

介绍
Elasticsearch 是一个基于 Apache Lucene 并由 Elastic 开发的开源搜索引擎。它可扩展性、弹性和性能等特性都十分优越,全球各地的公司,包括 Mozilla、Facebook、Github、Netflix、eBay、纽约时报等,每天都在使用它。Elasticsearch 是大型数据集最受欢迎的分析平台之一,所有你能看到包含搜索引擎的地方都几乎有 Elasticsearch 的存在。它在操作数据时使用基于文档的方法,并且在用户执行搜索时几乎可以实时解析它。它以 JSON 格式存储数据,并按索引和类型组织数据。
如果我们在传统关系数据库的组件和 Elasticsearch 的组件之间进行类比,它们看起来像这样:
数据库或表 → 索引
行/列 → 包含属性的文档
Elasticsearch 的优势
它源自 Apache Lucene,提供了极其强大的全文搜索功能。
它使用基于文档的体系结构,将复杂的现实世界实体存储为结构化 JSON 文档。默认情况下,它会索引所有字段,这在搜索时提供了巨大的性能。
它不使用带有索引的模式。文档通过包含它们来添加新字段,从而可以自由添加、删除或更改相关字段,而无需与传统数据库模式升级相关的停机时间。
它对文档执行语言搜索,返回与搜索条件匹配的文档。它使用 TFIDF 算法对结果进行评分,使更多相关文档在结果列表中更高。
它允许模糊搜索,即使拼写错误的搜索词也可以帮助查找结果。
它支持实时搜索自动完成,在用户键入搜索查询时返回结果。
它使用 RESTful API,通过简单、轻量级的界面展示其功能。
Elasticsearch 以极快的速度执行复杂查询。它还缓存查询,返回与缓存过滤器匹配的其他请求的缓存结果。
它可以水平扩展,从而可以扩展资源并平衡集群节点之间的负载。
它将索引分解为碎片,每个碎片具有任意数量的副本。每个节点都知道集群中每个文档的位置,并在必要时在内部路由请求以检索数据。
术语
Elasticsearch 使用特定术语来定义其组件。
集群:一起工作的节点集合。
节点:作为集群一部分的单个服务器,存储数据,并参与集群的索引和搜索功能。
索引:具有类似特征的文档集合。
文档:可以编制索引的基本信息单元。
Shard(分片):索引分为多个部分,称为分片,允许索引水平缩放。
副本:索引分片的副本
前期准备
要完成此次 demo,我们至少需要以下之一:
已配置好的 Rancher 部署和 Kubernetes 集群,或
两个节点,在其中部署 Rancher 和 Kubernetes,或
用于部署 Rancher 的节点和在托管提供程序(如 GKE)中运行的 Kubernetes 集群。
本文使用 Google Cloud Platform,但您也可以使用任何其他提供商或基础架构。
启动 Rancher
如果您还没有部署 Rancher,请先启动一个,具体步骤可以参考此处快速上手指南:
https://rancher.com/quick-start/
启动集群
根据这一指南,使用 Rancher 设置和配置最适合您的环境的集群:
https://rancher.com/docs/rancher/v2.x/en/cluster-provisioning/
部署 Elasticsearch
如果您已经习惯了 kubectl,可以直接使用 manifest。如果您更喜欢使用 Rancher 用户界面,请继续往下阅读。
我们将 Elasticsearch 部署为具有两个服务的 StatefulSet:一个是用于与 pod 通信的 headless service,另一个则用于从 Kubernetes 集群外部与 Elasticsearch 交互。
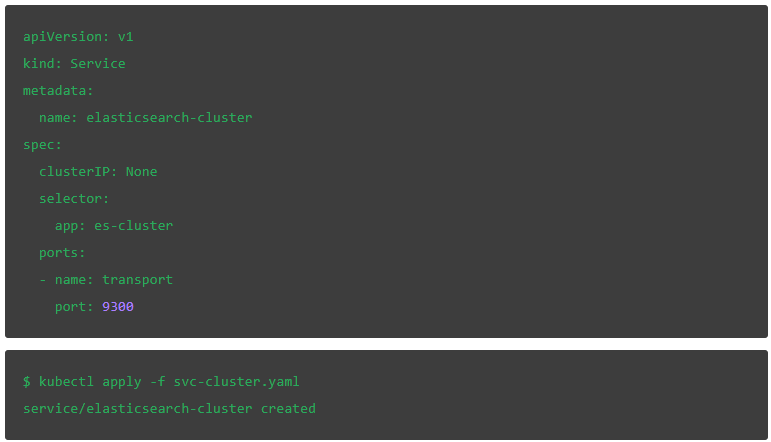
svc-cluster.yaml
svc-loadbalancer.yaml

es-sts-deployment.yaml
通过 Rancher UI 部署 Elasticsearch
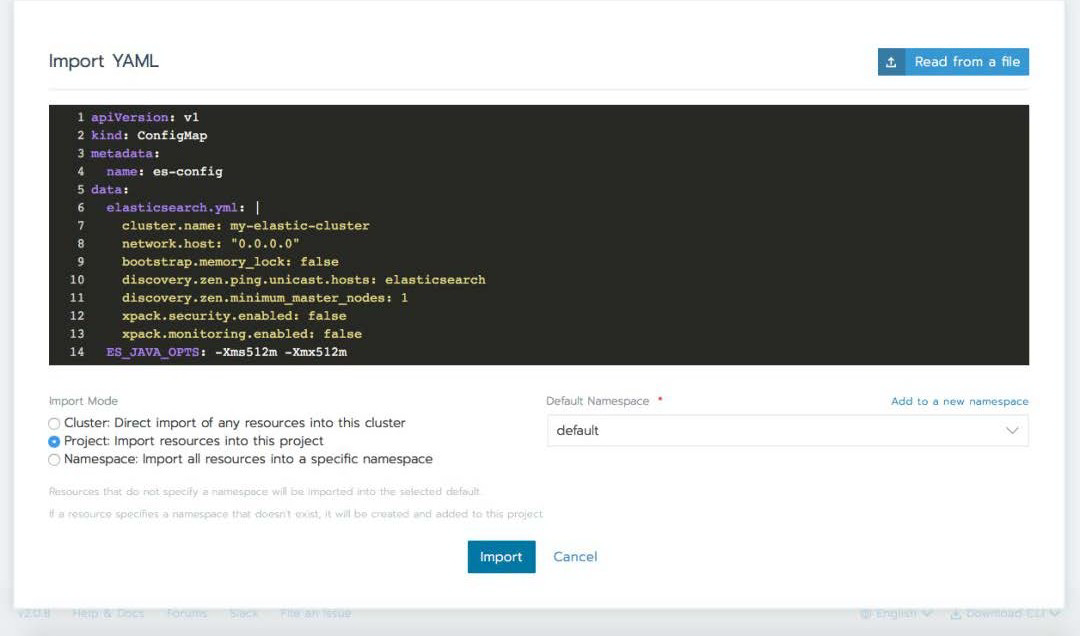
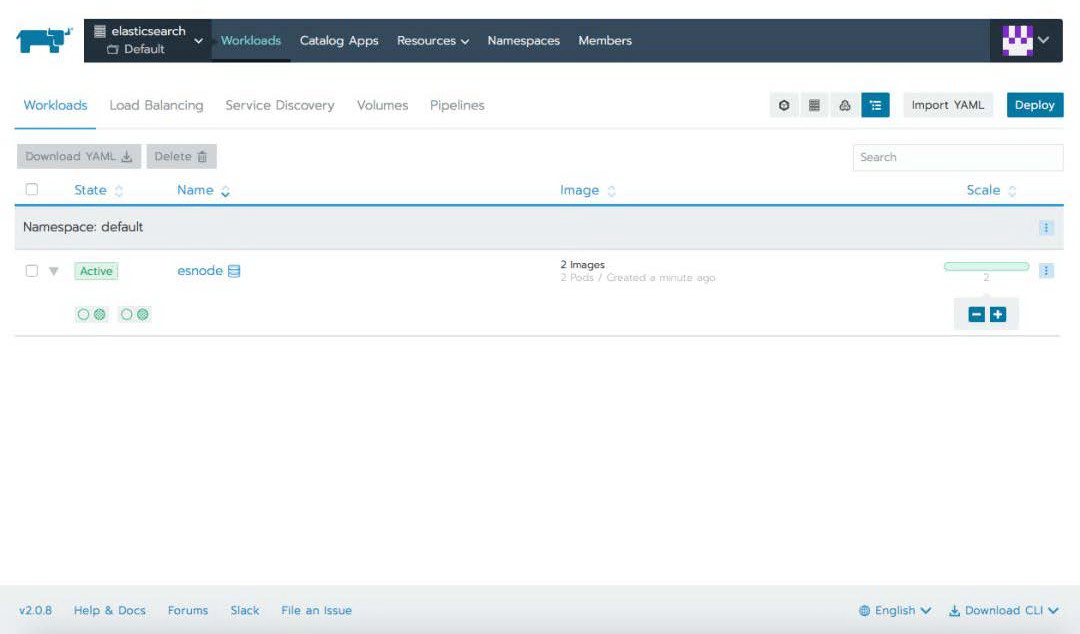
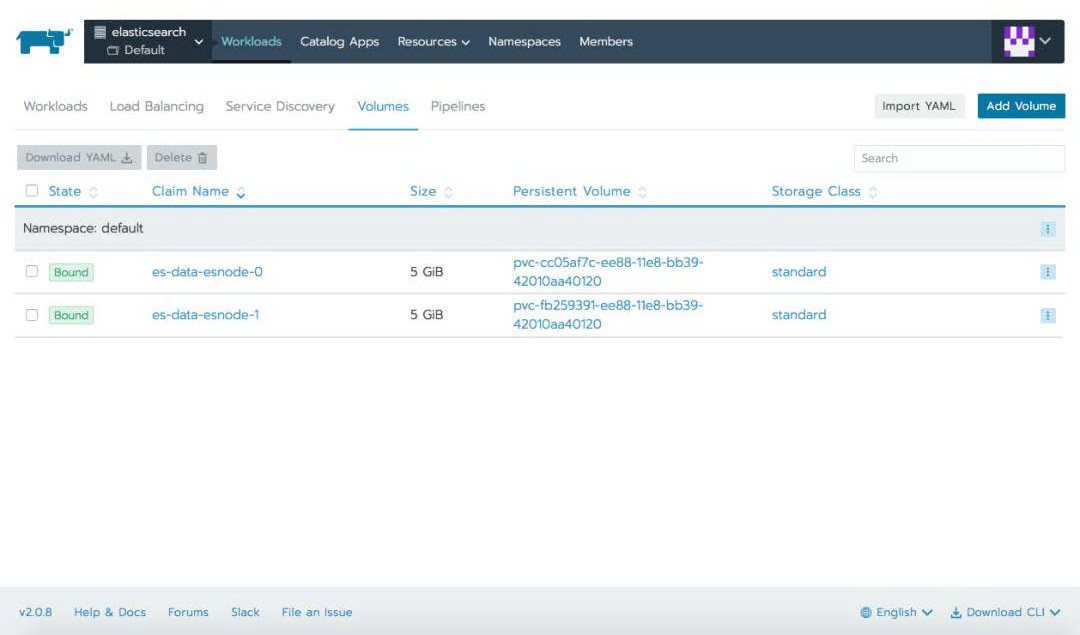
如果您想的话,可以通过 Rancher UI 将上述每个 manifest 都导入您的集群。下面的屏幕截图显示了每个过程。
导入 svc-cluster.yaml
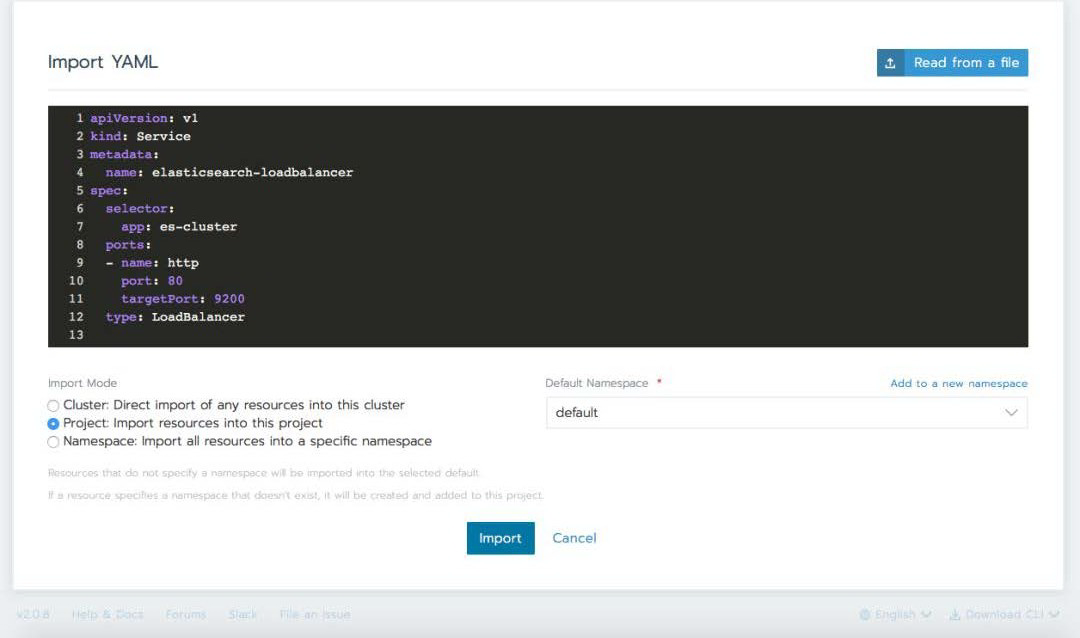
导入 svc-loadbalancer.yaml
导入 es-sts-deployment.yaml
检索负载均衡器 IP
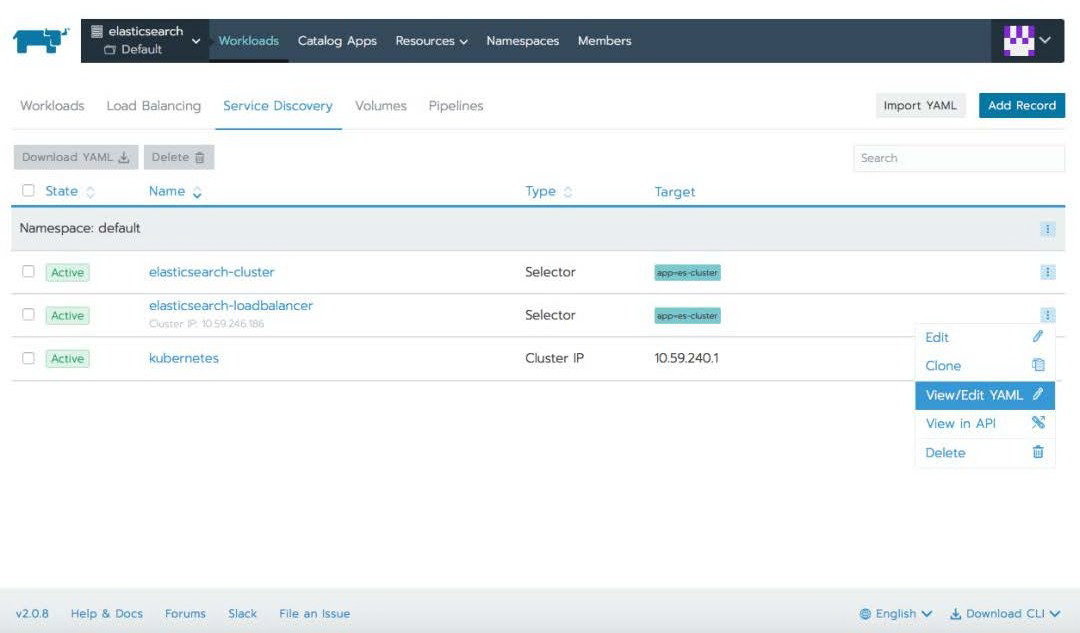
您后期会需要我们所部署的负载均衡器的地址的。您可以通过 kubectl 或 UI 检索此内容。
使用 CLI
使用 UI
测试集群
使用我们在上一步中检索的地址来查询集群以获取基本信息。
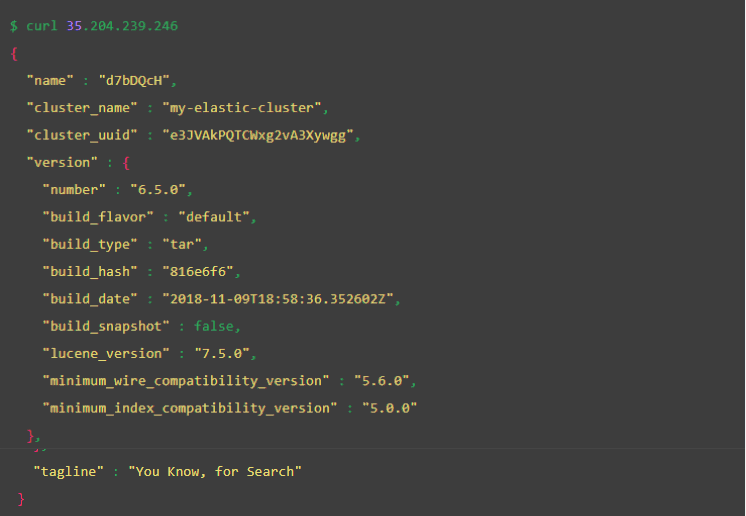
查询集群以获取有关其节点的信息。master 列中的星号突出显示当前主节点。

检查可用的指数:

因为这是一个全新的安装,所以它没有任何以前的索引或数据。为了继续本教程,我们将注入一些我们稍后可以使用的示例数据。我们将使用的文件可从 Elastic 网站获得:
https://www.elastic.co/guide/en/kibana/current/tutorial-load-dataset.html
下载它们,然后使用以下命令加载它们:
当我们重新检查索引时,我们将看到我们有五个新的索引数据。
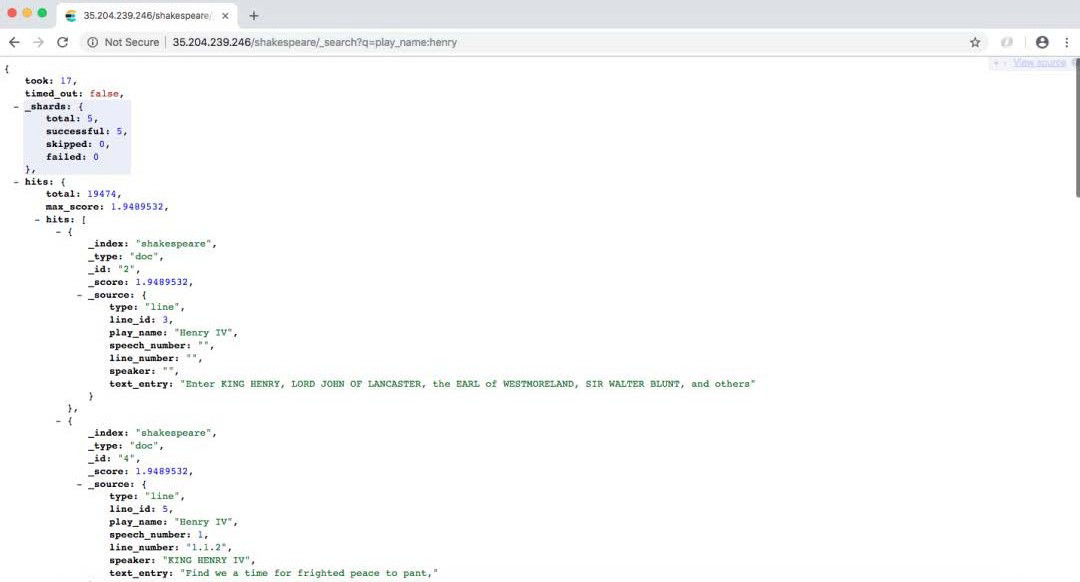
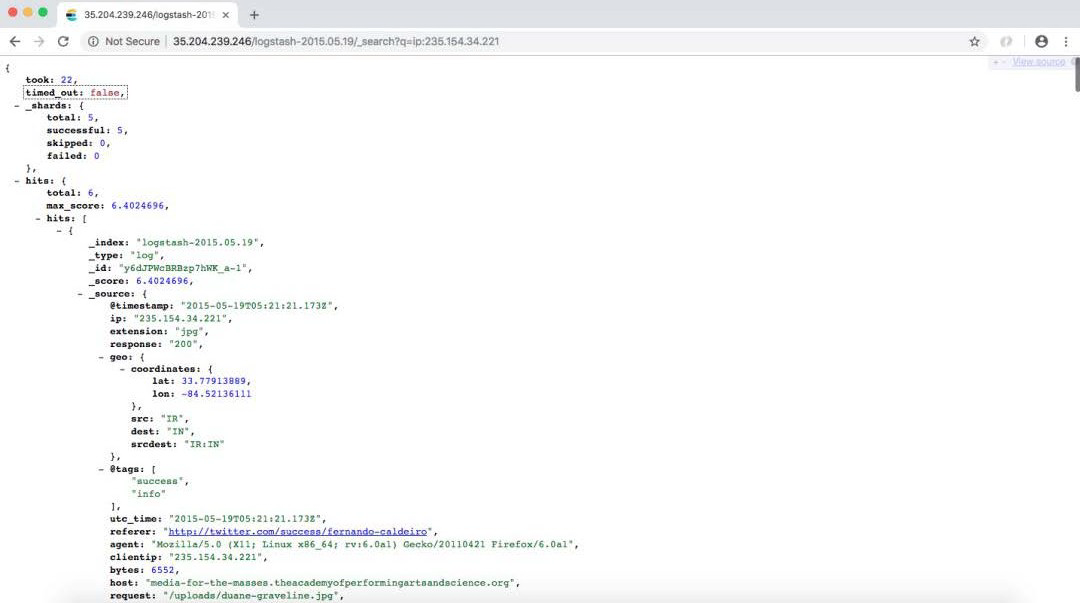
其中每个都包含不同类型的文档。对于 shakespeare 索引,我们可以搜索游戏的名称。对于 logstash-2015.05.19 索引,我们可以根据 IP 地址查询和过滤数据,对于 bank 索引,我们可以搜索有关特定帐户的信息。
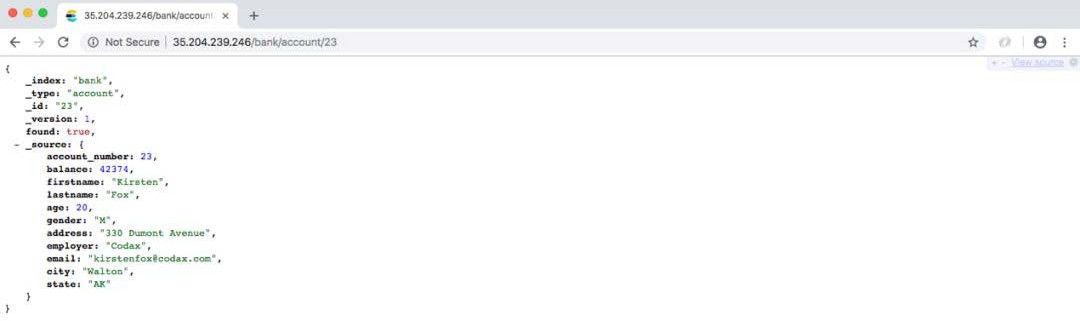
结论
Elasticsearch 非常强大。它既简单又复杂——易于部署和使用,而与数据交互的方式也很复杂。
本文向您展示了如何使用 Rancher 和 Kubernetes 部署它以及如何通过 RESTful API 进行查询的基础知识。
如果您希望探索在日常情况下使用 Elasticsearch 的方法,我们建议您探索 ELK 堆栈的其他部分:Kibana、Logstash 和 Beats。这些工具完善了 Elasticsearch 部署,使其可用于存储、检索和可视化来自系统和应用程序的各种数据。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论