

S3 是 AWS 非常核心的一个存储服务。由于 S3 具有极强的扩展性、数据持久性、极低成本和高安全性,很多 AWS 用户会在一个 S3 存储桶上存储超过百万甚至过亿个的对象。这些对象通常是图像、视频、日志文件、备份或其他关键的业务数据。S3 是很多 AWS 用户数据存储架构的重要组成部分,也是用来构建数据湖解决方案的基础。
那如何在 S3 通过简单快捷的方式来处理数百万甚至数十亿对象呢?可以考虑使用 S3 Batch Operations(批量操作)功能!通过 S3 批量操作功能,在 S3 控制台上通过几次鼠标点击就可以实现批量将对象复制到另一个存储桶、设置对象标签或 ACL、触发 Glacier/Deep Archive 对象还原或者是对每个对象触发指定的 Lambda 函数进行处理。
S3 批量操作功能通过 S3 现有的清单报告(Inventory Report)或手动编写 CSV 文件来指定需要操作的对象集合。用户不需要编写任何代码,也不需要启动虚拟机集群,更不需要了解如何将批量操作任务进行分解并分发到虚拟机上进行执行。借助 S3 批量操作功能,用户只需要在控制台上通过几次鼠标点击即可在数分钟内创建一个作业(Job)并提交,通过 S3 大规模并行处理机制进行海量对象的批量操作。通过 S3 控制台、命令行或 API,用户可以创建、监控和管理批量操作作业。
基本概念
在开始使用 S3 批量操作功能并创建作业前,我们需要先了解一些基本的概念:
存储桶(Bucket):一个 S3 存储桶可以存放无限数量的对象,并提供对象级别的多版本管理功能
清单报告(Inventory Report): 清单报告是 S3 后台每天或每周定期对存储桶进行检查并生成对象清单列表。清单报告可以包含存储桶中所有对象,或只包含某些前缀(prefix)的对象。
清单(Manifest): 指定需要进行处理的对象集合,可以是清单报告,也可以是 CSV 文件
操作**(Operation):期望对目标对象执行的动作。对某个对象执行动作称之为一个任务(Task)**。
IAM 角色(IAM Role): 通过 IAM 角色赋予 S3 相应的权限,以便读取清单报告、对目标对象执行特定的动作以及写入完成报告。如果执行动作是调用 Lambda 函数,则需要确保 Lambda 函数的执行角色(Execution Role)具有相应的权限
作业(Job):每个作业会包含上述提到的要素,同时每个作业均有状态和优先级。
演示
接下来我们演示如何通过 S3 控制台创建并运行一个批量替换对象标签的作业。
在 S3 控制台左边可以看到批量操作功能的入口并创建作业
另外我们也可以选择从清单创建作业:

在这个演示中,我们已经为存储桶 linjungz-batch-bjs 创建了一个名为 Inv1 的清单,并保存在了 linjungz-logs-bjs 存储桶中。因此我们选择“从清单创建作业”按钮开始进入作业创建向导:

从上图可以看到,我们需要先为作业选择相应的 AWS 区域:如果是复制对象操作,则作业需要与目标存储桶在同一个 AWS 区域 ;如果是其他操作,则作业需要与被操作的对象在同一个 AWS 区域。在这个例子中我们演示进行批量的标签替换操作,由于被操作的对象存放在北京区域的存储桶中,因此作业也需要在北京区域创建。
另外由于我们是从清单创建作业的,因此可以看到这里自动选择了“S3 清单报告”并自动填充了清单对象的路径。用户也可以通过创建一个 CSV 文件来指定需要操作的对象列表。如果清单对象有多个版本,在这里我们也可以指定版本 ID。
接着我们进入下一步,指定对象所需要执行的操作。在这里我们选择“替换所有标签“,并指定对象的新标签:
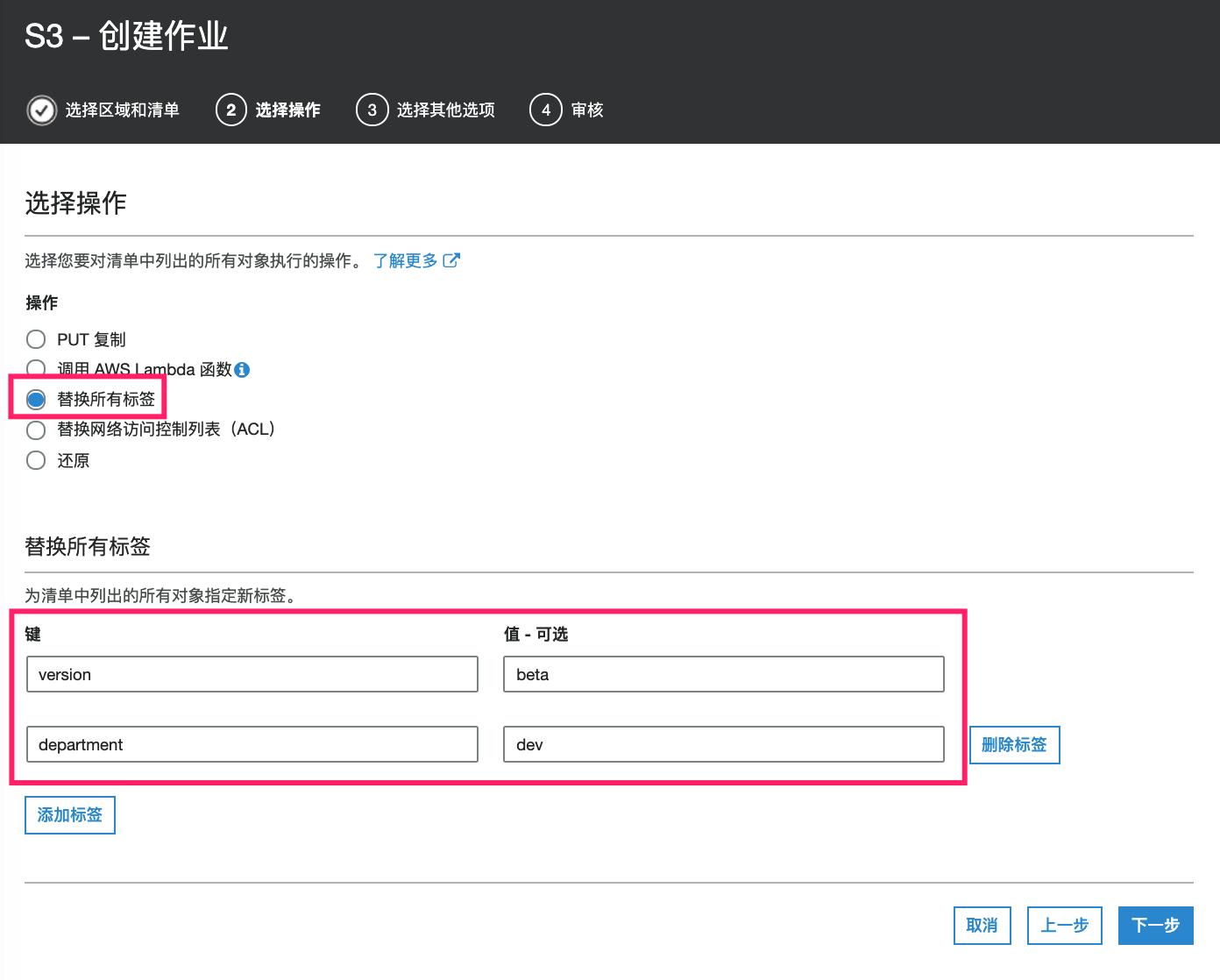
接着我们在下一步对作业的其他选项进行设置:

在上面截图可以看到,我们可以输入作业的描述和优先级,并指定是否生成完成报告及相应的位置。这里我把完成报告输出到了存储桶 linjungz-logs-bjs 并指定前缀 batch-reports。
同时在这里我们需要指定 S3 批量操作所需要的 IAM 角色,通过这个 IAM 角色 S3 可以获得相应的权限来执行批量操作。根据操作所需要的权限不同,控制台提供了对应的 IAM 角色的策略模板,基于这个模板用户可以快速的创建出相应的 IAM 策略。如下是替换对象标签所对应的 IAM 策略模板及简单的描述:

接下来我们将创建一个名为 linjungz-Batch 的 IAM 角色,以便 S3 Batch 可以有相应的权限来批量对指定的对象进行标签替换,并且输出作业完成报告。
首先我们将参考上述模板在 IAM 中创建一个新的策略,并命名为 linjungz-Batch-PutObjectTagging:
Json
(注意:在创建 S3 Batch 的策略时,如果该策略需要被重复使用,则可以适当放宽相应的读写权限。比如说在这个例子里,我的读取清单文件和写入完成报告的权限是指定到了整个存储桶。)
接着我们需要创建一个 IAM 角色。在这里我们需要指定这个角色的信任实体为 S3 Batch Operations

然后我们需要为这个角色附加刚才创建的策略:

最后我们在 S3 Batch 控制台上为这个作业选择刚才创建的 IAM 角色 linjungz-Batch

完成 IAM 角色创建后,我们可以进入到最后一步,即作业的审核:

确认没问题后,我们即可创建作业并提交。
在 S3 批量操作控制台上,我们即可看到刚提交的作业。稍等一会待作业准备完成后,作业状态会进入“等待确认”状态。此时我们可以看到 S3 Batch 已经通过我们指定的清单文件找到了本次作业所需要批量处理的对象数量,这里的例子是 158 个对象。
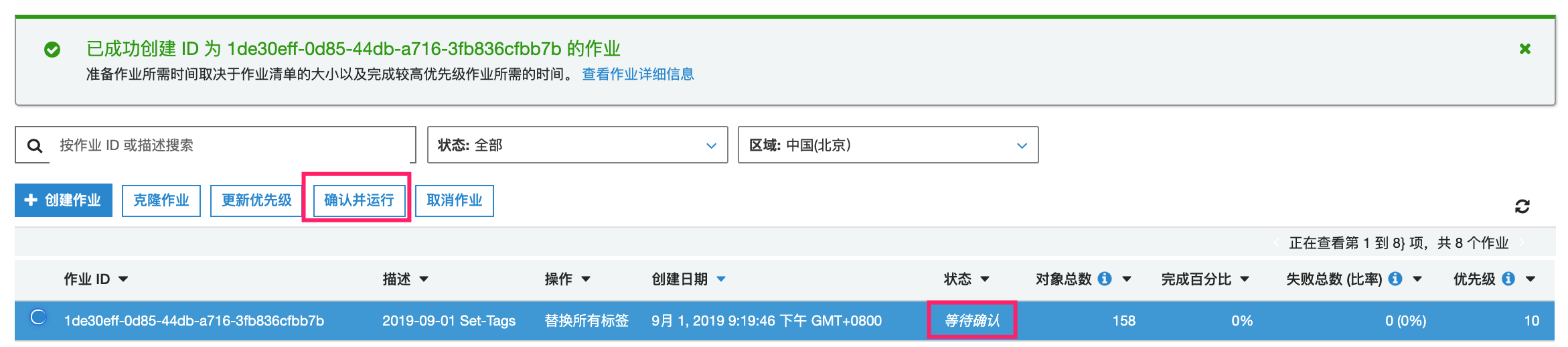
此时我们可以点击“确认并运行“按钮,并且确认后,S3 Batch 作业会在后台开始执行。
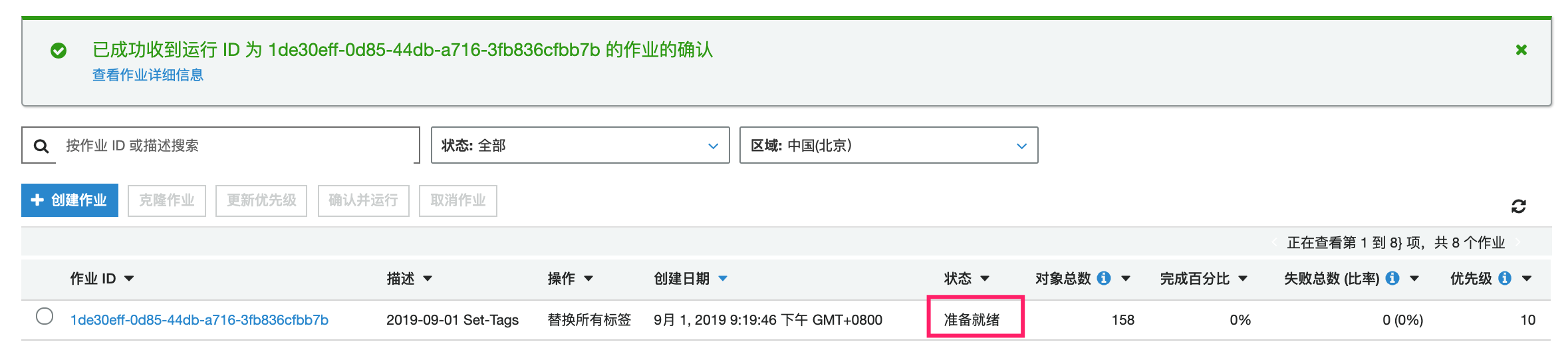
此时状态为“准备就绪“。在等待一段时间后作业完成,可以查看作业的状态:

可以随机挑选一个目标对象,检查标签是否已经替代成功:

同时 S3 会在刚才指定的存储桶 linjungz-logs-bjs 的指定路径下生成完成报告:

我们可以下载这个作业完成报告,或是直接在 S3 控制台上通过 S3 Select 查询完成报告所对应的 CSV 文件,看到本次 S3 Batch 作业的任务执行情况

小结
通过上面的演示我们可以看到,借助 S3 批量操作功能,我们可以方便地对海量对象进行批量操作,而无须自行编码去构建一个作业管理平台。S3 批量操作目前支持标签替换、ACL 替换、对象复制、Glacier/Deep Archive 数据还原以及触发 Lambda 函数。通过 Lambda 函数我们可以自行编码相应的处理逻辑,从而方便地扩展 S3 批量操作功能。
查阅我们的官方文档了解更多关于 S3 批量操作功能的信息吧
https://docs.amazonaws.cn/AmazonS3/latest/dev/batch-ops.html
作者介绍:
本文转载自 AWS 技术博客。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论