

引言
足球(欧洲足球)从小就是我最喜欢的运动之一。过去无论我去哪里,都会随身带着足球,这样我就能最大限度地利用踢足球的机会。
我也喜欢玩电脑游戏《FIFA 足球世界》,我觉得,用机器学习来分析 FIFA 中的球员是一件很酷的事情。
在本教程中,我将使用 K-均值(K-Means)聚类算法在 FIFA 20 将技能相似的球员进行分组。
了解聚类
聚类(Clustering)是无监督学习技术的一种(另一种是主成分分析)。
我们可以将观测值聚类(或分组)到相同的子组中,使子组内的观测值彼此相当相似,而不同子组中的观测值彼此相当不同。
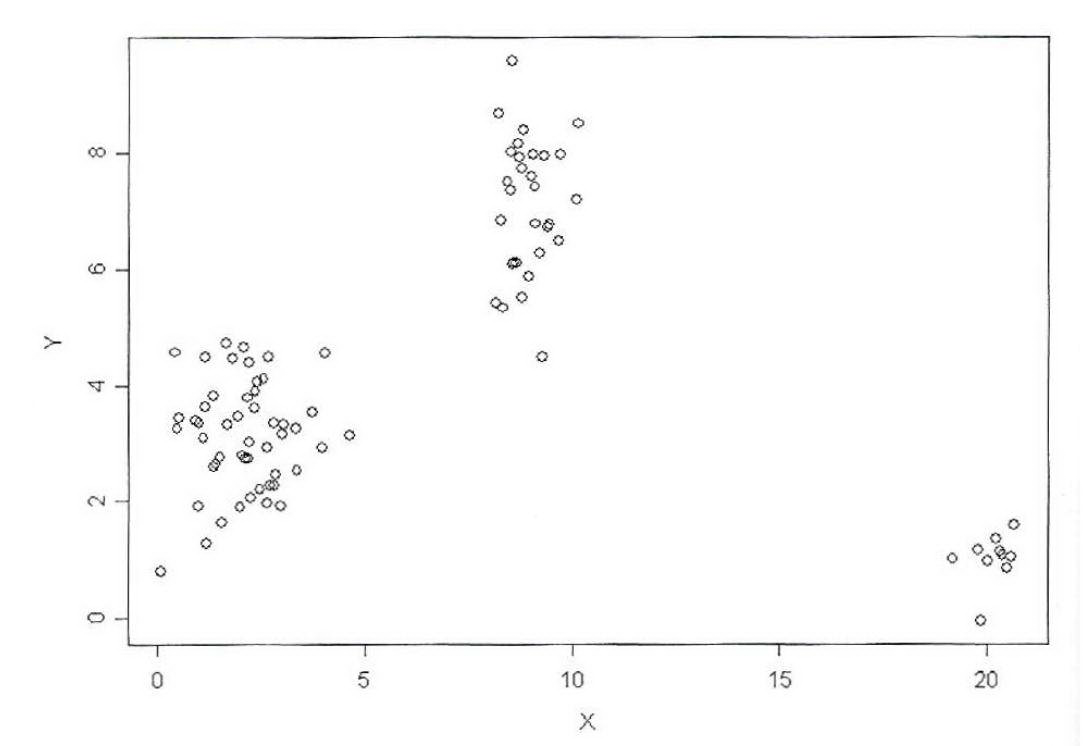
聚类示例。
上面的散点图显示了数据集中有三个不同的组。
了解 K-均值聚类算法
K-均值聚类算法是聚类算法中的一种。
基本算法如下:
指定 K-聚类并初始化随机质心。
进行迭代,直到聚类分配停止更改。该方法将每个观测值精确地分配到 K 个聚类中的一个。
对于每个 K 聚类,计算聚类平均值。
继续查看观测值列表,并将观测值分配给平均值最接近的聚类。
其目的是形成聚类,使同一聚类内的观测值尽可能相似。
K-均值聚类算法使用平方欧几里得距离计算相似度。
数据集
我们将使用 Kaggle 的 FIFA 20 数据集。
特征工程
我们只会选择数值和每个球员的名字。
我提取的是总成绩高于 86 分的球员,因为我们不想使用 18000 多名球员进行分组。
将空值替换为平均值。
归一化(标准化/缩放)数据。
我们希望将数据进行归一化,因为变量是在不同尺度上测量的。
使用主成分分析将图中的 60 个维度减少到 2 个。
执行 K-均值聚类
我们将指定有 5 个聚类。
通过添加球员的名字和他们的聚类来创建一个新的数据帧。
K-均值聚类图的可视化
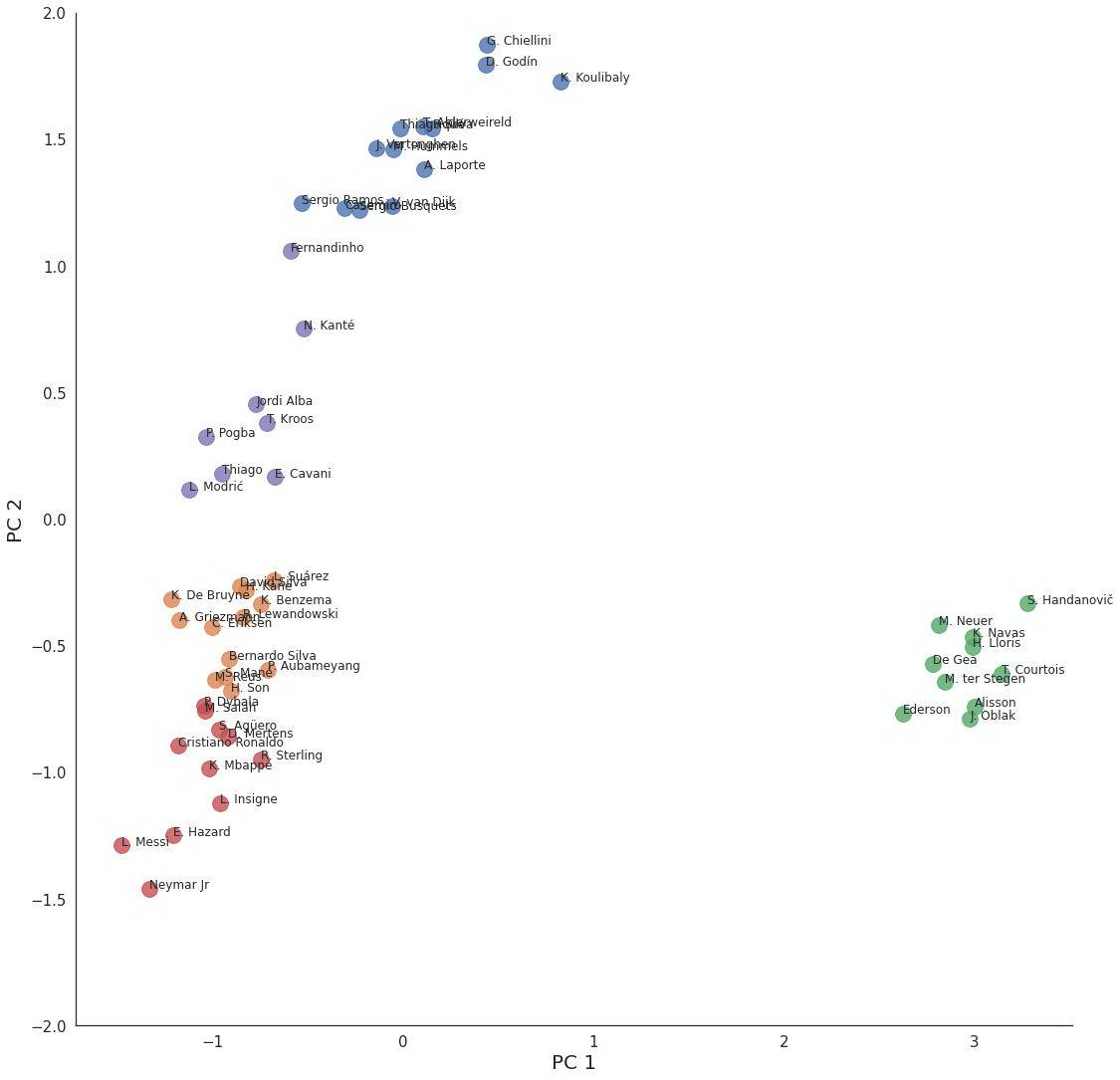
K-均值聚类
看看基于球员位置的聚类是如何形成的,是不是很酷!
我希望本教程对你有所启发,敬请关注下一篇教程!
作者介绍:
Jaemin Lee,专攻数据分析与数据科学,数据科学应届毕业生。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论