

对我来说,数据科学家们使用高级软件包、创建令人眼花缭乱的演示方案以及不同算法,绝对是种感官与心灵的双重享受。数据科学家们有种神秘的气质——穿上一件酷酷的 T 恤、再加上一杯咖啡和一台笔记本,然后在不动声色之间成就非凡。

但这里要给各位从业者,特别是新手数据科学家们提个醒,某些致命错误很可能在一夜之间摧毁你的辛勤付出。这些错误会损害数据科学家的声誉,甚至彻底断送原本光明的数据科学从业前景。本文的目标也非常简单:帮助大家规避这类错误。
(1) 为什么“Datetime”变量是最重要的变量?
请注意以 yymmdd:hhmmss 格式存在的任意 datetime 字段,我们不能在任何基于树状结构的方法中使用此变量。
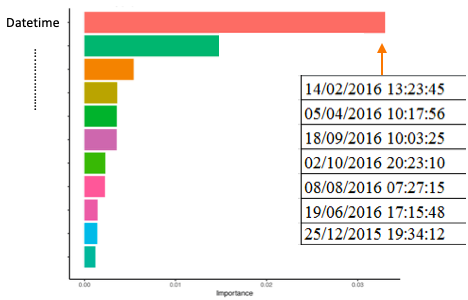
如下图所示,该变量的重要性冠绝群伦,这是因为其几乎被作为所有记录的唯一标识符,正如我们会在决策树中使用“id”字段一样。
另外,几乎可以肯定的是,大家会直接从该字段中导出年、月、日、工作日等信息。请记住,特征工程的核心,在于捕捉可重复模式(例如特定某个月或者某一周)以预测未来。
虽然在某些模型中,我们可以使用“year”作为变量来解释过去曾经发生的任何特定波动,但请永远不要将原始的 datetime 字段用作预测变量。
(2) 注意变量中的“0”、“-99”或“-999”
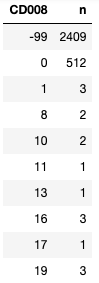
这些通常属于缺失值,因此系统将其设定为极值形式。在参数回归当中,请勿盲目将它们当成可用数值。
不同的系统,可能会设定出“-99”或者“-999”等形式的极值。这些值代表着某些特定含义,且不会随机缺失。请注意,不要在库等软件中盲目处理这类普遍存在的问题。
(3) 如何某个连续变量中包含“NA”、 “0”、“-99”或“-999”,该怎样处理?
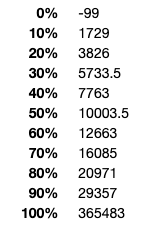
我建议大家对该连续变量进行归类,将其中的“0”、“-99”、“NA”等特殊值划分为独立的一类(当然也可以采用其他处理方法)。首先,我们可以为该变量设定分位点:
分位点如下所示:
接下来,利用以上分位点对变量进行归类,从而创建出新的变量。以下代码就保留有这类特殊值。这里我使用函数 cut()将连续变量划分为分类变量。我使用 case_when()来分配“-999”、“-99”、“0”以及“NoData”。(请注意,以下为 R 语言代码,但分类概念也适用于其他编程语言。)

(4) 强制将分类变量转换为基本变量
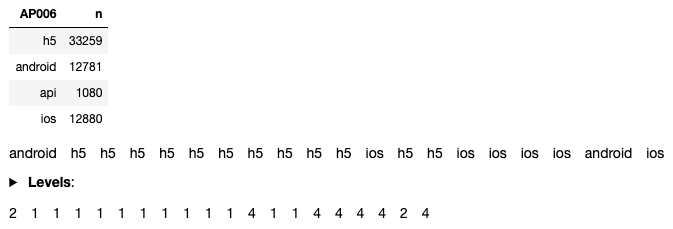
大家可能希望把分类变量转换为数字变量以运行回归,但却错误地将分类变量强制转换为数字变量。下图所示为将类别“AP006”强行转换为数字变量的结果。如果在回归中使用这个新变量,则品牌“Android”的值将比“h5”的值高出两倍。
(5) 忘记处理回归中的异常值
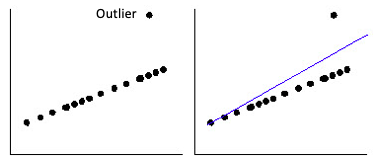
图中的异常值会导致您的回归偏向该观察值,并导致预测结果发生偏差。
(6) 要求线归回归中的因变量符合正态假设
因变量 Y 不必遵循正态分布,但是预测 Y 的相关误差应该遵循正态分布。数据科学家经常检查因变量直方图中的正态性假设。在这种特定情况下,如果因变量遵循正态分布,则会引发错误。
需要再次强调,基本根据是线性回归的误差应遵循正态分布,或者因变量本身会呈现出有条件的正态分布。我们先来回忆一下线性回归的定义:在 X 的每个值中,都存在一个符合正态分布的有条件 Y 分布。以下为线性回归的四大基本假设:
X 与 Y 之间为线性相关。
误差为正态分布。
误差具有同方差性(或者说与线周围的方差相关)。
观察的独立性。
根据大数定律与中心极限定理,线性回归中的最小二乘法(OLS)估计值仍将近似真实地分布在参数真值周围。因此,在一个大样本中,即使因变量不符合“正态假设”规则,线性回归方法仍能够发挥作用。
(7) 要求线性回归中的预变量符合正态假设
那么预测变量 X 呢?回归不会假设预测变量具有任何分布属性,其唯一的要求就是检查是否存在异常值(可使用盒型图检查异常值)。如果存在,则在该预测变量中应用上限与下限方法。
(8) 是否需要在决策树中做出分布假设?
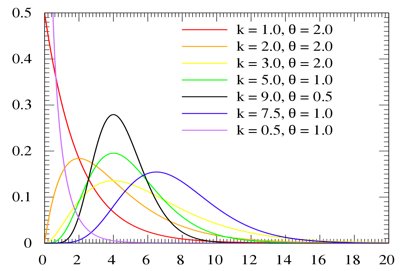
在参数式(例如线性回归)中,我们可以检查目标变量的分布以选择正确的分布。例如,如果目标变量呈现出 gamma 分布,则可以在广义线性模型(GLM)中选择 gamma 分布。
但是,决策树不会对目标变量进行假设。决策树的基本工作原理,是将每个父节点尽可能划分为不同的节点。决策树不会对初始群体或者最终群体的分布做任何假设。因此,分布的性质不影响决策树的实现。
(9) 是否需要在决策树中为预测变量设置上限与下限?
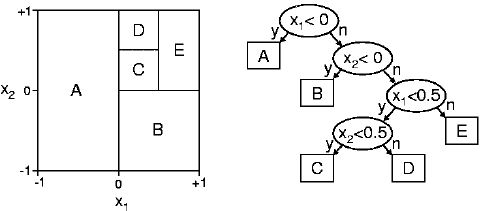
在参数式(例如线性回归)中,我们必须将异常值的上限设置为 99%(或 95%)并将下限设置为 1%(或 5%),从而处理异常值。在基于树状结构的算法当中,基本不需要在决策树中设置上限与下限。
换言之,决策树对于异常值具有鲁棒性。树算法会在同数值基础上拆分数据点,因此离群值不会对拆分产生太大影响。实际上,如何处理取决于您的超参数设置方式。
(10) 我的树中没有多少变量,或者变量数极少
这可能代表大家把复杂度参数(cp)设置得太高。复杂度参数(cp)代表的是每个节点所需要的最小模型改进。我们可以借此拆分节点来改善相对误差量。如果对初始根节点进行拆分,且相对误差从 1.0 降至 0.5,则根节点的 cp 为 0.5。
(11) 忘记对 K 均值中的变量进行标准化
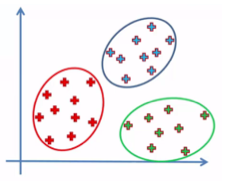
K 均值聚类可能是目前最流行的无监督技术,也确实能够带来很好的聚类效果。但是,如果没有将变量标准化为相同的大小,则可能给集群结果乃至业务应用带来灾难性的后果。
这里,我们用一个简单的例子进行解释。假设(X,Y)空间中的 P1、P2 与 P3 位置分别为(3000,1)、(2000,2)以及(1000,3)。K 均值计算出 P1 与 P2 之间的距离为 1000.0005。由于 X 的大小决定 Y 值,因此 X 会给结果带来错误影响。我们需要将 X 与 Y 设置为相同的大小。在本示例中,我们可以在 K 均值中将 X 表示为 X2 以计算距离。

下面列出几种可行方法:
(1) 缩放至 (0,1):
(2) Z 分数:
(3) 达到与先验知识相同的程度。在本示例中,我们知道 X 的大小为 Y 的 1000 倍,因此可以将 X 除以 1000 来生成 X2,其大小与 Y 相同。
原文链接:
Avoid These Deadly Modeling Mistakes that May Cost You a Career

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论