

DDQN
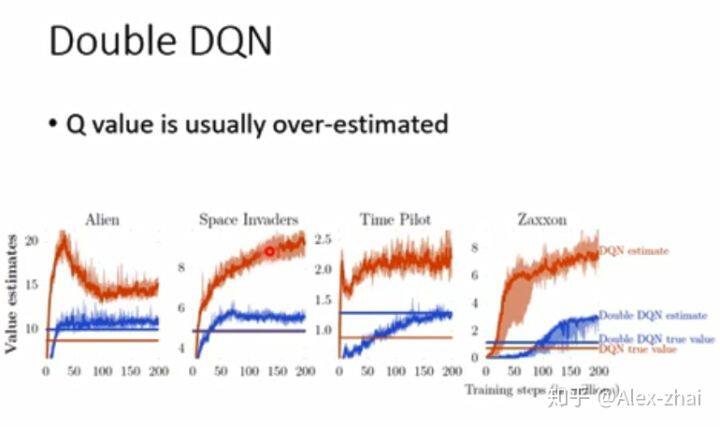
红色线表示 DQN 估计的 Q 值,发现都会比真实的 Q 值要高很多,那么是为什么会 Q 值会被高估?
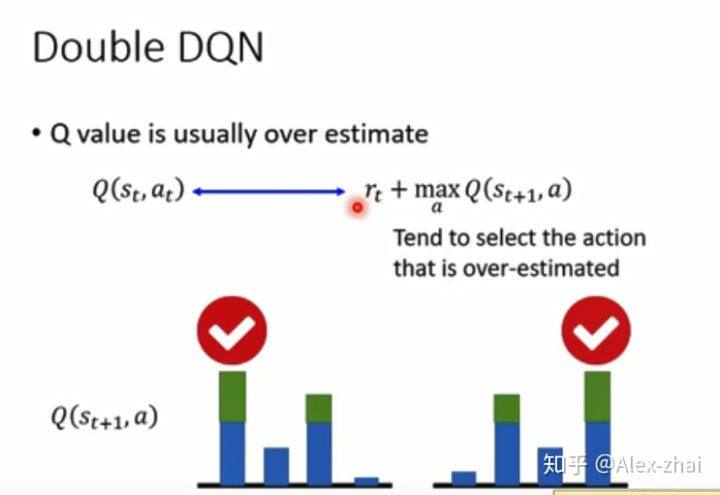
假设现在有 4 个状态动作对,他们真实的 Q 值其实是相差不大的,但是因为在学习过程中,Q 值是一个估计值,总会有状态动作对的 Q 值会被高估,此时被高估的 Q 值就会被选择出来当做 target。

解决方法就是用两个 Q 值函数(一个是当前的值网络,一个是 target 网络),一个用作动作的选择,一个用作 target Q 值的估计。这样当 Q 值被高估后,选出相应的动作,但只要[公式] 不高估就行。另外一种情况是如果 [公式] 被高估,但是此时被高估的动作也不会被选择到(选择动作是根据另一个 Q 值选的)。
Dueling DQN
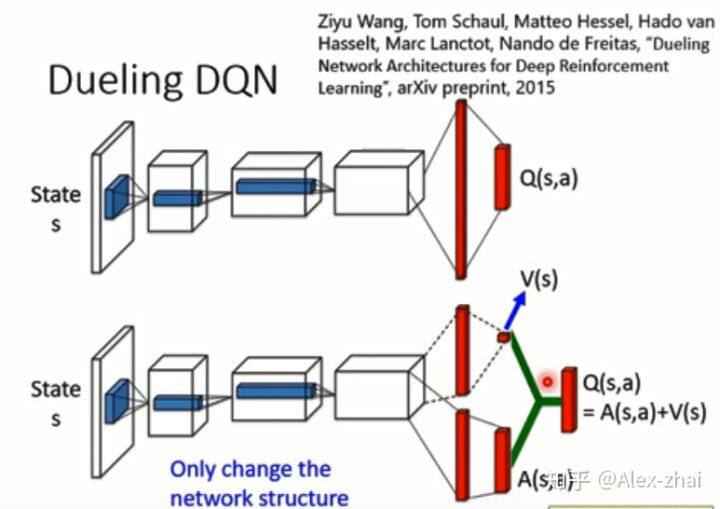
其实就是将输出 Q 值改为输出 V 值和 A 值。
那么这样有什么好处呢?
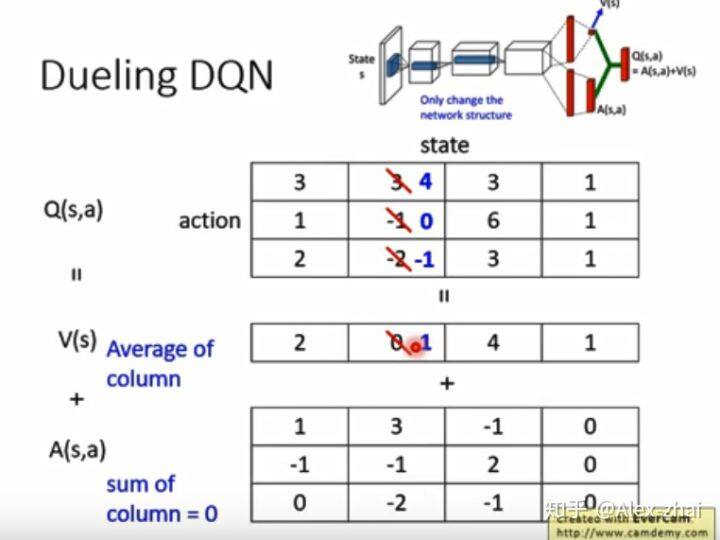
假设有两个 Q 值都希望+1,现在只能动 V 值和 A 值。现在可以让 V 值+1,那么所有的状态动作 Q 值都会改变,这样就不需要采样到所有状态动作对来更新所有的 Q 值,提高了样本的利用率。另外,必须对 A 值加 constraint,使得网络更新 A 值会比较复杂,而去倾向于更新 V 值。常做的方式是将一个动作的所有 A 值加起来为 0。
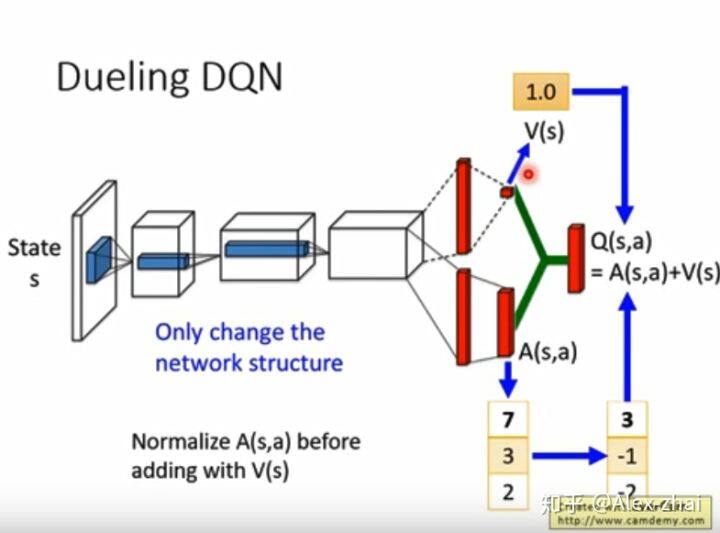
计算 Q 值的时候(V+A),先将 A 值做归一化。
Prioritized Reply
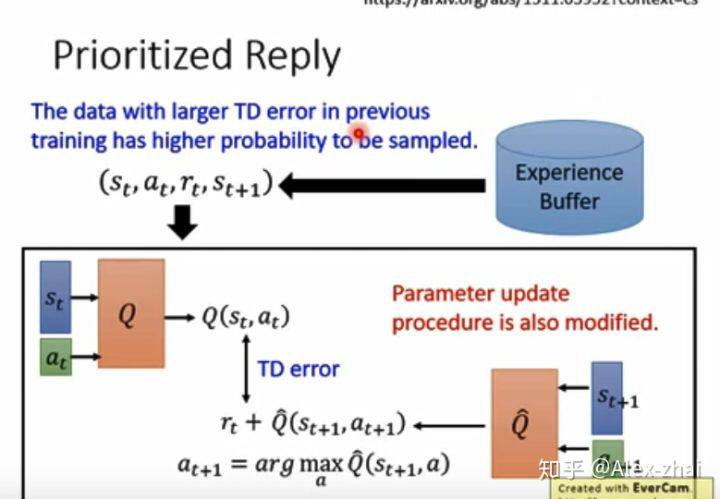
之前是从样本池中随机抽取一个 batch 训练数据,现在可优先选取 TD 误差较大的样本。TD 误差较大的样本训练价值更高,梯度会更大。
Multi-step

可结合使用 MC 和 TD 更新方法,之前 DQN 方法是存储一个时间步的转移样本 :[公式] ,现在存储 N 个时间步的转移样本。好处:sample 多个 step 的转移样本,Q 的估计值的准确性会提高,但是多个时间步的采样会导致方差变大。
Noisy Net

之前为了探索在动作上加 noise,现在可以在网络参数上加 noise。须注意的是 noise 必须在每个新的 episode 开始时加入,并且在每个 episode 期间没有动作的探索。
epsilon greedy 方法会有一个问题:在同个 state 下,可能会执行不同的动作。但是现实场景中合理的做法应该是同个 state 采取同一个 action。Noisy net 就会在同个 episode 中的同个 state 下,执行相同的动作。
Distributional Q-function
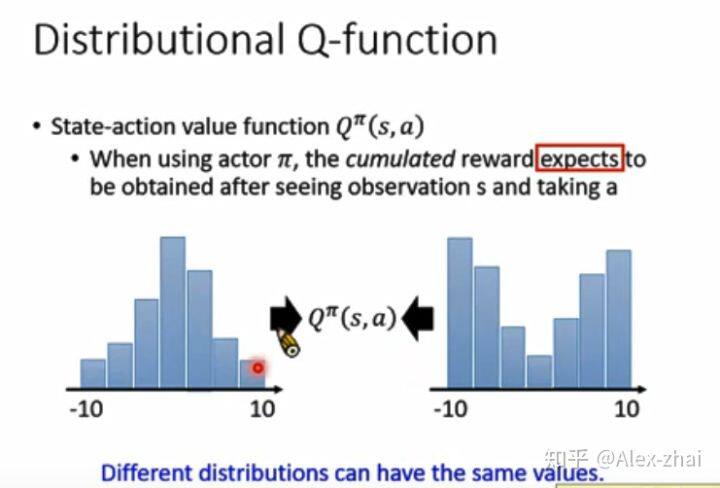
其实 Q(s,a)的值是有一个分布的,不同的分布可能会有同样的 mean 均值(当做 Q 值)。所以用 Q 来表示未来期望总奖赏会丢失一些信息。
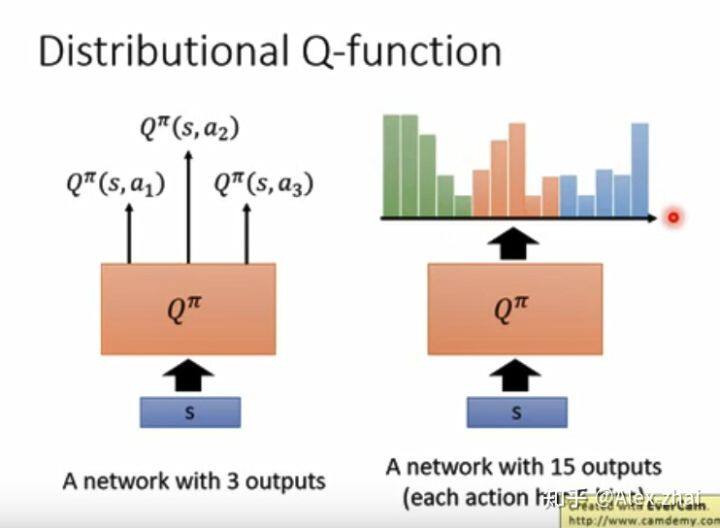
直接输出每个状态动作对的 Q 值的分布,这样可以根据 Q 值分布获得很多额外信息,比如可根据动作 Q 值的分布的熵来决定要不要采取该动作??
Rainbow
结合上述的几个 tips
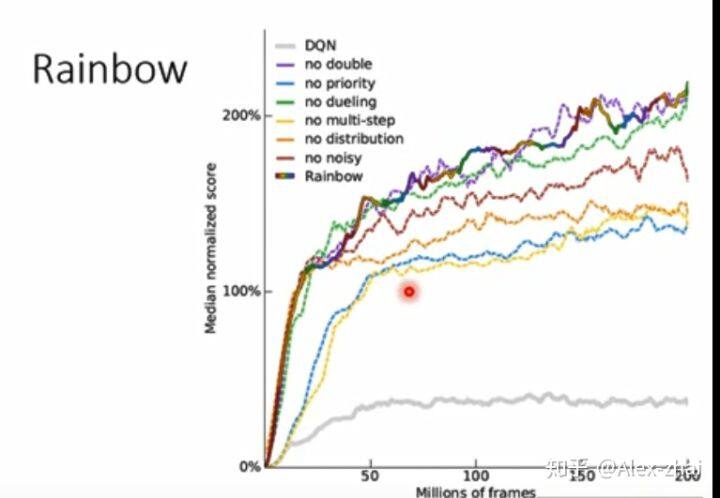
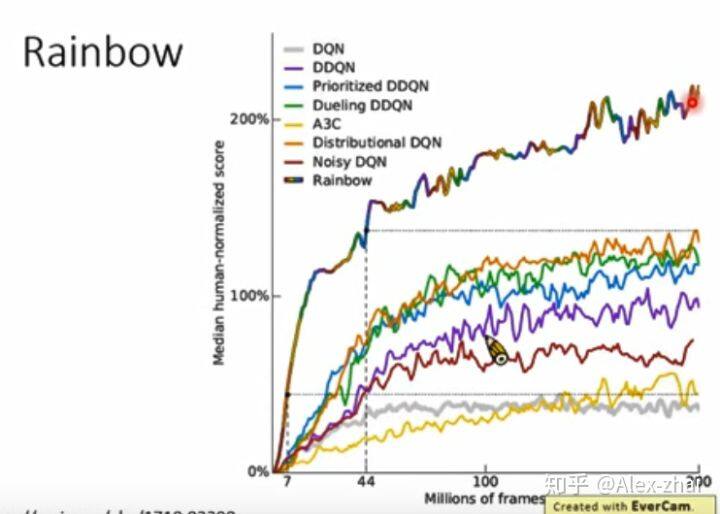
可发现,multi-step 和 priority 比较有用。
参考文献:
https://www.bilibili.com/video/av24
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/72994607

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论