硬限,为用户提供更好的查询稳定性。
基于 Resource Tag 的物理隔离方案
在 Apache Doris 中有 FE 和 BE 两类节点,FE 节点负责元数据存储、集群管理、用户请求接入以及查询计划解析等,BE 节点则负责数据的存储和计算。在查询执行过程中涉及资源消耗的主要是 BE 节点,因此 Apache Doris 负载隔离方案都是面向 BE 节点设计。
在 Resource Tag 资源物理隔离方案中,可以对同一个集群内的 BE 节点设置标签,标签相同的 BE 节点会组成一个资源组(Resource Group),可将资源组看作数据存储和计算的一个单元。数据入库时会按照资源组配置将数据的副本写入到不同的资源组中,查询时按照资源组的划分使用对应资源组上的计算资源进行计算。
参考文档:https://doris.apache.org/zh-CN/docs/2.0/admin-manual/resource-admin/multi-tenant
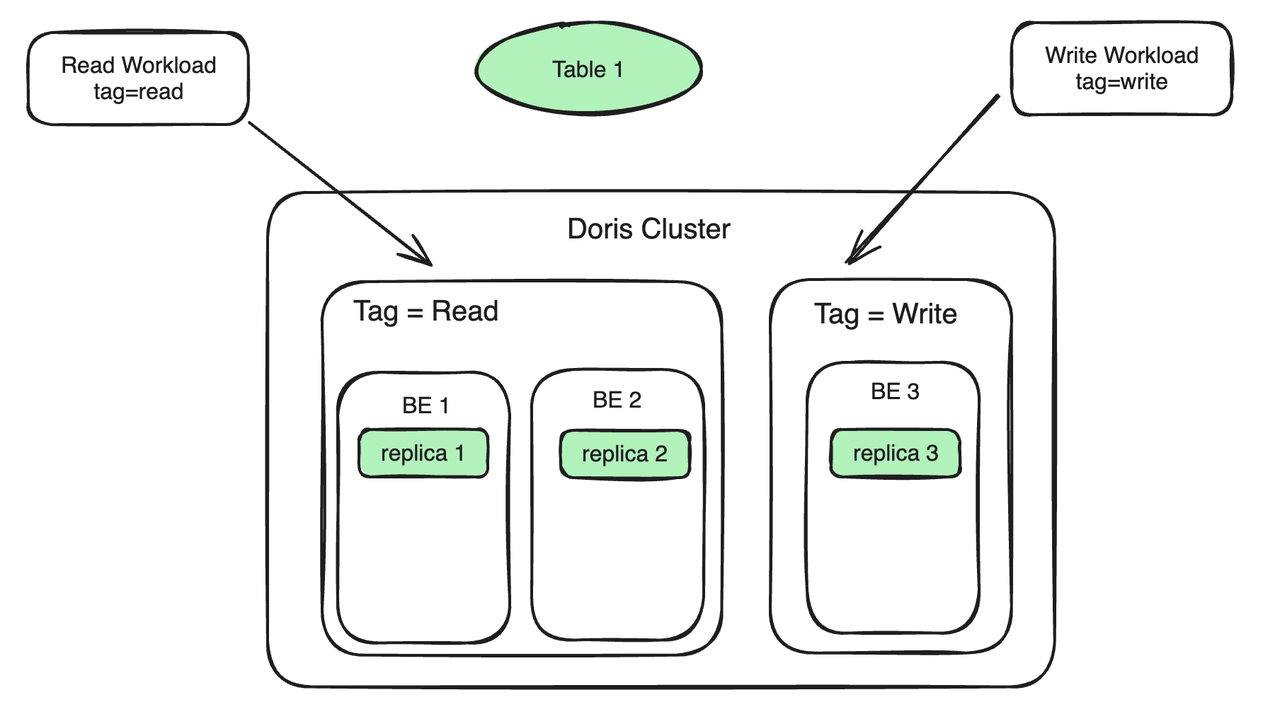
我们以常见的读写分析场景为例,假设集群中有 3 台 BE,具体使用步骤如下:
BE 节点绑定 Resource Tag:将两台 BE 绑定到 Tag Read 上,服务于读负载;一台 BE 绑定到 Tag Write 上,服务于写负载。读负载和写负载位于不同的机器上,以实现读写隔离。
数据副本绑定 Resource Tag:Table 1 有三个副本,两个副本绑定到 Tag Read 上,一个副本绑定到 Tag write 上。写入 replica 3 的数据会自动同步到 replica 1 和 replica 2 上,同步过程不会占用过多 BE 1 和 BE 2 的计算资源。
工作负载绑定到 Resource Tag:如果查询 SQL 携带的 Tag 为 Read,查询将被自动路由到 Tag 为 Read 上的机器上(BE 1 、BE 2)上执行;如果将 Stream Load 导入负载指定 Tag 为 Write,那么 Stream Load 就会路由到 Tag 为 Write 的机器上( BE 3)。在此过程除了副本同步时产生的开销,查询和导入之间不再有资源的竞争。
Resource Tag 还可以实现多租户的功能。例如有两个用户 UserA 和 UserB,期望创建各自独立的租户以避免相互影响,那么可以把 UserA 的计算和存储资源绑定到名为 UserA 的 Tag 上,把 UserB 的计算和存储资源绑定到名为 UserB 的 Tag 上,那么两个用户在 BE 侧就实现了租户间的资源隔离。

Resource Tag 本质是通过对 BE 节点的分组实现了资源隔离,这个方案的优点是:
隔离性好,多个租户之间通过物理机隔离,对 CPU、内存、IO 都实现了完全的隔离;
故障隔离,当一个租户出现问题(比如进程崩溃),另外一个租户丝毫不受影响;
基于这个技术,有的用户将不同的资源组放置到不同的物理机房内,实现同城 2 个机房的双活。
但是也存在一定的局限性:
读写隔离场景下,当写入负载停止时,Tag 为 Write 的机器就处于空闲状态,从而降低整个集群的资源利用率,显然无法满足用户对资源充分利用的期望。
多租户场景下,同一个租户内的多个业务方的负载之间也会相互影响。即使可以通过为每个业务方配置单独物理机来满足隔离性,却带来了高成本、低资源利用率等问题。
灵活性差,租户的数量实际是跟副本数绑定的,如果要建立 5 个租户,那么至少需要有 5 个副本才可以,这在一定程度上造成了存储空间的浪费。
基于 Workload Group 的负载管理方案
为解决上述问题,Apache Doris 推出了基于 Workload Group 的管理方案,支持了更细粒度的资源隔离机制——进程内的资源隔离,这意味着同一个 BE 内多个 Query 间也可以实现一定程度上的隔离,有效避免了进程内的资源竞争,提高资源的利用率。
Workload Group 是通过对工作负载进行分组管理,实现对内存和 CPU 资源的精细化管控。通过将用户执行的 Query 与 Workload Group 相关联,限制单个 Query 在单个 BE 节点上的 CPU 和内存资源的百分比。同时可以配置开启内存资源限制,集群资源紧张时自动终止组内高内存占用查询以缓解压力。资源空闲时,多个 Workload Group 共享空闲资源并自动突破限制,确保查询稳定执行。
CPU 资源的限制可细分为软限和硬限,CPU 软限具备资源利用率更高的特点,允许在资源空闲时候灵活分配资源;而 CPU 硬限则更侧重于性能稳定性的保障,确保各 Group 之间不会因负载变化而相互干扰。
(CPU 硬限和软限这两种隔离方式可匹配不同使用场景,但不可同时应用,用户可根据自身需求灵活选择)

Workload Group 与 Resource Tag 的方案主要有以下不同:
从计算资源的角度来说,Workload Group 是对 BE 进程内的 CPU 和内存资源进一步划分,多个 Workload Group 需要在同一个 BE 上竞争资源。而 Resource Tag 则是对 BE 节点进行分组,不同业务方的负载发送到不同分组的 BE 上实现资源隔离,不同 BE 分组间的业务负载不会有直接的资源竞争。
从存储资源的角度来说,Workload Group 无需关注存储资源,只关注单 BE 内计算资源的分配。Resource Tag 则需要对数据的副本进行分组,确保需要隔离的业务方数据分布在不同的 BE 上。
CPU 软限制
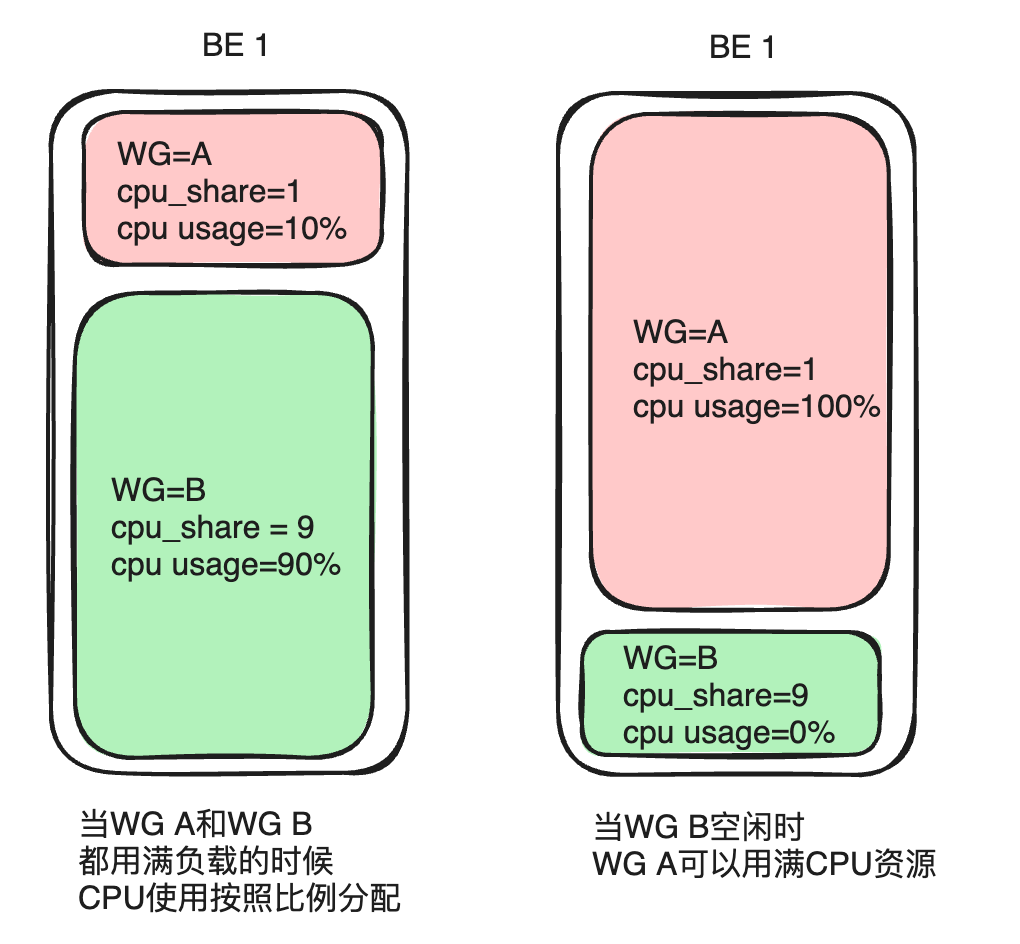
CPU 优先级主要通过参数 cpu_share 体现,可以将它类比为权重的概念。在相同的时间周期内,权重越高的 Group 可以获得更多的 CPU 时间。
以 Group A 和 Group B 为例,若配置 Group A 的 cpu_share 为 1、Group B 的 cpu_share 为 9,给定 10s 的时间周期。当两者负载均饱和时,权重更高的 Group B 可以获得 CPU 的时间为 9s(所有资源的 90%),Group A 可获得 CPU 时间为 1s(所有资源的 10%)。而在实际使用中,并非所有业务都是满负载运行,若 Group B 的负载较低或无负载,那么 Group A 可以独占 10s 的 CPU 时间。这种方式可以提供更高的资源分配灵活性,从而提高集群 CPU 资源的整体利用率。
CPU 硬限制
使用 CPU 软限时,如果系统负载较高或 CPU 资源紧张时,可能引起查询性能的波动。为满足更用户对查询性能稳定的高要求, Apache Doris 在最新的 2.1 版本中,实现了 Workload Group 的 CPU 硬限制——无论当前物理机整体 CPU 是否空闲,配置了硬限的 Group 最大 CPU 用量不能超过预先配置的限制值。
以 Group A 和 Group B 为例,若配置 Group A 的 cpu_hard_limit=10%,Group B 的 cpu_hard_limit=90%。当两者单机 CPU 资源均达到饱和时, Group A 的 CPU 利用率为 10%, Group B 的 CPU 利用率为 90%,这与 CPU 软限是一样的。但是当 Group B 的负载降低或没有负载时,即便 Group A 增加查询负载,其最大 CPU 利用率仍被严格限制在 10%,无法获得更多的资源。虽然这种方式牺牲了资源分配的弹性,但也确保了查询性能的稳定性。

内存资源限制
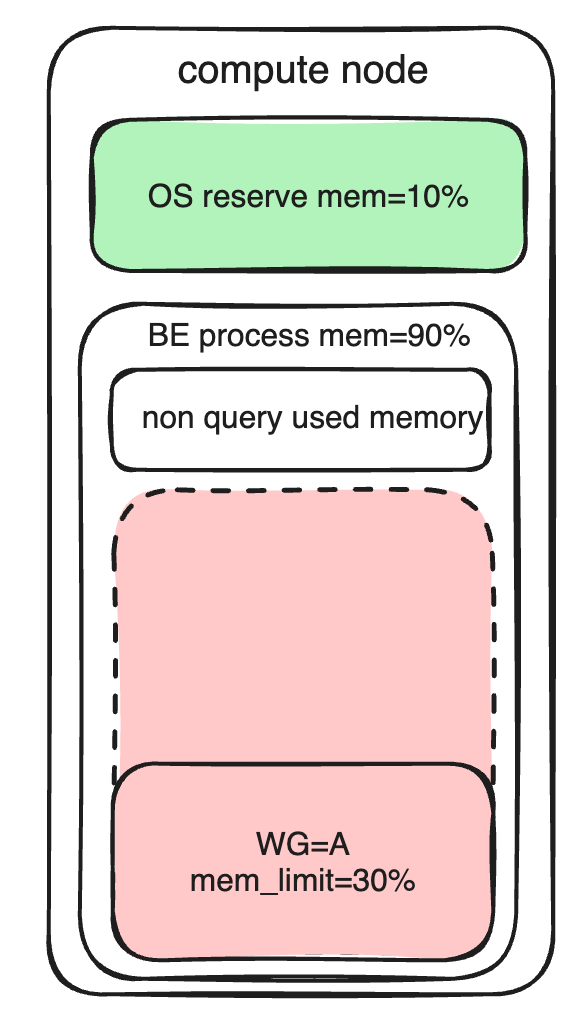
使用须知,BE 节点内存主要划分为以下几部分:
操作系统保留内存
BE 进程内非查询部分的内存,暂时无法被 Workload Group 统计到。
BE 进程内的查询部分的内存(包括导入操作),可被 Workload Group 统计并管理。
内存资源限制主要通过参数 memory_limit 来限制(设置可以使用 BE 内存的百分比)。不仅可以设置预配置内存用量,还影响内存过度分配(Overcommit)之后的归还优先级。
在初始状态下,高优先级的资源组会被配置更多的内存、低优先级的资源组被分配较少的内存。为了提升内存的利用率,可以通过 enable_memory_overcommit 开启资源组的内存软限制,如果系统有空闲内存资源时可以超限使用。
为了保证系统稳定运行,当系统整体内存资源不足时,系统将会优先取消占用内存较大的任务,以回收超额分配(Overcommit)的内存资源。在此过程中,系统会尽量保留高优先级的资源组内存资源,低优先级资源组超额内存将被更快收回。
查询排队
当业务负载超过系统可承载上限时,继续提交新的查询不仅无法有效执行,还会对运行中的查询造成影响。为避免该问题出现,Workload Group 支持查询排队功能。当查询达到预设的最大并发时,新提交计划会进入排队逻辑,当队列已满或等待超时,查询会被拒绝,以此来缓解高负载下系统的压力。
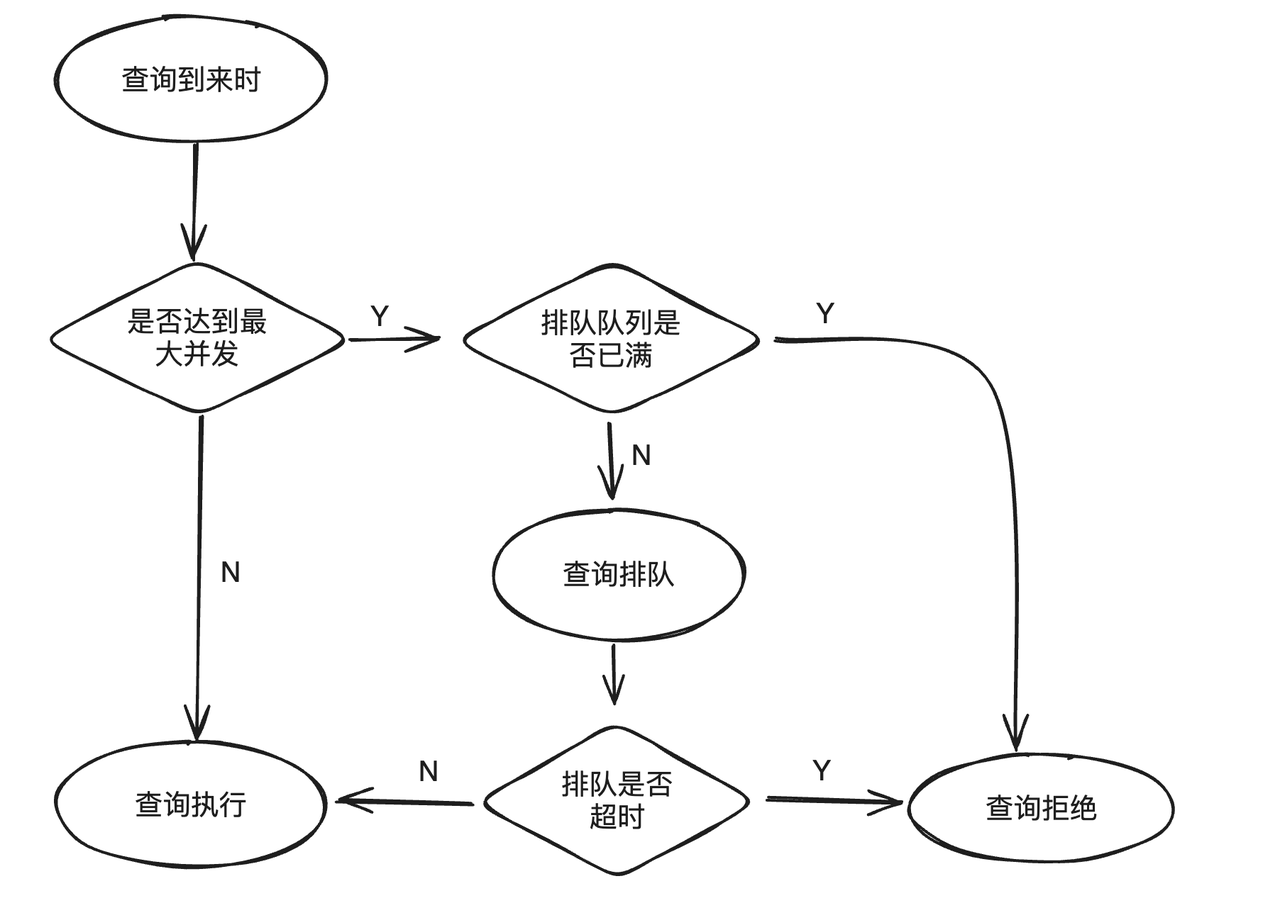
查询排队功能主要有三个属性:
max_concurrency:当前 Group 允许同时运行的最大 SQL 数,如果超过最大数值,则进入排队逻辑。max_queue_size:排队队列中的允许最大查询个数,如果队列满了,那么查询会被拒绝、执行失败。queue_timeout:队列中排队的时间限制,如果超时会直接失败,单位是毫秒。
参考文档:https://doris.apache.org/zh-CN/docs/admin-manual/workload-group
Workload Group 使用测试
接下来,我们对 Workload Group 的 CPU 软限制和硬限制进行详细测试,以便为用户清晰呈现这两种限制在相同硬件条件下的负载管理效果与性能表现。
测试环境:16 核 64G 内存单台物理机
部署方式:1 台 FE、1 台 BE
测试数据集:Clickbench、TPCH
压测工具:JMeter
CPU 软限测试
启动两个客户端(1、2),分别在未使用/使用 CPU 软限的前提下,测试 CPU 软限制对负载管理的效果。需要注意的是,在该测试中 Page Cache 会影响测试结果,需要关闭 Page Cache 才会达到理想的测试效果。

通过对比分析两次测试中的客户端的吞吐量数据,我们可以得出以下结论:
未使用 Workload Group 的情况下,两个客户端的吞吐量比例为 1:1,表明它们在相同运行时间内获得的 CPU 资源是相同的。
使用 Workload Group 之后, 分别设置
cpu_share为 2048 及 1024,结果表明吞吐量比例变为 2:1。这说明在相同的运行时间内,cpu_share参数更大的客户端 1 获得了更高比例的 CPU 资源。
CPU 硬限测试
由上文介绍可知,CPU 硬限制在负载较高时,可以保证很好的隔离性。因此我们使用硬限限制 CPU 使用率为 50%(cpu_hard_limit=50%),并使用同一客户端分别在并发数为 1、2、4 时(模拟不同负载)下执行 q23 查询测试,每次测试运行时间为 5 分钟。

从上方测试结果可知,随着查询并发数的增加,CPU 的利用率的始终稳定在 800% 上下(在一个 16 核的机器上,800% 的意味着使用 8 个核,实际的 CPU 利用率 为 50%)。由于 CPU 资源被硬限,因此在并发增加时,tp99 延时增加是符合预期的。
模拟生产环境测试
在实际生产环境中,用户往往更关注查询的延迟性能而非单纯的吞吐量。为了更贴近实际应用场景并准确评估性能,我们选取了一系列延迟约为 1 秒的查询 SQL(包括 CKBench 的 q15、q17、q23 和 TPCH 的 q3、q7、q19),构成一个 SQL 集合。这些查询涵盖了单表聚合和 Join 计算等多种特性,使用的 TPCH 数据集大小为 100G。
我们设计了两组测试,分别模拟了未使用 Workload Group 和使用 Workload Group 的场景。在客户端 1 和客户端 2 上进行了四次测试,重点关注 tp90 和 tp99 的延迟情况。
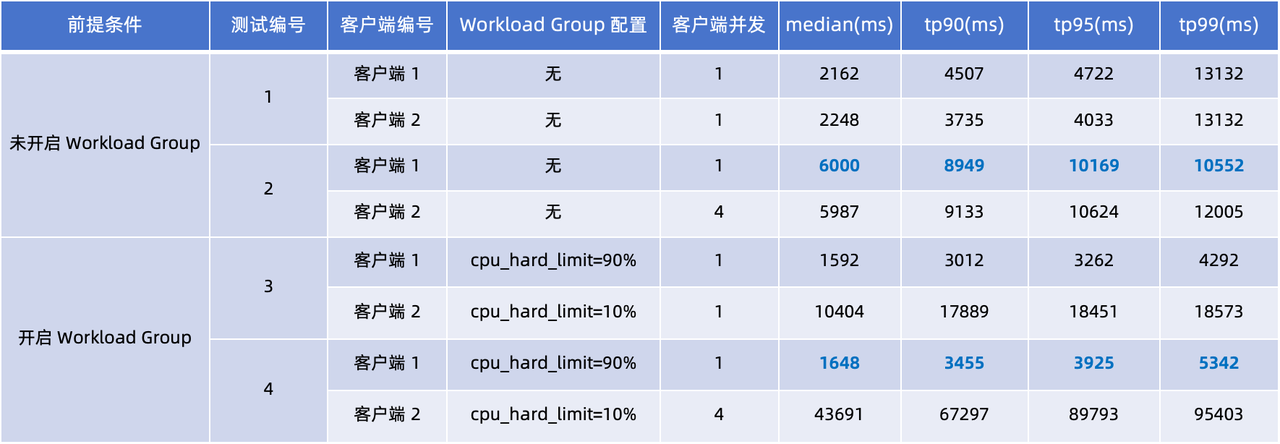
通过观察上表 4 次测试中查询延迟,可得出以下结论:
未使用 Workload Group(测试 1、2):当客户端 2 的并发量从 1 增加到 4 时,客户端 1、2 的查询延迟均显著上升。对比客户端 1 的性能表现,median、tp90 和 tp95 查询响应时间均增加了 2-3 倍。
使用 Workload Group(测试 3、4): 这两次测试中应用了 CPU 硬限制:设置客户端 1
cpu_hard_limit=90%、客户端 2cpu_hard_limit=90%。从测试结果可知,即使客户端 2 的并发量增加,客户端 1 的查询延迟仅呈现小幅上升,明显优于测试 2 中性能表现。这一结果充分展现了 Workload Group 在负载隔离和性能稳定保障上的有效性。
结束语
目前 Resource Tag 和 Workload Group 功能已经在多个社区用户的生产业务中上线并得到大规模验证,推荐有资源隔离需求的用户使用。
无论是 Resource Tag 或是 Workload Group,其目标都在于在资源隔离的独立性和资源的利用率二者之间进行平衡,前者采取了更彻底的隔离方案,而后者在保证隔离性的同时实现了资源的充分利用,并通过查询队列和任务排队机制进一步保证了在高工作负载场景下的系统稳定性。
在资源隔离的实际使用过程中,我们建议两种方案可以根据业务场景结合起来应用:
如果是跨体系/跨业务部门之间共享同一集群,希望实现资源和数据的物理隔离,可以采取 Resource Tag 方案;
如果是在同一集群内同时面对多种类型的查询负载,可以通过 Workload Group 将不同负载区分开来,通过灵活的资源分配保证多种查询负载均可以获得合适的资源;
在后续的功能完善上,我们还有很多规划:
当前内存限制通过 Cancel Query 来释放内存,未来通过算子落盘可以进一步提升大查询的稳定性、避免资源紧张时的查询任务失败。
目前在 BE 进程的内存模型中,还存在部分非查询的内存未被统计到,这可能导致用户看到的 BE 进程内存和 Workload Group 使用内存之间存在差异,未来版本中将尝试解决这个问题。
查询排队功能只支持根据最大查询并发数排队,未来将通过 BE 的资源用量来约束最大并发数,从而对客户端形成自动的反压,提升 Doris 在客户端持续提交高负载情况下的可用性。
Resource Tag 功能是对 BE 机器资源的划分,Workload Group 则是对单机进程内的资源划分,这两种资源划分的方式都对用户暴露了 BE 节点的概念。而用户在使用资源管理功能时,本质上仅需要关注自己的工作负载在整个集内的可用资源量和资源分配的优先级。未来会探索资源划分新方式,降低用户的理解和使用成本。
致谢
Workload Group 功能是开源社区合作开发的项目,感谢以下同学的贡献:罗甑林(luozenglin),刘立家(liutang123),赵立伟(levy5307)




