

本篇介绍目前 NLP 领域的“网红”特征抽取器 Transformer。首先,作为引子,引入 Transformer 是什么的问题;接着,详细介绍了 Transformer 的结构和其内部的机制;最后,再总结 Transformer 的本质和定义。
1 Transformer 是什么?
很早就不断的有读者问我什么时候介绍 Transformer。确实,Transformer 是现在 NLP 领域最大的网红特征抽取器,基本现在所有的前沿研究都基于 Transformer 来做特征提取,不奇怪大家对它颇有兴致。
但是,我其实并不是很想写 Transformer,主要是网上写它的文章真的太多太多了,基本上能说的,各路神仙都把它说了一遍,要写出新意真的太难。
今天姑且就在这里说说,我所理解的 Transformer 吧,如有不对的地方,请大家指正。
在《Attention is all you need》中,Transformer 是一个用于机器翻译的编解码结构,这也是它为什么叫 Transformer 的原因。后来,因为在序列编码中强大的特征抽取能力和高效的运算特性,Transformer 被从编解码结构里抽离出来,成为了在 NLP 领域,目前最流行的特征抽取器。
我们暂且把对 Transformer 的认知,停留在这个层面,看完 Transformer 里到底有什么之后,再来思考这个问题,看能不能有更多的收获。
2 Transformer 里有什么
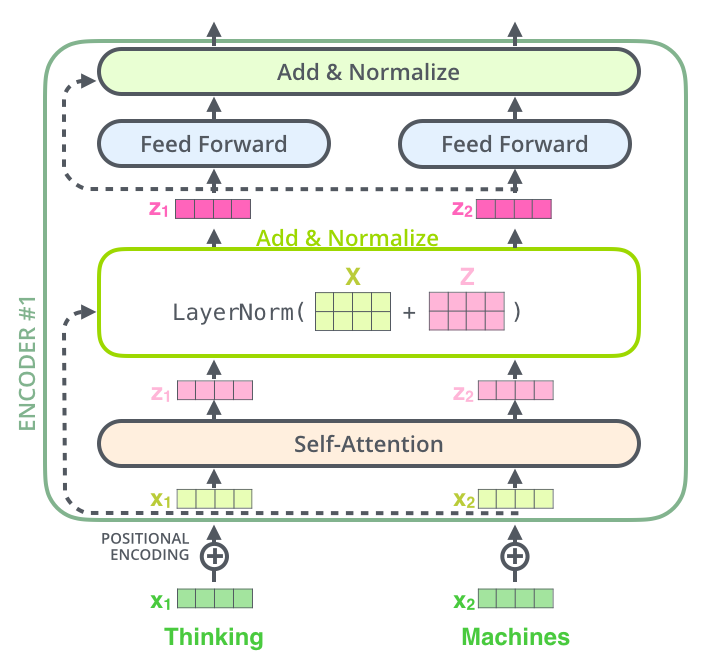
安利一下,上图来自http://jalammar.github.io/illustrated-transformer/该篇博客讲tranformer的网络结构讲的非常细和形象,想要了解这方面的读者开源仔细读一下。
上图是 Transformer 中,第一个 sub-layer 的结构示意图。其特别之处只有输入接收的为字向量和位置编码的和,其他 sub-layer 的输入为上一层 sub-layer 的输出。每一个 sub-layer,除上述差异之外,别无二致,所以我们只需要了解一个就可以。
通常,会有多层这样的 sub-layer,在 Bert-base 中,有 12 层,GPT-2.0 则更深,所以参数量都很大。GPT-2.0 的参数量达到了“丧心病狂”的 3 亿之多,是名副其实的大模型了。曾经刚入 NLP 坑的时候,会庆幸自己不用像 CV 的同学那样,天天看着贵的显卡乍舌叹气。不过小 Dream 哥现在也不用看了,训练最新模型的显卡,是一定买不起了。话说回来,NLP 中,模型参数已经大大超过了 CV 模型的参数量,正在朝着超大规模网络的方向狂奔。真有点担心,这样下去,后面 NLP 的玩家就只剩下那几个大玩家了。
好了,我们先看看 sub-layer 都有些什么内容。
(1) self-attention
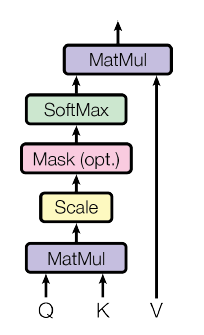
上图是 Transformer 中 self-attention 的计算过程。其实在 Transformer 中,Q,K,V 指的都是输入序列乘上不同的权重 W_Q,W_K,W_V。上述过程,可以用如下的公式概括:
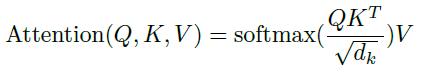
看过我们上一篇 Attention 文章的同学,应该对这个公式很熟悉。在 Transformer 中,主要通过这样一层 self-Attention 对输入序列进行编码。
该编码过程的一个特点是,在编码序列中的某一个词时,让该词充分的与序列中的其他词进行运算,从而能够得到该词与序列中所有词的句法和语义关系编码。
该编码过程的另外一个重要的特点是,序列是并行输入的,因此运算效率很高。
(2) Multi-head Attention
Multi-head Attention,即多头注意力机制。大概的处理流程如下图所示:
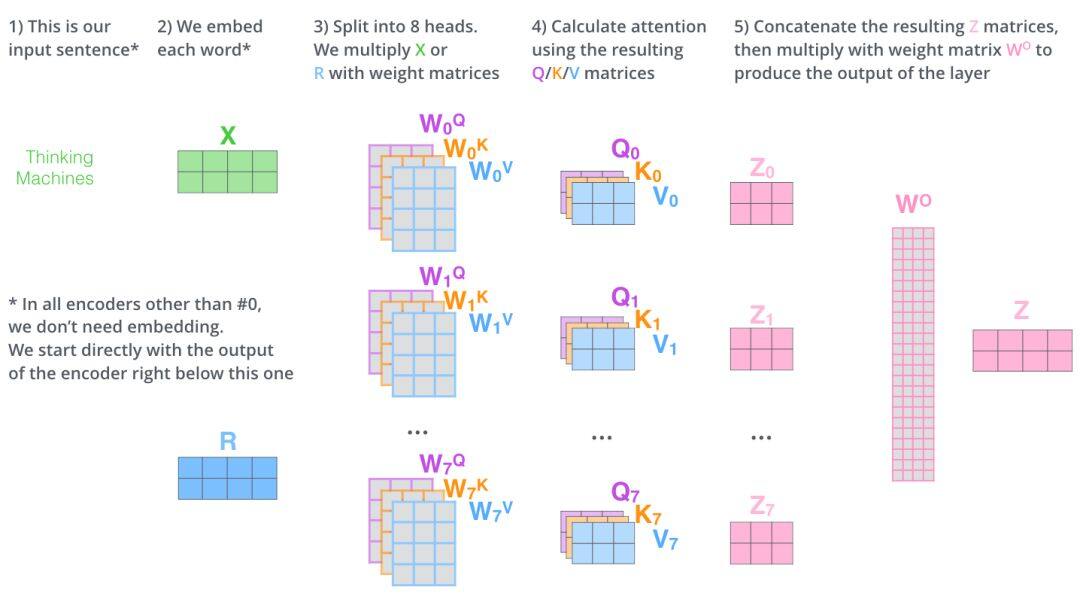
更多的细节,读者可以参考原文,这里不再详述。总的来说,多头机制就是 8 组权重,计算出了 8 个不同的输出,再通过拼接和运算得到新的序列编码。
那么,增加了 8 倍的参数和运算量。引入这样的机制有什么好处呢?
1) 极大的增强了模型的序列编码能力,特别是序列内词之间关系的语义表征能力。这个可以这样去想,假如只有一个头的话,因为是 self-attention,在计算过程中,很有可能该词与该词的的计算结果可能会比较大,从而词与自身的运算占据了很大的影响。如果引入多头机制,不同的权重,则可以避免这种弊端,增强模型的编码能力。
2) 实现了 Attention 的多个表征子空间。这样的好处是,每个子空间可以表征序列不同方面语义信息。这方面小 Dream 哥也没有看到相关论文的解释和支撑,就不多说了,了解的小伙伴可以留言指教。
(3) Feed-forward
每一个 sub-layer 还会接一个 Feed-forward Neural Network(FNN),FNN 的计算公式如下:
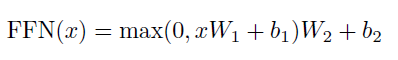
即在每个 sub-layer,针对 self-Attention 层的输出,先使用一个线性变换,再针对该线性变换的输出使用 RELU 函数,最后再针对 RELU 函数的输出使用一个线性变化。那么,做这么繁琐的变换有什么意义呢?
我们将 FNN 与 CNN 做对比,其实可以发现,其效果与加上一层卷积核大小为 11 的 CNN 是一样的。那么这就好理解了,这层所谓的 FNN 其实也是做特征提取的。至于它为什么不直接取名为 11CNN layer,这就要去问 Tranformer 的发明者了。
在 Transformer 中,还有其他的层,例如 Poition-Encoding 层,The Residuals 残差连接等,这些都好理解,读者可以参考前面推荐的 Jay Alammar 的博客。
3 再说 Transformer
前面大概讲述了 Transformer 的结构及其每个 sub-layer 的组成。那么我们再来讨论一下,Transformer 到底是什么?
我们可不可以这样说,Transformer 其实是一个用于对序列输入进行特征编码的工具。它以 self-Attention 机制为基础,从而能够编码序列输入的语义信息,对序列输入内不同词之间的关系也具有较强的编码能力,特别是 Multi-Attention 的引入,极大的增强了其编码能力。同时,Transformer 内其实还有 CNN 的影子,尽管原作者避免提及。并且,因为其结构上的优势,像 CNN 一样,Transformer 天然就能够并行计算,这一点是 RNN 等模型无法具备的。
总结
Transformer 中最重要的特点就是引入了 Attention,特别是 Multi-Head Attention。作为一个序列输入的特征抽取器,其编码能力强大,没有明显的缺点,短期内难以看到可以匹敌的竞争对手。
作者介绍
小 Dream 哥,公众号“有三 AI”作者。该公号聚焦于让大家能够系统性地完成 AI 各个领域所需的专业知识的学习。
原文链接
https://mp.weixin.qq.com/s/_rP-0WgqRCyKq5toXLCEvw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论